







InstructPix2Pix: Learning to Follow Image Editing Instructions
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
我们提出一种根据人类指令编辑图像的方法:给定一个输入图像和一份书面指令,告诉模型该如何操作,我们的模型按照这些指令来编辑图像。为了获得这个问题的训练数据,我们结合了两个大型预训练模型的知识——一个是语言模型(GPT-3),另一个是文本到图像模型(Stable Diffusion),生成了一个大型的图像编辑示例数据集。我们的有条件扩散模型 InstructPix2Pix,在我们生成的数据上进行训练,并在推理时推广到真实图像和用户编写的指令。由于它在正向传播中执行编辑,不需要每个示例的微调或反演,因此我们的模型能够在几秒钟内快速编辑图像。我们展示了对各种输入图像和书面指令的引人注目的编辑结果。
更多结果请参见我们的项目页面:timothybrooks.com/instruct-pix2pix

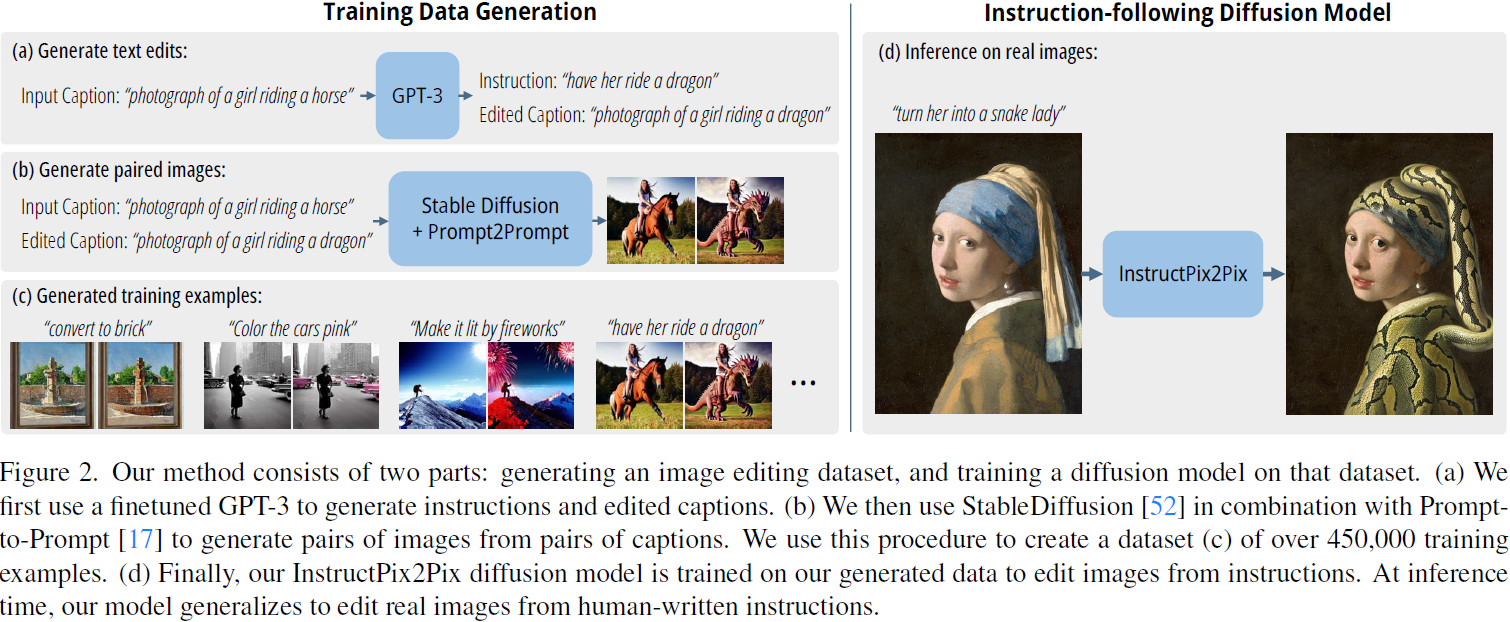
3. 方法
我们将基于指令的图像编辑视为一个监督学习问题:(1)首先,我们生成一对训练数据集,其中包括文本编辑指令和编辑前/后的图像(第 3.1 节,图 2a-c),然后(2)我们在这个生成的数据集上训练一个图像编辑扩散模型(第 3.2 节,图 2d)。尽管使用生成的图像和编辑指令进行训练,我们的模型能够通过任意人类编写的指令推广到对真实图像的编辑。请参见图 2,了解我们方法的概述。
3.1. 生成多模态训练数据集
3.1.1 生成指令和配对标题
我们首先完全在文本领域操作,在这里,我们利用一个大型语言模型处理图像标题,并生成编辑指令以及编辑后的文本标题。例如,如图 2a 所示,给定输入标题 “一个女孩骑马的照片”,我们的语言模型可以生成一个合理的编辑指令 “让她骑龙” 和一个经过适当修改的输出标题 “一个女孩骑龙的照片”。 在文本领域操作使我们能够生成大量丰富多样的编辑,同时保持图像变化与文本指令之间的对应关系。
’我们的模型通过在一个相对较小的人工编写的编辑三元组数据集上对 GPT-3 进行微调来进行训练:(1)输入标题,(2)编辑指令,(3)输出标题。为了生成微调数据集,我们从 LAION-Aesthetics V2 6.5+ [57] 数据集中随机抽取了 700 个输入标题,并手动编写了指令和输出标题。请参见表 1a,其中包含我们书面指令和输出标题的示例。 利用这些数据,我们使用默认训练参数对GPT-3 Davinci 模型进行了一次单轮微调。

