






前言
该文章是跟着哔哩哔哩up主致敬大神一起学习西瓜书时记录的笔记。
一、绪论:
1、引言
通过计算的手段,利用经验来改善系统自身的性能
数据通过算法得到模型进行检测
2、基本术语
基本流程:有了数据-通过算法-得到模型-进行预测
2.1、数据
数据集:100个西瓜
样本:一个西瓜
特征向量:大小,颜色,敲动的声音, 维度 样本空间
属性:颜色,中间一个向量
2.2、算法
用来学习和训练
2.3、模型
2.3.1有监督学习(知道正确答案)
分类:二分类(Y=2,正负,干还是不干呢)、多分类(Y>2不止两种选择,买那种西瓜呢)
回归:y=r实数集,某段时间内西瓜价钱,啥时间买最合适
2.3.2无监督学习
我们不知道分几类 ,每个组成为簇。
2.4、进行预测
测试样本、泛化能力(预测没见过的样本)
3、假设空间:
科学的推理手段
3.1、归纳:特殊到一般
狭义:从训练数据中得到概念
广义:从样本中学习
3.2、演绎:一般到特殊
4、归纳偏好:
同一个训练集可能训练出来不同模型,选择其中最简单的。
二、模型评估与选择
1、一种训练集一种算法
1.1 经验误差与过拟合
首先我们要明确概念,以手写字体为例子。选10000张照片,假如其中我们预测的结果有a个错的
样本数量(m):就是我们选择的手写字体的图片数量。
样本正确的结构(Y):比如第一张是7,第二张是6
利用模型预测的样本结果(Y‘)
容错率(error rate):E=a/m
精度(accuracy):1-E
误差(error):|Y-Y'|
过拟合:在机器学习选择模型的过程中,如果一味追求提高训练数据的预测能力,所选模型的复杂度则往往会比真模型更高,这种现象被称为过拟合,过拟合是指学习时选择的模型所包含的参数过多,以至于出现这一模型对已知数据预测得很好,对未知数据预测的很差的现象。
1.2模型评估方法(训练验证集与测试集)
泛化能力:即模型对没有见过的数据的预测能力,训练集vs测试集
1.2.1训练集(training set)
1.2.2测试集(testing set):
测试集的保留方法:
------留出法:三七分、二八分,但是要注意训练集和测试集同分布(错误示范,一共有十年数据,前七年训练,后三年测试。) 或者随机进行多次划分,训练出多个模型,最后取平均值。
直接将数据集D划分为两个互斥的集合,一个作为训练集S,另一个作为测试集 T,即 D=S∪T,S∩T=∅。
-------K折交叉验证:随机将样本拆分成K个互不相交大小相同的子集,然后用K-1个子集作为训练集训练模型,用剩余的子集测试模型,对K中选择重复进行,最终选出K次测评中的平均测试误差最小的模型。常用的k值有 5、10、20等
---------自助法:留出法每次从数据集 D 中抽取一个样本加入数据集 D′ 中,然后再将该样本放回到原数据集 D 中,即 D 中的样本可以被重复抽取。这样,D 中的一部分样本会被多次抽到,而另一部分样本从未被抽到。假设抽取 m 次,则在 m 次抽样中都没有被抽到的概率为 (1−1/m)m,取极限有:
也就是说,原数据集 D 中约 36.8% 的数据未在 D′ 中出现过,所以我们可以将 D′ 作为训练集,将 D−D′(D 与 D′ 的差集)作为测试集
1.2.3validation set 验证集:
是一些我们已经知道输入和输出的数据集,通过让机器学习去优化调整模型的参数,在神经网络中, 我们用验证数据集去寻找最优的网络深度(number of hidden layers)
为什么验证数据集和测试数据集两者都需要?
因为验证数据集(Validation Set)用来调整模型参数从而选择最优模型,模型本身已经同时知道了输入和输出,所以从验证数据集上得出的误差(Error)会有偏差(Bias)。
但是我们只用测试数据集(Test Set) 去评估模型的表现,并不会去调整优化模型。
1.3性能度量(performance management):
描述:
均方误差:回归任务最常用的性能度量是“均方误差”

错误率与精度:

查全率查准率:
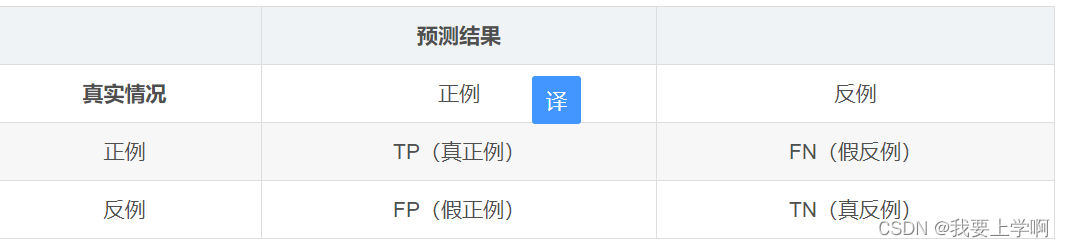
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive),假正例(false positive),真反例(true negative),假反例(false negative)四种情形,其中TP+FN+FP+TN=样例总数。

2、一种训练集多种算法
【西瓜书阅读笔记】02模型评估与选择:一个训练集多种算法 + 多种训练集一种算法_Checkmate9949的博客-CSDN博客
3、多种训练集一种算法
3、1代价敏感错误率与代价曲线
















 70
70











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









