






目录
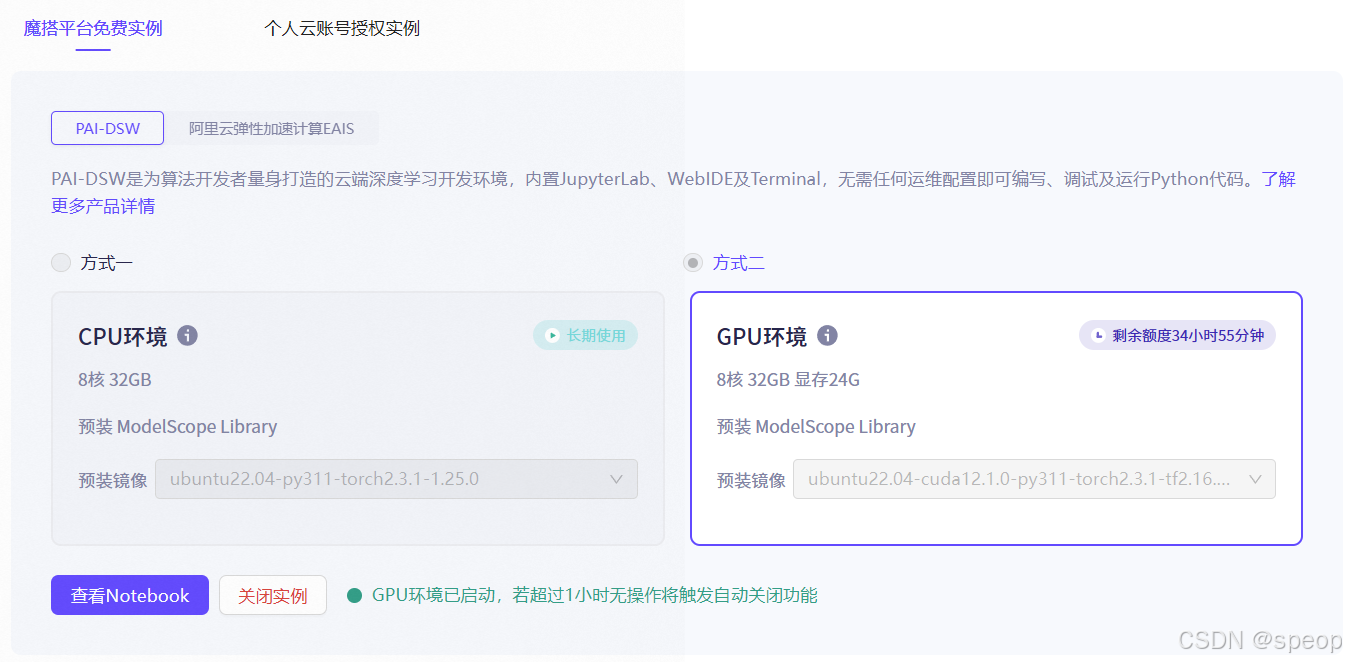
没有看清楚教程。一开始选择了第一种cpu方式运行,发现不行。然后使用了方式二可以运行
# !unzip -n data/A.zip -d data/ # -n 不覆盖已存在的文件
# !unzip -n data/train.zip -d data/
!pip install -r requirements.txt
import numpy as np
import cv2
import os
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
import time
from datetime import datetime
import torch
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
from sklearn.model_selection import StratifiedKFold
train_df = pd.read_csv("data/train.txt", sep="\t", header=None)
train_df[0] = 'data/train/' + train_df[0]
train_df
def is_valid_image(image_path):
if not os.path.exists(image_path):
return False
image = cv2.imread(image_path)
return image is not None
train_df = train_df[train_df[0].apply(is_valid_image)]
train_df
for lbl in train_df[1].value_counts().index:
img = cv2.imread(train_df[train_df[1] == lbl][0].sample(1).values[0])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.figure()
plt.imshow(img)
mapping_dict = {
'高风险': 0,
'中风险': 1,
'低风险': 2,
'无风险': 3,
'非楼道': 4
}
train_df[1] = train_df[1].map(mapping_dict)
class GalaxyDataset(Dataset):
def __init__(self, images, labels, transform=None):
self.images = images
self.labels = labels
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
start_time = time.time()
img = Image.open(self.images[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img,torch.from_numpy(np.array(self.labels[index]))
def __len__(self):
return len(self.labels)
def get_model1():
model = models.resnet18(True)
model.fc = nn.Linear(512, 5)
return model
def get_model3():
models.efficientnet_b0(True)
