







速览图像生成常见模型
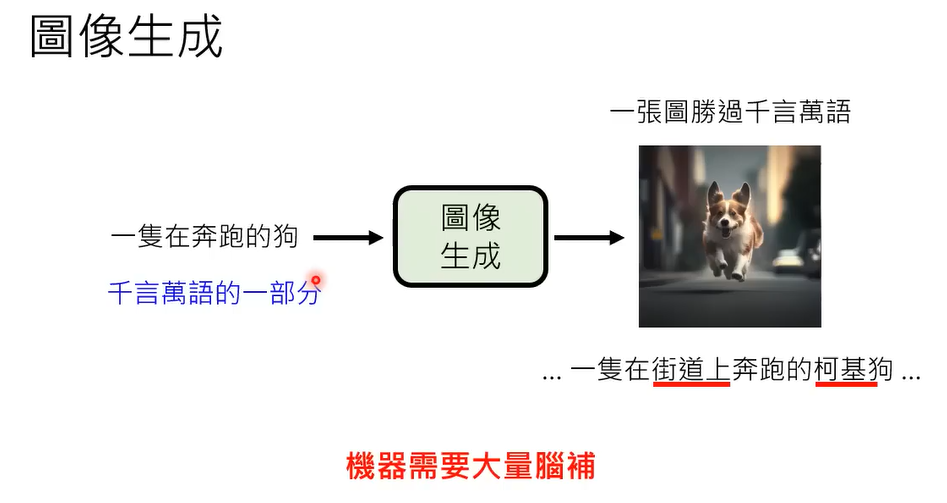
图像生成,给一个句子,生成图像可能有很多种不同样貌,另一个和图像生成比较像的是语音合成,给一段文字,生成的声音男女老少 语音语调可能都不一样。
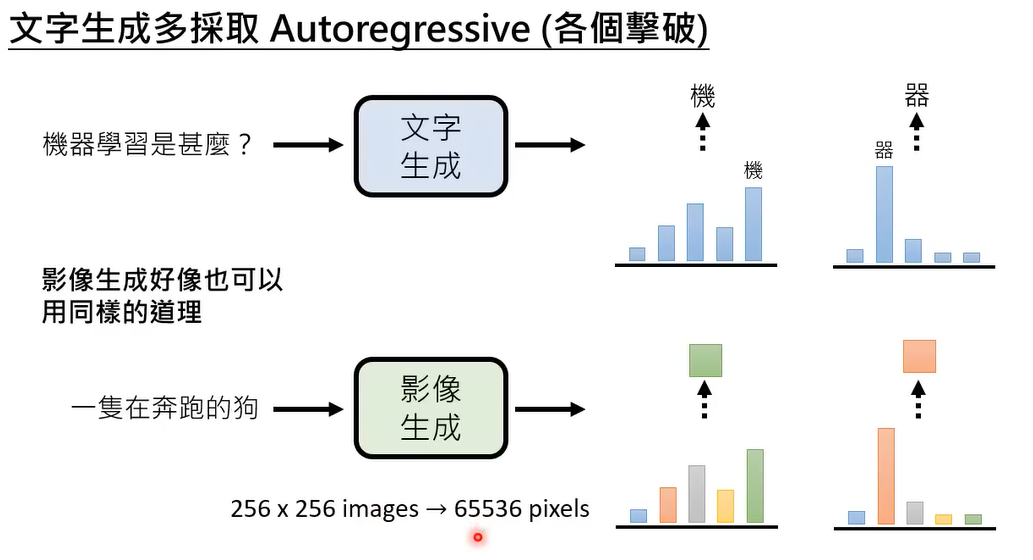
图像生成可以借鉴文字生成,预测每一个pixels,第一个pixels是红色还是蓝色(0~255)

openai之前也有做过类似的工作。但是这样做实在是太耗费时间了,现在大多数模型使用一次到位的方式,给一段文字,把每一个位置上要放什么颜色的distribution 都先产生出来,再根据这些distribution 去做sample。
生成了概率分布后,模型会从这些分布中进行采样。具体来说,模型会对每个像素的位置,基于所生成的概率分布随机选取一个值,这个值就成为该像素的最终颜色或特征。