






更多详细具体代码请订阅专栏,可远程部署环境(远程实现):https://blog.csdn.net/m0_52343631/category_12482955.html
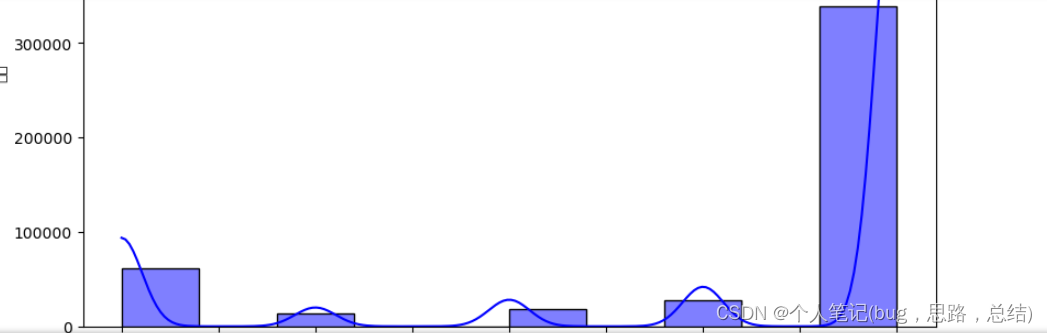
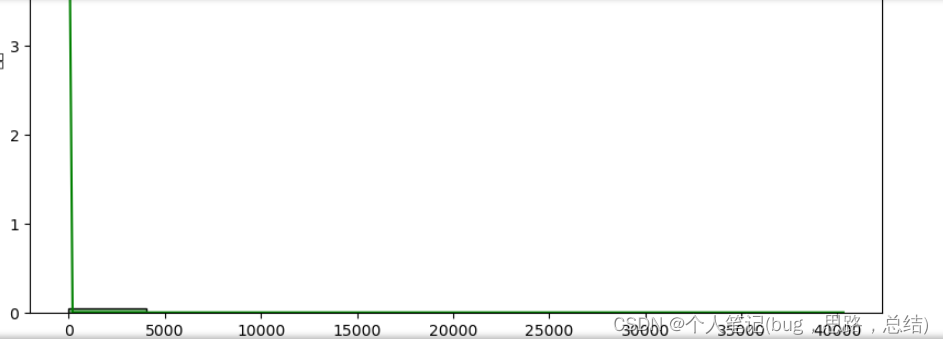
问题一:请分别绘制附件中抖音用户对抖音 APP 的“评分”和“点赞数”的 直方图,并通过假设检验判断“评分”和“点赞数”分布是否服从正态分布?

python代码示例(不完整,详细代码请订阅专栏:https://blog.csdn.net/m0_52343631/category_12482955.html)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import shapiro
# 数据加载
# data = pd.read_csv("douyin.csv", usecols=['评分', '点赞数'], encoding='utf-8')
data = pd.read_csv('douyin.csv', usecols=['评分', '点赞数'], encoding='GB18030')
# 绘制“评分”的直方图
plt.figure(figsize=(10, 6))
sns.histplot(data['评分'], bins=10, kde=True, color='blue')
plt.title('评分的直方图')
plt.xlabel('评分')
plt.ylabel('频次')
plt.show()
# 绘制“点赞数”的直方图
plt.figure(figsize=(10, 6))
sns.histplot(data['点赞数'], bins=10, kde=True, color='green')
plt.title('点赞数的直方图')
plt.xlabel('点赞数')
plt.ylabel('频次')
plt.show()
问题二:请通过数据分析抖音用户对抖音 APP 的评论时间主要集中在一天的 哪个时间段?“评分”最高和“点赞数”最多的抖音版本分别是哪个版本?
![]()

