







1 R-FCN介绍及一些前向知识
R-FCN(
Region-based Fully Convolutional Network
, 基于区域的全卷积网络)
1.1 前面介绍及问题
1 Fast R-CNN网络中引入RoI Pooling的主要目的是因为网络中存在全连接层,所以需要通过特定的池化操作将不同尺度的proposal转换为相同维度的特征属性。
2 在ResNet、GoogleNet等分类网络中,会将全连接转换为全卷积,也就是存在全卷积化的趋势。
3 NOTE: 如果简单的在目标检测网络中也使用全卷积网络来代替全连接网络,检测效果会很差(会丢失全连接的融合特征和特征映射功能)。
1.2 位置不变性和位置可变性
1 位置不变性(Location Invariance)
:无论这个物体出现在图中的那个位置,均可以分类为对应的类别。
2
位置可变性(Location Variance):在目标检测中,任务的希望是学习到物体的具体位置信息,也就是如果这个物体出现上左上角,那么就需要在左上角画一个框。
卷积层越深,不变性越强,但是可变性就较差(多层卷积+池化后,feature map非常小,物体的移动是没办法感知到的)
R FCN就是为了解决位置不变性和位置可变性之间权衡关系的一种方式。
2 R-FCN具体结构和流程
2.1 具体结构和部分流程讲解
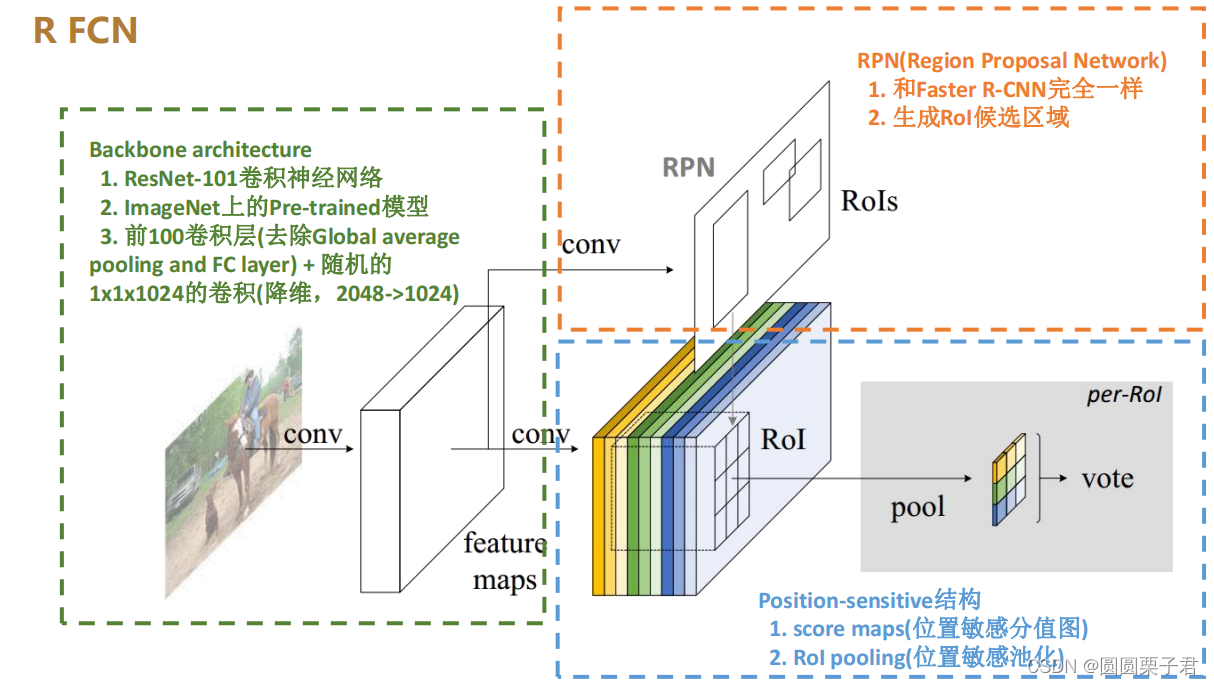
上述结构就是说,将一张图片放入ResNet-101中,只进行卷积,去除100层后面的池化和全连接,然后进行1x1卷积从2048降维到1024,得到特征图后,分两个部分,一部分卷积到RPN中,另一部分卷积成得分图即 后续 Position-sensitive 结构,这一部分在后面描述
2.2 Position-sensitive Score Maps(位置敏感分值图)
也可以称之为得分图

特殊的卷积层,对于Backbone architecture(即在2.1中的步骤
)输出的feature maps进行特殊化卷积操作,比如输出feature maps格式为[N,1024, H, W],经过一个 [1,1,1024,K^2*(C+1)]的卷积操作,最终输出的大小为[N, K^2*(C+1), H, W]的score maps。
C为类别数目,N为批次大小,H和W为feature map尺寸大小,K为相对位置的长宽区间大小。
这个分值图可以理解为feature maps的各个坐标点属于这个类别对应区域(上左、上中、上右、中左、中中、中右、下左、下中、下右)的概率值。
上述只是一个介绍参数,具体解释请看下面
输出feature maps格式为[N,1024, H, W],经过一个 [1,1,1024,K^2*(C+1)]的卷积操作,最终输出的大小为[N, K^2*(C+1), H, W]的score maps。其中,从1024个通道卷积到K^2*(C+1)个通道,代表着,被分成了C+1个组,每个组有K^2的通道,其中这每一个通道都代表了位置,如上图所示,共有K^2个通道,分别代表了区域(上左、上中、上右、中左、中中、中右、下左、下中、下右)的概率值。就是说,比如有猫狗人三个类别,加上背景有四个类别,那么四个类别经过卷积,每一个类别都有K^2个通道,代表了不同位置上是这个类别的概率值。
2.3 Position-sensitive RoI Pooling(位置敏感池化)