model.fc = nn.Linear(512, 5)
return model
def validate(val_loader, model, criterion):
# switch to evaluate mode
model.eval()
total_acc = 0
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
total_acc += (output.argmax(1).long() == target.long()).sum().item()
return total_acc / len(val_loader.dataset)
def train(train_loader, model, criterion, optimizer, epoch):
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
acc1 = (output.argmax(1).long() == target.long()).sum().item()
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print(datetime.now(), loss.item(), acc1 / input.size(0))
skf = StratifiedKFold(n_splits=5, random_state=233, shuffle=True)
for _, (train_idx, val_idx) in enumerate(skf.split(train_df[0].values, train_df[1].values)):
break
train_loader = torch.utils.data.DataLoader(
GalaxyDataset(train_df[0].iloc[train_idx].values, train_df[1].iloc[train_idx].values,
transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=20, shuffle=True, num_workers=20, pin_memory=True
)
val_loader = torch.utils.data.DataLoader(
GalaxyDataset(train_df[0].iloc[val_idx].values, train_df[1].iloc[val_idx].values,
transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=20, shuffle=False, num_workers=10, pin_memory=True
)
model = get_model1().cuda()
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adam(model.parameters(), 0.005)
best_acc = 0.0
for epoch in range(5):
print('Epoch: ', epoch)
train(train_loader, model, criterion, optimizer, epoch)
val_acc = validate(val_loader, model, criterion)
print("Val acc", val_acc)
model = get_model3().cuda()
