







一、二叉树基础
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
vector<int> ret;
if(root)
{
queue<TreeNode*> que;
que.push(root);
while(!que.empty())
{
int size=que.size();
while(size--)
{
//1.取当前层的
auto node=que.front();
que.pop();
//2.让入下一层的
//左
if(node->left) que.push(node->left);
//右
if(node->right) que.push(node->right);
//中
//3.业务逻辑
//加入每一层的最后一个节点
if(size==0) ret.push_back(node->val);
}
}
}
return ret;
}
};
class Solution {
private:
//统计遍历的节点个数
int cnt=0;
//存储第k小的节点值
int res=-1;
void dfs(TreeNode* node,int k)
{
if(!node) return;
//左
dfs(node->left,k);
//中
//业务逻辑
//如果遍历的节点树到达k,说明这个节点就是第k小的节点
if(++cnt==k)
{
res=node->val;
return;
}
//右
dfs(node->right,k);
}
public:
int kthSmallest(TreeNode* root, int k) {
dfs(root,k);
return res;
}
};
技巧:使用成员变量,让递归中不使用额外变量参与递归。
二叉树的创建
二叉树是非线性的结构,创建一棵二叉树必须首先确定树中结点的输入顺序,常有的方法是先序创建和层序创建。
TreeNode* buildTree(vector<int>& nums, int left,int right)
{
if(left>=right) return nullptr;
int mid=left+((right-left)>>1);
//创建根节点并递归生成子树
return new TreeNode(nums[mid],buildTree(nums,left,mid),buildTree(nums,mid+1,right));
}
(一)先序创建
/按先序遍历创建二叉树/
typedef struct BinNode
{
ElementType data;
BinNode *Left;
BinNode *Right;
}BinTree;
BinTree *CreatePre(BinTree* &BT)
{
char ch;
cout<<"ch=";
cin>>ch;
if(ch=='0')
BT=NULL;
else{
BT=new BinTree;
BT->data=ch;
BT->Left=CreatePre(BT->Left);
BT->Right=CreatePre(BT->Right);
}
return(BT);
}
树的遍历方式总体分为两类:深度优先搜索(DFS)、广度优先搜索(BFS)。
- 常见 DFS : 先序遍历、中序遍历、后序遍历。
- 常见 BFS : 层序遍历(即按层遍历)。
- /**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root)
{
//特殊处理
if(root==nullptr) return 0;
//初始化
vector<TreeNode*> que;
que.push_back(root);
int res=0;
//循环遍历: 当 queue 为空时跳出。
while(!que.empty())
{
//初始化一个空列表 tmp ,用于临时存储下一层节点。
vector<TreeNode*> tmp;
//遍历队列: 遍历 queue 中的各节点 node ,并将其左子节点和右子节点加入 tmp。
for(TreeNode* node:que)
{
if(node->left!=nullptr) tmp.push_back(node->left);
if(node->right!=nullptr) tmp.push_back(node->right);
}
//更新队列: 执行 queue = tmp ,将下一层节点赋值给 queue。
que=tmp;
//统计层数: 执行 res += 1 ,代表层数加 111。
res++;
}
//返回值: 返回 res 即可。
return res;
}
};
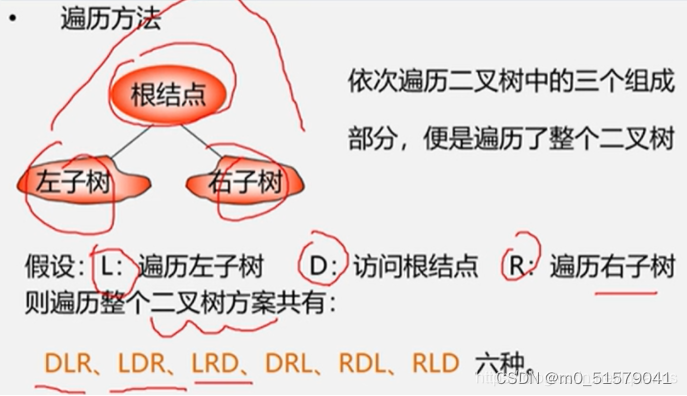
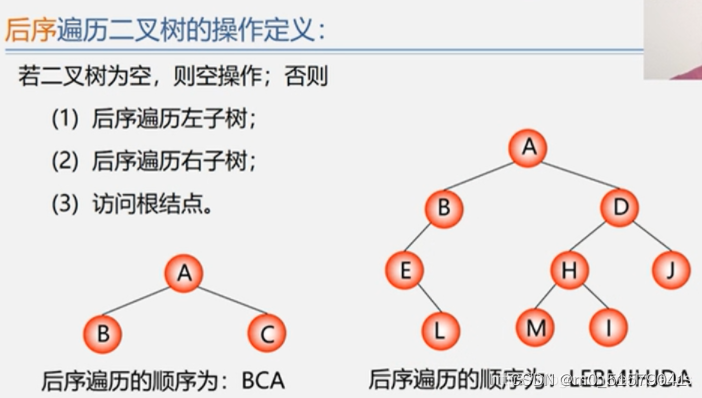
二叉树遍历:
顺着一条搜索路径访问二叉树中的节点,每个节点均被访问一次,且只被访问一次。
遍历目的:
得到树中所有节点的一个线性排列。
遍历用途:
是二叉树元素增删改查等操作的前提。

//定义节点
typedef struct BiNode{
ElemType data; //数据域
struct BiNode *lchild, *rchild; //左右孩子指针
}BiNode, *BiTree;
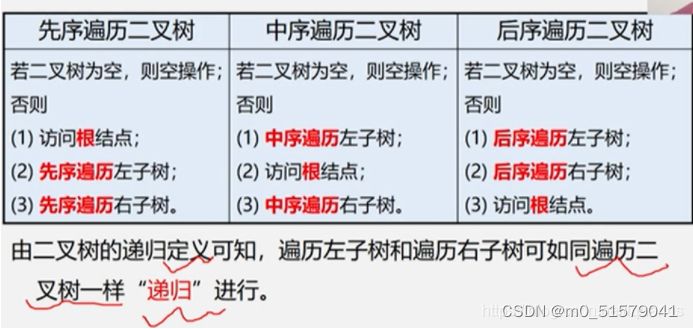
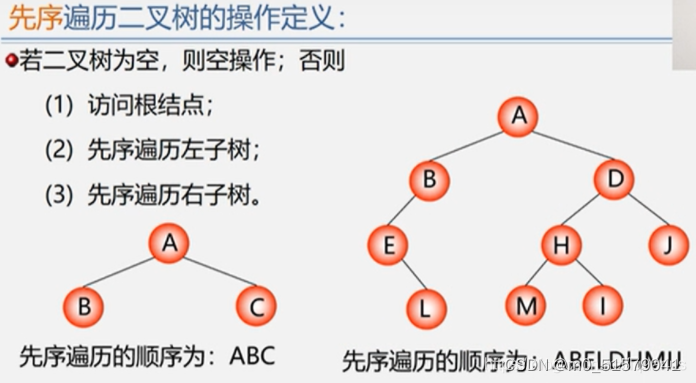
//二叉树先序遍历算法 - 根 左 右
int PreOrderTraverse(BiTree T){
if( T == NULL){ //若是空二叉树,则直接返回0
return 1;
}else{
visit(T); //访问根节点(自定义visit()方法,比如获取该节点的数据域)
PreOrderTraverse(T->lchild); //遍历递归左子树
PreOrderTraverse(T->rchild); //遍历递归右子树
}
}
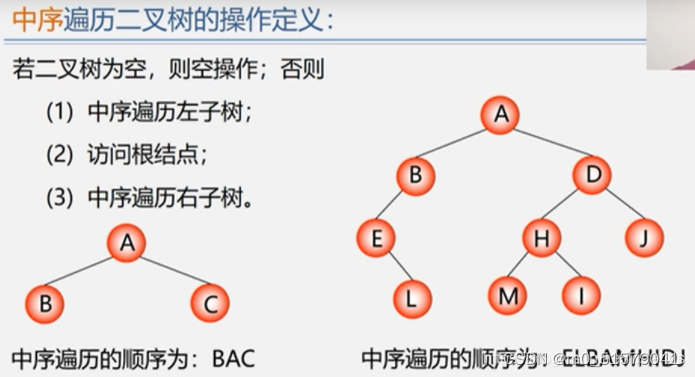
//二叉树中序遍历算法 - 左 根 右
int InOrderTraverse(BiTree T){
if( T == NULL ){ //若是空二叉树,则直接返回
return 1;
}else{
