






总结上篇adaboost 学习效果并不好
XGBoost简介
XGBoost(eXtreme Gradient Boosting)是一种基于Boosting的 gradient boosting framework,它使用了一种称为“树的叠加”(tree boosting)的技术来构建模型。XGBoost 是一种高效且可扩展的 gradient boosting 算法,它在许多机器学习任务中表现出色,如分类、回归和排名等。
XGBoost 的核心思想是通过构建一系列有序的决策树来逐步改进模型,每个树都尝试纠正前一个树的错误。这种方法通常可以提高模型的准确性,同时减少过拟合的风险。XGBoost 的主要特点包括:
- 支持并行和分布式计算,可以在多个 CPU 或 GPU 核心上运行,提高训练速度。
- 具有高效的内存使用策略,可以在有限的内存情况下处理大规模数据。
- 提供了许多超参数来优化模型性能,如学习率、最大深度、最小样本数等。
- 支持 L1 和 L2 正则化,可以防止过拟合和减少模型复杂度。
具体实现步骤:
- 首先,将训练数据分为多个块,每个块包含一个或多个样本。
- 然后,构建第一个决策树,用于预测训练数据的标签。
- 计算第一个决策树的损失函数值,并将其记录为残差(residual)。
- 构建第二个决策树,用于预测残差。这个树的目标是最小化第一个决策树的残差。
- 计算第二个决策树的损失函数值,并将其记录为新的残差。
- 重复进行决策树的构建,直到达到预设的迭代次数或残差达到满意水平。
混淆矩阵(sklearn.metrics.confusion_matrix)
混淆矩阵(confusionmatrix)也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。
在人工智能中,混淆矩阵(confusionmatrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。混淆矩阵是通过将每个实测像元的位置和分类与分类图像中的相应位置和分类相比较计算的。
参数解析
- y_true: 是样本真实分类结果
- y_pred: 是样本预测分类结果
- labels:是所给出的类别,通过这个可对类别进行选择
- sample_weight : 样本权重
bug1:ValueError: Invalid classes inferred from unique values of y. Expected: [0 1 2 3], got [1 2 3 4]
表示你必须将分类标签处理一下,从0开始。解决办法很简单,在训练数据和预测数据使用标签编码器(lableEncoder)
代码如下:
from sklearn.preprocessing import LabelEncoder
leb=LabelEncoder()
y_train=leb.fit_transform(y_train)
xgb_module=xgb.XGBClassifier().fit(X_resample,y_resample.values)
pred=xgb_module.predict(X_test)
pred=leb.inverse_transform(pred)
real=y_test
print(f"混淆矩阵:{confusion_matrix(real,pred)}")
print(f"模型的预测正确率:{accuracy_score(real,pred)}")
print(f"模型评分为:{classification_report(real,pred)}")
bug2:ValueError: Target is multiclass but average=‘binary’. Please choose another average setting, one of [None, ‘micro’, ‘macro’, ‘weighted’].
