







流/批/OLAP一体的Flink引擎介绍
开源生态
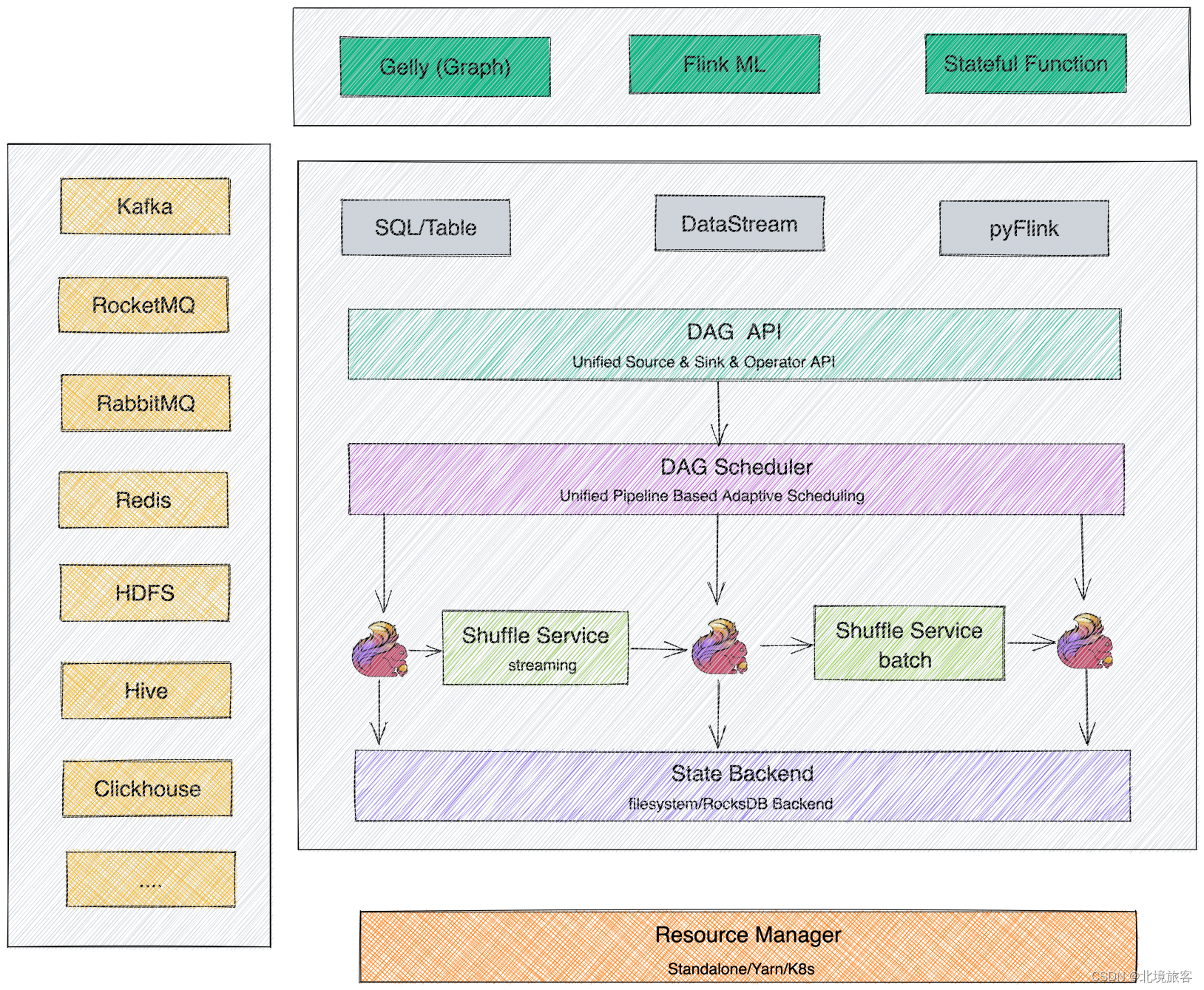
2.Flink整体架构
2.1Flink分层框架
1.SDK层:分为三类:SQL/Table、DataStream、Python;
2.执行引擎层(Runtime层):Runtime层提供统一的DAG,用来描述数据处理的流水线,不管是刘还是批,都会转换为DAG图,调度层再把DAG转换成分布式环境下的Task,Task之间通过Shuffle传输数据;
3.状态存储层:负责存储算子的状态信息;
4.资源调度层:目前Flink可以指出部署在多种环境
2.2Flink总体框架
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j2HwfoBw-1658980629564)(D:\学习笔记\字节跳动大数据青训营笔记\picture\day2\Flink总体框架.png)]](https://img-blog.csdnimg.cn/4c74b108e75943b7a4805274586db281.png)
1.JobManager(JM):负责整个任务的协调工作,包括调度task、触发协调Task做Checkpoint、协调容错恢复。
-
Dispatcher:接受作业,拉起JobManager来执行作业,并在JobMaster挂掉之后恢复作业。
-
JobMaster:管理一个job的整个生命周期,会向ResourceManager申请slot,并将task调度到对应TM上。
-