InOrderTraverse(T->lchild); //遍历递归左子树
visit(T); //访问根节点
InOrderTraverse(T->rchild); //遍历递归右子树
}
}
//二叉树后序遍历算法 - 左 右 根
int PostOrderTraverse(BiTree T){
if( T == NULL ){
return 1;
}else{
PostOrderTraverse(T->lchild); //遍历递归左子树
PostOrderTraverse(T->rchild); //遍历递归右子树
visit(T); //访问根节点
}
}
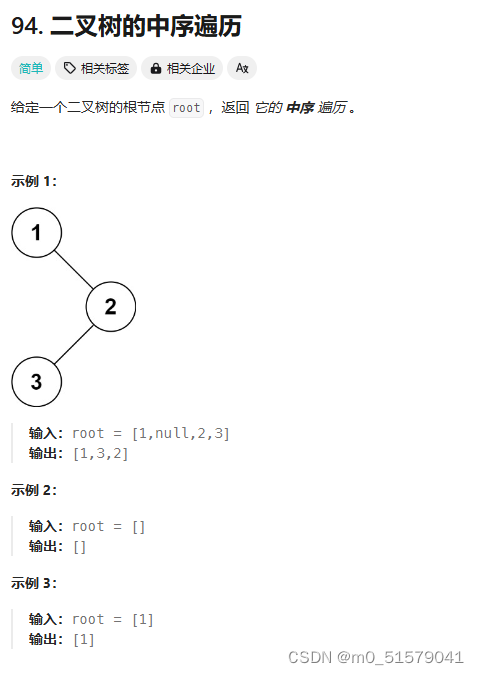
二、94. 二叉树的中序遍历
1 题目
2 解题思路
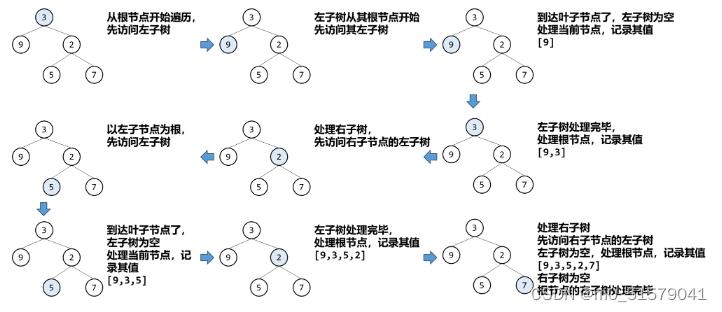
(1)二叉树的 中序遍历: 从根节点开始,首先遍历左子树,然后访问根节点,最后访问右子树。然后在遍历左子树的时候,同样首先遍历左子节点的左子树,然后访问根节点,最后遍历左子节点的右子树…
图解这个遍历过程:
(2)递归法
我们从根节点开始,我们先处理根节点的左子树,再处理根节点,最后处理根节点的右子树。而处理根节点的左子树时,我们把根节点的左子节点当成根节点,先处理左子节点的左子树,再处理左子节点,最后处理左子节点的右子树…依次类推
我们可以看到,对于每个节点的处理过程是一致的。先处理这个节点的左子树,再处理这个节点,最后处理这个节点的右子树,那么我们可以把这个过程封装成一个函数:
递归处理节点的左子节点;
添加节点的值;
递归处理节点的右子节点;
递归的关键是递归终点:当处理的节点是一个空节点时,说明以这个节点为根的子树是个空子树,无法处理,递归结束。
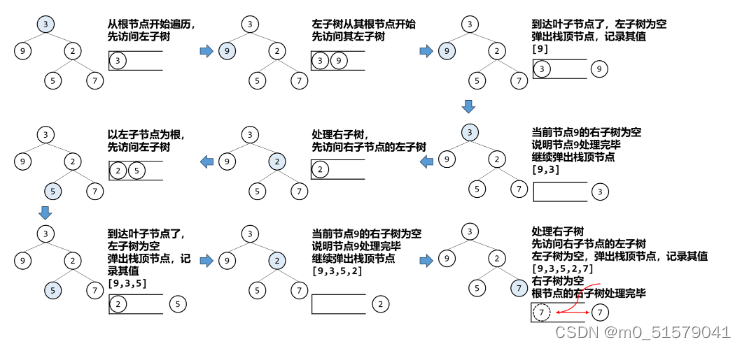
(3)迭代法
递归法其实隐式维护了一个栈结构:我们一直递归寻找最左侧的节点,直到找到后,再处理之前找到的节点。
因此迭代法我们可以使用一个栈结构,迭代的寻找当前节点的左子节点,直到找到最左侧的子节点,弹出处理。然后再处理这个节点的右子节点。
图解这个算法过程:
3 code
递归法
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
void dfs(TreeNode* node, vector<int>& res)
{
if(!node) return;
//先处理左子树
dfs(node->left,res);
//再处理当前根节点
res.emplace_back(node->val);
//最后处理右子树
dfs(node->right,res);
}
public:
vector<int> inorderTraversal(TreeNode* root)
{
vector<int> res;
dfs(root,res);
return res;
}
};
迭代法
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> res;
TreeNode* node = root;
stack<TreeNode*> st;
// 节点不为空或栈内有节点时,说明还有节点未遍历
while(!st.empty() || node){
// 中序遍历,优先遍历当前node为根的子树的最左侧节点
while(node){
st.push(node);
node = node->left;
}
node = st.top(); // 获取当前节点
st.pop(); // 弹出栈顶节点
res.emplace_back(node->val);
node = node->right; // 遍历node的右子树
}
return res;
}
};
三、104. 二叉树的最大深度
1 题目
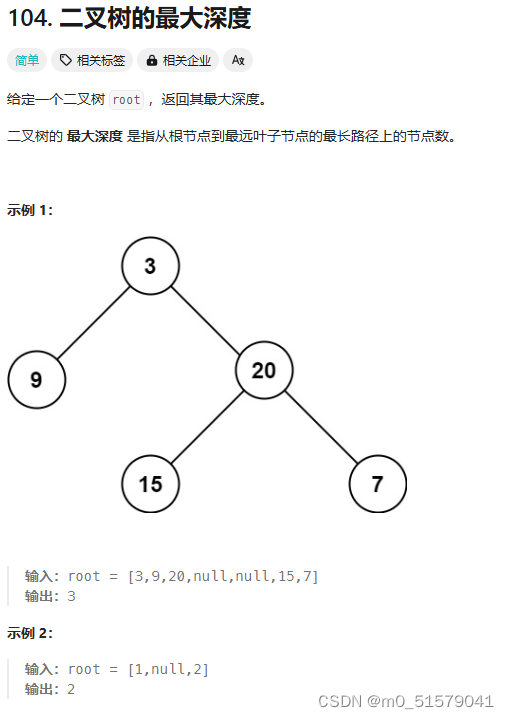
2 解题思路
方法一:后序遍历(DFS)
树的后序遍历 / 深度优先搜索往往利用 递归 或 栈 实现,本文使用递归实现。
关键点: 此树的深度和其左(右)子树的深度之间的关系。显然,此树的深度 等于 左子树的深度 与 右子树的深度中的 最大值 +1+1+1 。
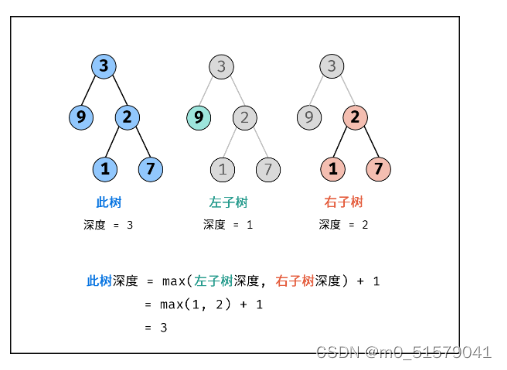
算法解析:
终止条件: 当 root 为空,说明已越过叶节点,因此返回 深度 000 。
递推工作: 本质上是对树做后序遍历。
计算节点 root 的 左子树的深度 ,即调用 maxDepth(root.left)。
计算节点 root 的 右子树的深度 ,即调用 maxDepth(root.right)。
返回值: 返回 此树的深度 ,即 max(maxDepth(root.left), maxDepth(root.right)) + 1。
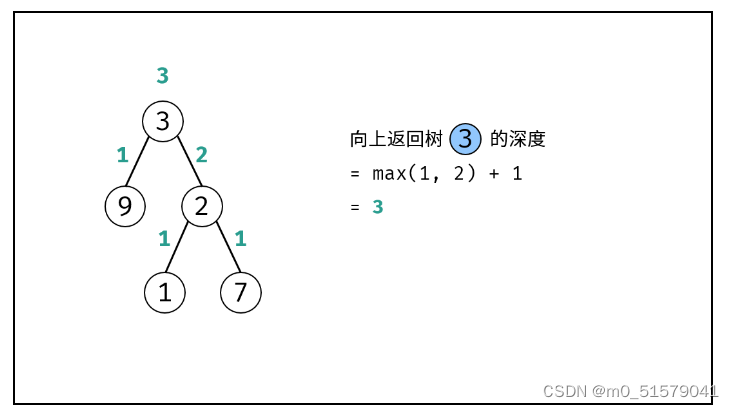
方法二:层序遍历(BFS)
树的层序遍历 / 广度优先搜索往往利用 队列 实现。
关键点: 每遍历一层,则计数器 +1+1+1 ,直到遍历完成,则可得到树的深度。
算法解析:
特例处理: 当 root 为空,直接返回 深度 000 。
初始化: 队列 queue (加入根节点 root ),计数器 res = 0。
循环遍历: 当 queue 为空时跳出。
初始化一个空列表 tmp ,用于临时存储下一层节点。
遍历队列: 遍历 queue 中的各节点 node ,并将其左子节点和右子节点加入 tmp。
更新队列: 执行 queue = tmp ,将下一层节点赋值给 queue。
统计层数: 执行 res += 1 ,代表层数加 111。
返回值: 返回 res 即可。
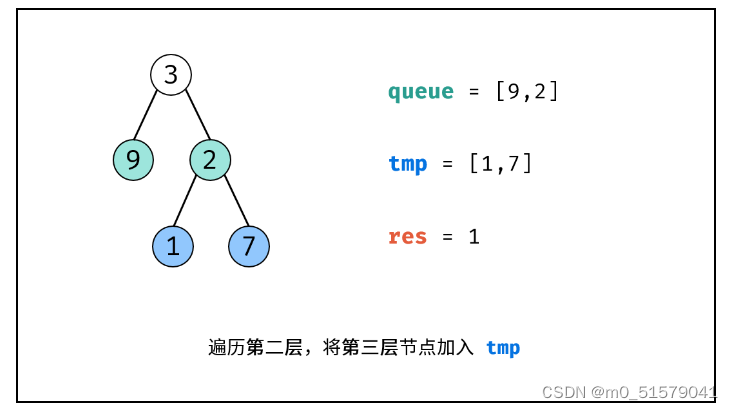
3 code
方法一:后序遍历(DFS)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root)
{
if(root==nullptr) return 0;
int l=maxDepth(root->left);
//error
//int depth=max(l,r)+1;
int r=maxDepth(root->right);
//业务逻辑需要用到左右子树,所以只能后序遍历
int depth=max(l,r)+1;
return depth;
}