测评模型的方法里面加一种’f1_micro’其他也可以。
代码如下:
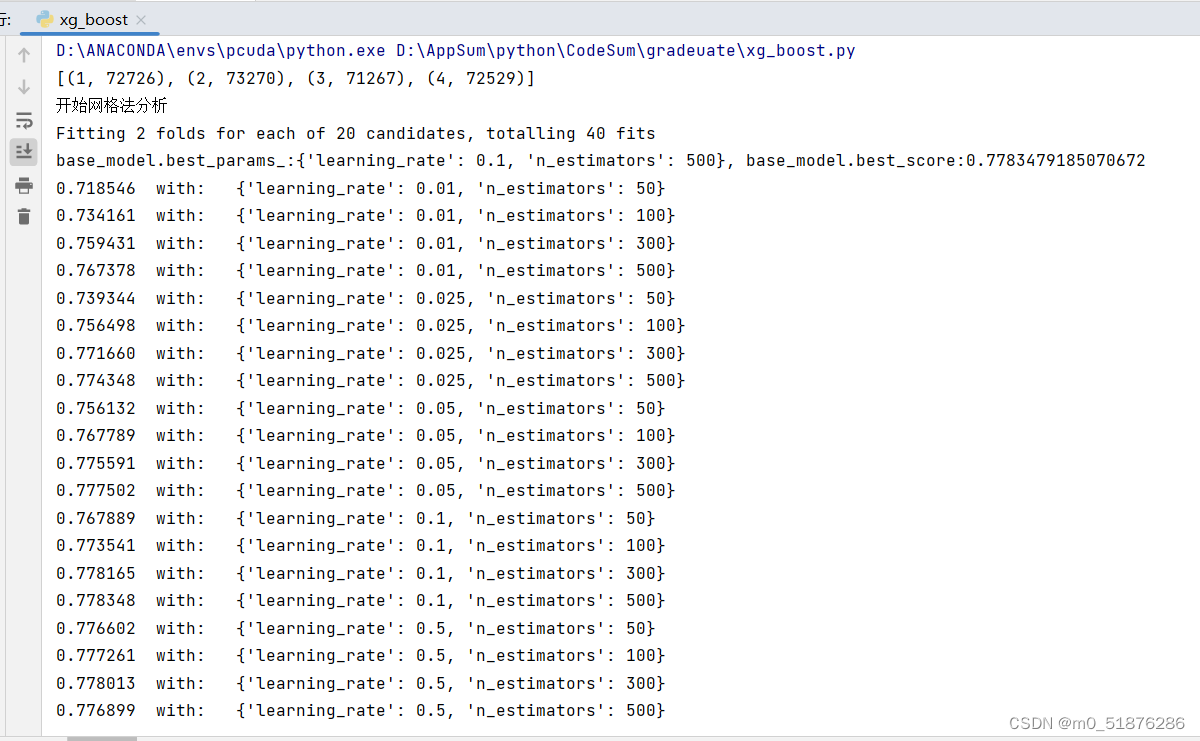
print("开始网格法分析")
clf = GridSearchCV(xgb.XGBClassifier(booster='gbtree',eval_metric='mlogloss',num_class=4,objective='multi:softmax'), param_grid=param_dict,scoring='f1_micro', cv=2, n_jobs=-1, verbose=1)
best_result=clf.fit(X_resample, y_resample)
print(f"base_model.best_params_:{best_result.best_params_}, base_model.best_score:{ best_result.best_score_}")
means = best_result.cv_results_['mean_test_score']
params = best_result.cv_results_['params']
for mean,param in zip(means,params):
print("%f with: %r" % (mean,param))
通过网格法进行参数调优
网格法上一篇介绍过了,代码如下:
param_dict = {
'n_estimators': [50,100,300,500],
'learning_rate':[0.01,0.025,0.05,0.1,0.5],
# 'max_depth': [ 23,24,25,26,27,28],
}
#xgb_module =xgb.train()
print("开始网格法分析")
clf = GridSearchCV(xgb.XGBClassifier(booster='gbtree',eval_metric='mlogloss',num_class=4,objective='multi:softmax',max_depth=26,learning_rate=0.1,n_estimators=500), param_grid=param_dict,scoring='f1_micro', cv=2, n_jobs=-1, verbose=1)
best_result=clf.fit(X_resample, y_resample)
print(f"base_model.best_params_:{best_result.best_params_}, base_model.best_score:{ best_result.best_score_}")
means = best_result.cv_results_['mean_test_score']
params = best_result.cv_results_['params']
for mean,param in zip(means,params):
print("%f with: %r" % (mean,param))
bug3:xgboost.core.XGBoostError: value 0 for Parameter num_class should be greater equal to 1 num_class: Number of output class in the multi-class classification.
