







目录
动量梯度下降法:让梯度下降的过程中纵向波动减小
动量梯度下降法采用累积梯度来代替当前时刻的梯度。直观来讲,动量方法类似把球推下山,球在下坡时积累动力,在途中速度越来越快,如果某些参数在连续时间内梯度方向不同,动量就会变小,反之,在连续时间内梯度方向一致,动量会增大。动量梯度下降法可以更快速的收敛并减少目标函数的震荡。
- 通过mini_batch进行神经网络的前向反馈、反向传播计算梯度dw 、db
,
,
是动量参数,通常取0.9,
为超参数,
是x轴方向的动量,
是纵向y轴方向的动量。
是梯度更新的步长。

RMSprop :消除梯度下降中的摆动
RMSprop可以自适应调整每个参数的学习率,此外,RMSprop可以客服学习率过早衰减的问题。
相较于动量梯度下降法,()后相乘的微分变为微分的平方,
是衰减系数 ,通常取0.9。
通过mini_batch计算dw db
,
较小
较大
, w逐渐变大,加快收敛速度
, b逐渐变小,消除梯度下降中的摆动
Adam 优化算法:
动量梯度下降法和RMSprop的缝合怪,可以自适应调整每个参数的学习率
通过mini_batch计算dw db
参数选择:需要调节,
,
,
用来计算平方数的指数加权平均数,
计算指数加权平均数
神经网络参数初始化

- 初始化为0:在输入参数中全部初始化为0,参数名为initialization = “zeros”,核心代码:
parameters['W' + str(l)] = np.zeros((layers_dims[l], layers_dims[l - 1]))
- 初始化为随机数:把输入参数设置为随机值,权重初始化为大的随机值。参数名为initialization = “random”,核心代码:
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * 10
- 抑梯度异常初始化:参见梯度消失和梯度爆炸的那一个视频,参数名为initialization = “he”,核心代码:
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(2 / layers_dims[l - 1])
学习率衰减
学习率衰减可以减小梯度下降到达最优点的震荡。选择合适的学习率也很重要。学习率太小导致收敛缓慢,学习率太大会阻碍收敛并导致损失函数在最小值附近波动或发散。深度网络通常采取模拟退火的方法在训练期间动态调整学习率。 模拟退火算法的学习率有包括反向衰减学习率和指数衰减学习率。
- 反衰减学习率
假设初始化学习率为 ,
是衰减系数,t是迭代次数,反向衰减可以定义为:
- 指数衰减学习率
固定衰减的模拟退火方法不能直接泛化到多个数据集上,我们也不希望采用相同的频率和步长来更新所有的网络参数,所以自适应调整学习率被提出,给每个参数设置不同的自适应学习率。
Batch Norm
实践中,为了加快学习速率,通常进行归一化
Batch Norm可以使你构造含其他平均值和方差的隐藏单元值(不止均值0 方差1),而且Batch归一化的作用是它适用的归一化过程不只是输入层
- 在网络中获得一些值
,
即网络中任意某一层的参数
由
和
两个参数控制
,
用在动量梯度下降法,RMSprop, Adam 中的不同
在神经网络中加入Batch归一化,在神经网络的正向传播过程对隐藏层的Z值进行归一,将每个隐藏层的均值和方差缩放
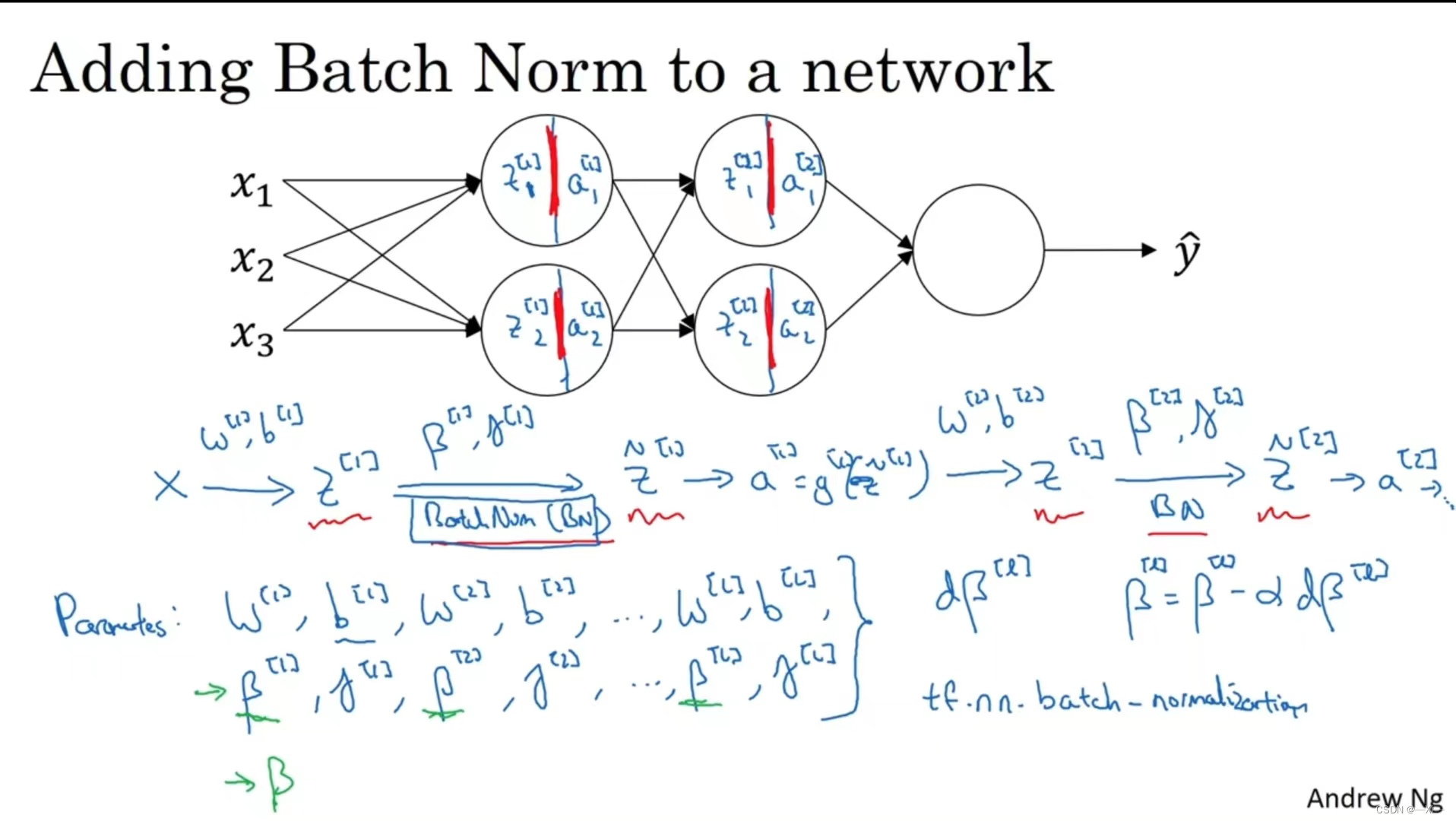