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adam(model.parameters(), 0.003)
best_acc = 0.0
for epoch in range(5):
print('Epoch: ', epoch)
train(train_loader, model, criterion, optimizer, epoch)
val_acc = validate(val_loader, model, criterion)
print("Val acc", val_acc)
def predict(test_loader, model):
# switch to evaluate mode
model.eval()
pred = []
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(test_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
pred += list(output.argmax(1).long().cpu().numpy())
return pred
test_df = pd.read_csv("data/A.txt", sep="\t", header=None)
test_df["path"] = 'data/A/' + test_df[0]
test_df["label"] = 1
test_loader = torch.utils.data.DataLoader(
GalaxyDataset(test_df["path"].values, test_df["label"].values,
transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=20, shuffle=False, num_workers=10, pin_memory=True
)
pred = predict(test_loader, model)
pred = np.stack(pred)
inverse_mapping_dict = {v: k for k, v in mapping_dict.items()}
inverse_transform = np.vectorize(inverse_mapping_dict.get)
test_df["label"] = inverse_transform(pred)
test_df[[0, "label"]].to_csv("submit.txt", index=None, sep="\t", header=None)
import torch
print(torch.cuda.is_available())
#查看是否可以使用pytorch
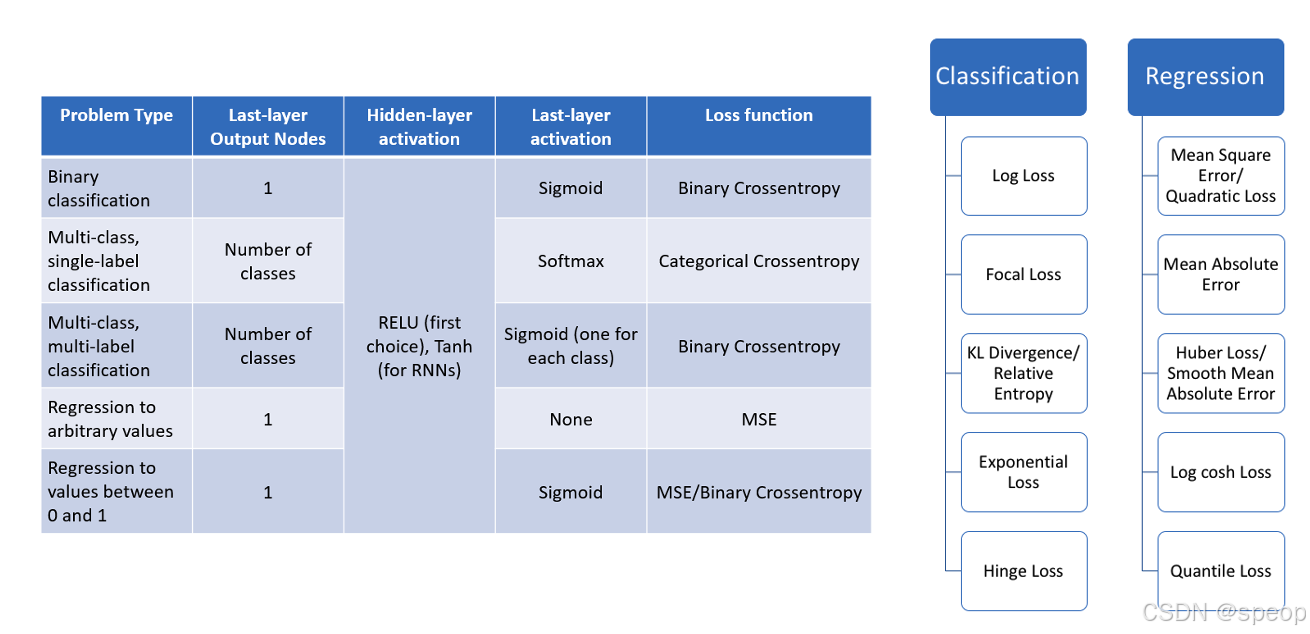
图像分类是计算机视觉中最基础的任务之一。它的目标是从输入的图像中判断出图像的类别(在这个赛题中,是判断场景是“楼道”还是“非楼道”)。这种任务相对简单,容易理解和实现,是入门计算机视觉的绝佳起点。
数据集的特点如下:
多样性:图片内容丰富,包含楼道、街道、室内其他区域等。
复杂性:楼道场景中可能存在各种消防隐患,如堆积物、电动车、飞线充电等。
标注信息(也是我们要分类预测的结果) :每张图片都有标注信息,说明其场景类别(楼道/非楼道)以及隐患等级(无隐患、低风险、中等风险、高风险)。

图像分类任务的一般处理流程
图像分类模型的训练和推理过程相对简单,不需要复杂的网络结构或大量的计算资源。这使得我们可以在短时间内完成模型的初步训练和评估,快速迭代和优化,一般需要做如下工作:
-