原因是多分类问题,必须指定分类数,在参数里面加上就可以了。
XGBoost参数介绍
| booster | 用于指定弱学习器的类型,默认值为 ‘gbtree’,表示使用基于树的模型进行计算。还可以选择为 ‘gblinear’ 表示使用线性模型作为弱学习器。 |
|---|---|
| eta / learning_rate | 引入了"Shrinkage"的思想,即不完全信任每个弱学习器学到的残差值。为此需要给每个弱学习器拟合的残差值都乘上取值范围在(0, 1] 的 eta,设置较小的 eta 就可以多学习几个弱学习器来弥补不足的残差。 |
| gamma | 指定叶节点进行分支所需的损失减少的最小值,默认值为0。设置的值越大,模型就越保守。【0,1】 |
| alpha / reg_alpha | L1正则化权重项,增加此值将使模型更加保守。在XGBClassifier与XGBRegressor中,对应参数名为 reg_alpha 。推荐的候选值为:[0, 0.01,0.1, 0.5,1] |
| lambda / reg_lambda | L2正则化权重项,增加此值将使模型更加保守。在XGBClassifier与XGBRegressor中,对应参数名为 reg_lambda。推荐的候选值为:[0, 0.1, 0.5, 1] |
| max_depth | 指定树的最大深度,默认值为6,合理的设置可以防止过拟合。推荐的数值为:[1,3, 5, 10, 15, 17, 25,50,100]。 |
| min_child_weight | 指定孩子节点中最小的样本权重和,如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束,默认值为1。推荐的候选值为:[1,,3, 6,10] |
| subsample | 默认值1,指定采样出 subsample * n_samples 个样本用于训练弱学习器。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。 取值在(0, 1)之间,设置为1表示使用所有数据训练弱学习器。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不地 |
| colsample_bytree | 建弱学习器时,对特征随机采样的比例,默认值为1。[0.6, 0.7, 0.8, 0.9, 1] |
| objective | 用于指定学习任务及相应的学习目标,常用的可选参数值如下:“reg:linear”,线性回归(默认值)“reg:logistic”,逻辑回归。“binary:logistic”,二分类的逻辑回归问题,输出为概率。“multi:softmax”,采用softmax函数处理多分类问题,同时需要设置参数num_class用于指定类别个数 |
| num_class | 用于设置多分类问题的类别个数。 |
| eval_metric | 用于指定评估指标,可以传递各种评估方法组成的list。常用的评估指标如下:‘rmse’,用于回归任务‘mlogloss’,用于多分类任务‘error’,用于二分类任务‘auc’,用于二分类任务 |
| silent | 数值型,表示是否输出运行过程的信息,默认值为0,表示打印信息。设置为1时,不输出任何信息。 |
案例代码:乳腺癌多分类代码
import time
import joblib
import numpy as np
import pandas as pd
import xgboost as xgb
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold
from imblearn.combine import SMOTETomek
from imblearn.combine import SMOTEENN
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
## 导入数据
data=pd.read_csv("C:/Users/86152/Desktop/data.csv")
data=data[data["Breast"]<5] #处理乳腺癌类型标签,1,2,3,4类
##参数比较重要的标签
lable=['Dage', 'Dyear', 'ajcc', 'cs','rx', 'Survival.month']
X_train,X_test,y_train,y_test=train_test_split(data[lable],data.Breast,test_size=0.25,random_state=1234)
#print(X_train.shape,y_train.shape)
##数据不平衡处理
smote=SMOTETomek(random_state=0)
X_resample,y_resample=smote.fit_resample(X_train,y_train)
print("smote平衡数据:",sorted(Counter(y_resample).items()))
smoten = SMOTEENN(random_state=0)
X_resample1,y_resample1=smote.fit_resample(X_train,y_train)
print("smoten平衡数据:",sorted(Counter(y_resample1).items()))
##默认参数训练数据查看模型的表现,在两份数据上进行划分
from sklearn.preprocessing import LabelEncoder