比如,如果生成的红色通道的分布是一个均值为200,标准差为30的正态分布,那么模型就会从这个分布中随机采样一个值(例如195、202、198等)。对绿色和蓝色通道做类似的操作,最后得到一个RGB值来决定该像素的颜色。
但是这样做会有什么问题
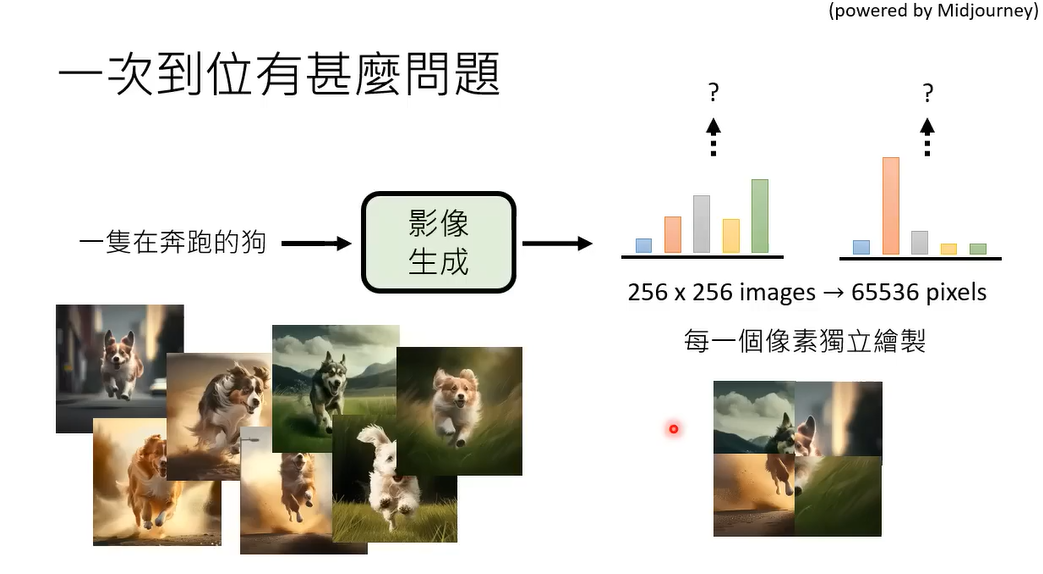
如果模型在每个像素上独立地进行这种操作,就会遇到协调性和连贯性的问题。因为每个像素的生成都是从单独的分布中采样出来的,可能会导致局部区域的颜色或特征没有连贯性。举个例子:
假设一幅图像中有一只狗,而模型在生成每个像素时没有全局信息或上下文约束。某些像素可能会显示狗的不同部位的颜色,比如有的像素可能显示狗的腿是偏黑色的,有的可能显示头部是白色的,而其他区域可能是不一致的颜色。这些局部的、独立生成的像素分布,最终可能会使得狗的形象变得模糊或扭曲。
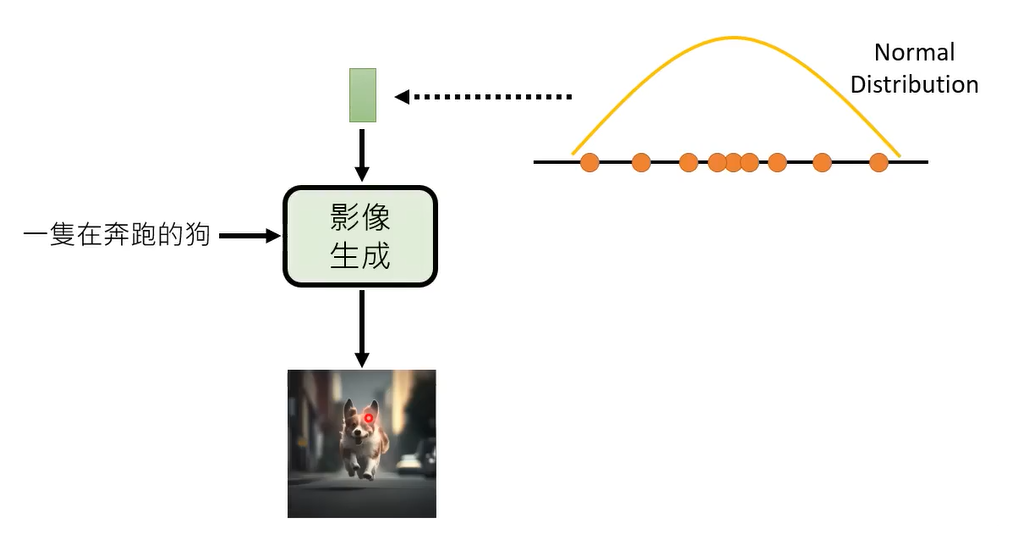
所以现在的模型会从一个高维的distribution(已知分布或者足够简单)sample出一个高维向量,然后和文字一起合力生成一张图像