选择合适的网络架构 :对于图像分类任务,可以选择经典的卷积神经网络(CNN)架构,如 ResNet、VGG 或 MobileNet。这些架构已经被广泛验证,具有良好的性能和可扩展性。
-
选择 预训练模型 :利用预训练模型(如在 ImageNet 数据集上预训练的模型)可以大大减少训练时间和计算资源。通过迁移学习,将预训练模型的权重迁移到我们的任务上,并对最后几层进行微调,可以快速提升模型的性能。
-
设计 损失函数 :对于多分类任务,通常使用交叉熵损失函数(Cross-Entropy Loss)。它能够衡量模型输出的概率分布与真实标签之间的差异。
-
选择 优化器 :选择合适的优化器(如 Adam 或 SGD)来更新模型的权重。Adam 优化器由于其自适应学习率的特性,通常在训练初期表现较好。
-
调整 学习率 :在训练过程中,可以使用学习率调整策略(如学习率衰减或学习率预热),以加快收敛速度并提高模型的最终性能。
为什么使用深度学习
图像数据通常是高维度的(例如,一张256×256像素的RGB图像有196,608个特征值)。这些特征之间存在复杂的非线性关系,传统的机器学习方法(如支持向量机、决策树等)很难有效地捕捉这些关系。
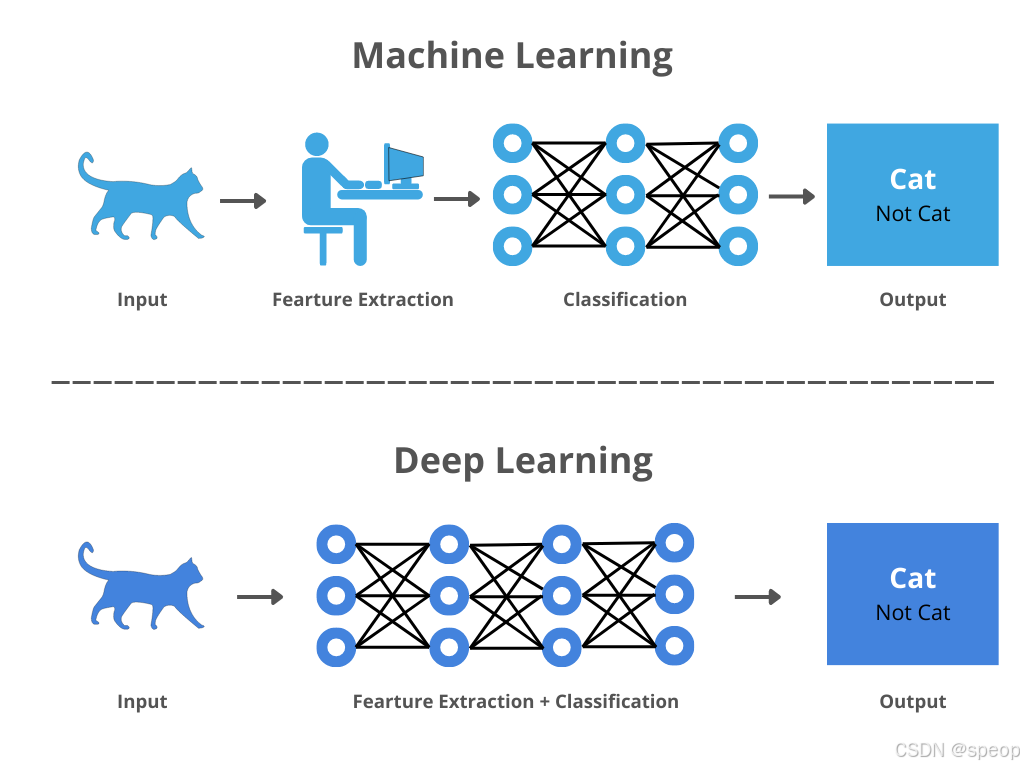
深度学习模型,尤其是CNN,通过多层神经网络结构,能够自动学习图像中的层次化特征表示。从低层次的边缘和纹理,到高层次的物体形状和场景结构,CNN可以逐步提取出对分类任务有用的特征。
赛题中的数据集包含多种场景(如楼道、街道、室内等),并且每个场景中可能存在多种消防隐患(如堆积物、电动车、飞线充电等)。这种多样性和复杂性要求模型能够泛化到不同的场景和情况。
深度学习模型通过大量的训练数据学习通用的特征表示,能够更好地适应数据集的多样性。通过数据增强技术(如旋转、翻转、裁剪等),还可以进一步提高模型的泛化能力。
迁移学习
在实际应用中,尤其是特定领域的任务(如消防隐患检测),很难收集到足够多的标注数据。深度学习模型通常需要大量的数据来学习有效的特征表示,数据量不足会导致模型过拟合,泛化能力差。
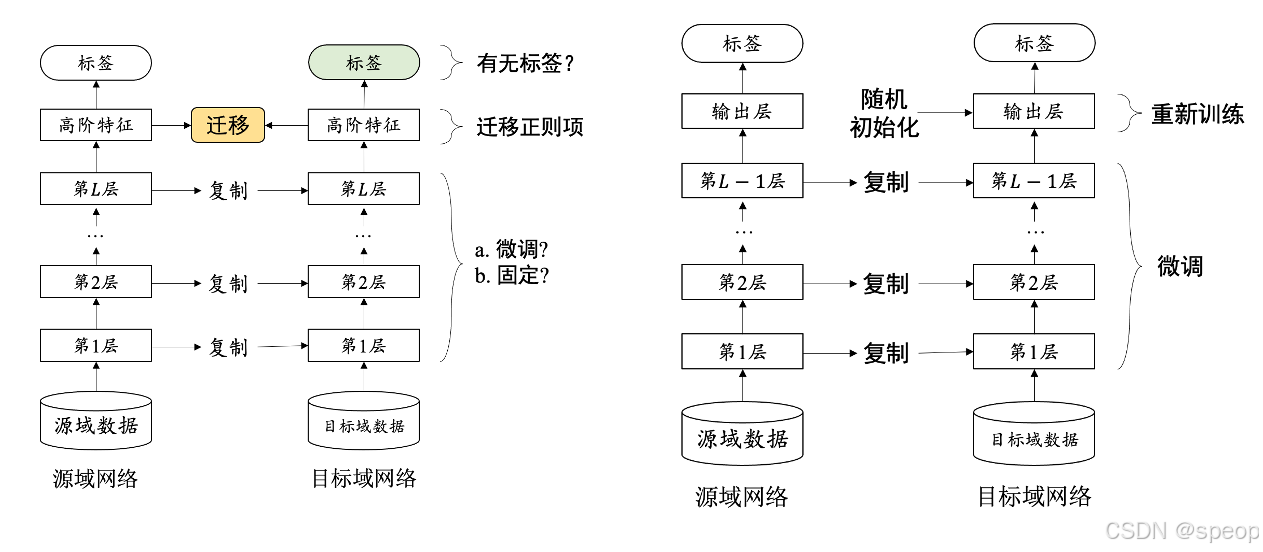
迁移学习通过在大规模通用数据集(如ImageNet)上预训练模型,学习到通用的图像特征表示。然后,将这些预训练模型迁移到特定任务上,并在有限的数据集上进行微调。这样可以充分利用预训练模型在大规模数据上学到的知识,弥补特定任务数据量不足的问题。
从头开始训练一个深度学习模型需要大量的计算资源和时间,尤其是对于复杂的网络结构(如ResNet、EfficientNet等)。训练过程可能需要数天甚至数周的时间,这对于快速迭代和优化模型非常不利。
baseline的大体情况如下:
- 分数区间:2.3分左右(具体分数可能因随机性略有波动)。
- 任务目标:对拍摄的照片内容进行识别,实时判断照片内场景是否存在消防安全隐患以及隐患的危险程度。
- 输入:蓝骑士拍摄的照片,内容包括楼道、街道、室内等场景。
- 输出:隐患等级(高风险、中风险、低风险、无风险、非楼道)。
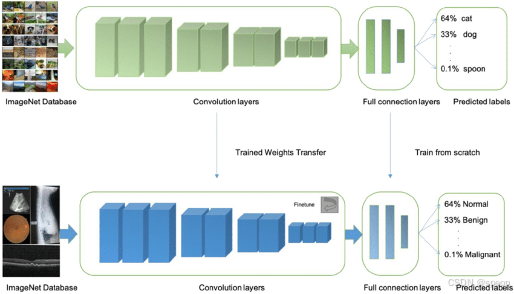
主要进行了以下工作:
- 数据预处理:加载数据集,过滤无效图片,对图片进行归一化和数据增强。
- 模型构建:加载预训练的ResNet18模型,修改最后的全连接层以适应5个分类类别。
- 模型训练:使用训练集进行模型训练,使用验证集进行模型验证,记录最佳模型。
- 模型评估:计算模型在验证集上的准确率,评估模型性能。
加载实操环境的库
import numpy as np
import cv2
import os
