







另在一篇文章中,我们介绍了随机梯度下降的细节以及如何解决陷入局部最小值或鞍点等问题。在这篇文章中,我们看看另一个困扰神经网络训练的问题,即病态曲率。
虽然局部最小值和鞍点可以阻止我们的训练,但是病态曲率可以使训练减慢到机器学习从业者可能认为搜索已经收敛到次优极小值的程度。让我们深入了解病理曲率是什么。
病态曲率
考虑以下损失轮廓。
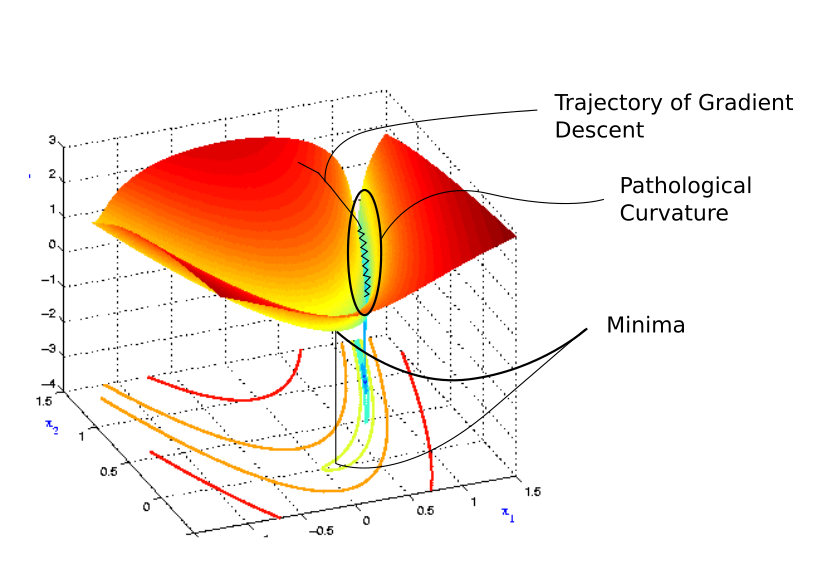
病态曲率
你看,我们在进入以蓝色标记的山沟状区域之前随机开始。颜色实际上表示损失函数在特定点处的值有多大,红色表示最大值,蓝色表示最小值。我们想要达到最小值点,为此但需要我们穿过山沟。这个区域就是所谓的病态曲率。理解要为什么它被称为病态,让我们深入研究。下图是病态曲率放大后的图像,看起来像..
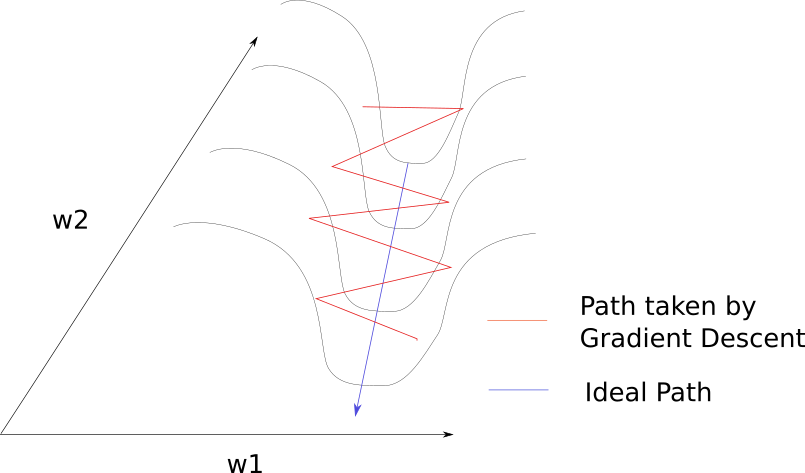
要理解这里发生的事情并不是很难。梯度下降沿着山沟的山脊反弹,向极小的方向移动较慢。这是因为脊的表面在W1方向上弯曲得更陡峭。
如下图,考虑在脊的表面上的一个点梯度。该点的梯度可以分解为两个分量,一个沿着方向w1,另一个沿着w2。梯度在w1方向上的分量要大得多,因此梯度的方向更靠近w1,而不是朝向w2(最小值位于其上)。