1 将w*h尺寸的RoI拆分为K*K个w/k * h/k尺寸的bin(bin就是上述图片的每一个网格)不同(颜色)bin对应对应位置(和bin相同颜色)的通道 层(score map)
2 Bin内做均值池化
3 输出尺寸大小为k*k*(C+1)
上述只是介绍,下面是具体解释
上面看不明白不用管,RoI就是RPN生成的候选区域,对于每个 RoI,它首先被逻辑上划分为 3×3 网格(假设 K=3)。这个划分是为了在后续处理中从每个网格中提取特征,以便进行位置敏感的分类。然后对于每个网格,就是bin,其实这只是逻辑划分,在得分图实际位置中,RoI对应的有具体的区域,每一个bin对应的是对应的得分图实际位置,比如对于 RoI 的左上角 bin,对应得分图中左上角位置的通道,理解就行,还有一个要注意,每一个Roi进来对应的只是KxK网格,是每个类别都是对应KxK网格,就是每个位置上的概率,比如说猫,一个RoI进来,预测是猫RoI的KxK个网格里写着每个位置为猫的概率,最后求平均,其他类别也是一样。
就是说如果输入的roi的尺寸和位置对应在得分图上的尺寸为右上角的9x9区域,那么得分图会提取出来这位于得分图9x9区域的信息,然后基于这个区域,把roi划分为逻辑上C+1个3x3网格,每一个网格对应右上,中上,左上等一系列的位置的,对应于得分图的3x3的一个小部分,提取每一个得分图的3x3的区域的特征,来给逻辑上C+1个3x3的网格进行概率预测,对应的是每个位置的每个类别的概率值
上述来说,就是对逻辑划分的3x3网格进行预测概率的时候,是对每个网格在得分图对应的真实位置进行池化,比如上述的roi对应的得分图的是某个9x9区域,在一个网格的时候,则会对得分图中的一个对应的3x3区域进行池化,例如最大池化,得出这个得分图中3x3区域的一个最大值
对于每个 RoI,它首先被逻辑上划分为 3×3 网格(假设 K=3)。然后,针对这个 RoI 的每个网格(或称为 bin),我们会根据 RoI 在特征图上的实际位置和大小从得分图中提取得分。这个过程是如下的:
-
RoI 网格划分:每个 RoI 在逻辑上被划分为 3×3的网格。这意味着,无论 RoI 在特征图上的实际大小如何,我们都将其视为包含 9 个 bins。
-
得分提取:
- 对于 RoI 的每个 bin,根据这个 bin 在 RoI 内的相对位置,我们会从位置敏感得分图中提取得分。得分图中的每个通道都对应于 RoI 中一个特定的位置。
- 这意味着,比如,对于 RoI 的左上角 bin,我们会从得分图中对应于左上角位置的通道提取得分;对于 RoI 中心 bin,我们会从得分图中对应于中心位置的通道提取得分,以此类推。
-
得分池化:
- 得分通常不是简单地从得分图中的单个点提取的,而是通过在得分图的相应区域进行某种池化操作(例如平均池化或最大池化)来计算的。这意味着,对于 RoI 的每个 bin,我们实际上是在得分图的一个小区域上提取得分,这个小区域对应于特征图上 RoI 的相应部分。
-
类别决定:
- 每个 bin 的得分被汇总起来(例如通过取平均),以计算该 RoI 对每个类别的得分。
- 最终,这些得分被用来决定 RoI 中包含的对象的类别。
得分聚合(voting)和 softmax 分类,计算类别概率,得分平均也可以,这样也可以

示例图

2.4 回归
上述介绍的基本都是分类,其实回归也差不多
回归就是在每个网格里对应区域对真实边框的偏移参数
在Backbone architecture输出值的基础上(1024维, [N, 1024, H, W])类似 k^2(C+1)-d Convolutional外,构建一个同级别的网络分支,也就是一个 4*k^2-d Convolutional Layer,也就是卷积输出大小为: [N, 4*k^2, H, W];
使用Position-sensitive RoI Pooling应用到每一个ROI对应的feature maps上,从而得到一个[K,K,4]大小的数据, 类似分类的过程,对K*K个值做一个均值操作(均值投票),从而得到实际预测的offset box偏移量值(4维的向量)。
2.5 损失

3 R-FCN解决的问题
R FCN的提出主要是为了解决以下两个问题的:
1 Faster R-CNN在RoI Pooling Layer后存在全连接层,那么需要对每个Region Proposal候选框均进行全连接特征提取(不共享),比较耗时;所以R FCN的提出的一个重要目的就是:
通过最大化共享计算来提升执行速度
。
2 在进行RoI Pooling Layer后置的情况下,希望能够解决模型对于位置可变性的要求,也就是引入了Position-sensitive结构,即指定不同score map是负责检测目标的不同位置。pooling后把不同位置得到的score map进行组合就能复现原来的位置信息。














 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