受益于 GPT-3 的丰富知识和泛化能力,我们微调后的模型能够生成富有创意但合理的指令和标题。请参见表 1b,其中包含 GPT-3 生成数据的示例。我们的数据集是通过使用这个训练模型生成大量编辑和输出标题来创建的,其中输入标题是来自 LAION-Aesthetics 的真实图像标题(不包括具有重复标题或重复图像 URL 的样本)。我们选择了 LAION 数据集,是因为它规模庞大,内容多样(包括对专有名词和流行文化的引用),以及媒介多样(照片、绘画、数字艺术)。LAION 的一个潜在缺点是它相当嘈杂,并包含一些毫无意义或欠描述的标题——然而,我们发现通过数据集过滤(第 3.1.2 节)和无分类器指导(第 3.2.1 节)的组合,可以减轻数据集的噪音。我们最终生成的指令和标题的语料库包含 454,445 个示例。
3.1.2 从配对标题生成配对图像
接下来,我们使用一个预训练的文本到图像模型将一对标题(涉及编辑前后的图像)转换为一对图像。将一对标题转换为一对相应的图像的一个挑战在于,即使在条件提示微小变化的情况下,文本到图像模型也不能保证图像的一致性。例如,两个非常相似的提示:“一只猫的图片” 和 “一只黑猫的图片” 可能会生成截然不同的猫的图像。这对于我们的目的是不适用的,因为我们打算将这些配对数据用作训练模型编辑图像的监督(而不是生成不同的随机图像)。因此,我们使用了 Prompt-to-Prompt [17],这是一种旨在鼓励文本到图像扩散模型生成多个相似生成的最新方法。这是通过在某些去噪步骤中使用借用的交叉注意力权重来实现的。图 3 显示了带有 Prompt-to-Prompt 和不带的抽样图像的比较。

