






学习PyG文档——消息传递
创建消息传递网络
将卷积算子推广到不规则图通常表示为邻域聚合或消息传递方案。通过,表示层中节点的节点特征和表示节点之间的边缘特征,消息传递图神经网络可描述为:
,
消息传递的公式:


□γφ,可以是可微、可转换不变的函数比如求和、求平均、求最大值,也可表示为可以微分的函数,比如MLP。
‘消息传递’的基类
PyG提供了MessagePassing基类,它通过自动处理消息传播来帮助创建此类消息传递图神经网络。用户只需定义函数 ,**message()**和 update(),以及要使用的聚合方案(aggr=‘add’ or ‘mean’,or ‘max’)。
这是在下列方法的帮助下实现的。
- MessagePassing(aggr=“add”, flow=“source_to_target”, node_dim=-2):定义了要使用的聚合方案(‘aggr’)和消息传递的流动方向(‘flow’)。此外,该属性还指出要沿着哪个轴传播(‘node_dim’)。
- MessagePassing.propagate(edge_index, size=None, **kwargs):开始传播消息的初始调用。接收边缘指数和所有额外的数据,这是构建消息和更新节点嵌入所需要的。请注意,propagate()不仅限于在形状的方形邻接矩阵中交换信息,而且还可以通过传递作为额外参数在形状为一般的稀疏赋值矩阵中交换信息(例如,二分图)。如果size为None,则假定分配矩阵是方阵。对于具有两组独立节点和索引的二分图,并且每个集合都包含自己的信息,可以通过将信息作为元组传递来标记这种拆分,例如,[N, N][N, M],size=(N, M),x=(x_N, x_M)
- MessagePassing.message(…):构造消息到节点,类似于每个边 i 和 j。可以接受初始化的传递 。此外,传递给的张量可以映射到各个节点,并通过附加或附加到变量名称 。请注意,我们通常将其称为信息聚合的中心节点,并将其称为相邻节点,因为这是最常见的表示法。iφ(j,i) ∈ ε
- MessagePassing.update(aggr_out, …): 更新节点嵌入,为每个节点更新。将聚合的输出作为第一个参数,和接收最初传递给propagate()的任何参数。
让我们通过重新实现两个流行的 GNN 变体来验证这一点,即来自 Kipf 和 Welling 的 GCN 层以及来自 Wang 等人的 EdgeConv 层。
实现GCN层
GCN数学公式为:

其中相邻节点特征首先由权重矩阵 变换,按其度数归一化,最后求和。这个公式可以分为以下几个步骤:
- 在邻接矩阵中添加自循环。
- 节点特征矩阵进行线性变换。
- 计算归一化系数。
- 归一化节点特征。
- 相邻节点特征求和(聚合)。
步骤 1-3 通常在消息传递发生之前计算。使用 MessagePassing 基类可以轻松处理步骤 4-5。全层实现如下所示:
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super().__init__(aggr='add') # 聚合方式为 求和 (Step 5)。
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x的形状为[N,in_channels],N节点数量。
# edge_index 的形状 [2, E] ,只能是[2, E],其他形状需要转换。
# Step 1: 在邻接矩阵中添加自循环。
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: 节点矩阵的线性转换。
x = self.lin(x)
# Step 3: 归一化系数。
row, col = edge_index
deg = degree(col, x.size(0), dtype=x.dtype)
deg_inv_sqrt = deg.pow(-0.5)
deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
# Step 4-5: 开始传播消息。
return self.propagate(edge_index, x=x, norm=norm)
def message(self, x_j, norm):
# x_j 的形状 [E, out_channels] E是边的数量,区别有向图和无向图的E
# Step 4:归一化节点特征.
return norm.view(-1, 1) * x_j
GCNConv 继承MessagePassing中的传播。该层的所有逻辑运算都发生在这方法中。在这里,我们首先使用 torch_geometric.utils.add_self_loops() 函数将自循环添加到边缘索引(step 1),并通过调用 torch.nn.Linear 实例(step 2)线性变换节点特征。归一化系数是由每一条边中,两个个节点的节点的度导出的。结果保存在tensor中(步骤 3)。
然后我们调用propagate(),它在内部调用message()、aggregate() 和update()。我们将节点嵌入和归一化系数作为消息传递的附加参数。
在 message() 函数中,我们需要通过 norm 对相邻节点特征 x_j 进行归一化。这里,x_j 表示一个特征提升后的张量,它包含每条边的源节点特征,每个节点的邻居。
可以通过将 _i 或 _j 附加到变量名称来自动提升节点特征。事实上,任何张量都可以通过这种方式进行转换,只要它们具有源节点或目标节点的特征。
这就是创建一个简单的消息传递层所需的全部内容。您可以将此层用作深层架构的构建块。初始化和调用它很简单:
conv = GCNConv(16, 32)
x = conv(x, edge_index)
实现边的卷积
边缘卷积层处理图或点集,在数学上定义为:
其中 hΘ 表示 MLP。类比 GCN 层,我们可以使用 MessagePassing 类来实现这一层,这次使用“max”聚合方式
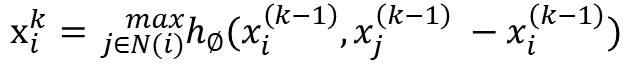
import torch
from torch.nn import Sequential as Seq, Linear, ReLU
from torch_geometric.nn import MessagePassing
class EdgeConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super().__init__(aggr='max')
self.mlp = Seq(Linear(2 * in_channels, out_channels),
ReLU(),
Linear(out_channels, out_channels))
def forward(self, x, edge_index):
return self.propagate(edge_index, x=x)
def message(self, x_i, x_j):
tmp = torch.cat([x_i, x_j - x_i], dim=1)
return self.mlp(tmp)
在 message() 函数中,我们使用 self.mlp 对每条边 (j,i)∈E 转换目标节点特征 x_i 和相对源节点特征 (x_j - x_i)。
边缘卷积实际上是一个动态卷积,它使用特征空间中的最近邻重新计算每一层的图。幸运的是,PyG 带有一个名为 torch_geometric.nn.pool.knn_graph() 的 GPU 加速的批量 KNN 图生成方法:
from torch_geometric.nn import knn_graph
class DynamicEdgeConv(EdgeConv):
def __init__(self, in_channels, out_channels, k=6):
super().__init__(in_channels, out_channels)
self.k = k
def forward(self, x, batch=None):
edge_index = knn_graph(x, self.k, batch, loop=False, flow=self.flow)
return super().forward(x, edge_index)
在这里,knn_graph() 计算一个最近邻图,进一步用于调用 EdgeConv 的 forward() 方法。
conv = DynamicEdgeConv(3, 128, k=6)
x = conv(x, batch)
今天的学习就到这了。














 1404
1404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









