







 本文详细介绍了决策树算法的实验过程,包括实验目的、数据预处理、算法描述、实验步骤(如数据集选择、离散化处理和构建决策树),以及实验结果分析。通过实际操作演示了如何使用Python和JupyterNotebook实现决策树分类,并展示了如何处理连续型数据和计算香农熵。
本文详细介绍了决策树算法的实验过程,包括实验目的、数据预处理、算法描述、实验步骤(如数据集选择、离散化处理和构建决策树),以及实验结果分析。通过实际操作演示了如何使用Python和JupyterNotebook实现决策树分类,并展示了如何处理连续型数据和计算香农熵。
实验 2:决策树算法实验
一、实验目的及要求:
(1)掌握决策树算法模型的实现过程及基本方法。
(2)掌握决策树算法的实现。
二、实验内容:
(1)选择合适的数据集。
(2)数据预处理。
(3)决策树算法模型设计。
三、设备要求
(1) PC 一台。
(2) Python 或 C++或 JAVA 编程软件。
四、算法描述
1、分类算法名称
决策树是一种非参数化监督学习方法,用于分类和回归。目标是创建一个模型,通过学习从数据功能推断出的简单决策规则来预测目标变量的值。以二分类任务为例,我们希望从给定训练数据集学得一个模型用以对新示例进行分类,这个把样本分类的任务,可看作对“当前样本属于正类吗?”这个问题的“决策”或“判定”过程。顾名思义,决策树是基于树结构来进行决策的,这恰是人类在面临决策问题时一种很自然的处理机制。
2、算法描述
(1)、算法流程
一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点;叶结点对应于决策结果,其他每个结点则对应于一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根结点包含样本全集。从根结点到每个叶结点的路径对应了一个判定测试序列。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的“分而治之”(divide-and-conquer)策略。伪代码如下所示:


五、实验结果分析
1、实验设置
利用Jupyter Notebook编写python语言进行决策树分类算法分析。
2、实验数据
每个列分别表示:[‘卷面成绩’,‘班级排名’,‘综测分’,‘奖学金等级’],如下图1所示。
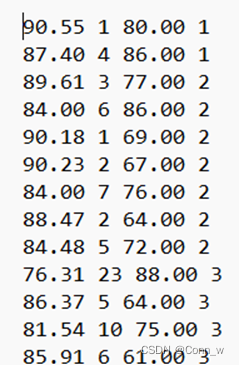
图1、实验部分数据
3、数据处理
可以看到属性的数据类型都为连续型,由于连续属性的可取值数目不再有限,因此不能直接对连续型属性的可取值来对节点进行划分,接下来要将数据离散化。
最简单暴力的方法,排序后按比例划分n类(暂时不考虑信息增益):
mydata=createData(‘E:/grade.txt’)
for i in range(3):
discretedata(mydata,i,3)
print(mydata)
结果如下图2所示,这里所有属性都分为3个等级,可以根据实践情况再调整。

图2、划分数据为3个属性
4、实验结果与分析
(1)、计算出计算给定数据集的香农熵为下图3所示。
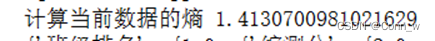
图3、香农熵值
(2)、按照给定特征划分数据集,结果如下图4所示。
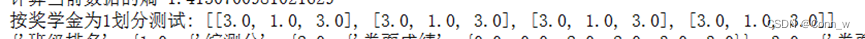
图4、划分数据集结果
(3)、递归构建决策树
采用递归的原则处理数据集,但程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类时递归结束。
如果数据集已经处理了所有的属性,但是类标签依然不是唯一的,此时我们需要决定如何定义该叶子节点,在这种情况下,通常会采用多数表决的方法决定叶子节点的分类。
测试输出结果如下图5所示。

(4)、使用Matplotlib注解绘制树形图,如下图6所示。
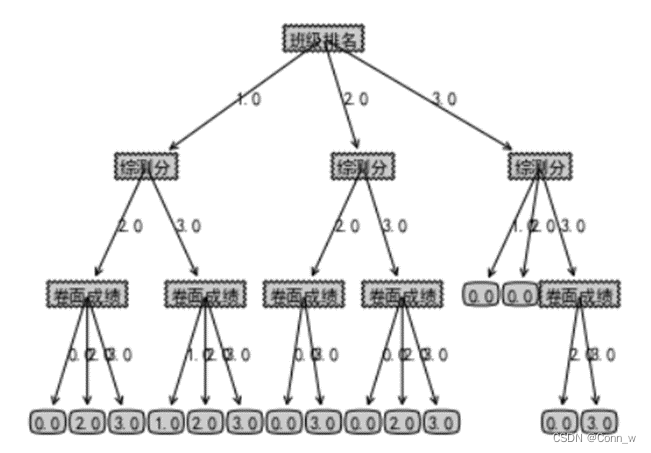
(5)、实验结果分析
从数据划分上看:为获得更高的奖学金等级,班级排名越低越好;综测分越高越好;卷面成绩越高越好
1、在绘制的决策树中可以看出,班级排名为首选分类属性(越低表示班级排名越高,越容易拿到奖学金),这也符合实际。
2、第二个属性为综测分,最右边的节点可以看出,当综测分等级为3时(最高),综测分低于2等级的都不可能拿到奖学金(分支下所有实例都具有相同类别),等于3时有可能拿到3等奖学金
3、后期可以根据熵来处理连续型属性,当前采用3等级划分已经符合实际了,下次实验有待改进。
七、实验总结
通过本次数据挖掘的决策树分类实验,了解了决策树算法的实现过程及基本方法。
决策树和其他模型相比有以下优点:生成的规则可理解;效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度;决策树算法的时间复杂度较小,为用于训练决策树的数据点的对数。
决策树的目标函数是最小化损失函数,损失函数是正则化最大似然函数。
分类树采用叶子节点里概率最大的类别作为当前节点的预测类别。回归树输出采用的是用最终叶子的均值或者中位数来预测输出结果。
附:源代码
from numpy import *
#加载数据
def createData(filename):
fr=open(filename,'r')
arrayOLines=fr.readlines()
random.shuffle(arrayOLines)#打乱
numberOfLines=len(arrayOLines)#数据的数量
returnMat=zeros((numberOfLines,4))
index=0
for line in arrayOLines:
line=line.strip()
listFromLine=line.split(' ')
returnMat[index,:]=listFromLine[0:4]
index+=1
return returnMat
#离散化数据
#data数据 axis待划分属性 num划分几类
def discretedata(data,axis,num):
len_data=len(data)
#求该属性的最大值和最小值
max=0;min=100
for i in range(len_data):
if data[i][axis]>max:
max=data[i][axis]
if data[i][axis]<min:
min=data[i][axis]
#划分区间
degree=(max-min)*1.0/num
limit=[min]
for i in range(num):
limit.append(min+degree*(i+1))
#修改对应的值,1代表最低级
for one_data in data:
for i in range(len(limit)-1):
if one_data[axis]>= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











