







《Gradient-Based Learning Applied to Document Recognition》(《基于梯度学习在文档识别中的应用》)是卷积神经网络的开山之作,主要有LeNet-1~LeNet-5系列。这里主要实现LeNet-5。
摘要:将反向传播算法的多层神经网络应用在图像上,提出卷积神经网络。应用在两个方面:①在线手写识别的系统、②读取银行支票的图形转换器。
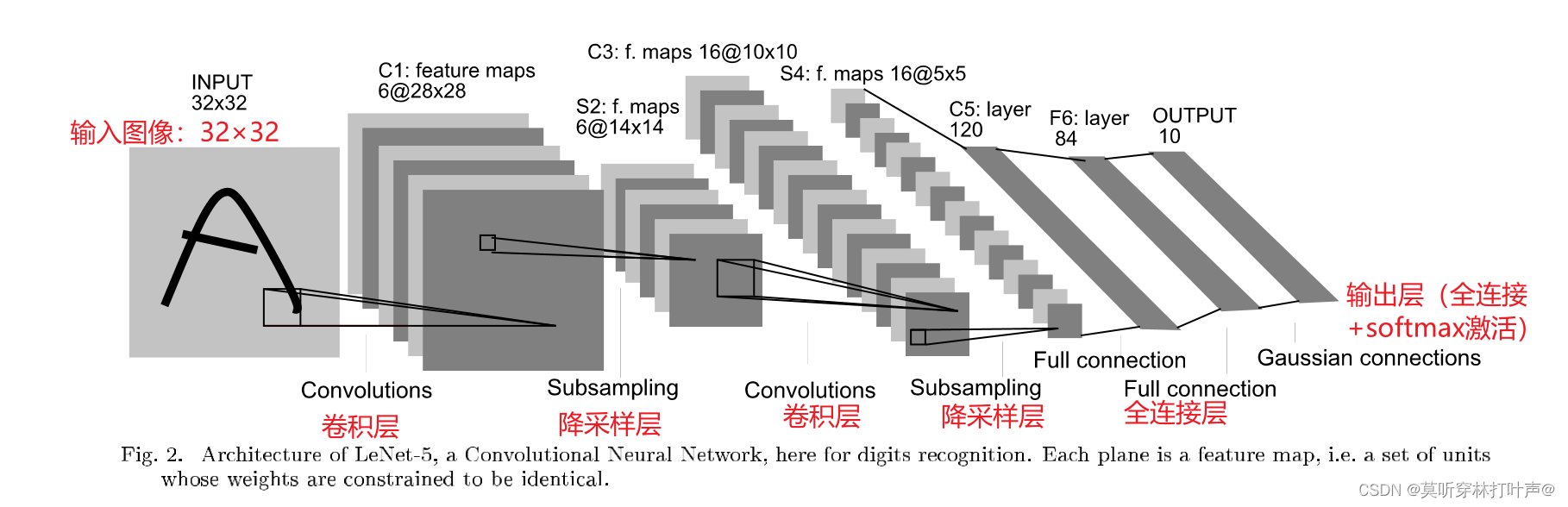
LeNet-5网络架构
卷积神经网络------用来处理图像问题。
LeNet-5是一个简单的卷积神经网络,有卷积层,降采样层,全连接层,输出层组成。
降采样(下采样):即为池化,将图像缩小。AlexNet将其更名为池化层。
记住:通道数=卷积核个数
- 局部连接:每个神经元仅与输入神经元的一块区域连接,这块局部区域(上一层神经元)称作感受野。在图像卷积操作中,即神经元在空间维度(H和W所在的平面)是局部连接,在深度上是全部连接。对于二维图像本身而言,也是局部像素关联性较强。这种局部连接保证了学习后的过滤器能够对于局部的输入特征有最强的相应。(局部接收信息)
- 权重共享:权重只是对于同一深度切片的神经元是共享的。在卷积层,通常采用多组卷积核提取不同特征,即对应不同深度切片的特征,不同深度切片的神经元权重不共享。偏置对同一深度切片的所有神经元都是共享的。
各层参数详解:
0、INPUT-输入层
输入图像的尺寸统一归一化为32×32。
1、第一层卷积层
输入图片:32×32
卷积核大小:5×5
卷积核个数:6
输出feature map大小:28×28,(32-5+1)=28
stride:1
2、第一层池化层
输入图片:28×28
采样区域:2×2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可偏置训练。结果通过sigmoid
过滤器个数:6
输出feature map大小:14×14,(28/2)
stride:2,选择最大池化层
3、第二层卷积层
输入:14×14
卷积核大小:5×5
卷积核个数16
输出feature map大小:10×10,(14-5+1)=10
stride:1
4、第二层池化层
输入:10×10
采样区域:2×2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
过滤器个数:16
输出feature map大小:5×5,(10/2)
stride:2,选择最大池化层
5、第三层卷积层当作全连接层
输入:16×5×5
输入:120
6、全连接层
输入:120
输出:84
7、输出层Softmax-output
全连接层:输入:84,输出:10(分成了10类)
加softmax层
pytorch搭建网络结构
1、搭建网络模型
- 要将Softmax()写到classifier里,没有参数。第一次写到foward()里了,写成x=nn.Softmax(x)报错!
