







InstructPix2Pix: Learning to Follow Image Editing Instructions
我们提出了一种根据人类指令编辑图像的方法:给定输入图像和告诉模型该做什么的书面指令,我们的模型遵循这些指令来编辑图像。
为了获得这个问题的训练数据,我们结合了两个大型预训练模型的知识——一个语言模型(GPT-3)和一个文本到图像模型(Stable Diffusion)——来生成一个大型图像编辑示例数据集。
我们的条件扩散模型InstructPix2Pix是在我们生成的数据上进行训练的,并在推理时推广到真实图像和用户编写的指令。由于它在向前传递中执行编辑,并且不需要每个示例的微调或反转,因此我们的模型可以在几秒钟内快速编辑图像。我们为输入图像和书面说明的不同集合展示了令人信服的编辑结果
模型结合gpt3和SD生成了一个用于图像编辑的数据集
作者使用生成的数据集训练了一个条件扩散模型来实现文本编辑图像

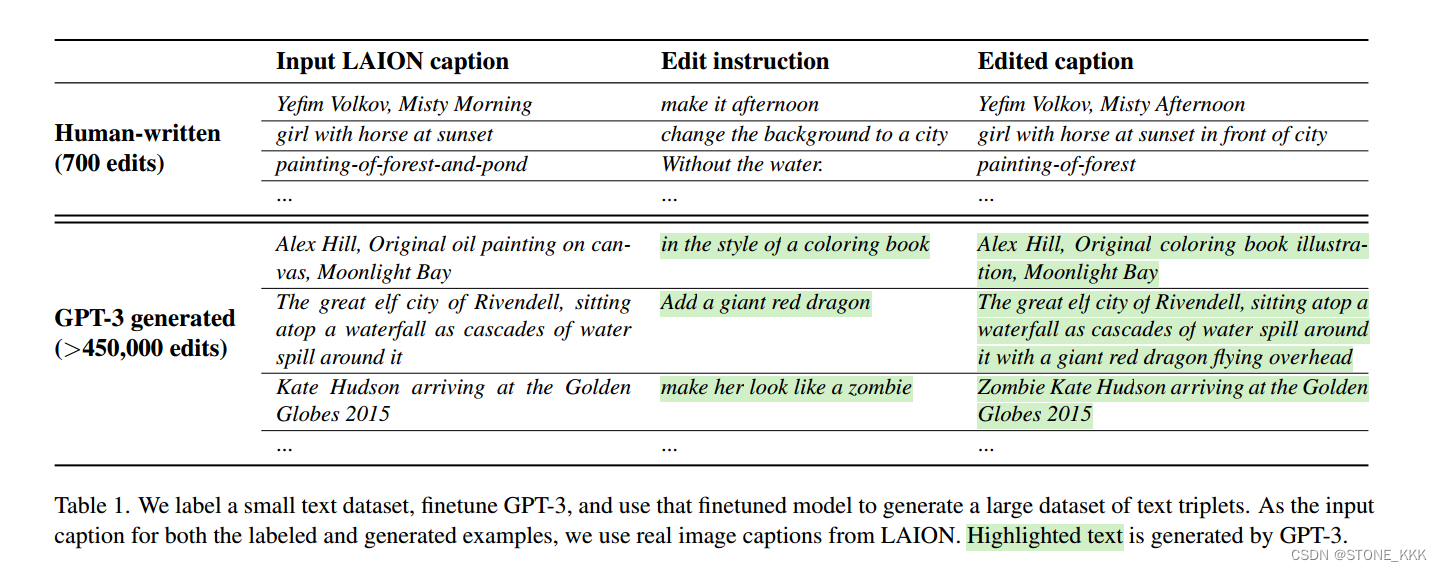

数据生成
作者使用了700条人工标注的文本编辑指令三元组微调GPT-3,之后使用微调过的GPT-3生成大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4464
4464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