};
方法二:层序遍历(BFS)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root)
{
//特殊处理
if(root==nullptr) return 0;
//初始化
vector<TreeNode*> que;
que.push_back(root);
int res=0;
//循环遍历: 当 queue 为空时跳出。
while(!que.empty())
{
//初始化一个空列表 tmp ,用于临时存储下一层节点。
vector<TreeNode*> tmp;
//遍历队列: 遍历 queue 中的各节点 node ,并将其左子节点和右子节点加入 tmp。
for(TreeNode* node:que)
{
if(node->left!=nullptr) tmp.push_back(node->left);
if(node->right!=nullptr) tmp.push_back(node->right);
}
//更新队列: 执行 queue = tmp ,将下一层节点赋值给 queue。
que=tmp;
//统计层数: 执行 res += 1 ,代表层数加 111。
res++;
}
//返回值: 返回 res 即可。
return res;
}
};
四、226. 翻转二叉树
1 题目
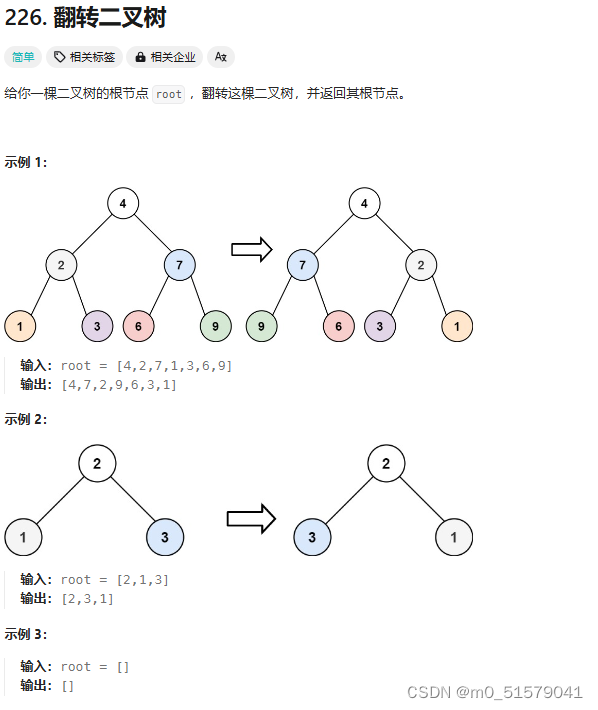
2 解题思路
方法一:深度优先搜索(DFS)【递归法/自底向上】
自底向上依次翻转每一个节点的左右子节点。
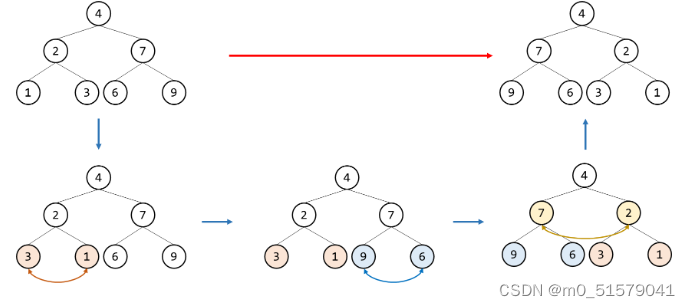
方法二:广度优先搜索(BFS)【迭代法/自顶向下】
自顶向下一层一层的翻转每一个节点的左右子节点。
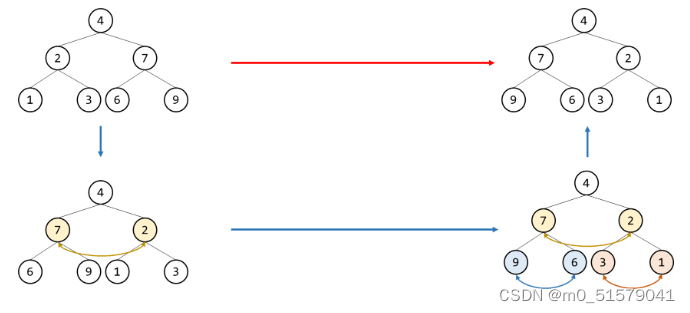
3 code
方法一:深度优先搜索(DFS)【递归法/自底向上】
class Solution {
public:
TreeNode* invertTree(TreeNode* root)
{
if(!root) return root;
auto temp = invertTree(root->left);
root->left=invertTree(root->right);
root->right=temp;
return root;
}
};
方法二:广度优先搜索(BFS)【迭代法/自顶向下】
class Solution {
public:
TreeNode* invertTree(TreeNode* root)
{
if(!root) return root;
queue<TreeNode*> q;
q.push(root);
int size;
TreeNode* node;
TreeNode* temp;
while(!q.empty())
{
//获取每一层的节点数
size=q.size();
//依次弹出这一层的size个节点
while(size-->0)
{
node=q.front();
q.pop();
//交换节点的左右子节点
temp=node->left;
node->left=node->right;
node->right=temp;
//左右子节点不为空的,加入队列作为下一层处理的节点
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
}
}
return root;
}
};
四、101. 对称二叉树
1 题目
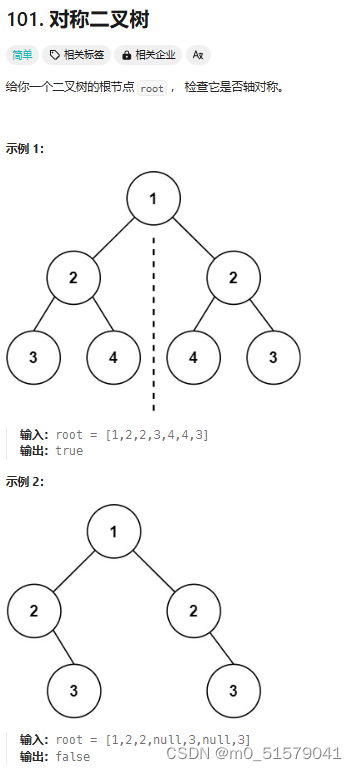
2 解题思路
这道题要判断一个二叉树是否对称,关键有两点:
如何构成对称;
如何找到对应位置的节点。即找到每次要判断是否对称的两个节点;
第一步比较容易解决,对称的依据是 要么对应位置上的节点都为空,要么都不为空且值相等。
而如何找到每次要判断对称的两个节点呢?从图上来看:
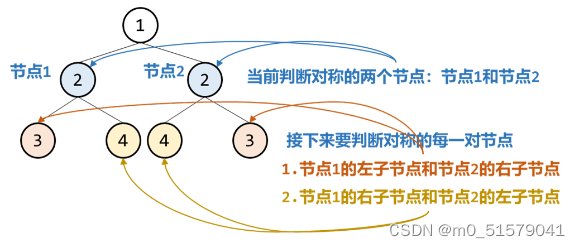
每一次比较对称的节点对,都是当前节点对一个的左子节点和另一个的右子节点。而初始比较对称的节点对为根节点的左右子节点。
方法一:深度优先搜索(DFS)【递归法/自底向上】
每一次判断两个节点是否对称:
- 两个节点都为空,对称;
- 存在一个为空一个不为空,或者两个不为空但值不相等,不对称;
- 否则就递归比较两个节点的子节点,即节点1的左子节点和节点2的右子节点,以及节点1的右子节点和节点2的左子节点。
方法二:广度优先搜索(BFS)【迭代法/自顶向下】
广度优先搜索对节点判断是否对称的方式不变,而是遍历的方式发生了改变。通过队列存储每一层需要比较对称的节点。
即每一次从队列取出两个节点,由于队列中不能存储空节点,因此我们取出的两个节点并不是要比较的节点对,而是已经比较过的节点对。真正要比较的是这两个节点的子节点,即节点1的左子节点和节点2的右子节点,以及节点1的右子节点和节点2的左子节点。
初始我们比较根节点的左右子节点是否对称,非空且对称,则加入队列进行其子节点的比较。
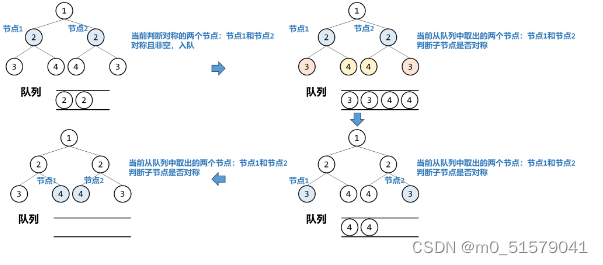
3 code
方法一:深度优先搜索(DFS)【递归法/自底向上】
class Solution {
public:
bool isSymmetric(TreeNode* root)
{
if(!root) return true;
return check(root->left,root->right);
}
bool check(TreeNode* node1,TreeNode* node2)
{
//当前判断对称的两个节点:节点1和节点2
if(!node1 && !node2) return true;
//接下来要判断对称的每一对节点
//1.节点1的左子节点和节点2的右子节点
//2.节点1的右子节点和节点2的左子节点
if(!node1 || !node2 || node1->val != node2->val) return false;
//两个节点相同值相同--对称,递归比较其子节点
return check(node1->left,node2->right) && check(node1->right,node2->left);
}
};
方法二:广度优先搜索(BFS)【迭代法/自顶向下】
class Solution {
