







在数据处理和清洗的过程中我们经常会遇到时间类型的数据
1.时间序列的处理
如果读入的时间列数据是string类型,我们可以先进行时间序列的转换
df['login_time'] = pd.to_datetime(df['login_time'])
#或者
df.loc[:, '日期'] = pd.to_datetime(df.loc[:, '日期'], format='%Y/%m/%d', errors='coerce')
这样处理后可以使用dt模块,如果需要添加日期对应的周数或者月份
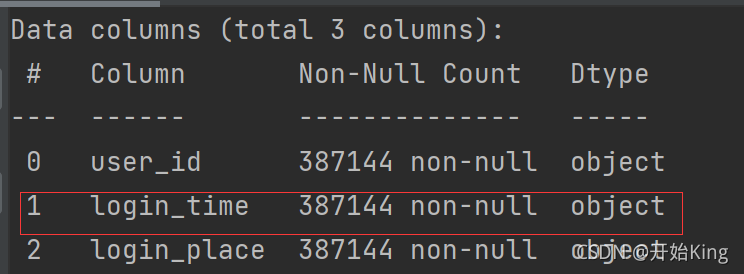
原始数据

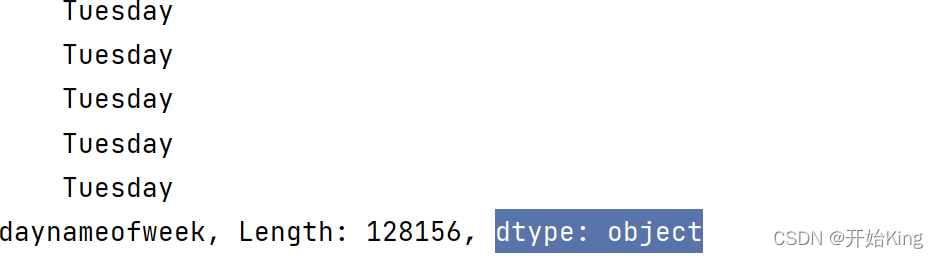
1 添加星期名称
df['daynameofweek'] = df['login_time'].dt.day_name()
2 只保留数据的时分秒
df['数据时间']=df['数据时间'].dt.time
 返回类型为dtype: object
返回类型为dtype: object
3只保留数据的年月日
dt.date 和 dt.normalize()返回一个日期的年月日。但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的。
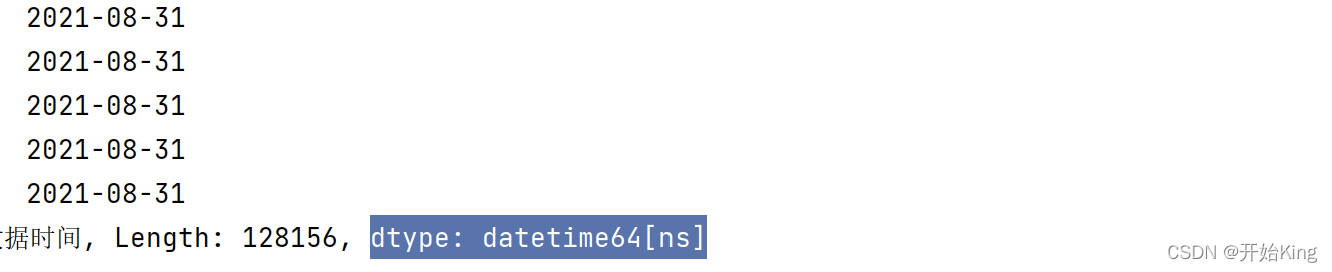
df['数据时间']=df['数据时间'].dt.date

df['数据时间']=df['数据时间'].dt.normalize()
4 返回年,月,日等
1.2 dt.year、dt.month、dt.day、dt.hour、dt.minute、dt.second、dt.isocalendar().week 分别返回日期的年、月、日、小时、分、秒及一年中的第几周
train_data['年']=train_data['数据时间'].dt.year
train_data['月']=train_data['数据时间'].dt.month
train_data['日']=train_data['数据时间'].dt.day
train_data['小时']=train_data['数据时间'].dt.hour
train_data['一年中的第几周']=train_data['数据时间'].dt.isocalendar().week
返回的都是整数,除了isocalendar().week返回的是dtype: UInt32
df['dayofweek']=df['数据时间'].dt.dayofweek # 获取一周的第几天
小技巧
也可以读取数据的时候,直接转换成时间类型,参数parse_dates=
offline_train = pd.read_csv(r'D:\train.csv',
parse_dates=['Date_received', 'Date'],encoding='gbk')


















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