其实发现不管是用什么样的影像生成模型,VAE,GAN,或者是Diffusion model其实方法都是一样的,你都不是只拿文字去生成影像,都需要一个额外的输入,都需要从一个简单的distribution里sample出来一个东西,sample出的东西有点像杂讯
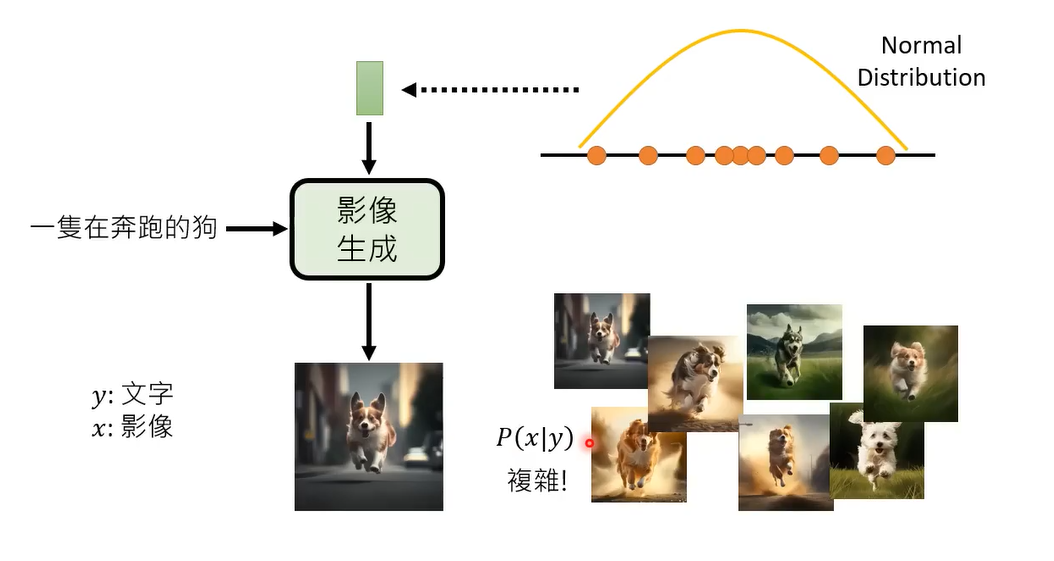
如果我们知道P(X|Y)的分布,那我们就能画出图像,但是P(X|Y)的分布是复杂的
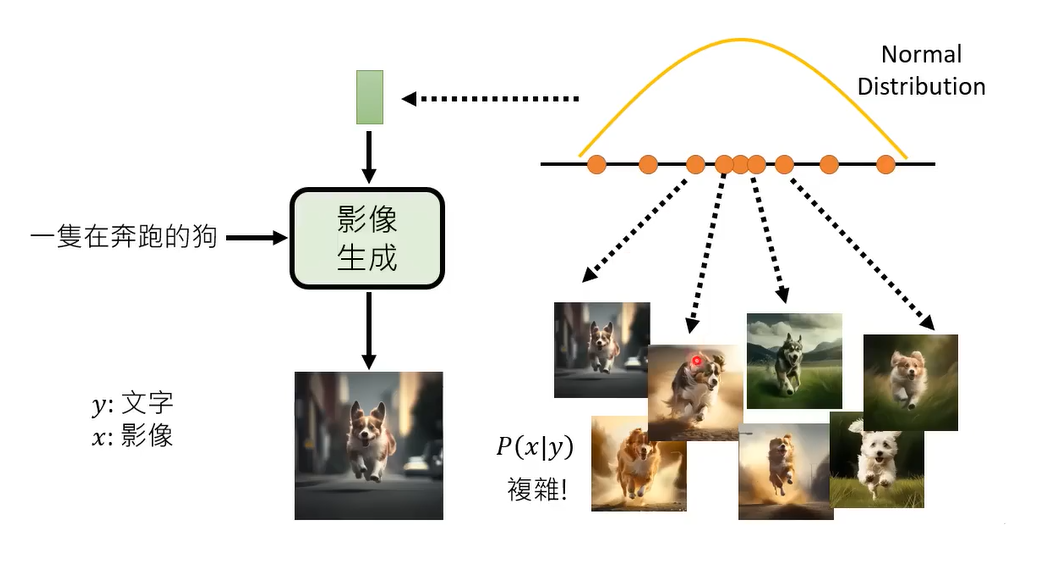
所以我们的做法是把normal distribution里sample出来的向量对应到P(X|Y)里的每一个x , 把normal distribution里sample出来的向量对应到可能画的狗 。
那么这个影像生成模型做的是就是产生这个对应关系,把normal distribution里sample出来的向量对应到正确的,狗在奔跑的图片
