






一、前言
用反向传播算法训练的多层神经网络是一种比较成功的基于梯度的学习技巧的好例子。在适当的网络架构下,基于梯度的学习算法可以用于合成复杂的决策面,该决策面可以用最少的预处理对高维模式(如手写字符)进行分类。本文回顾了应用于手写字符识别的各种方法,并在标准手写数字识别任务中进行了比较。卷积神经网络专门设计用于处理二维形状的可变性,其性能优于所有其他技术。现实生活中的文档识别系统由多个模块组成,包括字段提取、分割、识别和语言建模。一种新的学习范式,称为图变换网络(GTN),允许使用基于梯度的方法对此类多模块系统进行全局训练,以最小化整体性能度量。描述了两个在线手写识别系统。实验证明了全局训练的优势和图变换网络的灵活性。还描述了用于读取银行支票的图形变换器网络。它使用卷积神经网络字符识别器与全局训练技术相结合,以提供商业和个人检查的记录准确性。它被商业化部署,每天可以读取数百万张支票。
二、介绍
大多数模式识别系统是使用自动学习技术和手工算法结合来构建的。
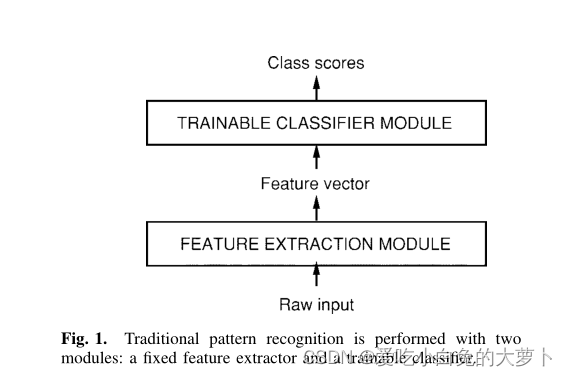
传统的模式识别系统如下图所示:
原始输入->特征提取器->特征向量->训练分类模型->分类结果
(1)特征提取器:将输入模式变成低维向量或短串符号。特征提取器包含大部分先验知识,并且是特定于任务的。它也是大多数设计工作的重点,因为它通常完全是手工制作的。
(2)分类器:通常具有通用性和可训练性。
这种传统方法的主要问题之一是,识别精度在很大程度上取决于设计者提出一组适当特征的能力。不幸的是,这是一项艰巨的任务,必须针对每个新问题重新进行。大量的模式识别文献致力于描述和比较针对特定任务的不同特征集的相对优点。
由于强大的机器学习技术的可用性,使得模式识别技术可以处理高维输入,并且在输入这些大数据集时可以生成复杂的决策函数。可以说,语音和手写识别系统准确性的最新进展在很大程度上可以归因于对学习技术和大型训练数据集的日益依赖。作为这一事实的证据,大部分现代商业OCR系统使用某种形式的多层神经网络,并通过反向传播进行训练。
学习机计算一个函数: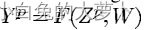
其中Zp表示第p个输入模式,W表示可学习参数的集合,Yp表示模式Zp的已识别标签或每个类相关的概率。
损失函数: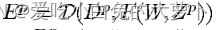
其中Dp表示模式Zp的正确输出。
平均损失函数: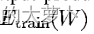
表示已标记的训练集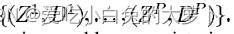
的系统平均预测损失。
训练目的:找到一组学习参数W,使平均误差最小。当在实际应用中,最终目的是要让模型在测试集(与训练集不相关)上的误差最小。
测试集与训练集上的平均误差的差值为:
其中:p表示训练样本数,h是用来衡量机器“有效容量”或复杂性的标准,alpha是一个常量,介于0.5-1之间。随着训练样本数的增加,二者的差值减少。随着h机器有效容量的增加,训练平均误差会减少。因此,当h增加时,会在训练误差的减少和差值的增加之间进行权衡,以达到泛化误差最小的最优值。
结构风险最小值通常通过最小化函数: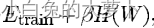
来实现的。其中H(W)表示正则化函数,正则化函数限制了参数空间的取值,可以防止出现过拟合和模型过于复杂的情况。β为常数。
这里假设参数空间连续可微,则参数优化的方法为梯度下降,现在常采用随机梯度下降法,基于单个随机样本更新参数: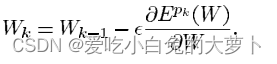
这里采用反向传播的神经网络学习算法。
三、模式识别系统的介绍
1.手写字识别:除了单个字符的识别,还包括将字符从单词或句子内相邻的字符中分离出来,即“分割”。这里包括使用启发式图像处理技术在字符之间生成大量潜在切割,然后根据识别器为每个候选字符给出的分数选择切割的最佳组合。在这种模型中,系统的准确性取决于启发式生成的切割质量,以及识别器区分正确分割的字符与字符片段、多个字符或其他错误分割的字符的能力。训练识别器执行这项任务是一项重大挑战。解决办法:
(1)通过分割器运行字符串图像,然后手动标记所有字符假设。不幸的是,这不仅是一项极其繁琐和昂贵的任务,而且很难始终如一地进行标记。
(2)完全消除分割。其思想是将识别器扫描到输入图像上的每个可能位置,并依赖识别器的“字符定位”特性,即识别器能够正确识别其输入字段中居中良好的字符,即使存在除此之外的其他字符,同时拒绝包含不居中字符的图像。然后,将识别器扫过输入获得的识别器输出序列馈送到GTN(图形变压器网络),该GTN考虑了语言约束,并最终提取最可能的解释。该GTN有点类似于HMM(隐马尔可夫模型),这使得该方法令人想起经典语音识别。虽然这种技术在一般情况下相当昂贵,但卷积神经网络的使用使其特别具有吸引力,因为它可以显著节省计算成本。
模式识别系统,通常由多个模块组成。为了确保全局损失函数可微,整个系统构建为一个前馈网络,所有模块都可微。每个模块的函数都应是连续可微的,且与内部参数有关,eg权重W,同时也与模块输入有关。
每个模块的函数为: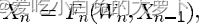
其中Xn、Xn-1分别为模块的输出和输入向量,Wp表示可学习参数。反向传播的过程如下所示:
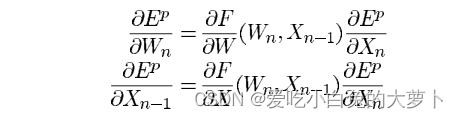
其中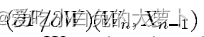
表示F在点(Wn,Xn-1)处关于W的雅克比矩阵。
四、孤立字符识别的卷积神经网络
1.全连接网络到卷积网络:
全连接网络的参数数量很大,给训练优化带来了难度。且全连接架构的一个缺陷是完全忽略了输入的拓扑结构。输入变量可以以任何(固定)顺序呈现,而不影响训练结果。相反,图像(或语音的时频表示)具有强大的二维局部结构:在空间或时间上邻近的变量(或像素)高度相关。局部相关性是在识别空间或时间对象之前提取和组合局部特征的众所周知优势的原因,因为相邻变量的配置可以分为少量类别(例如边缘、角点等)。卷积网络通过将隐藏单元的感受野限制为局部来强制提取局部特征。
卷积神经网络结合了三种架构思想,以确保一定程度的平移、缩放和失真不变性:
(1)局部感受野。通过局部视野,神经元可以提取基本的视觉特征,然后这些特征被随后的层结合起来,一检测更高阶的特征;
(2)共享权重(或权重复制)(eg.共享卷积核)。即对图像一部分有用的特征提取器可能对整个图像都有用,因此它们的接受域可以位于图像的不同位置,具有相同的权重向量;
(3)空间或时间子采样。
2、LeNet-5网络
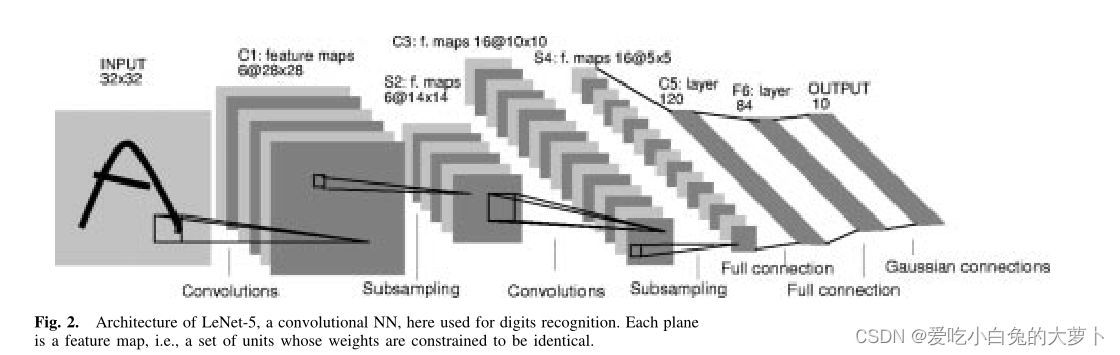
i输入平面接收大小大致正常化并居中的字符图像。层中的每个单元从位于小邻域中的一组单元接收输入。每个单元的输出集合被称为特征图。一个完整的卷积层包含多个特征映射(如:多通道卷积核、多卷积核),以提取多个特征。
C:表示卷积层
S:子采样层(包含池化和激活,起到降维作用)
F:线性层
input层:网络输入是3232像素大小的图片,并对输入进行了归一化处理,使输入均值约为0,方差约为1,加快了学习。
C1:第一个卷积层有有6个平面,每个平面都是一个特征图。特征图中的每个单元都有25个输入连接到输入中的一个55的区域。(即卷积核为55的)。参数个数为:6(55+1)=156,连接数为:1562828,最后得到6张(32-5+1)=28的2828特征图。
S1:该层包含六个要素图,前一层中的每个要素图一个。每个单位的感受野是前一层相应特征图中的2 2区域。每个单元计算其四个输入的平均值,将其乘以可训练系数,添加可训练偏差,并将结果通过一个S形函数传递。连续单位具有不重叠的连续感受野。因此,子采样层特征图的行数和列数是前一层特征图的一半。可训练系数和偏差控制了sigmoid非线性的影响。如果系数很小,则该单元以准线性模式运行,子采样层只会模糊输入。如果系数较大,则子采样单元可以视为根据偏差值执行“噪声或”或“噪声和”函数。即S1层包含6个22的卷积核进行池化(求平均),padding=0,stride=2。所以输出为6个1414的特征图。
即先降采样,再用sigmod激活函数进行激活: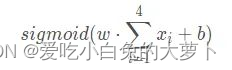
参数个数:(1+1)6
连接数:(22+1)61414