通常情况下,我们使用低学习率来应对这样的反复振荡,但在病态曲率区域使用低学习率,可能要花很多时间才能达到最小值处。事实上,有论文报告,防止反复振荡的足够小的学习率,也许会导致从业者相信损失完全没有改善,干脆放弃训练。
大概,我们需要找到一种方法,首先缓慢地进入病态曲率的平坦底部,然后加速往最小值方向移动。二阶导数可以帮助我们来到来到赖这一点一一。
牛顿法
下降梯度的英文一阶优化方法。它只考虑损失函数的一阶导数而不是较高的导数。这基本上意味着它没有关于损失函数曲率的线索。它可以判断损失是否在下降和速度有多快,但无法区分曲线是平面,向上弯曲还是向下弯曲。

上图三条曲线,红点处的梯度都是一样的,但曲率大不一样。解决方案?考虑二阶导数,或者说梯度改变得有多快。
使用二阶导数解决这一问题的一个非常流行的技术是牛顿法(Newton's Method)。为了避免偏离本文的主题,我不会过多探究牛顿法的数学。相反,我将尝试构建牛顿法的直觉。
牛顿法可以提供向梯度方向移动的理想步幅。由于我们现在具备了损失曲面的曲率信息,步幅可以据此确定,避免越过病态曲率的底部。
牛顿法通过计算海森矩阵做到这一点.Hessian矩阵是损失函数在所有权重组合上的二阶导数的矩阵。

黑森州提供了损失曲面每一点上的曲率估计。正曲率意味着随着我们的移动,损失曲面变得不那么陡峭了。负曲率则意味着,损失曲面变得越来越陡峭了。
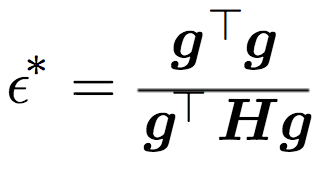
注意,如果这一步的计算结果是负的,那就意味着我们可以切换回原本的算法。这对应于下面梯度变得越来越陡峭的情形。

然而,如果梯度变得越来越平坦,那么我们也许正向病态曲率的底部移动。这时牛顿算法提供了一个修正过的学习步幅,和曲率成反比。换句话说,如果损失曲面变得不那么陡峭,学习步幅就下降。
为何我们不常使用牛顿法?
你已经看到公式中的海森矩阵了.Hessian矩阵需要我们计算损失函数在所有权重组合上的梯度。也就是说,需要做的计算的数量级是神经网络所有权重数量的平方。
现代神经网络架构的参数量可能是数亿,计算数亿的平方的梯度在算力上不可行。
虽然高阶优化方法在算力上不太可行,但二阶优化关于纳入梯度自身如何改变的想法是可以借鉴的。虽然我们无法准确计算这一信息,但我们可以基于之前梯度的信息使用启发式算法引导优化过程。(这个大家可以看看神经网络与机器学习这本书,那里有详细的讲解,当然需要你拥有很好的数学基础和理解能力)
随机梯度下降( Stochastic Gradient Descent,SGD )
SGD的学习原理很简单就是选择一条数据,就训练一条数据,然后修改权值算法过程如下:
随机梯度下降法:
给定数据集,数据集标记为:
,学习器为
,学习率
对于迭代足够多次
{
1.随机选择数据:
2.计算损失梯度:
3.修改权值:
}
SGD算法在训练过程中很有可能选择被标记错误的标记数据,或者与正常数据差异很大的数据进行训练,那么使用此数据求得梯度就会有很大的偏差,因此SGD在训练过程中会出现很强的随机现象。如何解决呢?
可以多选择几个数据在一起求梯度和,然求均值,这样做的好处是即使有某条数据存在严重缺陷,也会因为多条数据的中和而降低其错误程度。在上述的的算法中,率学习通常的英文固定的值,但是在实际中,我们通常希望学习率随着训练次数增加而减小,减小的原因上面也说了减少振荡,这里先给出一种调节学习率的公式:
上面是线性学习率调整规则,通常ķ的取值和训练次数有关,如果训练次数为上百次,则ķ要大于100,而b的值可以粗略的设置为百分之一的初始学习率,学习率初始值一般作为超参数进行设置,一般采取尝试策略。
学习率最小批量梯度下降算法
初始化:
给定数据集,数据集标记为:
,随机采样m条数据,训练周期k,学习率衰减最低值b,学习器为
,初始学习率
训练:
对于
{
1.随机采样几条数据:
2.计算采样数据平均损失梯度:
3.计算衰减学习率:
4.修改权值:
}
效果如下图