虽然这在很大程度上有助于使生成的图像相似,不同的编辑可能需要在图像空间中进行不同程度的更改。例如,较大幅度的更改,比如大规模改变图像的结构(例如,移动物体、用不同形状的物体替换)可能需要在生成图像对中较少的相似性。幸运的是,Prompt-to-Prompt 具有一个参数,可以控制两个图像之间的相似性:共享注意力权重的去噪步骤的比例 p。不幸的是,仅通过标题和编辑文本来确定 p 的最佳值是困难的。因此,我们对每对标题,生成了 100 个图像样本对,每个都有一个随机的 p ~ U(0.1, 0.9),并使用基于 CLIP 的度量来过滤这些样本:在 CLIP 空间中的方向相似度,由 Gal 等人引入 [14]。该度量衡量了两个图像(在 CLIP 空间中)之间的变化与两个图像标题之间的变化的一致性。进行此过滤不仅有助于最大程度地提高图像对的多样性和质量,而且使我们的数据生成对 Prompt-to-Prompt 和 Stable Diffusion 的失败更加稳健。
3.2. InstructPix2Pix
我们使用生成的训练数据来训练一个有条件的扩散模型,用于根据书面指令编辑图像。我们的模型基于 Stable Diffusion,这是一个大规模的文本到图像潜在扩散模型。
扩散模型 [60] 通过一系列去噪自动编码器学习生成数据样本,这些编码器估计数据分布的得分 [23](指向更高密度数据的方向)。潜在扩散 [52] 通过在预训练的变分自动编码器 [30] 的潜在空间中操作,改进了扩散模型的效率和质量,该模型具有编码器 E 和解码器 D。对于图像 x,扩散过程将噪声添加到编码的潜在 z = E(x),产生一个噪声潜在 z_t,其中噪声水平随时间步 t ∈ T 逐渐增加。我们学习一个网络 ε_θ,该网络预测在给定图像条件 c_I 和文本指令条件 c_T 的情况下添加到噪声潜在 z_t 的噪声。我们最小化以下潜在扩散目标:
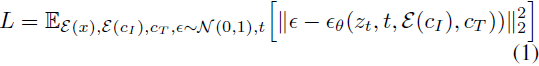
Wang 等人 [67] 表明,对大型图像扩散模型进行微调优于从头开始训练模型,特别是在配对训练数据有限的情况下,针对图像转换任务而言。因此,我们将模型的权重初始化为预训练的 Stable Diffusion 检查点,充分利用其强大的文本到图像生成能力。为了支持图像条件,我们在第一个卷积层中添加了额外的输入通道,将 z_t 和 E(c_I) 连接起来。扩散模型的所有可用权重都从预训练检查点初始化,而对新添加的输入通道进行操作的权重则初始化为零。我们重用了最初用于标题的相同文本条件机制,改为接受文本编辑指令 c_T 作为输入。有关额外的训练细节,请参见补充材料。
3.2.1 用于两种条件的无分类器指导
无分类器扩散指导 [20] 是一种在质量和生成样本多样性之间进行权衡的方法,常用于类别条件和文本条件图像生成,以提高生成图像的视觉质量,并使抽样图像更好地与其条件相对应。无分类器指导有效地将概率质量转移到数据上,其中隐式分类器 p_θ(c | z_t) 为条件 c 分配高似然。无分类器指导的实现涉及在训练时联合训练条件和无条件去噪的扩散模型,并在推理时结合两个得分估计。对于无条件去噪的训练,只需在训练过程中以概率将条件设置为固定的空值 c = Ø。在推理时,使用引导尺度 s ≥ 1,修改的得分估计 ~ e_θ(z_t, c) 在朝向条件 e_θ(z_t, c) 以及远离无条件e_θ(z_t, Ø) 的方向上进行外推:
![]()
对于我们的任务,得分网络 e_θ(z_t, c_I, c_T) 具有两个条件:输入图像 c_I 和文本指令 c_T。我们发现,针对两个条件进行无分类器指导是有益的。Liu 等人 [38] 表明,一个条件扩散模型可以组合来自多个不同条件值的得分估计。我们将相同的概念应用于我们的模型,使用两个单独的条件输入。在训练过程中,我们随机地为 5% 的示例仅设置 c_I = Ø_I,为 5% 的示例仅设置 c_T = Ø_T,以及为 5% 的示例同时设置 c_I = Ø_I 和 c_T = Ø_T。 因此,我们的模型能够在两个或任一条件输入方面进行有条件或无条件去噪。我们引入两个指导尺度,s_I 和 s_T,可以调整生成样本与输入图像相对应和与编辑指令相对应的强度之间的权衡。我们的修改后的得分估计如下:
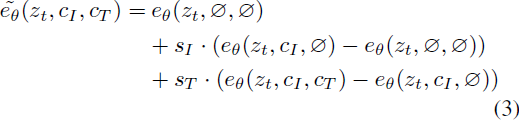
在图 4 中,我们展示了这两个参数对生成样本的影响。有关我们的无分类器指导公式的详细信息,请参见附录 B。

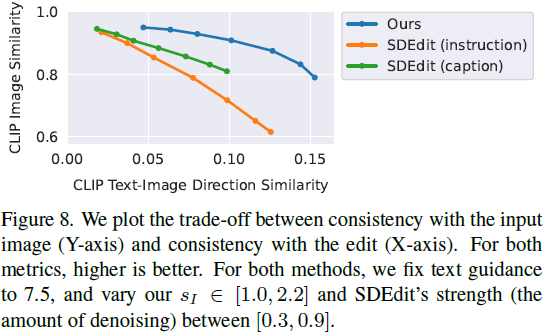
4. 结果 
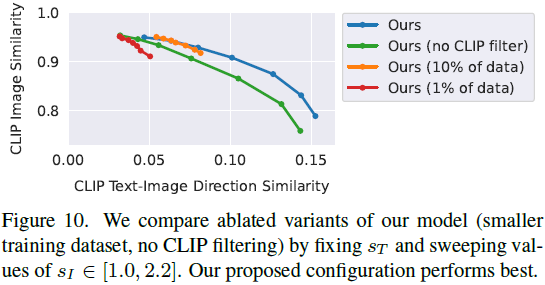