public:
queue<TreeNode*> q;
bool isSymmetric(TreeNode* root)
{
//判断根节点
if(!root) return true;
//判断根节点的左右子节点
if(!check(root->left,root->right)) return false;
while(!q.empty())
{
//从根节点的左右子节点开始,依次比较
TreeNode* node1=q.front();
q.pop();
TreeNode* node2=q.front();
q.pop();
if(!check(node1->left,node2->right)) return false;
if(!check(node1->right,node2->left)) return false;
}
return true;
}
bool check(TreeNode* node1,TreeNode* node2)
{
//当前判断对称的两个节点:节点1和节点2
if(!node1 && !node2) return true;
//接下来要判断对称的每一对节点
//1.节点1的左子节点和节点2的右子节点
//2.节点1的右子节点和节点2的左子节点
if(!node1 || !node2 || node1->val != node2->val) return false;
q.emplace(node1);
q.emplace(node2);
return true;
}
};
五、543. 二叉树的直径
1 题目
2 解题思路
之前应该做过一个很类似的题,还是用遍历加改变节点值的方法。
首先明确怎么确定这个最大路径,很简单可以思考到,这个最大路径肯定有一个’根节点’,这个根节点不一定是原二叉树的根节点,意思是从该根节点往左右节点延申到叶子节点得到的路径肯定是最长的路径,因为如果没有这个根节点,只算一边肯定不能是最大路径,因为还可以往另一边延申,如果不到叶子节点肯定也不对,因为还可以向下走,就不能算最大路径。
lz最开始的思路是用前序遍历,从根节点遍历每一个节点,算每个节点左右子树的最大高度之和就是从该根节点能达到的最大路径,但是这种方式我们每次都要重新遍历节点,每次都要重新算从某个节点往下延伸的最大高度,这样上一次算出来的最大路径在后面也不能用,所以考虑使用后序遍历的方式,先遍历最下面的,然后将算出来的高度作为节点的值,这样上面一个节点的最大路径就是左节点的高度加上右节点的高度,由于我们是从下往上算的,就不需要重复算,直接读我们存的值就可以了。
3 code
class Solution {
public:
int ans;
//后序遍历
int depth(TreeNode* node)
{
if(!node) return 0;
int L=depth(node->left);
int R = depth(node->right);
//后序遍历,最大深度
int dep = max(L,R)+1;
//用ans变量记录最长距离,为左右子树的最大深度之和
ans = max(ans,L+R+1);
//返回最大深度
return dep;
}
int diameterOfBinaryTree(TreeNode* root)
{
ans=1;
depth(root);
return ans-1;
}
};
六、102. 二叉树的层序遍历
1 题目
2 解题思路
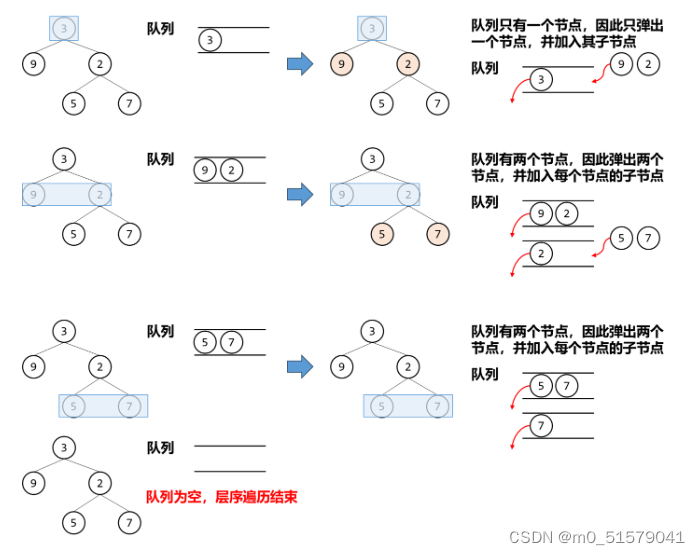
对二叉树的层序遍历,其实是广度优先搜索的一种表现形式。
假设我们已经维护了某一层的节点,当我们在遍历这一层节点的时候,这一层所有节点的子节点即为下一层要遍历的节点。
因此我们在遍历这一层节点的同时,还需要把其子节点(如果存在的话)储存起来作为下一层遍历的节点。由于这一层先遍历到的节点,其子节点先储存并且在下一层也应该是先遍历到的。即符合“ 先入先出 ”,应该使用 队列 进行存储。
因此我们一边从队首中弹出当前层的节点进行遍历,一边把下一层的节点加入队尾作为下一层遍历的节点。由于队列中的节点个数始终在变,因此我们应该明确这一层节点和下一层节点的交界。
很明显,当我们遍历完一层时,队列中的节点应该全是下一层遍历的节点。因此在下一层开始遍历之前,我们先记录队列中的节点个数,一旦弹出的节点个数达到记录值,这一层遍历结束。
初始的时候,我们把根节点入队,队列中储存第一层的唯一元素。
3 code
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root)
{
//所有层结果
vector<vector<int>> ret;
if(root==nullptr) return ret;
queue<TreeNode*> que;
que.push(root);
while(!que.empty())
{
//一层结果
vector<int> tmp;
int sz=que.size();
while(sz--)
{
TreeNode* node_ =que.front();
que.pop();
tmp.push_back(node_->val);
if(node_->left) que.push(node_->left);
if(node_->right) que.push(node_->right);
}
ret.push_back(tmp);
}
return ret;
}
};
七、102. 二叉树的层序遍历
1 题目
2 解题思路
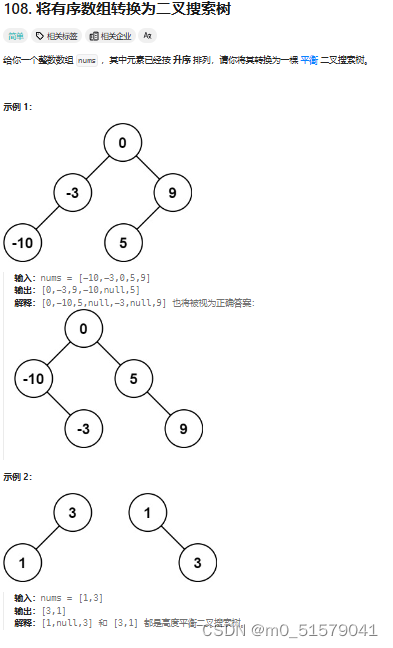
这道题要根据给定的升序数组构造一个二叉搜索树。
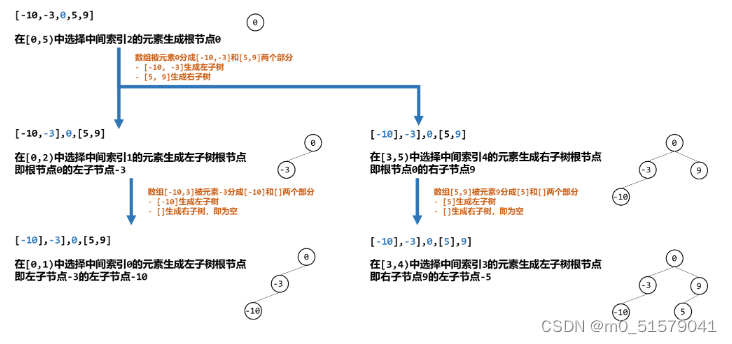
二叉搜索树的特征是:对于树上的任意一个节点,其左子树的所有节点值都小于它,其右子树的所有节点值都大于它。而给定数组 nums 是一个严格递增的数组,对于其中任意一个数字,其左侧的数字都小于它,其右侧的数字都大于它。

因此我们可以选择数组 [0, n) 中任意一个元素 nums[i] 作为根节点,那么其左子树就由 [0, i) 的 nums 的元素值构成,其右子树就由 [i+1, n) 的 nums 的元素值构成。
而对于左子树 [0, i) 或者右子树 [i+1, n) 要选择一个元素作为子树的根节点,其方法与上述生成整棵树的根节点的方法一致。
分治
现在问题就是选择范围里哪个元素作为根节点?
