






现在大家都习惯用隐式反馈来学习推荐模型,并作用于线上推荐系统(十方也不例外)。大量的隐式反馈数据确实缓解了数据稀疏的问题,但是这些数据很多并没有反馈用户真正的需求。拿电商举例,大量的点击,并不会带来支付行为,就算是支付,用户也可能给差评,这种情况往往应该是负例,但是我们却把它们当初正例用于推荐模型,这样不可避免带来了噪声。《Denoising Implicit Feedback for Recommendation》这篇论文发现了这种偏差对推荐产生了严重的负面影响,所以提出了一种新的训练策略Adaptive Denoising Training(ADT),在训练过程中就能发现噪声。下面我们就看看如何用这种训练策略,去提升推荐质量吧。
噪声的恶劣影响
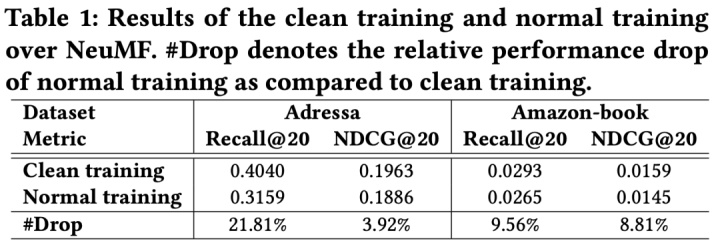
从下表中,我们可以看到有噪声的数据训练(Normal training)在Recall和NDCG上都远低于用无噪声训练(Clean training),所以纠偏就很重要了。
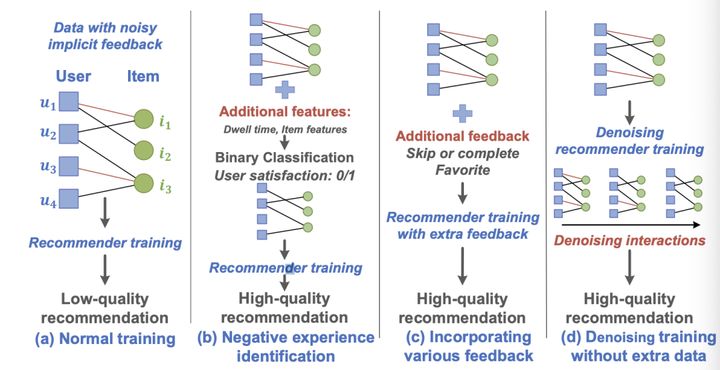
其实以往就有很多工作进行纠偏,如下图所示。(b)方法通过一些用户行为过滤掉噪声样本,如用户在页面停留时间和一些其他行为模式,同时还增加了很多item特征,如item描述长度,来达到纠偏效果。(c)通过补充其他反馈,从而缓解隐式反馈的影响。这些方法都要补充很难获取且较少的数据,并不是解决问题的好方法。(d)就是本论文提出的好方法,并不需要任何额外数据。(d)方法纠偏,主要是发现了那些false-positive(FP)的交互的loss在训练的早期都偏大,所以会误导模型学习,并且在训练模型,模型就会过拟合这些噪声,所以我们要对这种loss进行纠偏,但是要避免错误的对true-positive(TP)交互纠偏。
本文提到,该纠偏方法主要聚焦false-positive交互带来的噪声,忽视false-negative的交互。也很容易理解,正例远比负例稀疏,所以false-positive会带来更多影响。需要注意的是,false-positive交互在早期训练中会非常难拟合,很容易拟合的样本大多是非噪声的样本,过早的拟合hard的样本也会损伤模型的泛化能力。从下图中,我们对比true-positive和false-positive交互的loss,我们会发现两种样本的loss会最终收敛,说明模型不仅记住了正确的信息,也把噪声学到了。同时我们还发现两种样本loss下降速度不同,并在早期训练过程中,false-positive要远大于true-positive,这也说明了模型很难学到这些噪声,虽然最终还是学到了。
降噪两板斧
Truncated Loss: 通过一个动态阈值直接裁剪hard样本的loss,如下式所示。
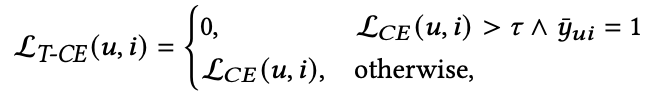
T-CE loss 会无差别的移除loss超过阈值的部分,这个阈值是不能固定的,因为loss会随着训练的进行逐渐下降,所以阈值也会有个drop rate。这个drop rate必须有个上限,限制丢掉loss的比例,该drop rate需要平滑的从0增长到它的上限,这样使得模型可以逐渐的区分true-positive和false-positive,所以drop rate定义如下:
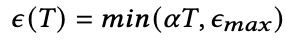
整个T-CE loss的算法定义如下所示:

Reweighted Loss: 在训练中给hard样本一个较小的权重。
这个定义如下式,就是给loss乘个weight:
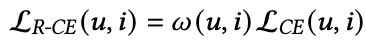
同理,这个weight在训练过程中应该动态更新,尽量需要对hard的样本给予一个较小的weight,并且可以适用于不同的模型和数据。该方法主要收到Focal Loss的启发,通过预估的score评估w的大小。预估的score是在[0,1]范围,而CE loss范围是[0,∞],对positive样本预估较小的值会导致很大的CE loss,所以w定义如下:
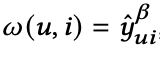
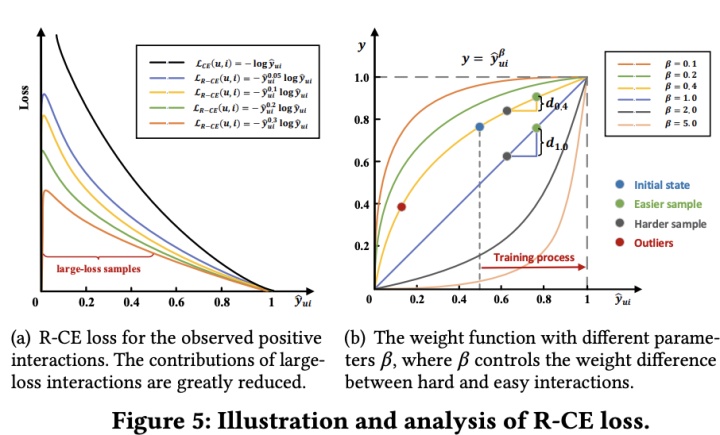
这里beta是一个超参控制weights的范围,从下图我们可以看到用上述weights,我们可以显著降低hard样本的loss。
我们需要注意的是,负例也会产生很大的loss,所以我们把公式修订为下式:
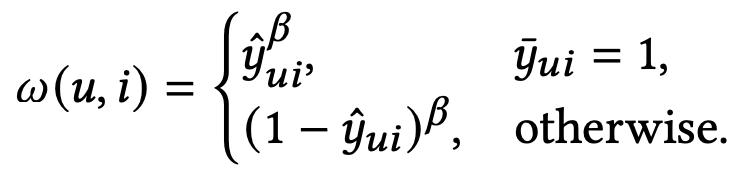
实验
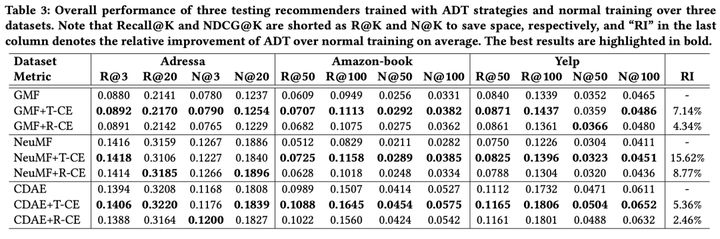
从下面实验中我们发现,使用这“两板斧”效果还是不错的。


















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