那么这些影像生成都是在解决这个问题,只是解法不同
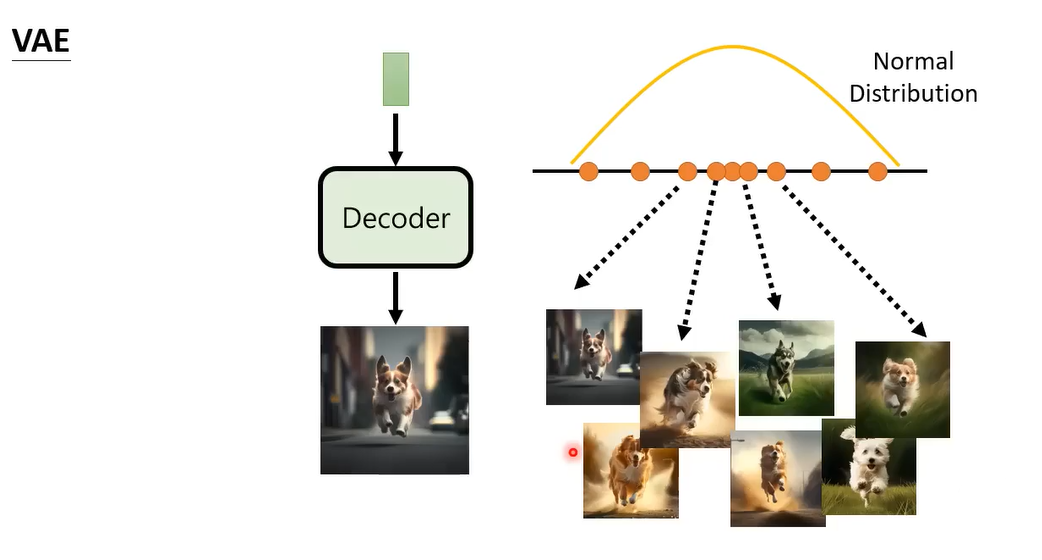
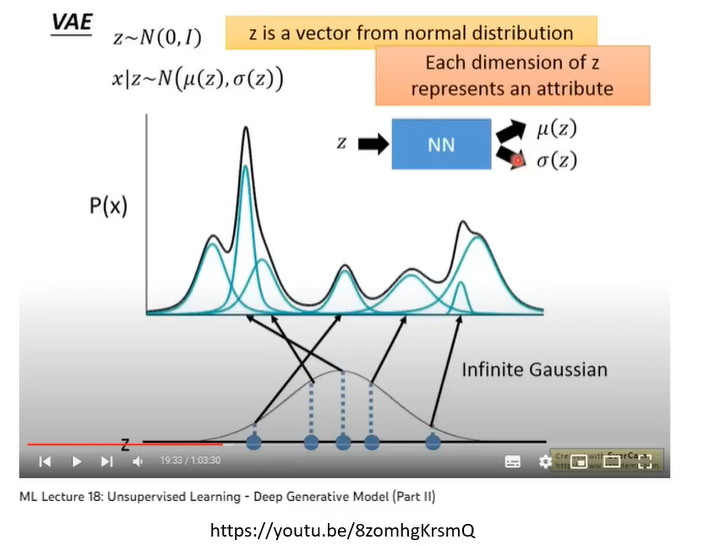
VAE就是输入是从normal distribution里sample出的向量,希望输出是要的图像(这里省略了文字的输入)。怎么训练一个向量对应一个图片的encoder,你就是要训练一个network,如果你有一个成对的data,知道normal distribution对应到哪一张狗的图像,那你就i可以训练这个decoder,但是我们不知道这个对应关系,那该怎么做呢
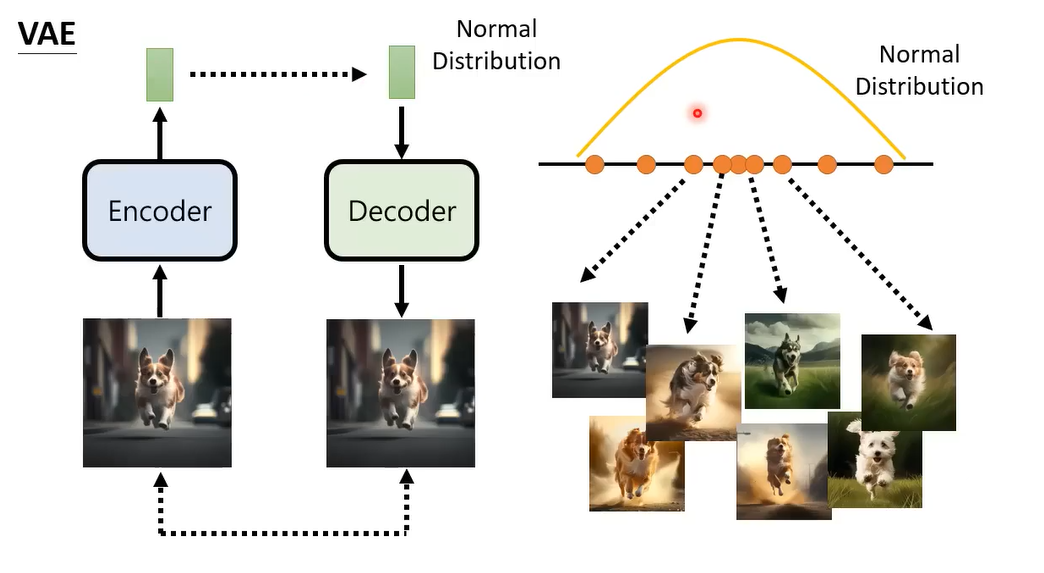
那就再加一个encoder,只有encoder和decoder没法训练,那就把他们连在一起。图像输入encoder产生向量,然后再通过decoder变回图像,让输入和输出越接近越好。