ResourceManage:负责slot资源的管理和调度,Task manager拉起之后会向RM注册。
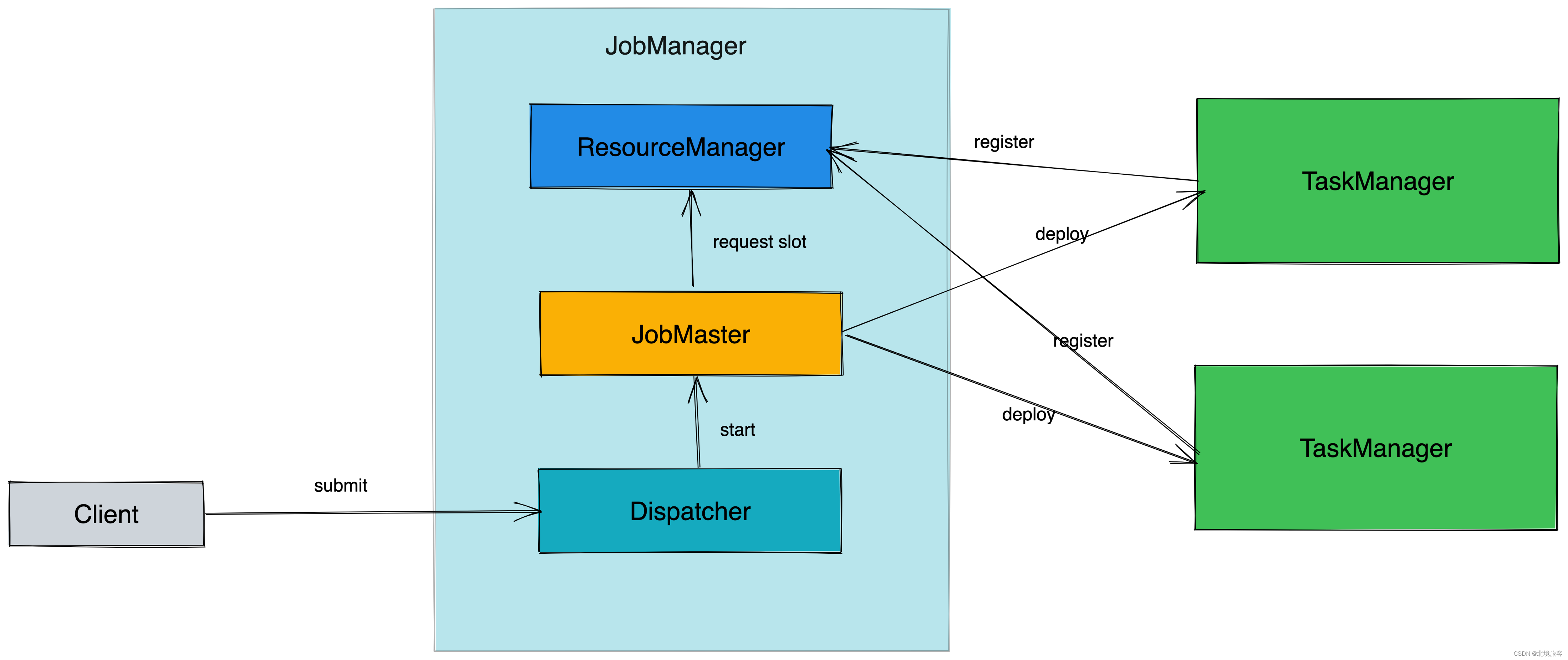
2.TaskManager(TM):负责执行一个DataFlow Graph的各个task以及data streams 的buffer和数据交换。
2.3Flink如何做到流批一体
批式计算与流式计算的核心区别
| 维度 | 流式计算 | 批式计算 |
|---|---|---|
| 数据流 | 无限数据集 | 有限数据集 |
| 时延 | 低时延、业务会感知运行中的情况 | 实时性要求不高,只关注最终结果的产出时间 |
Flink为什么可以做到流批一体
批式计算是流式计算的特例,对于Flink,==无边界数据集(流式数据)是一种数据流,一个无边界的数据流可以按照时间切断成一个个有边界的数据集,因此有界数据集(批式数据)==也是一种数据流。
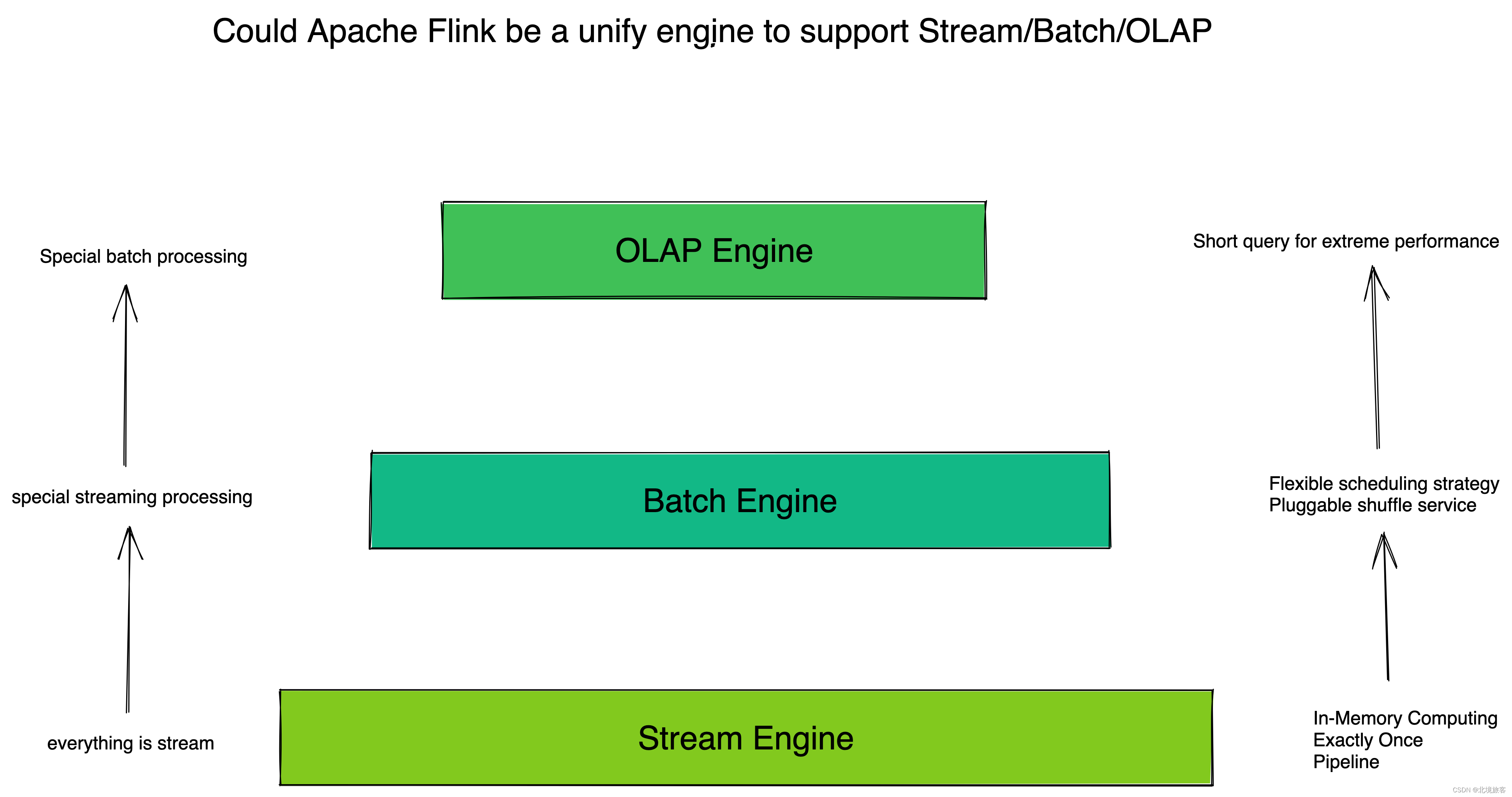
Apache Flink主要从以下几个模块来做到流批一体
1.SQL层
2.DataSteam API层统一,批和流都可以使用DataSteam API开发
3.Schedler层架构统一,支持流批场景
4.Failover Recovery层架构统一,支持流批场景
5.Shuffle Service层架构统一,根据不同场景选择不同服务
Schedler层
主要负责将作业的DAG转换为在分布式环境中可执行的task
在1.12之前的版本中,Flink支持以下两种调度模式
| 模式 | 特点 | 场景 |
|---|---|---|