题目要求得到一棵高度平衡的二叉搜索树,即任意一个节点的左右子树高度差绝对值不超过1。我们可以假设绝对一点,根节点的左右子树都是链式结构,那么左右子树的高度就是左右子树节点个数。要使高度差绝对值不超过 1,即 左右子树的节点数差值绝对值不超过 1。
而左右子树的节点数就对应选取元素两侧的元素数,因此应该选择 [0, n) 的中点坐标 n / 2 (结果向下取整) 作为根节点:
- n 为奇数,n / 2 刚好中间元素的索引,左右区间的元素个数相等;
- n 为偶数,n / 2 为中间两个元素靠右的那个元素,左区间比右区间多一个元素。
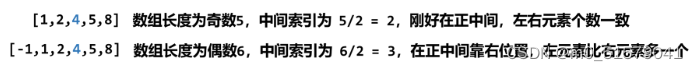
而对于根节点的左右子树,我们可以以同样的策略生成子树的根节点,作为根节点的左子节点和右子节点。即我们每次对区间 [left, right) 的元素构建子树。当区间不存在时(left > right),即为递归终点
3 code
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution
{
public:
TreeNode* buildTree(vector<int>& nums, int left,int right)
{
if(left>=right) return nullptr;
int mid=left+((right-left)>>1);
//创建根节点并递归生成子树
return new TreeNode(nums[mid],buildTree(nums,left,mid),buildTree(nums,mid+1,right));
}
TreeNode* sortedArrayToBST(vector<int>& nums)
{
return buildTree(nums,0,nums.size());
}
};
八、98. 验证二叉搜索树
1 题目
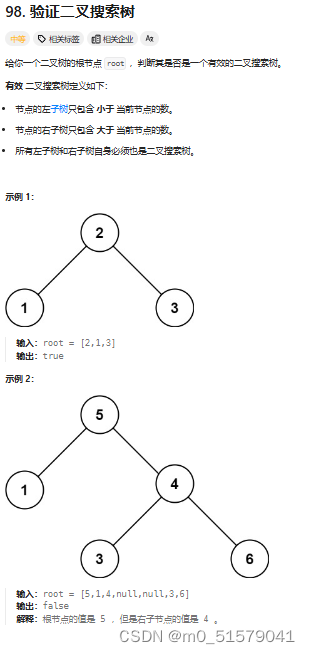
2 解题思路
首先我们要知道的一点:二叉搜索树的中序遍历的结果是一个升序序列。【二叉搜索树任意一个节点的左子树的节点值都小于当前节点,其右子树的节点值都大于当前节点。而中序遍历刚好是先处理左子树再处理当前节点最后处理右子树】
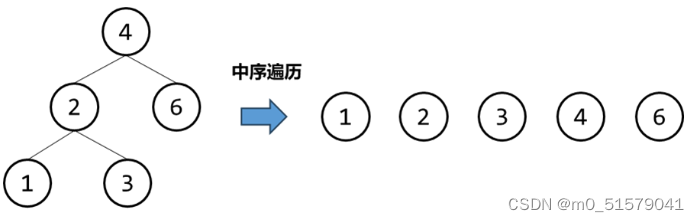
根据 中序遍历 的处理策略,我们 只需要替换对当前节点的处理策略,即在完成对二叉搜索树的中序遍历同时进行其他操作。
对于这道题,我们要判断二叉树是否是一颗二叉搜索树,而二叉搜索树的中序遍历是一个升序序列。因此我们可以判断当前节点的值是否大于前一个遍历节点的值,满足了说明这个节点是满足二叉搜索树条件的,否则就不满足。
即我们记录上一个遍历节点的值,对当前节点的处理策略就是比较当前节点值和上一个节点值,前者大于后者即为满足条件。
类似题目
530.二叉搜索树的最小绝对差
230. 二叉搜索树中第K小的元素
代码
由于首个节点没有上一个节点,为了统一计算,我们可以初始上一个节点为一个极小值,这样首个节点更新时,其与上一个节点的差值将是一个极大值,从而不会影响最小绝对差的更新。
这道题节点的取值范围为int,因此我们可以使用更大的数据类型 long 来获得最小值。
3 code
/**
-
Definition for a binary tree node.
-
struct TreeNode {
-
int val; -
TreeNode *left; -
TreeNode *right; -
TreeNode() : val(0), left(nullptr), right(nullptr) {} -
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} -
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} -
};
/
class Solution {
private:
long long lastVal=LONG_MIN;
bool ret=true;
//中序遍历
bool dfs(TreeNode node)
{
if(!node) return true;//左 if(!dfs(node->left) || lastVal>=node->val) return false; //中 lastVal=node->val; //右 bool xx=dfs(node->right); return xx;};
public:
bool isValidBST(TreeNode* root)
{
ret=dfs(root);
return ret;
}
};
# 九、230. 二叉搜索树中第K小的元素
## 1 题目
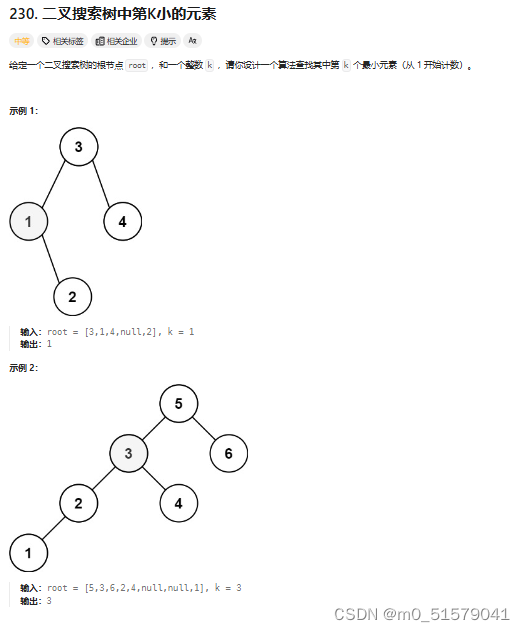
## 2 解题思路
首先我们要知道的一点:二叉搜索树的中序遍历的结果是一个升序序列。【二叉搜索树任意一个节点的左子树的节点值都小于当前节点,其右子树的节点值都大于当前节点。而中序遍历刚好是先处理左子树再处理当前节点最后处理右子树】

根据 中序遍历 的处理策略,我们 只需要替换对当前节点的处理策略,即可完成对二叉搜索树的中序遍历。
对当前节点的处理策略就是我们要记录当前遍历到的节点是第几个节点,如果遍历到第 k 个节点则返回当前节点的值。因此我们需要一个变量统计遍历到第几个节点。
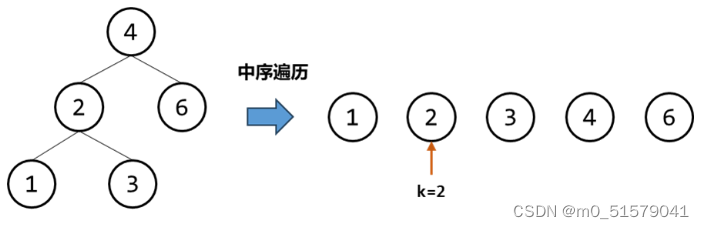