但是只是这样训练是不够的,这样训练,encoder产生的向量不一定会是normal distribution,所以要加一个额外的限制,强迫中间的向量是一个normal distribution。更多详细介绍
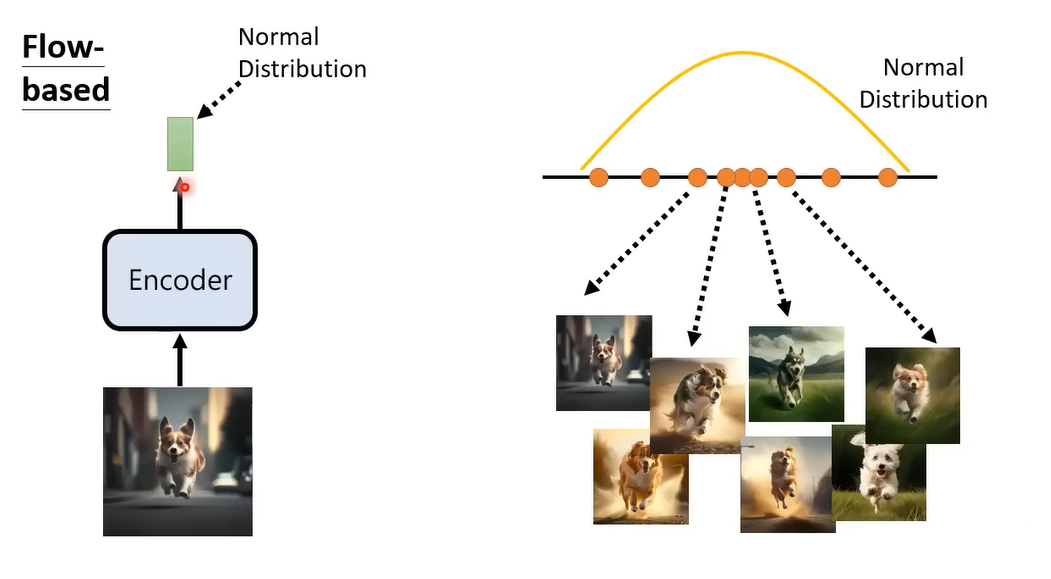
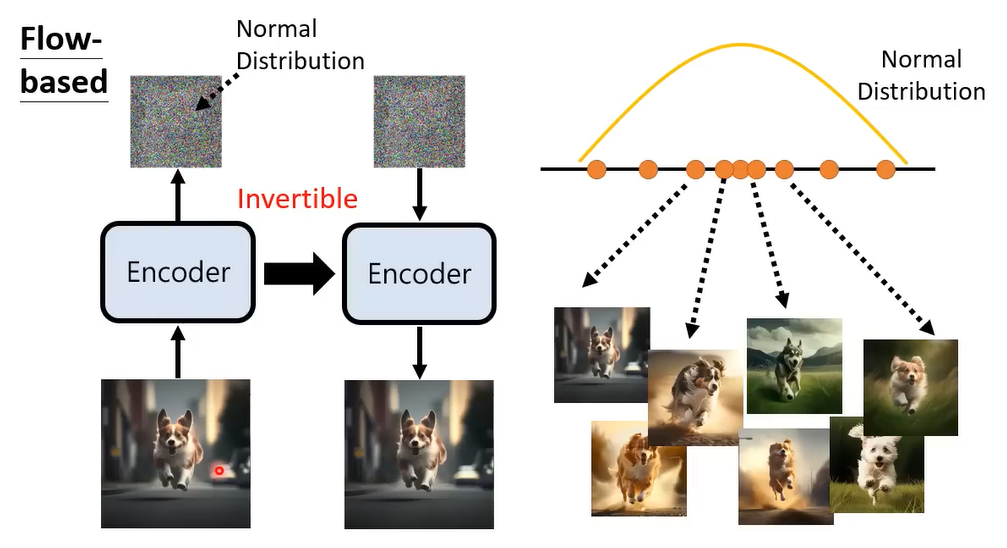
flow-based generative 和VAE相反,我们希望先训练一个Encoder,输出的向量分布 就是一个Normal Distribution
接下来我们再强迫这个encoder是一个Invertible的function,我们就可以把这个encoder当作decoder来用
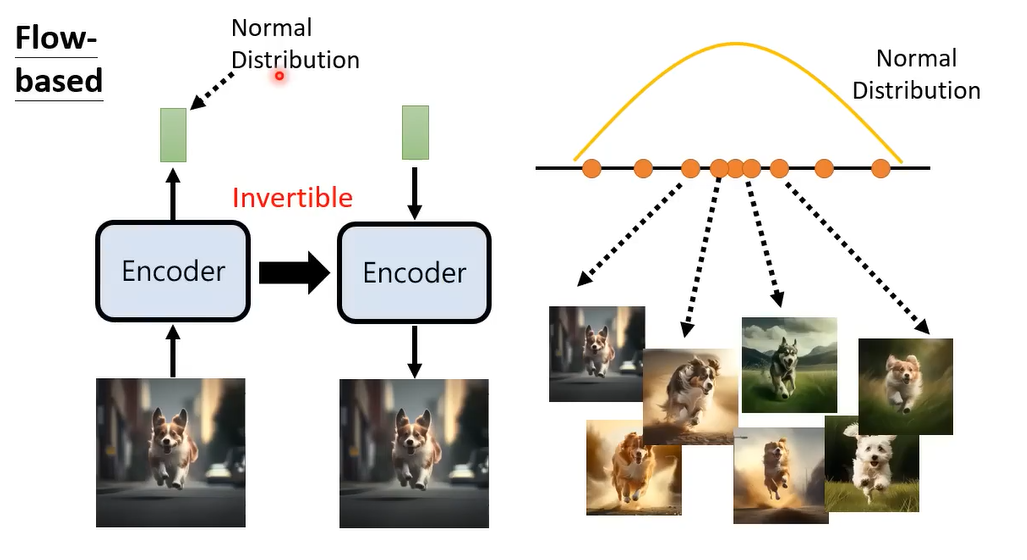
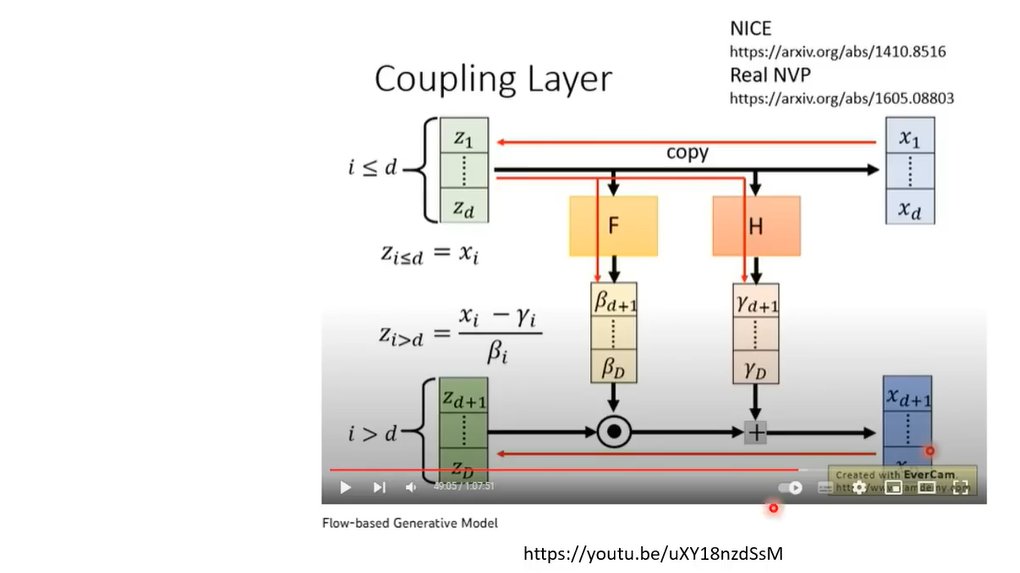