5. 讨论
我们展示了一种方法,结合了两个大型预训练模型,一个是大型语言模型,另一个是文本到图像模型,以生成一个遵循图像编辑指令的用于训练扩散模型的数据集。虽然我们的方法能够对图像进行各种引人注目的编辑,包括风格、媒体和其他背景的更改,但仍然存在一些局限性。
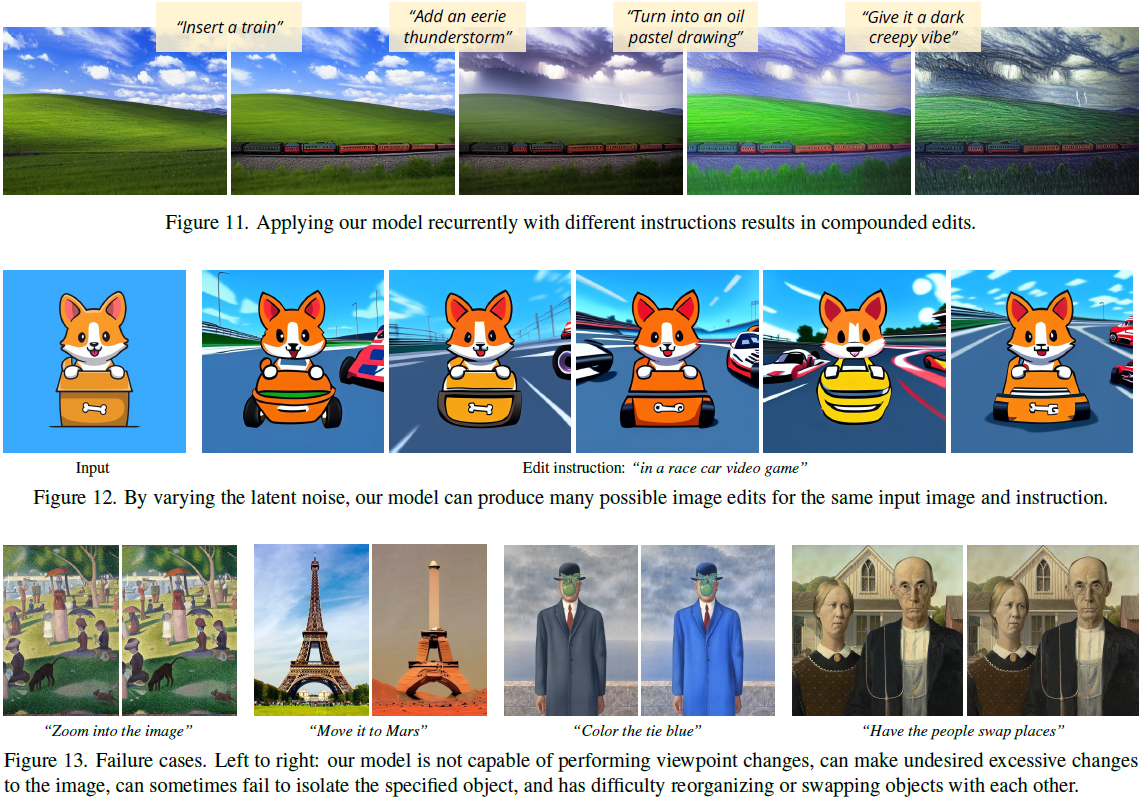
我们的模型受到生成数据集的视觉质量的限制,因此也受到用于生成图像的扩散模型(在本例中为Stable Diffusion [52])的限制。此外,我们的方法能够推广到新的编辑并正确将视觉变化与文本指令关联起来的能力受到人工编写的用于微调 GPT-3 [7] 的指令的限制,受到 GPT-3 创造指令和修改标题的能力的限制,以及 Prompt-to-Prompt [17] 修改生成的图像的能力的限制。特别是,我们的模型在计数对象数量和空间推理方面存在困难(例如,“将其移到图像的左侧”,“交换它们的位置” 或 “在桌子上放两个杯子,一个放在椅子上”),就像 Stable Diffusion 和 Prompt-to-Prompt 一样。失败的示例可以在图 13 中找到。
此外,我们所依赖的数据和预训练模型中存在充分记录的偏见,因此我们方法生成的编辑图像可能会继承这些偏见或引入其他偏见(图 14)。 除了缓解上述限制之外,我们的工作还开启了一些问题,例如:如何遵循空间推理的指令,如何将指令与其他条件模态(如用户交互)结合,以及如何评估基于指令的图像编辑。将人类反馈纳入模型以改进其性能是未来工作的另一个重要方向,而人在回路强化学习等策略可以用于提高我们的模型与人类意图之间的对齐度。















 1615
1615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