动量学习法
和SGD一起使用的非常流行的技术称为Momentum。动量也不仅使用当前步骤的梯度来指导搜索,而是累积过去步骤的梯度以确定要去的方向。那么什么是动量学习法呢?
在物理学中,动量的英文与物体的质量、速度相关的物理量。一般而言,一个物体的动量指的的是这个物体在它运动方向上保持运动的趋势。动量是矢量这里我们可以把梯度理解成力,力是有大小和方向的,而且力可以改变速度的大小和方向,并且速度可以累积。这里把权值理解成速度,当力(梯度)改变时就会有一段逐渐加速或逐渐减速的过程,我们通过引入动量就可以加速我们的学习过程,可以在鞍点处继续前行,也可以逃离一些较小的局部最优区域下面类比物理学定义这里的动量:
物理学中,用变量v表示速度,表明参数在参数空间移动的方向即速率,而代价函数的负梯度表示参数在参数空间移动的力,根据牛顿定律,动量等于质量乘以速度,而在动量学习算法中,我们假设质量的单位为1,因此速度v就可以直接当做动量了,我们同时引入超参数,其取值在【0,1】范围之间,用于调节先前梯度(力)的衰减效果,其更新方式为:
(1)
根据上面的随机梯度下降算法给出动量随机梯度下降算法;
初始化:
给定数据集,数据集标记为:
,,初始速度
,随机采样m条数据,训练周期k,学习率衰减最低值b,学习器为
,初始学习率
,初始动量参数为
训练:
对于
{
1.随机采样米条数据:
2.计算采样数据平均损失梯度:
3.更新速度:
4.更新参数:
}
在随机梯度的学习算法中,每一步的步幅都是固定的,而在动量学习算法中,每一步走多远不仅依赖于本次的梯度的大小还取决于过去的速度。速度v是累积各轮训练参的梯度,其中越大,依赖以前的梯度越大。假如每轮训练的梯度方向都是相同的,和小球从斜坡滚落,由于但衰减因子的
存在,小球并不会一直加速,而是达到最大速度后开始匀速行驶,这里假设每轮获得的梯度都是相同的,那么速度最大值为(按照(1)计算可得):
从上式可以看到当= 0.9时,最大速度相当于梯度下降的10倍(带进上式去算可得),通常
可取0.5,0.9,0.99,情况一般
的调整没有
调整的那么重要适当。取值即可。
图形如下:

好到这里大家懂了动量的学习机理,我们继续看看那篇博文:
梯度下降的方程式修改如下。

上面的第一个等式就是动量,动量等式由两部分组成,第一项是上一次迭代的动量,乘以“动量系数”。

如果我们将v的初始值设置为0并选择我们的系数为0.9,则后续更新方程式将如下所示。

我们看到,后续的更新保留了之前的梯度,但最近的梯度权重更高。
下面我们来看看动量法如何帮助我们缓解病态曲率的问题。下图中,梯度大多数发生更新在字形方向上,我们将每次更新分解为W1和W2方向上的两个分量。如果我们分别累加这些梯度的两个分量,那么W1方向上的分量将互相抵消,而W2方向上的分量得到了加强。
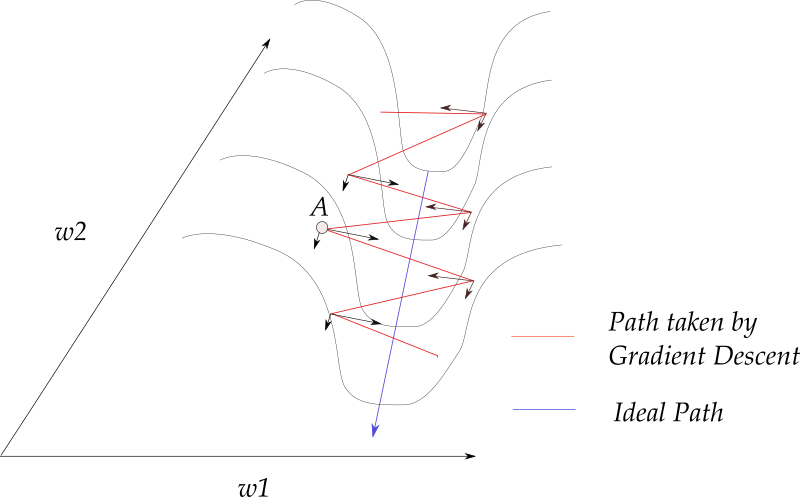
也就是说,基于动量法的更新,积累了W2方向上的分量,清空了W1方向上的分量,从而帮助我们更快地通往最小值。从这个意义上说,动量法也有助于抑制振荡。
动量法同时提供了加速度,从而加快收敛。但你可能想要搭配模拟退火,以免跳过最小值。当我们使用动量优化算法的时候,可以解决小批量SGD优化算法更新幅度摆动大的问题,同时可以使得网络的收敛速度更快。
在实践中,动量系数一般初始化为0.5,并在多个时期后逐渐退火至0.9。
AdaGrad(自适应梯度算法)
前面的随机梯度和动量随机梯度算法都是使用全局的学习率,所有的参数都是统一步伐的进行更新的,上面的例子中我们是在二维权值的情况,如果扩展到高维,大家可想而知,我么你的优化环境将很复杂,比如你走在崎岖额深山老林林,到处都是坑坑洼洼,如果只是走一步看一步(梯度下降),或者快速奔跑向前(动量学习),那我们可能会摔的头破血流,怎么办呢如果可以针对每个参数设置学习率可能会更好,让他根据情况进行调整,这里就先引出自适应梯度下降?
AdaGrad其实很简单,就是将每一维各自的历史梯度的平方叠加起来,然后更新的时候除以该历史梯度值即可。如针对第我个参数,算法如下。
定义首先一个量用于累加梯度的平方,如下:
平方的原因是去除梯度符号的干扰,防止抵消,更新时:
其中= 10 ^ -7,防止数值溢出。
从上式可以看出,AdaGrad使的参数在累积的梯度较小时()就会放大学习率,使网络训练更加快速。在梯度的累积量较大时(
)就会缩小学习率,延缓网络的训练,简单的来说,网络刚开始时学习率很大,当走完一段距离后小心翼翼,这正是我们需要的。但是这里存在一个致命的问题就是AdaGrad容易受到过去梯度的影响,陷入“过去“无法自拔,因为梯度很容易就会累积到一个很大的值,此时学习率就会被降低的很厉害,因此AdaGrad很容易过分的降低学习率率使其提前停止,怎么解决这个问题呢?RMSProp算法可以很好的解决该问题。
RMSProp(均方根支柱)
同样,RMSProp可以自动调整学习率。还有,RMSProp为每个参数选定不同的学习率。
虽然AdaGrad在理论上有些较好的性质,但是在实践中表现的并不是很好,其根本原因就是随着训练周期的增长,学习率降低的很快。而RMSProp算法就在AdaGrad基础上引入了衰减因子,如下式,RMSProp在梯度累积的时候,会对“过去”与“现在”做一个平衡,通过超参数进行调节衰减量,常用的取值为0.9或者0.5(这一做法和SGD有异曲同工之处)
参数更新阶段,和AdaGrad相同,学习率除以历史梯度总和即可。
实践中,RMSProp更新方式对深度学习网络十分有效,是深度学习的最有效的更新方式之一。
图形如下:

下面接着那篇博客看,(这里还是通过动量过来的,原理是一样的,因为都是梯度的累加。这里大家不用迷惑,当你知道本质的东西以后,就知道通过表面看本质的的意义了)

在第一个等式中,类似之前的动量法,我们计算了梯度平方的指数平均。由于我们为每个参数单独计算,这里的梯度GT表示正更新的参数上的梯度投影。
第二个等式根据指数平均决定步幅大小。我们选定一个初始学习率η,接着除以平均数。在我们上面举的例子中,W1的梯度指数平均比W2大得多,所以W1的学习步幅比W2小得多。这就帮助我们避免了脊间振荡,更快地向最小值移动。
第三个等式不过是权重更新步骤。
上面的等式中,超参数ρ一般定为0.9,但你可能需要加以调整。等式2中的ε是为了确保除数不为零,一般定为1E-10。
注意RMSProp隐式地应用了模拟退火。在向最小值移动的过程中,RMSProp会自动降低学习步幅,以免跳过最小值。
Adam(自适应动量优化)
到目前为止,我们已经看到RMSProp和动量采用对比方法。虽然动量加速了我们对最小值方向的搜索,但RMSProp阻碍了我们在振荡方向上的搜索.Adam通过名字我们就可以看出他是基于动量和RMSProp的微调版本,该方法是目前深度学习中最流行的优化方法,在默认情况尽量使用亚当作为参数的更新方式
首先计算当前最小批量数据梯度。
和动量学习法一样,计算衰减梯度五:
和RMSProp算法类似,计算衰减学习率R:
最后更新参数:
上面就是RMSProp和动量的有机集合,使他们的优点集于一身,是不是很漂亮,但还是有一个问题就是开始时梯度会很小,R和v经常会接近0,因此我们需要初始给他一个?合适的值,这个值怎么给才合适呢先看下面的公式:
其中吨表示训练次数,刚开始动很大,随着训练次数吨的增加VB逐渐趋向于V,R类似下面给出总体的算法结构。
初始化:
给定数据集,数据集标记为:
,初始速度
,随机采样m条数据,训练周期k,学习器为
,初始学习率
,初始动量参数为
,学习衰减参数
,
训练:
用于 :
{
1.随机采样米条数据:
2.计算当前采样数据的梯度:
3.更新当前速度:
4.更新当前学习率:
5.更新训练次数:
6.更新参数:
}
好,我们继续看看那篇博客:

这里,我们计算了梯度的指数平均和梯度平方的指数平均(等式1和等式2)。为了得出学习步幅,等式3在学习率上乘以梯度的平均(类似动量),除以梯度平方平均的均方根(类似RMSProp)。等式4是权重更新步骤。
超参数β1一般取0.9,β2一般取0.99.ε一般定为1E-10。
结语
本文介绍了三种应对病态曲率同时加速训练过程的梯度下降方法。
在这三种方法之中,也许动量法用得更普遍,尽管从论文上看Adam更吸引人。经验表明这三种算法都能收敛到给定损失曲面的不同的最优局部极小值。然而,动量法看起来要比Adam更容易找到比较平坦的最小值,而自适应方法(自动调整学习率)倾向于迅速地收敛于较尖的最小值。比较平坦的最小值概括性更好。

尽管这些方法有助于我们训练深度网络难以控制的损失平面,随着网络日益变深,它们开始变得不够用了。除了选择更好的优化方法,有相当多的研究试图寻找能够生成更平滑的损失曲面的架构。批量归一化(Batch Normalization)和残差连接(Residual Connections)正是这方面的两个例子。我们会在后续的文章中详细介绍它们。但这篇文章就到此为止了。欢迎在评论中提问。
进一步阅读
原博客地址:https://blog.paperspace.com/intro-to-optimization-momentum-rmsprop-adam/(需要翻墙)
这里需要说明的是,本人在那篇博客的基础上增添了SGD,动量,AdaGrad,RMSProp,亚当的算法推倒说明以及算法伪代码的实现,因此转载请注明出处,谢谢。本节到此结束,下一篇继续讲解梯度消失和激活函数的优化问题。

















 636
636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