leb=LabelEncoder()
y_resample=leb.fit_transform(y_resample)
# start_time=time.time()
# print("训练开始")
# xgbclassfier_module=xgb.XGBClassifier().fit(X_resample,y_resample)
# print(f"训练结束,训练时间为:{time.time()-start_time}")
# pred=xgbclassfier_module.predict(X_test)
# pred=leb.inverse_transform(pred)
# real=y_test
# print(f"混淆矩阵:\n{confusion_matrix(real,pred)}")
# print(f"模型的预测正确率:{accuracy_score(real,pred)}")
# print(f"模型评分为:\n{classification_report(real,pred)}")
##网格法选择最佳参数
#
# param_dict = {
# 'n_estimators': [50,100,300,500],
# 'learning_rate':[0.01,0.025,0.05,0.1,0.5],
# # 'max_depth': [ 23,24,25,26,27,28],
# }
# #xgb_module =xgb.train()
# print("开始网格法分析")
#clf = GridSearchCV(xgb.XGBClassifier(booster='gbtree',eval_metric='mlogloss',num_class=4,objective='multi:softmax',max_depth=26,learning_rate=0.1,n_estimators=500), param_grid=param_dict,scoring='f1_micro', cv=2, n_jobs=-1, verbose=1)
# best_result=clf.fit(X_resample, y_resample)
# print(f"base_model.best_params_:{best_result.best_params_}, base_model.best_score:{ best_result.best_score_}")
#
# means = best_result.cv_results_['mean_test_score']
# params = best_result.cv_results_['params']
# for mean,param in zip(means,params):
# print("%f with: %r" % (mean,param))
##开始进行模型训练,
def train_moudle(X_train,y_train,X_test,y_test):
xg_train=xgb.DMatrix(X_train,leb.fit_transform(y_train))
xg_test=xgb.DMatrix(X_test,leb.fit_transform(y_test))
param = {'max_depth':26, 'eta':0.1, 'silent':1, 'subsample':0.7, 'colsample_bytree':0.7, 'objective':'multi:softmax' ,'n_estimators':500,'eval_metric':'mlogloss','num_class':4}
watchlist = [(xg_test,'eval'), (xg_train,'train')]
num_round = 10
bst = xgb.train(param, xg_train, num_round, watchlist)
y_pred=bst.predict(xgb.DMatrix(X_test))
print(f"分类1:{sorted(Counter(y_pred).items())}")
#y_pred=leb.inverse_transform(y_pred)
real=leb.fit_transform(y_test)
print(f"分类2:{sorted(Counter(real).items())}")
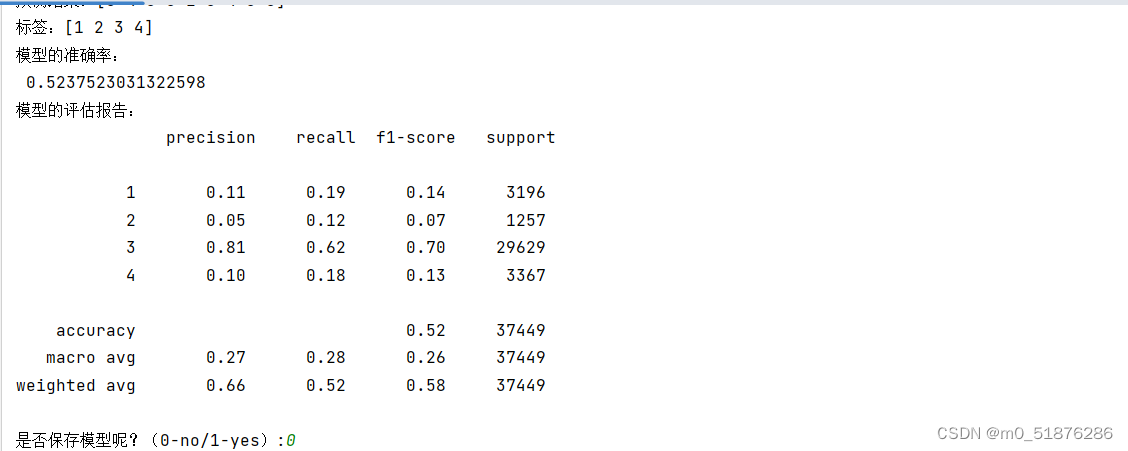
print("模型的准确率:\n",accuracy_score(real,y_pred))
print("模型的评估报告:\n",classification_report(real,y_pred))
xgb.plot_importance(bst)
print(f"标签的评分:{bst.get_score()}")
is_storage=input("是否保存模型呢?(0-no/1-yes):")
print(f"isstorage={is_storage}")
if is_storage == 1:
joblib.dump(bst,"/modle/xgb_module")
print("保存完毕")
if __name__ == "__main__" :
train_moudle(X_resample1,y_resample1,X_test,y_test)















 7594
7594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