| EAGER | 申请一个作业所需的所有资源,然后同时调度这个作业的所有task,所有task之间采用pipeline通信 | Stream作业场景 |
| LAZY | 先调度上游,等待上游产生护具或结束后再调度下游,类似Spark的STAGE执行模式 | Batch作业场景 |
EAGER模式会调用所有16个task,集群需要足够的资源
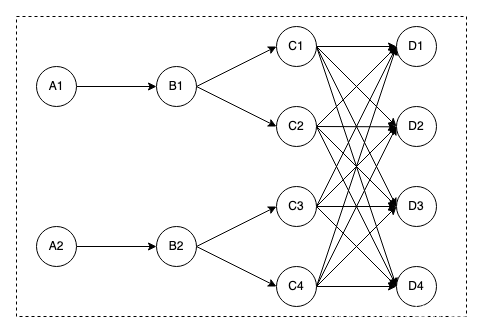
LAZY模式最小调度一个task,集群有一个slot资源可以运行
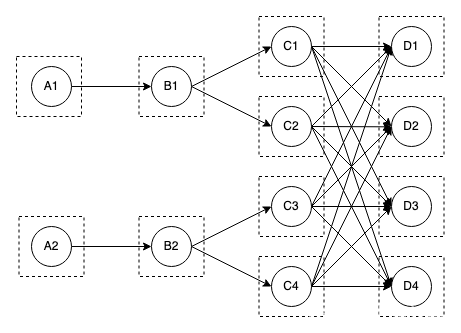
Shuffle Service层
==Shuffle:==在分布式计算中,用来连接上下游数据交互的过程叫做Shuffle。
实际上,分布式计算中所有涉及到上下游衔接的过程,都可以理解为Shuffle。
针对不同的分布式计算框架,Shuffle通常有几种不同的实现:
-
基于文件的Pull Based Shuffle,比如Spark或MR。具有较高容错性,适合大规模批处理作业,容错性和稳定性更好。
-
基于Pipeline的Push Based Shuffle,比如Flink,Storm,具有低延时和高性能,但是因为shuffle数据没有存储下来,如果是batch任务的话,就需要重跑恢复。
流和批Shuffle之间的差异:
-
Shuffle的生命周期:流作业Shuffle数据与Task是绑定的,批作业和Shuffle是解耦的。
-
Shuffle数据存储介质:流作业的Shuffle(生命周期短,要保证实时性)存储在内存,批作业的Shuffle(数据量大,有容错需求)存储在磁盘。