那么怎么强迫这个encoder是一个Invertible的function,其实这就是flow-based model的神奇之处,它其实有限制network的架构,让你train完以后马上知道这个encoder的Inverts长什么样子
这里你要保证输入的图像和输出的图像要一样大小,如果输出比输入小,那就不是Invertible的了。详情可以看下面的课
接下来就是Diffusion Model
Diffusion model的概念是什么呢,就是把 一张图片一直加杂讯,一直加杂讯,一直到看不出来原来的图是什么。那怎么生成图像呢
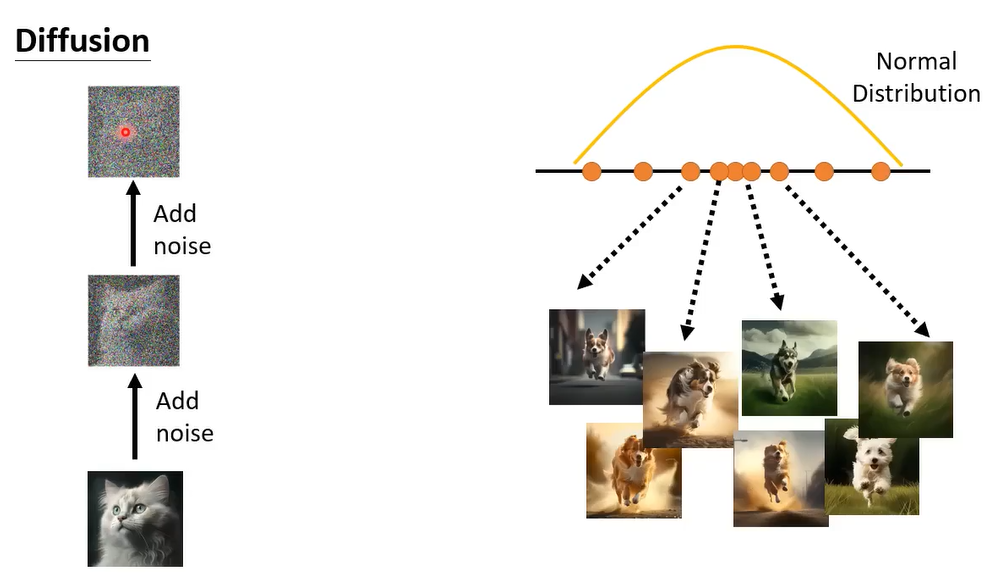
生成图像其实就是你learn 一个Denoise的model,丢一个从Normal Distribution sample出来的vector做输入,然后一步步去噪,你要的图就产生出来了。
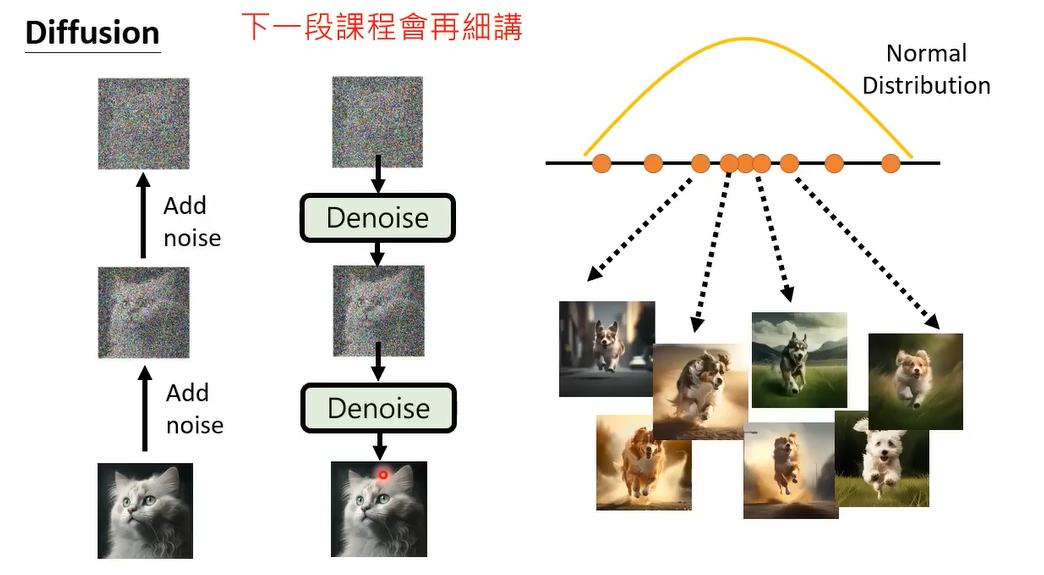
现在感到困惑是正常的,后面会详细讲解这个模型