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
import time
from datetime import datetime
import torch
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
from sklearn.model_selection import StratifiedKFold
加载数据集,默认data文件夹存储数据
train_df = pd.read_csv("data/train.txt", sep="\t", header=None)
train_df[0] = 'data/train/' + train_df[0]
def is_valid_image(image_path):
if not os.path.exists(image_path):
return False
image = cv2.imread(image_path)
return image is not None
train_df = train_df[train_df[0].apply(is_valid_image)]
将图像类别进行编码
mapping_dict = {
'高风险': 0,
'中风险': 1,
'低风险': 2,
'无风险': 3,
'非楼道': 4
}
train_df[1] = train_df[1].map(mapping_dict)
自定义数据读取
class GalaxyDataset(Dataset):
def __init__(self, images, labels, transform=None):
self.images = images
self.labels = labels
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
start_time = time.time()
img = Image.open(self.images[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img,torch.from_numpy(np.array(self.labels[index]))
def __len__(self):
return len(self.labels)
加载预训练模型
def get_model1():
model = models.resnet18(True)
model.fc = nn.Linear(512, 5)
return model
def get_model3():
models.efficientnet_b0(True)
model.fc = nn.Linear(512, 5)
return model
模型训练,验证和预测
def validate(val_loader, model, criterion):
# switch to evaluate mode
model.eval()
total_acc = 0
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
total_acc += (output.argmax(1).long() == target.long()).sum().item()
return total_acc / len(val_loader.dataset)
def train(train_loader, model, criterion, optimizer, epoch):
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