class LeNet5(nn.Module):
def __init__(self,num_classes,grayscale=False) -> None:
super().__init__()
self.grayscale=grayscale
self.num_classes=num_classes
if self.grayscale:
in_channels=1
else:
in_channels=3
self.feature=nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=6,
kernel_size=5,stride=1),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,5,1),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.classifier=nn.Sequential(
nn.Linear(16*5*5,120),
nn.Linear(120,84),
nn.Linear(84,num_classes),
nn.Softmax(dim=1) # 输出10个可能的概率
)
def forward(self,x):
x=self.feature(x) #输出16*5*5的feature map
x=torch.flatten(x,1) #展平(1,16*5*5)
x=self.classifier(x) #输出10个
return x
2、随机给一个数,测试网络输出结果
num_classes=10 #分类数目
grayscale=True #是否为灰度数
model=LeNet5(num_classes,grayscale)
input_data=torch.randint(10,size=(1,1,32,32),dtype=torch.float32)
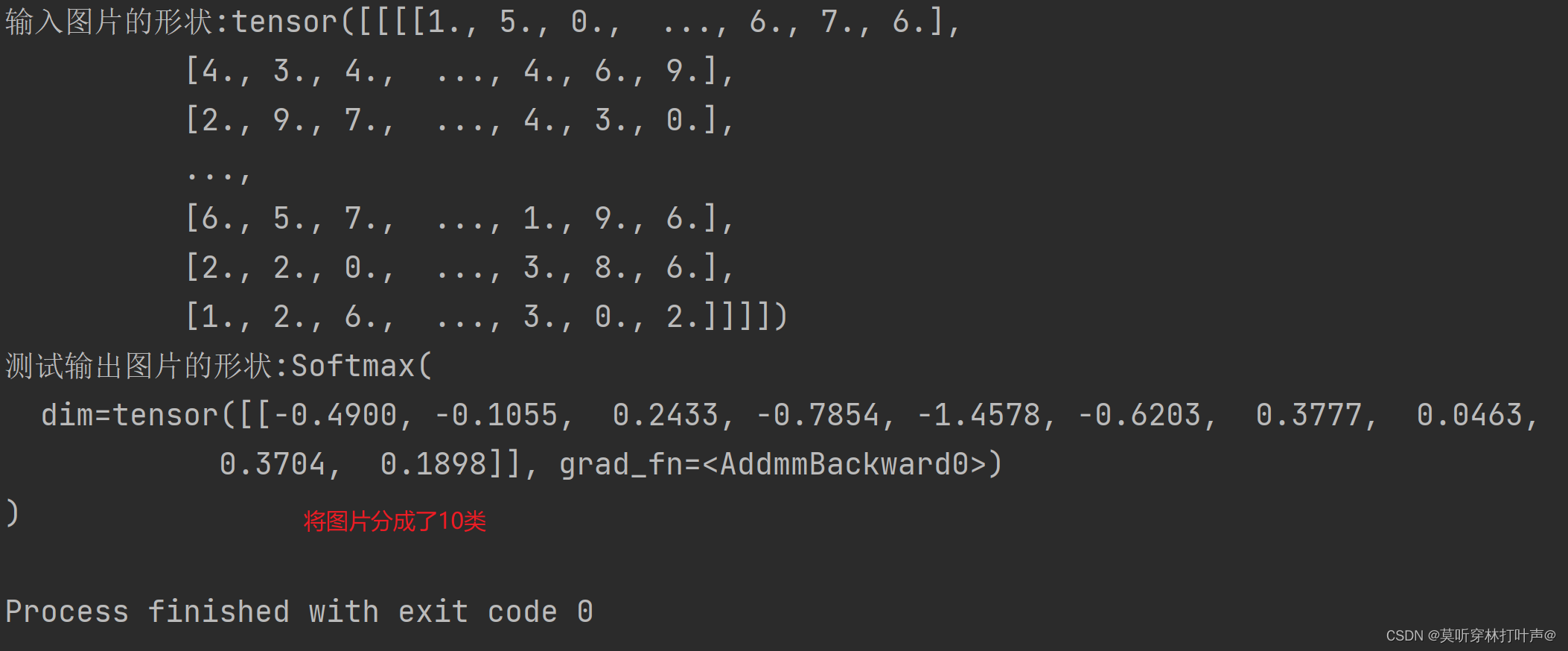
print('输入图片的形状:{}'.format(input_data))
output_data=model(input_data)
print('测试输出图片的形状:{}'.format(output_data))