## 3 code
```cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
//统计遍历的节点个数
int cnt=0;
//存储第k小的节点值
int res=-1;
void dfs(TreeNode* node,int k)
{
if(!node) return;
//左
dfs(node->left,k);
//中
//业务逻辑
//如果遍历的节点树到达k,说明这个节点就是第k小的节点
if(++cnt==k)
{
res=node->val;
return;
}
//右
dfs(node->right,k);
}
public:
int kthSmallest(TreeNode* root, int k) {
dfs(root,k);
return res;
}
};
九、199. 二叉树的右视图
1 题目
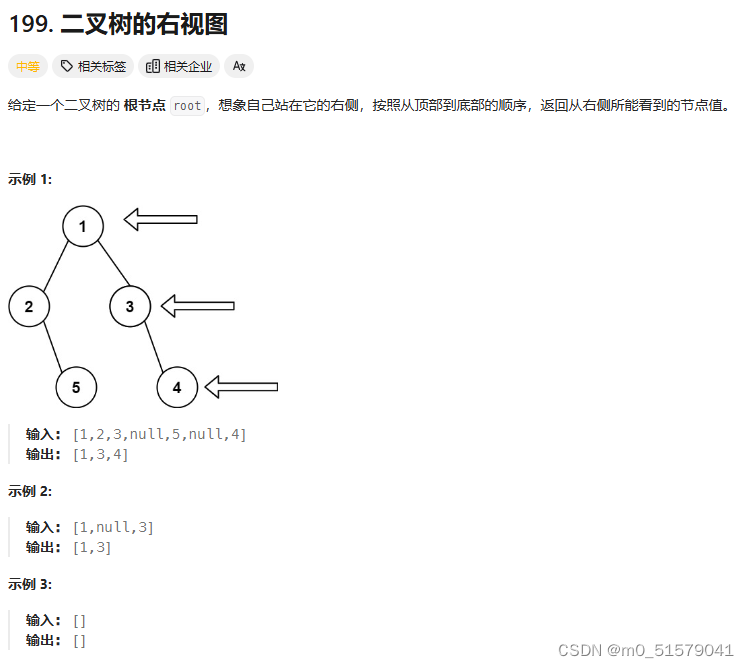
2 解题思路
(1)从顶部到底部,说明要使用BFS广度优先搜索
(2)最右侧的值可以通过一个成员变量来维护
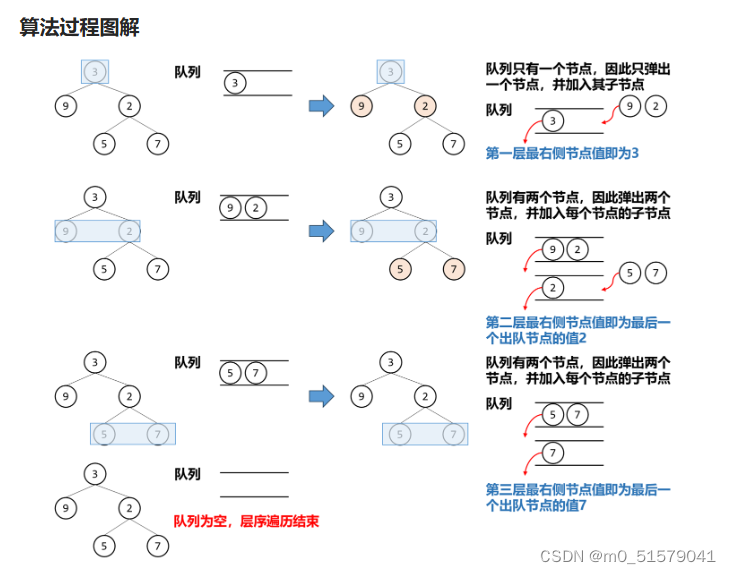
3 code
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
vector<int> ret;
if(root)
{
queue<TreeNode*> que;
que.push(root);
while(!que.empty())
{
int size=que.size();
while(size--)
{
//1.取当前层的
auto node=que.front();
que.pop();
//2.让入下一层的
//左
if(node->left) que.push(node->left);
//右
if(node->right) que.push(node->right);
//中
//3.业务逻辑
//加入每一层的最后一个节点
if(size==0) ret.push_back(node->val);
}
}
}
return ret;
}
};
十、114. 二叉树展开为链表
1 题目

2 解题思路
这道题咋一看思路比较简单,就是根据二叉树前序遍历的顺序,将节点依次串起来。
我们可以使用一个节点node表示当前展开后链表的尾部节点。那么我们每遍历到一个节点,只要把节点追加到node的尾部即可。
先序遍历(前序遍历)的遍历顺序为:中左右【即先处理当前节点,再依次处理其左子节点和右子节点】
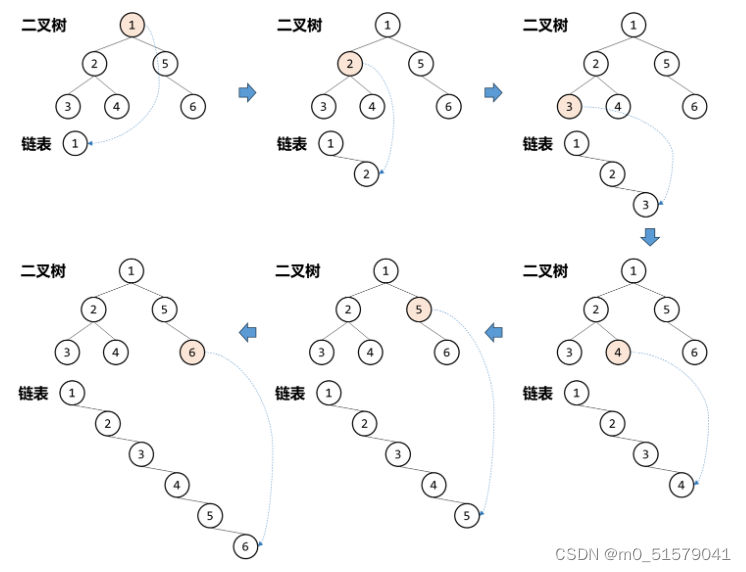
但是这其中有个问题,展开链表的各个节点是通过right进行来连接的。因此在展开的过程中,部分节点的right被更新,导致原有的右子树信息丢失而无法进行正确的前序遍历。【如上图的节点1,其右子树还没有遍历,其右子节点已经变成了节点2】
因此我们在进行递归之前,需要对当前节点的右子树进行暂存。保证在左子树递归后,该节点的右子树信息还能找到,从而进行右子树的递归。
3 code
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution
{
public:
//展开后的单链表应该同样使用TreeNode
TreeNode* listnode;
void dfs(TreeNode* node)
{
if(!node) return;
//中
//业务逻辑
if(!listnode)
{//链表为空
listnode=node;
}
else
{//链表不为空
//链表左节点置空
listnode->left=nullptr;
//链表右节点更新
//赋值:相当于head.next
listnode->right=node;
//移动:相当于head=head.next
listnode=listnode->right;
}
//暂存节点的右子树,避免递归过程中右子树信息丢失
TreeNode* tmp = node->right;
//左
dfs(node->left);
//右
flatten(tmp);
}
//前序遍历
void flatten(TreeNode* root)
{
dfs(root);
}
};
十一、105. 从前序和中序遍历序列构造二叉树
1 题目
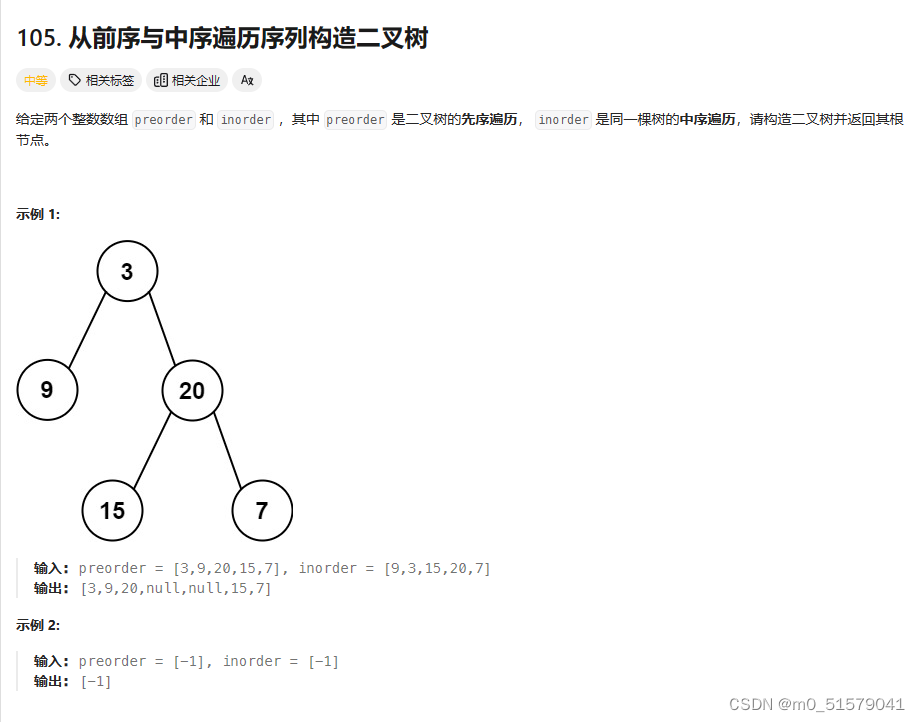
2 解题思路
首先明确:
前序遍历的遍历顺序为:【根左右——先处理当前节点,再处理左子节点,最后处理右子节点】;
中序遍历的遍历顺序为:【左根右——先处理左子节点,再处理当前节点,最后处理右子节点】
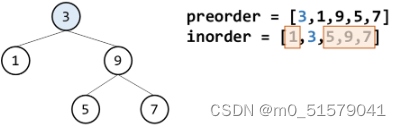
前序遍历其实是深度优先搜索,沿着一条路径遍历直到一个叶子节点。因此前序遍历数组中的首个节点一定是根节点,然后依次是其左子树的节点和右子树的节点。
我们以深度优先搜索的方式生成二叉树,通过遍历前序遍历数组获得每一个节点的值。但问题在于通过前序遍历数组我们只能定位根节点,而其他节点并无法明确其是上一个节点的左子节点还是右子节点。
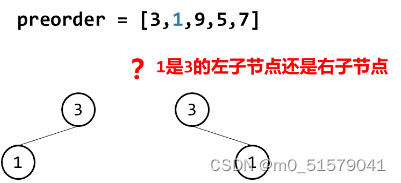
而从前序遍历数组中定位到中序遍历数组中根节点的位置,我们可以看到在中序遍历数组中:根节点左侧一定是其左子树节点,右侧一定是其右子树节点。
那么我们从前序遍历数组中获取下一个节点值时,只要判断其是在根节点的左侧还是右侧即可判断其是哪个子树的节点。