acc1 = (output.argmax(1).long() == target.long()).sum().item()
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print(datetime.now(), loss.item(), acc1 / input.size(0))
def predict(test_loader, model):
# switch to evaluate mode
model.eval()
pred = []
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(test_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
pred += list(output.argmax(1).long().cpu().numpy())
return pred
划分验证集并训练模型
train_loader = torch.utils.data.DataLoader(
GalaxyDataset(train_df[0].iloc[train_idx].values, train_df[1].iloc[train_idx].values,
transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=20, shuffle=True, num_workers=20, pin_memory=True
)
val_loader = torch.utils.data.DataLoader(
GalaxyDataset(train_df[0].iloc[val_idx].values, train_df[1].iloc[val_idx].values,
transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=20, shuffle=False, num_workers=10, pin_memory=True
)
model = get_model1().cuda()
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.Adam(model.parameters(), 0.005)
best_acc = 0.0
for epoch in range(5):
print('Epoch: ', epoch)
train(train_loader, model, criterion, optimizer, epoch)
val_acc = validate(val_loader, model, criterion)
print("Val acc", val_acc)
修改baseline
处理输入数据
在PyTorch中,自定义数据集是一个常见的需求,特别是在处理非标准数据或需要特定预处理步骤时。在PyTorch中,你需要继承 torch.utils.data.Dataset 类来创建自定义数据集。这个类需要实现三个方法: init , len , 和 getitem 。
class GalaxyDataset(Dataset):
def __init__(self, images, labels, transform=None):
self.images = images
self.labels = labels
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
start_time = time.time()
