







最近Transformer的文章看的有点多,正好昨天发现一篇整理的比较好的文章,在这里翻译一下分享给大家。
鉴于内容有点多,之后将对本文章持续更新...
(一)Attention 以及 Self-Attention
1.Attention
- 是神经网络中的一种机制:模型可以通过选择性地关注给定的数据集来学习做出预测。Attention的个数是通过学习权重来量化的,输出则通常是一个加权平均值。
2.Self-Attention:
- 是一种注意机制,模型利用对同一样本观测到的其他部分来对数据样本的剩下部分进行预测。从概念上讲,它感觉非常类似于non-local的方式。还要注意的是,Self-attention是置换不变的;换句话说,它是对集合的一种操作。
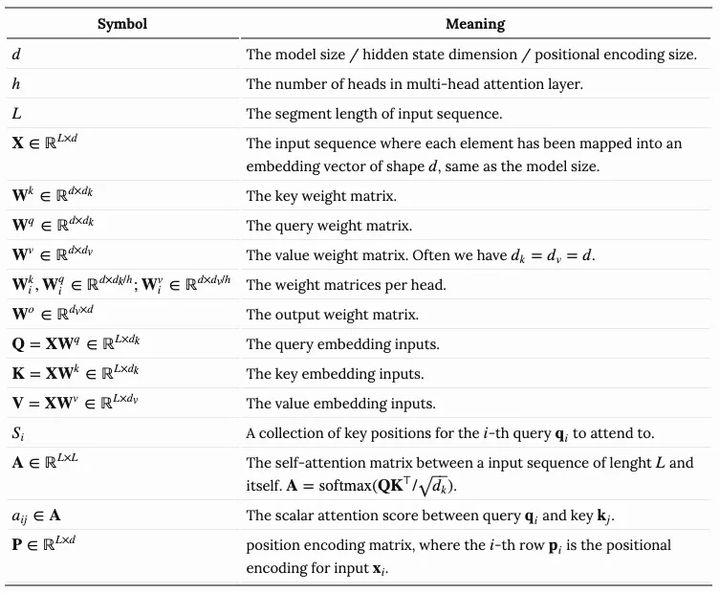
而关于attention和self-attention存在非常多的形式,我们之前常见的Transformer是依赖于scaled-dot-product的形式,也就是:给定query矩阵Q, key矩阵K以及value矩阵V,那么我们的输出就是值向量的加权和,其中,分配给每个值槽的权重由Quey与相应Key的点积确定。
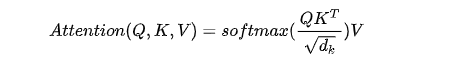

(二)Multi-Head Self-Attention
multi-head self-attention是Transformer的核心组成部分,和简单的attention不同之处在于,Multihead机制将输入拆分为许多小的chunks,然后并行计算每个子空间的scaled dot product,最后我们将所有的attention输出进行拼接。
(三)Transformer
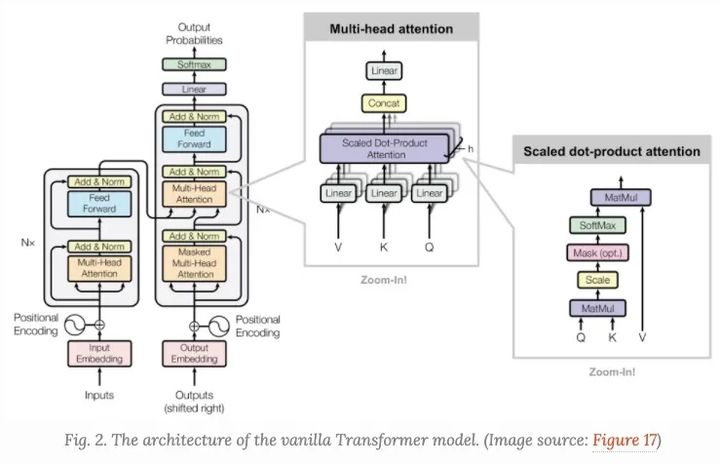
Transformer,很多时候我们也称之为"vanilla Transformer", 它有一个encoder-decoder的结构,decoder的Transformer可以在语言建模的时候获得非常好的效果。
Encoder-Decoder结构
Encoder生成一个基于attention的表示,能够从一个大的上下文中定位一个特定的信息片段。它由6个身份识别模块组成,每个模块包含两个子模块、一个multihead self-attention和一个point-wise全连接前馈网络。
按point-wise来说,这意味着它对序列中的每个元素应用相同的线性变换(具有相同的权重)。这也可以看作是滤波器大小为1的卷积层。每个子模块都有一个剩余连接和layer normalization。所有子模块输出相同维度的数据。
Transformer的decoder功能是从encoder的表示中抽取信息。该结构与encoder非常相似,只是decoder包含两个多头注意子模块,而不是在每个相同的重复模块中包含一个。第一个多头注意子模块被屏蔽,以防止位置穿越。
Positional Encoding
因为self-attention操作是permutation不变的,所以使用正确的位置编码是非常重要的,此处我们使用如下的位置编码来提供order信息,位置编码,我们可以直接将它们加入到我们到vanilla Transformer中,

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