-
Shuffle的部署方式:流作业的Shuffle服务和计算节点部署在一起,可以减少网络开销,从而减少延迟,批作业不同。
不同场景的服务模式:
==1.Stream和OLAP场景:==为了性能,通常会使用基于Pipeline的Shuffle模式。
==2.Batch场景:==一般会选取Blocking的Shuffle模式。
3.Flink架构优化
三种场景对比
| 流式计算 | 批式计算 | 交互式分析 | |
|---|---|---|---|
| SQL | Yes | Yes | Yes |
| 实时性 | 高、处理延退毫秒级别 | 低 | 高、查询延退在秒级但要求高并发查询 |
| 容错能力 | 高 | 中,大作业失败重跑代价高 | 没有,失败重试即可 |
| 状态 | Yes | No | No |
| 准确性 | Exactly Once 要求高,重跑需要恢复之前的状态 | Exactly Once 失败重跑即可 | Exactly Once 失败重跑即可 |
| 扩展性 | Yes | Yes | Yes |
三种业务场景为什么可以用一套引擎解决
1.批式计算是流式计算的特殊场景
2.OLAP计算是一种特殊的批式计算,它对并发性和实时性要求更高,其他场景和普通批式作业没有态度区别
Flink做OLAP优势
1.引擎统一:降低学习成本,提高开发效率,提高维护效率
2.既有优势:内存计算,Code-gen,Pipeline Shuffle,Session模式的MPP架构
3.生态支持:跨数据源查询支持,CP-DS基准测试性能强
Flink做OLAP的挑战