在每一个隐藏层L, 用反向传播得到,
,
,通过Batch_norm 将
转换为
。
-
,
和
的维度:(
,1)
- 并通过梯度下降来来更新由Batch归一化添加到算法中的
,
,
关于Batch_norm:
- Batch Norm减少了输入值改变的问题,减少了隐藏值分布变化的数量,输入层输入的数据改变,均值和方差不变,加快收敛和学习速率.
- 每个mini_batch进行归一化只在这个mini_batch进行
- Batch Norm 在mini_batch里的
里添加了一些噪音,像Dropout一样,在每个隐藏层的激活项添加了噪音
- Batch_norm有正则化效果
在dropout部分, 之所以dropout可以抑制overfitting, 是因为在训练阶段, 我们引入了 随机性(随机cancel一些Neuron),减少网络的匹配度, 在测试阶段, 我们去除掉随机性, 并通过期望的方式marginalize随机影响。
在BatchNormalization中, 训练阶段, 我们随机选取了Batch进行Normalization, 并计算running mean等, 在测试阶段, 应用running_mean这些训练参数来进行整体Normalization, 本质上是 在Marginalize训练阶段的随机性。 因此, BatchNormalization也提供了 Regularization的作用, 实际应用中证明, NB在防止过拟合方面确实也有相当好的表现。
Batch_norm 在测试时:

- m为mini_batch中的样本数量
- 用均值和方差来调整,加上
是为了数值稳定性,
和
是在整个mini_batch上计算出来的,再用
得到隐藏层的数值归一















 1146
1146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