输出结果:
3、尝试分类手写数字
使用pytorch提供的数据集:
- 将每个图片转成tensor数据类型,大小变成32×32,因为LeNet-5输入的图片大小为32×32。
train_data=torchvision.datasets.MNIST(root="./MNIST",train=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor(),
]),
download=True)
test_data=torchvision.datasets.MNIST(root="./MNIST",train=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.Resize((32, 32)),torchvision.transforms.ToTensor(),
]),
download=True)
train_dataloader=DataLoader(dataset=train_data,batch_size=100,drop_last=False)
test_dataloader=DataLoader(dataset=test_data,batch_size=100,drop_last=False)
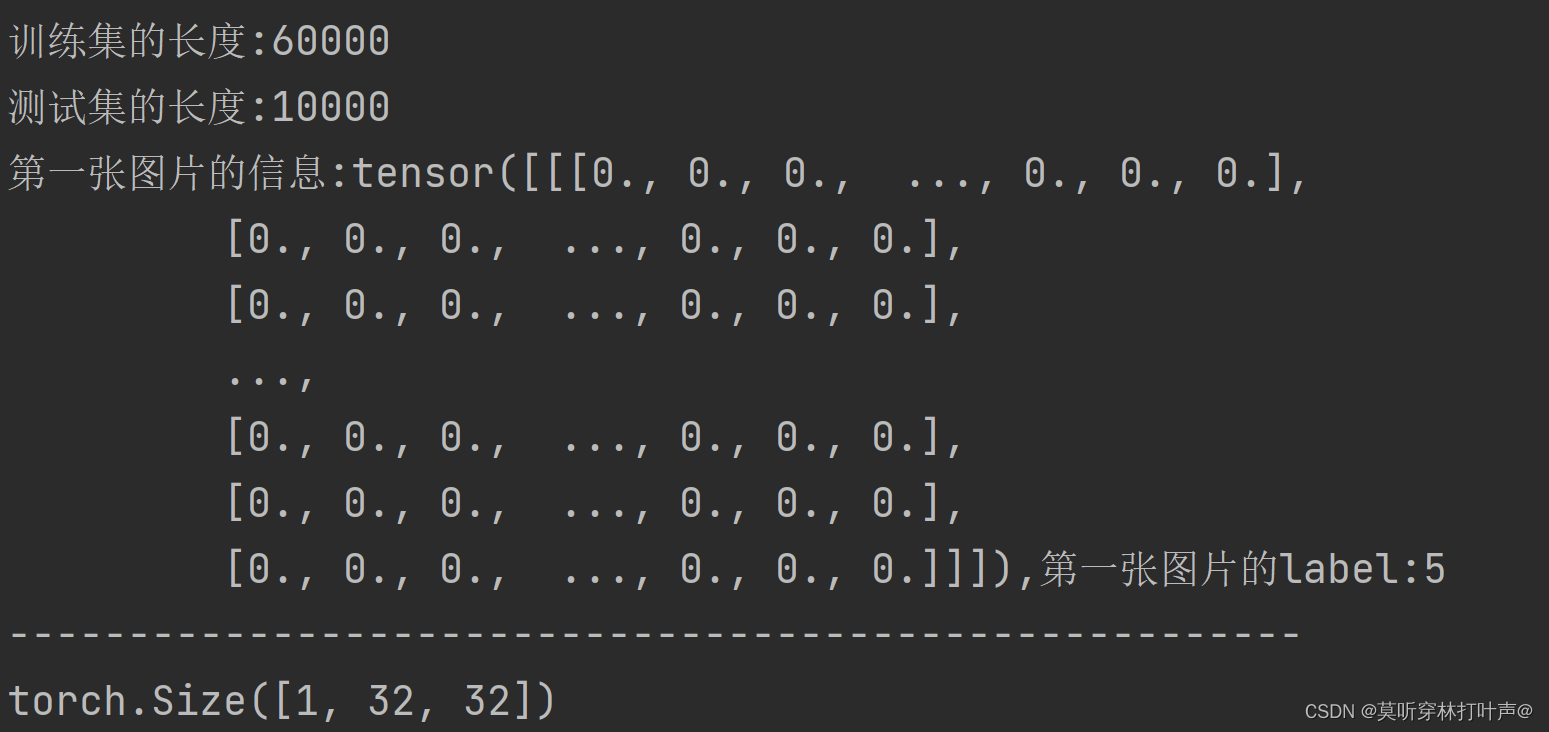
print('训练集的长度:{}'.format(len(train_data)))
print('测试集的长度:{}'.format(len(test_data)))
#print('第一张图片的信息:{}'.format(train_data[0]))
img,label=train_data[0]
print('第一张图片的信息:{},第一张图片的label:{}'.format(img,label))
print('------------------------------------------------------')
print(img.shape)
输出结果:图片的类型为tensor数据类型,label为int数据类型。是符合pytorch网络的输入输出的。
4、训练网络
loss_fn=nn.CrossEntropyLoss()