1.秒级和毫秒级的小作业
2.对Latency+QPS的要求高
3.作业频繁启停,资源碎片
Flink构架现状
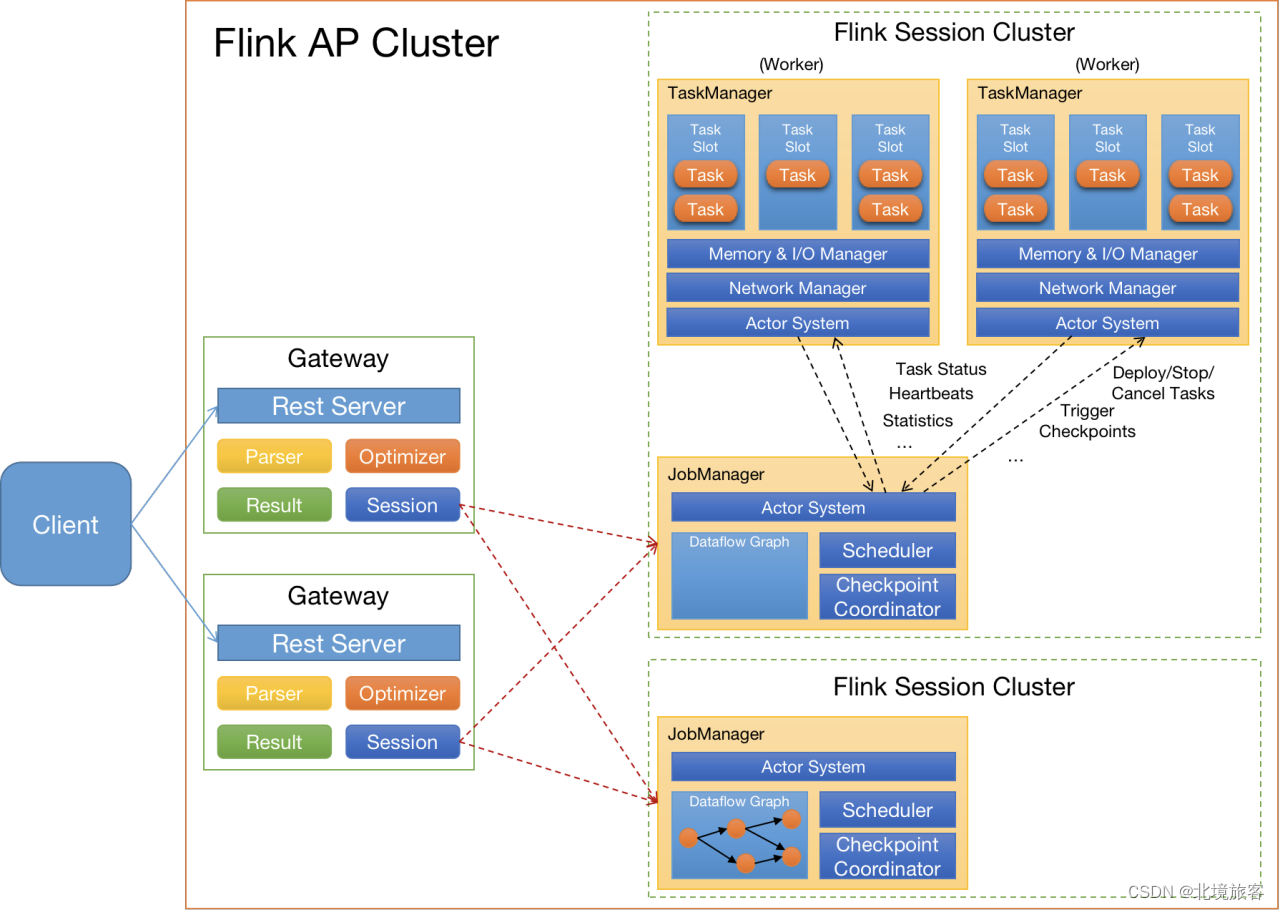
-
Client:提交SQL Query
-
Gateway:接受Client提交的SQL Query,对SQL进行语法解析和查询优化,生成Flink作业执行计划,提交给Session集群
-
Session Cluster:执行作业调度及计算,并返回结果。
FlinkOLAP架构存在的问题与设想:
1. 架构与功能模块
-
JM与RM在一个进程内启动,无法对JM进行水平扩展。
-
Gateway与Flink Session Cluster互相独立,无法进行统一管理。
2. 作业管理及部署模块
-
JM处理和调度作业时,负责的功能比较多,导致单作业处理时间长,并占用过多内存。
-
TM部署计算任务时,任务初始化部分好事严重,消耗大量CPU。
3. 资源管理及计算任务调度
-
资源申请及计算任务调度
-
资源申请及资源释放流程链路过长
-
Slot作为资源管理单元,JM管理slot资源,导致JM无法感知到TM维度的资源分布,是的资源管理完全依赖于RM。
4. 其他
-
作业心跳与Failover机制,并不适合AP这种秒级或毫秒级计算场景
-
AP目前使用Batch算子进行计算,这些算子初始化比较耗时。
Flink最终演化结果
















 2519
2519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