卷积和子采样的连续层通常交替进行,从而形成“双锥”:在每一层,特征图的数量随着空间分辨率的降低而增加。尽管当时没有诸如反向传播之类的全局监督学习过程可用。通过逐渐增加表示的丰富性(特征图的数量)来补偿空间分辨率的逐渐降低,可以实现对输入的几何变换的很大程度的不变性。由于所有的权值都是通过反向传播学习的,所以卷积网络可以被看作是合成了自己的特征提取器。权重共享技术有一个有趣的副作用,即减少自由参数的数量,从而减少机器的“容量”,减少测试误差和训练误差之间的差距。
C3:卷积层,采用16个 5×5xn 大小的多通道多卷积核(注意:同一个卷积核55n里面的每个通道的卷积核是不一样的),padding=0,stride=1 进行卷积,得到 16 个 10×10 大小的特征图:14-5+1=10。

由上面的图可以看出:卷积核里面包含6个553、9个554的、1个556的。具体的卷积核连接的特征图如上图所示。
!!为什么不将每个S2特征图连接到每个C3特征图?原因有两方面。首先,非完全连接方案将连接数保持在合理范围内。更重要的是,它迫使网络中的对称性打破。不同的特征映射被迫提取不同的(希望是互补的)特征,因为它们得到不同的输入集。
参数个数:(553+1)6+(554+1)6+(554+1)3+(556+1)1=1516。
连接数:15161010 = 151600。1010为输出特征层,每一个像素都由前面卷积得到,即总共经历1010次卷积。
S4: S4 层与 S2 一样也是降采样层,使用 16 个 2×2 大小的卷积核进行池化,padding=0,stride=2,得到 16 个 5×5 大小的特征图:10/2=5。
参数个数:(1+1)16=32。
连接数:(22+1)165*5= 2000。
C5: 卷积层,使用 120 个 5×5x16 大小的卷积核,padding=0,stride=1进行卷积,得到 120 个 1×1 大小的特征图:5-5+1=1。即相当于 120 个神经元的全连接层。
值得注意的是,与C3层不同,这里120个卷积核都与S4的16个通道层进行卷积操作。
参数个数:(5516+1)120=48120。
连接数:481201*1=48120
!!C5被标记为卷积层,而不是完全连接层,因为如果在保持其他一切不变的情况下使LeNet-5输入变大,则特征映射维数将大于1。
F6: F6 是全连接层,共有 84 个神经元,与 C5 层进行全连接,即每个神经元都与 C5 层的 120 个特征图相连。计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过 sigmoid 函数输出。
F6 层有 84 个节点,对应于一个 7x12 的比特图,-1 表示白色,1 表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。

output层:采用RBF径向基函数,最后要分成10类:0-9,每一类的输入有84个神经元,具体计算如下所示:
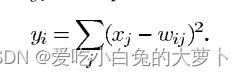
每个输出RBF单元计算其输入向量和参数向量之间的欧几里得距离。输入距离参数向量越远,RBF输出越大。即W表示参数向量,这里wij取-1或1,分别白色和黑色。由于每个数字都有一个有-1和1组成的编码,通过计算输入向量{xj}与参数向量{Wij}的距离,从而判断是哪一个符号。
这种表示法对于识别孤立数字并不特别有用,但对于识别取自完全可打印ASCII集的字符串非常有用。其基本原理是,类似且容易混淆的字符,例如大写“O”、小写“O”和零、小写“l”数字一,以及方括号和大写“I”,将具有类似的输出代码。如果该系统与能够纠正此类混淆的语言后处理器相结合,这将特别有用。由于可混淆类的代码相似,因此模糊字符的相应径向基函数的输出将相似,后处理器将能够选择适当的解释。
!!这里参考了https://redstonewill.blog.csdn.net/article/details/121804658?spm=1001.2014.3001.5502的文章
侵删!!















 1077
1077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