换句话说,当前前序遍历数组的值val如果属于上一个值的左侧,那么就是上一个节点的左子节点,否则左子节点为空;如果属于上一个值的右侧,那么就是上一个节点的右子节点,否则右子节点为空。
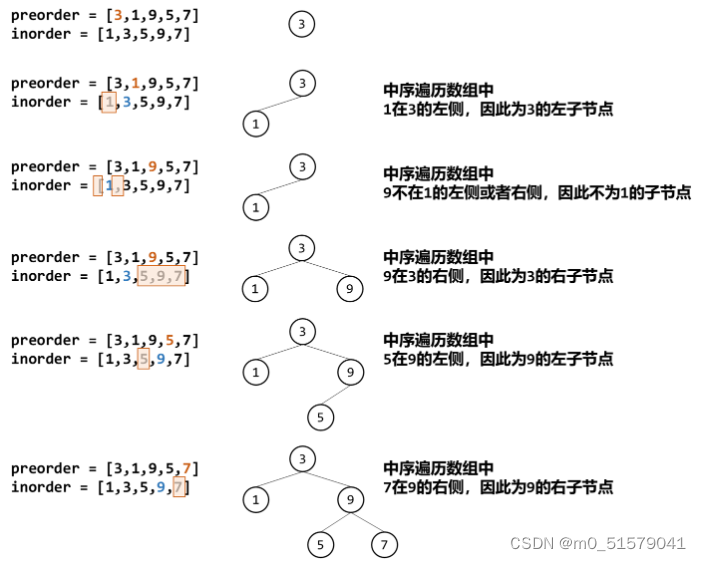
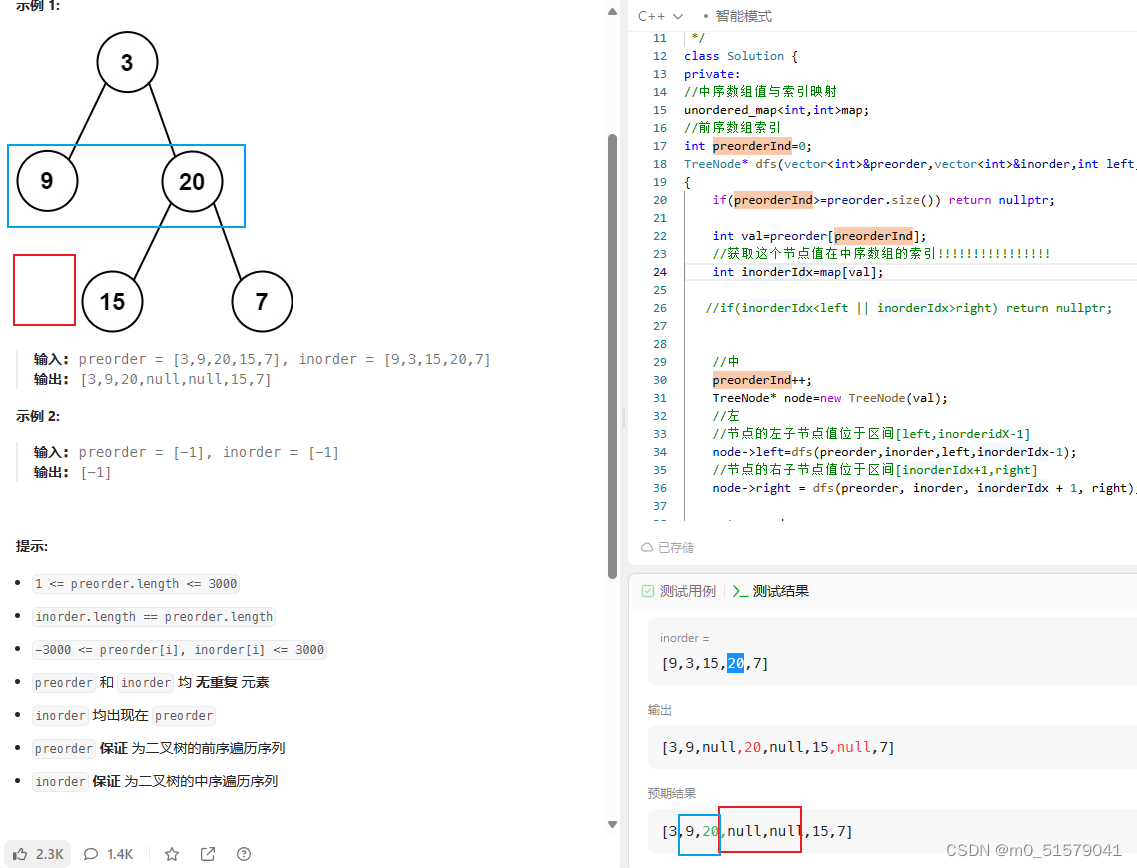
3 code
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
//中序数组值与索引映射
unordered_map<int,int>map;
//前序数组索引
int preorderInd=0;
TreeNode* dfs(vector<int>&preorder,vector<int>&inorder,int left,int right)
{
if(preorderInd>=preorder.size()) return nullptr;
int val=preorder[preorderInd];
//获取这个节点值在中序数组的索引
int inorderIdx=map[val];
if(inorderIdx<left || inorderIdx>right) return nullptr;
//思考一下这里为什么是new,因为返回二叉树就行
TreeNode* node=new TreeNode(val);
preorderInd++;
//左
//节点的左子节点值位于区间[left,inorderidX-1]
node->left=dfs(preorder,inorder,left,inorderIdx-1);
//节点的右子节点值位于区间[inorderIdx+1,right]
node->right = dfs(preorder, inorder, inorderIdx + 1, right);
return node;
}
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int n=inorder.size();
for(int i=0;i<n;i++)
{
map[inorder[i]] = i;
}
return dfs(preorder,inorder,0,n-1);
}
};
十二、437. 路径总和③
1 题目
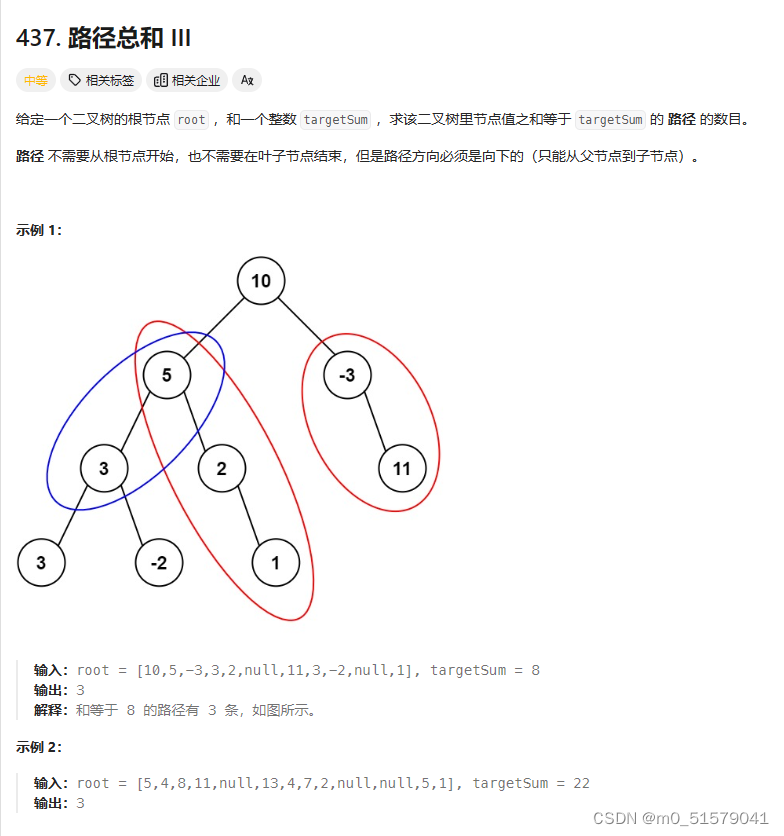
2 解题思路
问题分类
二叉树路径的问题大致可以分为两类:
1、自顶向下:
顾名思义,就是从某一个节点(不一定是根节点),从上向下寻找路径,到某一个节点(不一定是叶节点)结束
具体题目如下:
257. 二叉树的所有路径
面试题 04.12. 求和路径
112. 路径总和
113. 路径总和 II
437. 路径总和 III
988. 从叶结点开始的最小字符串
而继续细分的话还可以分成一般路径与给定和的路径
2、非自顶向下:
就是从任意节点到任意节点的路径,不需要自顶向下
124. 二叉树中的最大路径和
687. 最长同值路径
543. 二叉树的直径
解题模板
这类题通常用深度优先搜索(DFS)和广度优先搜索(BFS)解决,BFS较DFS繁琐,这里为了简洁只展现DFS代码
一般路径:
vector<vector<int>>res;
void dfs(TreeNode*root,vector<int>path)
{
if(!root) return; //根节点为空直接返回
path.push_back(root->val); //作出选择
if(!root->left && !root->right) //如果到叶节点
{
res.push_back(path);
return;
}
dfs(root->left,path); //继续递归
dfs(root->right,path);
}
# **给定和的路径:**
void dfs(TreeNode*root, int sum, vector<int> path)
{
if (!root)
return;
sum -= root->val;
path.push_back(root->val);
if (!root->left && !root->right && sum == 0)
{
res.push_back(path);
return;
}
dfs(root->left, sum, path);
dfs(root->right, sum, path);
}
这类题型DFS注意点:
1、如果是找路径和等于给定target的路径的,那么可以不用新增一个临时变量cursum来判断当前路径和,
只需要用给定和target减去节点值,最终结束条件判断target==0即可
2、是否要回溯:二叉树的问题大部分是不需要回溯的,原因如下:
二叉树的递归部分:dfs(root->left),dfs(root->right)已经把可能的路径穷尽了,
因此到任意叶节点的路径只可能有一条,绝对不可能出现另外的路径也到这个满足条件的叶节点的;
而对比二维数组(例如迷宫问题)的DFS,for循环向四个方向查找每次只能朝向一个方向,并没有穷尽路径,
因此某一个满足条件的点可能是有多条路径到该点的
并且visited数组标记已经走过的路径是会受到另外路径是否访问的影响,这时候必须回溯
3、找到路径后是否要return:
取决于题目是否要求找到叶节点满足条件的路径,如果必须到叶节点,那么就要return;
但如果是到任意节点都可以,那么必不能return,因为这条路径下面还可能有更深的路径满足条件,还要在此基础上继续递归