img = Image.open(self.images[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img,torch.from_numpy(np.array(self.labels[index]))
def __len__(self):
return len(self.labels)
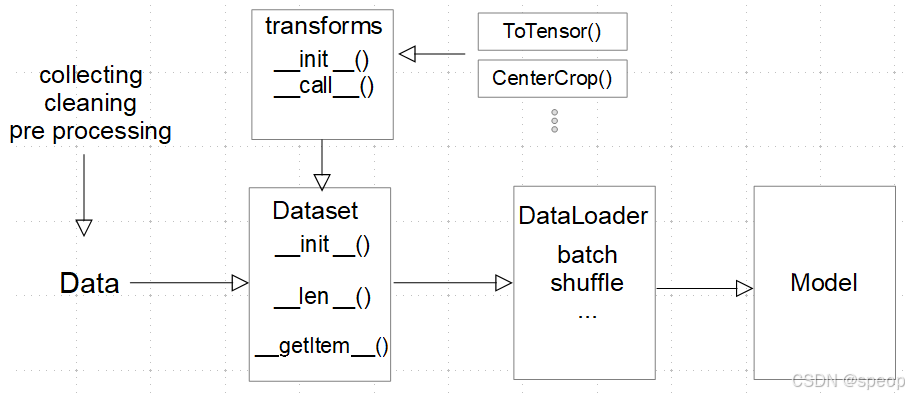
DataLoader 是PyTorch中用于加载数据集的一个类,它提供了批处理、打乱数据和多进程加载数据的功能。最后,你可以使用 DataLoader 在训练循环中加载数据,并将数据输入到你的模型中进行训练。
选择合适的模型
对于模型选择,可以从ImageNet的排行榜选择选择。但模型的选择需要根据具体的任务需求、数据量和计算资源来综合考虑。并不是越大的模型就一定越好。我们可以多参考开源社区分享的测评和经验贴:
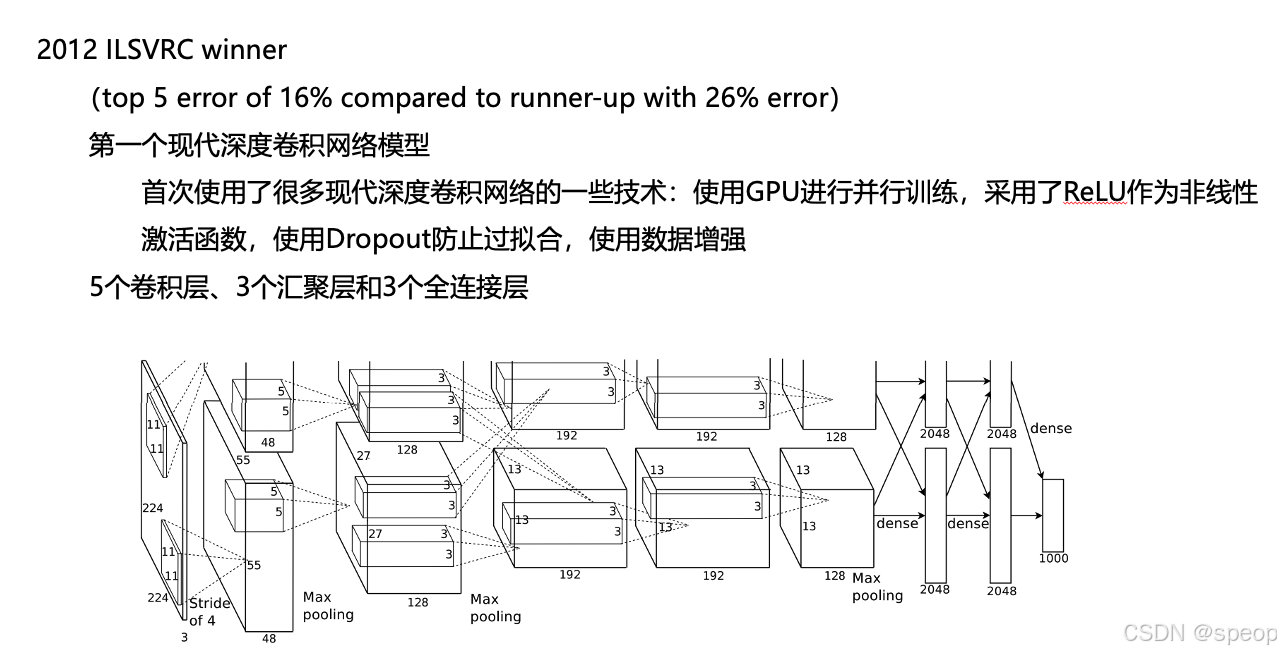
AlexNet
在ImageNet竞赛中取得突破性成果,使用ReLU激活函数和Dropout技术减少过拟合,开启了深度学习在图像分类领域的应用
GoogLeNet(Inception)
引入了Inception模块,通过并行的卷积和池化操作来增加网络宽度,同时控制参数数量。

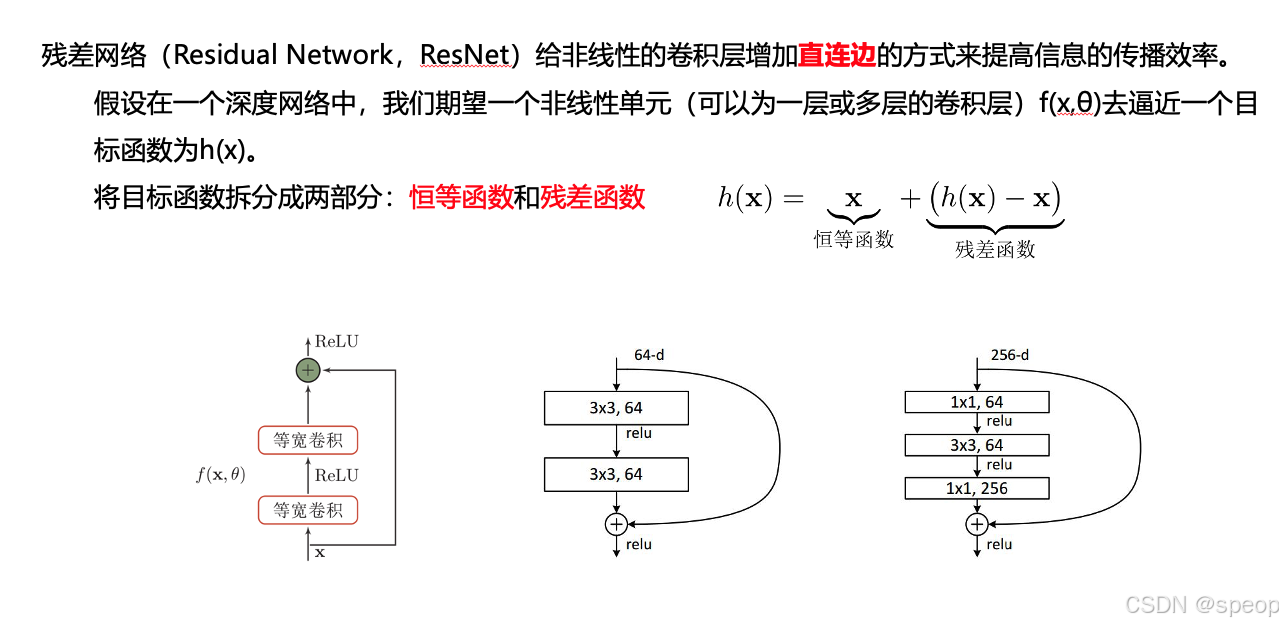
ResNet
引入了残差连接(Residual Connection),解决了深层网络训练中的退化问题,使得训练更深的网络成为可能。
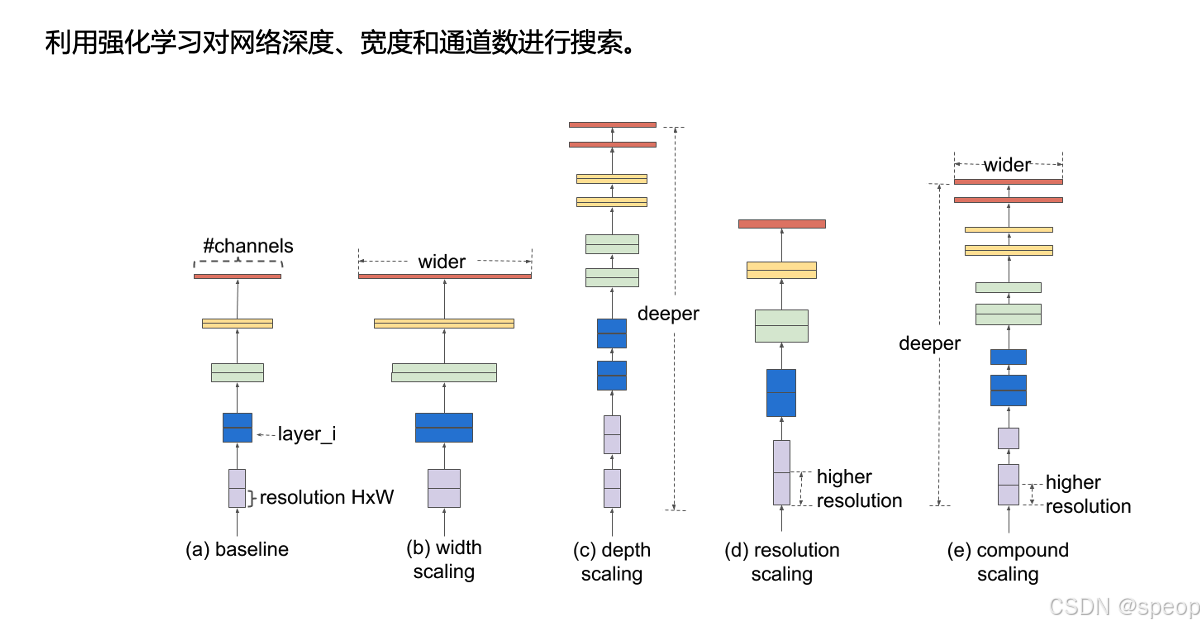
EfficientNet模型
通过复合缩放方法(同时扩展深度、宽度和分辨率)来提高网络性能,同时保持较低的计算成本。
我们可以如何在已有的数据集上做文章呢?(数据增强)
数据增强是图像分类任务中常用的技术,旨在通过对原始图像进行一系列随机变换来增加数据集的多样性,从而提高模型的泛化能力。

Mixup 是一种数据增强技术,通过将两张图像及其标签进行线性插值来生成新的训练样本。例如,给定两张图像
I
1
I_1
I1和
I
2
I_2
I2及其对应的标签
y
1
y _1
y1和
y
2
y_2
y2,Mixup生成新的图像和标签为:
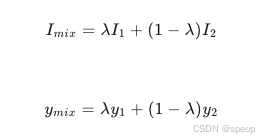
CutMix 是Mixup的变体,它不是对整个图像进行混合,而是在图像之间交换矩形区域。具体来说,随机选择一个矩形区域,将该区域从一张图像“剪切”并“粘贴”到另一张图像上,同时标签也按照区域面积比例进行混合。这种方法可以鼓励模型关注图像的局部特征,提高模型的鲁棒性。
这一部分的资料可以参考:
- https://albumentations.ai/docs/3-basic-usage/image-classification/
- https://pytorch.org/vision/main/transforms.html
还可以如何提升分类效果
Focal Loss
当类别分布不均匀时,模型可能会偏向于多数类,导致对少数类的识别性能较差。为了解决这个问题,可以采用多种策略,其中之一就是使用Focal Loss。
Focal Loss的优点
- 提高少数类识别性能:通过增加少数类样本的损失贡献,Focal Loss有助于提高模型对少数类的识别性能。
- 减少易分类样本的影响:通过减少易分类样本的损失贡献,Focal Loss有助于模型关注难以分类的样本,从而提高整体性能。
- 灵活性:Focal Loss的参数( α 和 γ )可以根据具体任务进行调整,以获得最佳性能。
还有哪些进阶方法?