python代码示例(不完整,详细代码请订阅专栏:https://blog.csdn.net/m0_52343631/category_12482955.html)
import pandas as pd
from datetime import datetime
# 使用示例数据创建DataFrame
data = pd.read_csv('douyin.csv', encoding='GB18030')
df = pd.DataFrame(data)
# print(df)
# 将评论时间转换为datetime对象,方便后续处理
df['评论时间'] = pd.to_datetime(df['评论时间'])# 提取小时并统计评论数
df['小时'] = df['评论时间'].dt.hour
time_distribution = df['小时'].value_counts().sort_index()print("评论时间分布:")
print(time_distribution)
问题三:请分析附件中抖音用户的评语,通过自然语言处理进行文本的情感 分析,建立数学模型,判断用户的每条评语属于“积极”、“消极”还是“中立” 的态度,并计算出附件中所有评语中“积极”、“消极”和“中立”的比例。

python代码示例(不完整,详细代码请订阅专栏:https://blog.csdn.net/m0_52343631/category_12482955.html)
import pandas as pd
from textblob import TextBlob
# 使用示例数据创建DataFrame
data = pd.read_csv('douyin.csv', encoding='GB18030')
df = pd.DataFrame(data)
# 确保评语列为字符串类型
df['评语'] = df['评语'].astype(str)
# 定义情感分析函数
def sentiment_analysis(text):
analysis = TextBlob(text)
if analysis.sentiment.polarity > 0:
return '积极'
elif analysis.sentiment.polarity < 0:
return '消极'
else:
return '中立'
# 应用情感分析函数到评语列
df['情感倾向'] = df['评语'].apply(sentiment_analysis)问题四:请绘制附件中所有抖音用户评语的“词云图”,并分别绘制评语属 于“积极”、“消极”和“中立”的“词云图”,然后分析“词云图”中的高频 词汇信息,基于此请给北京字节跳动公司的“抖音”部门提出你们的建议




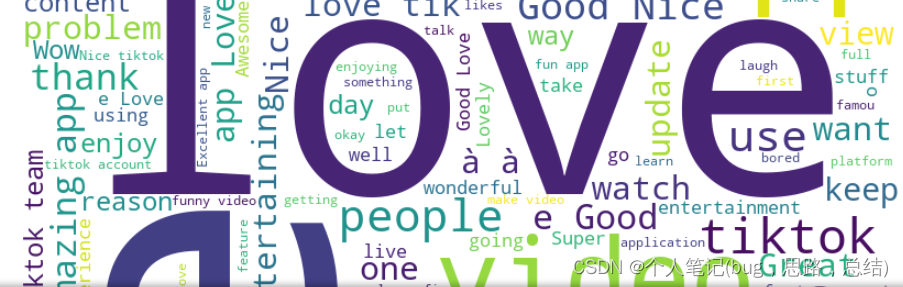



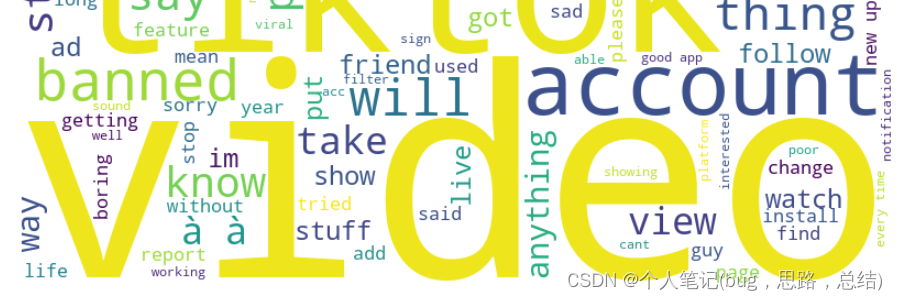



python代码示例(不完整,详细代码请订阅专栏:https://blog.csdn.net/m0_52343631/category_12482955.html)
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def generate_word_cloud(text):
wordcloud = WordCloud(width = 800, height = 800,
background_color ='white',
min_font_size = 10).generate(text)
# Plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()















 611
611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