4、是否要双重递归(即调用根节点的dfs函数后,继续调用根左右节点的pathsum函数):看题目要不要求从根节点开始的,还是从任意节点开始
二、非自顶而下:
这类题目一般解题思路如下:
设计一个辅助函数maxpath,调用自身求出以一个节点为根节点的左侧最长路径left和右侧最长路径right,那么经过该节点的最长路径就是left+right
接着只需要从根节点开始dfs,不断比较更新全局变量即可
int res=0;
int maxPath(TreeNode *root) //以root为路径起始点的最长路径
{
if (!root)
return 0;
int left=maxPath(root->left);
int right=maxPath(root->right);
res = max(res, left + right + root->val); //更新全局变量
return max(left, right); //返回左右路径较长者
}
这类题型DFS注意点:
1、left,right代表的含义要根据题目所求设置,比如最长路径、最大路径和等等
2、全局变量res的初值设置是0还是INT_MIN要看题目节点是否存在负值,如果存在就用INT_MIN,否则就是0
3、注意两点之间路径为1,因此一个点是不能构成路径的
3 code
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
int ans=0;
//因为是给的胡和,所以要传进去
void dfs(TreeNode* root,int sum)
{
if(!root) return;
//root
sum-=root->val;
//task logit
if(sum==0) ans++;
//left
dfs(root->left,sum);
//right
dfs(root->right,sum);
}
public:
//双重递归:先调用dfs函数从root开始查找路径,再调用pathsum函数到root左右子树开始查找
int pathSum(TreeNode* root, int targetSum) {
if(!root) return ans;
dfs(root,targetSum);
dfs(root->left,targetSum);
dfs(root->right,targetSum);
return ans;
}
};
十三、437. 路径总和③
1 题目

2 解题思路
这道题要找两个目标节点的最近公共祖先。首先我们要明确两个节点的最近公共祖先应该满足什么条件:
要么这个节点的左右子树分别包含一个目标节点;
要么这个节点就是其中一个目标节点,且其某个子树包含另一个目标节点。
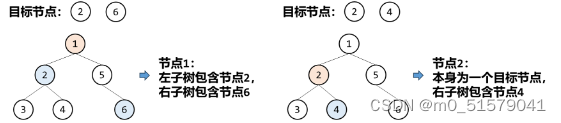
因此我们需要递归查找以每个节点为根的子树是否包含目标节点,包含节点的情况有两种:
节点本身为目标节点其中一个;
节点的左子树或右子树包含目标节点;
即节点 node 对目标节点的包含状态 isContains(node) 的状态转移为:
isContains(node) = node.val == p.val || node.val == q.val || isContains(node.left) || isContains(node.right)
即我们先要获取每个节点的左右子节点的状态,才能得到当前节点的状态,即遍历顺序为 “左右中”, 为后序遍历。
算法过程示例图
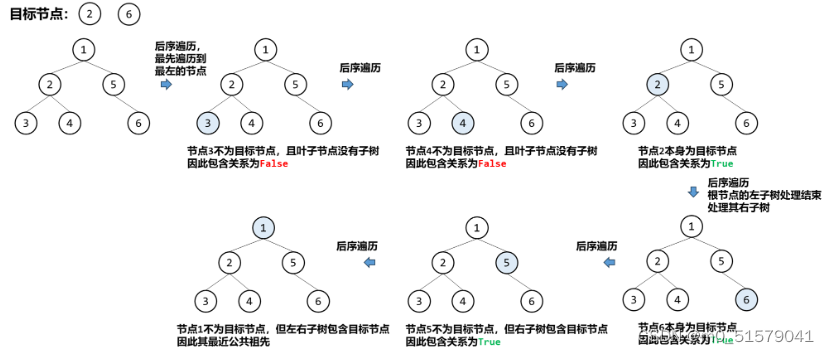
3 code
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
private:
TreeNode* ancestor;
bool checkContainNode(TreeNode* root,TreeNode* p,TreeNode* q)
{
if(!root) return false;
//递归查找左子树是否包含
bool isLeftContains =checkContainNode(root->left,p,q);
//递归查找右子树是否包含
bool isRightContains =checkContainNode(root->right,p,q);
//后续遍历
//根
if((isLeftContains && isRightContains)|| (root->val ==p->val || root->val ==q->val)
&& (isLeftContains || isRightContains))
{
this->ancestor=root;
}
// 返回包含状态,只要当前节点自己是p或q或者子树包含p或q,则包含
return root->val == p->val || root->val == q->val || isLeftContains || isRightContains;
}
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
//从根节点开始递归搜索对节点p,q的包含状态
checkContainNode(root,p,q);
return this->ancestor;
}
};

















 1295
1295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