在图像分类任务中,尤其是针对消防隐患识别这样的具体应用场景,除了基本的图像分类方法外,还有多种进阶方法可以帮助提升模型的性能和准确性。
-
高风险:楼道中出现电动车、电瓶、飞线充电等可能起火的元素。
-
中风险:楼道中存在大量堆积物严重影响通行或堆放大量纸箱、木质家具等能造成火势蔓延的堵塞物。
-
低风险:存在楼道堆物现象但不严重。
-
无风险:楼道干净,无堆放物品。
-
非楼道:一些与楼道无关的图片。
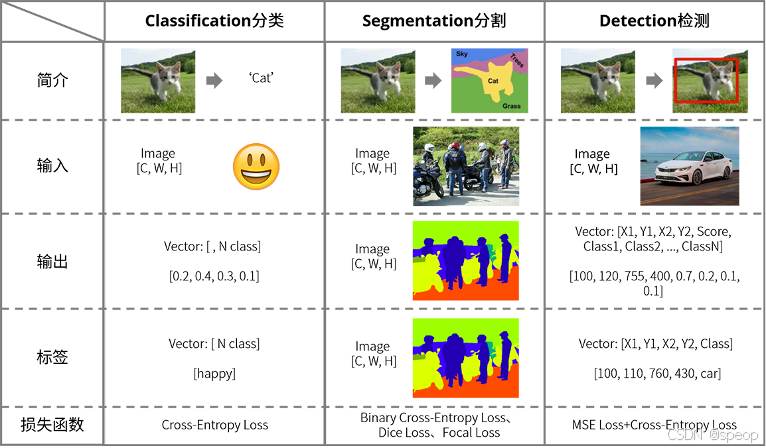
待选的思路如下: -
使用物体检测模型(如YOLO、Faster R-CNN等)来识别图像中的具体物体,如电动车、电瓶、堆积物等。
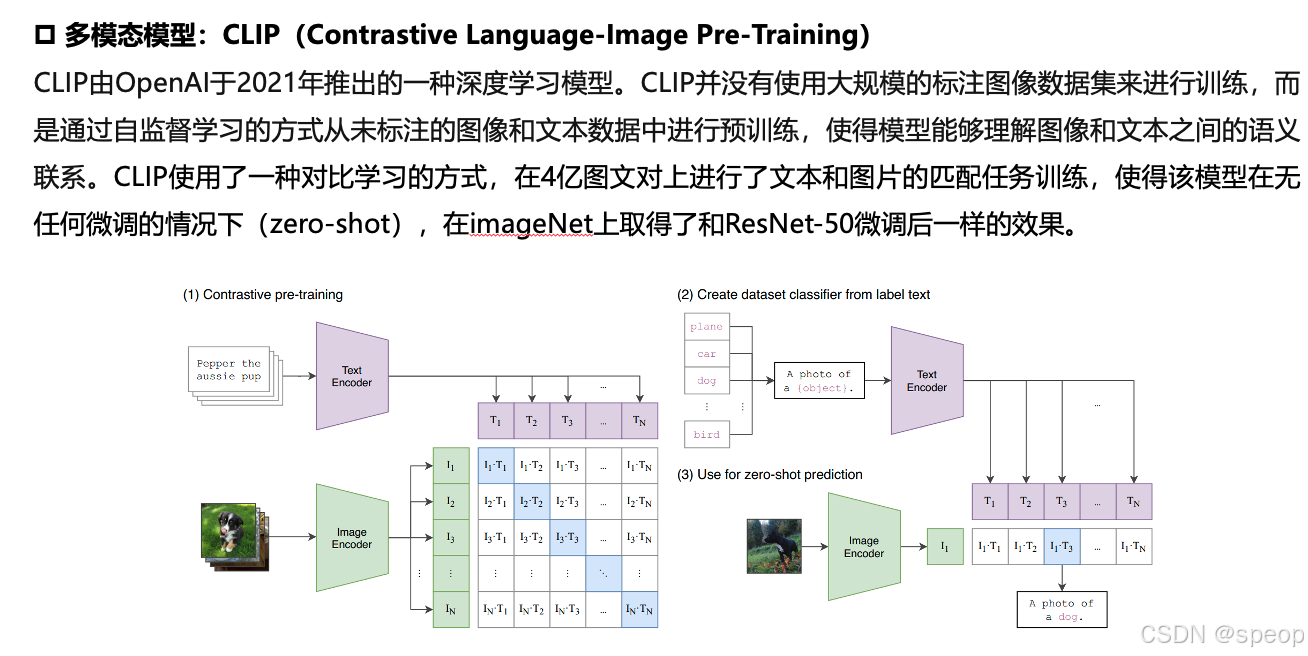
-
CLIP(Contrastive Language-Image Pre-training)模型能够将图像和文本映射到同一个嵌入空间,从而实现跨模态的匹配。
-
利用多模态大模型(如ViLT、ALIGN等),这些模型能够同时处理图像和文本信息。

















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