最后要介绍的就是大家耳熟能详的GAN,我之前有篇笔记详细介绍了GAN
GAN就只train了Decoder(这里叫Decoder是为了和前面保持一致性,你也可以就叫Generator)没有train Encoder了
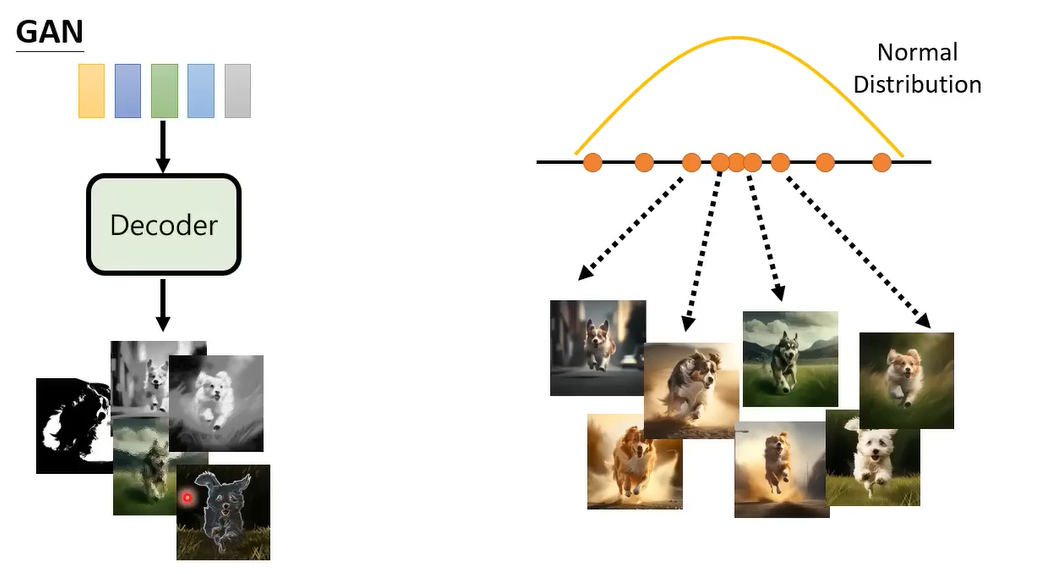
刚开始因为还没训练,输出的就是一些乱七八糟的东西,比上面图片要差很多,就是一些杂讯啊。接下来你会训练一个Discriminator,
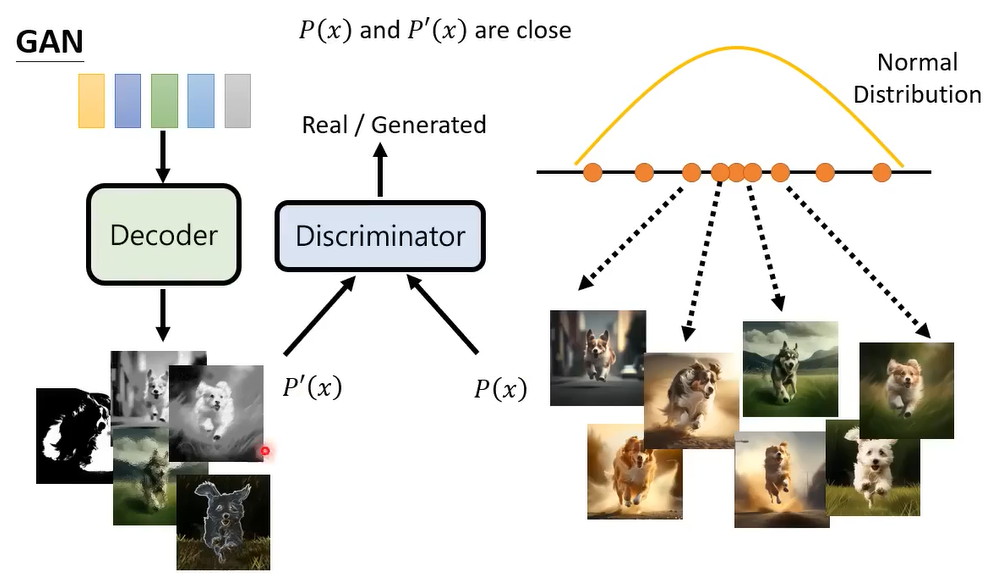
Discriminator训练的loss其实就这 P ′ ( X ) 和 P ( X ) P^\prime(X)和P(X) P′(X)和P(X)图片的相似程度。更详细介绍可以看下面的介绍

然后就是总结
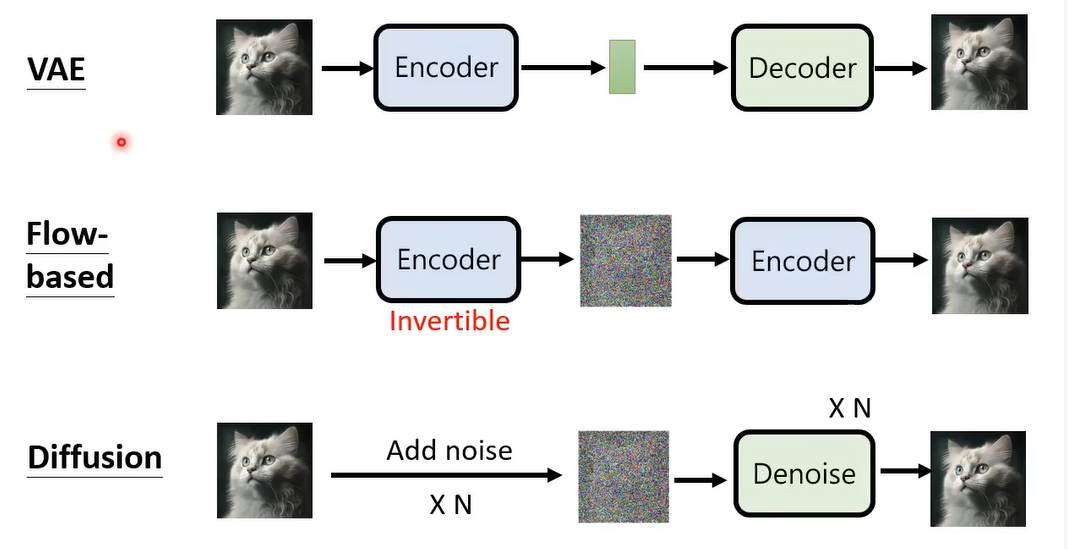
在VAE里面我们train了两个model,一个encoder一个decoder,而flow-based 我们其实通过一些限制,使encoder是 invertible的,其实只训练一个encoder,Diffusion model就只训了一个Decoder,其实你也可以把add noise的过程看成encoder,不过这个过程不需要学习参数,然后产生的杂讯经过N次Denoise就生成一张图像,你可以把N次Denoise看成Decoder。
这里没有GAN,是因为你可以在这三个模型最后的输出加一个Discriminator让输出和真实图像越接近越好
然后产生的杂讯经过N次Denoise就生成一张图像,你可以把N次Denoise看成Decoder。
这里没有GAN,是因为你可以在这三个模型最后的输出加一个Discriminator让输出和真实图像越接近越好


















 2942
2942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