loss_fn=loss_fn.cuda()
learning_rate=1e-4
optimizer=torch.optim.Adam(model.parameters(),learning_rate)
total_train_step=0
total_test_step=0
epoch=20
for i in range(epoch):
print("-------------------第{}轮训练开始------------------".format(i))
model.train()
for data in train_dataloader:
imgs,targets=data
imgs=imgs.cuda()
targets=targets.cuda()
outputs=model(imgs)
loss=loss_fn(outputs,targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
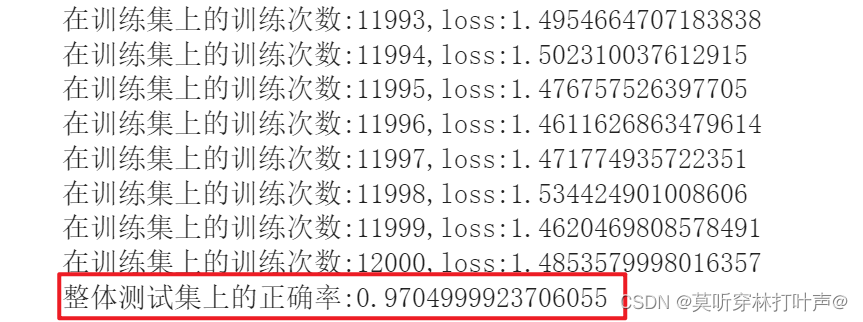
print("在训练集上的训练次数:{},loss:{}".format(total_train_step,loss.item()))
model.eval()
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
imgs=imgs.cuda()
targets=targets.cuda()
outputs=model(imgs)
loss=loss_fn(outputs,targets)
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的正确率:{}".format(total_accuracy/len(test_data)))
total_test_step=total_test_step+1
结果:结果还不错!
这个网络是世界上第一个卷积神经网络,网络比较小,手写数字数据集也小,如果用在大型数据集上,效果就不好了!

















 1897
1897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











