






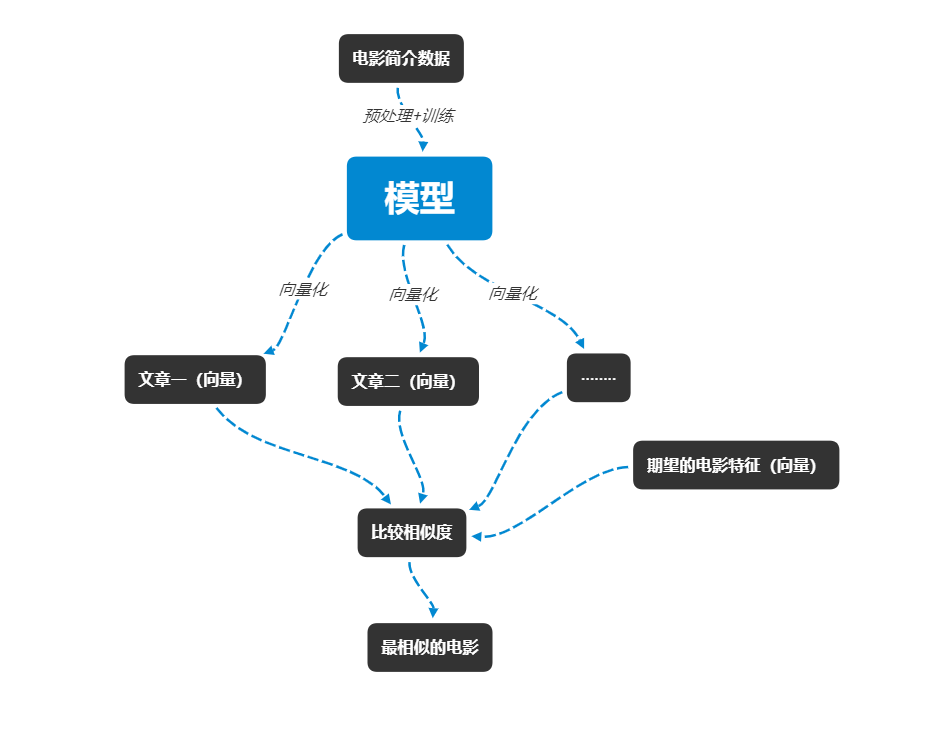
电影推荐思路
利用doc2vec做电影推荐,其实核心就是比较两部电影介绍文本之间的向量相似程度。自然语言处理中的分布式假设提出了“某个单词的含义由它周围的单词形成”。那么根据这个理论,与爱情相关的电影简介向量相互之间应该是相似的。那我们只需要将doc2vec模型训练出来,将文本向量化,比较文本相似度,输出排行靠前的就行了。
项目目录
数据预处理
网上关于电影简介的数据非常少,但是我们可以通过网络爬虫先获取电影信息。这里我是爬取了网上的电影信息,关于爬取操作将在另一篇文章中介绍这里只关注自然语言处理相关的操作。
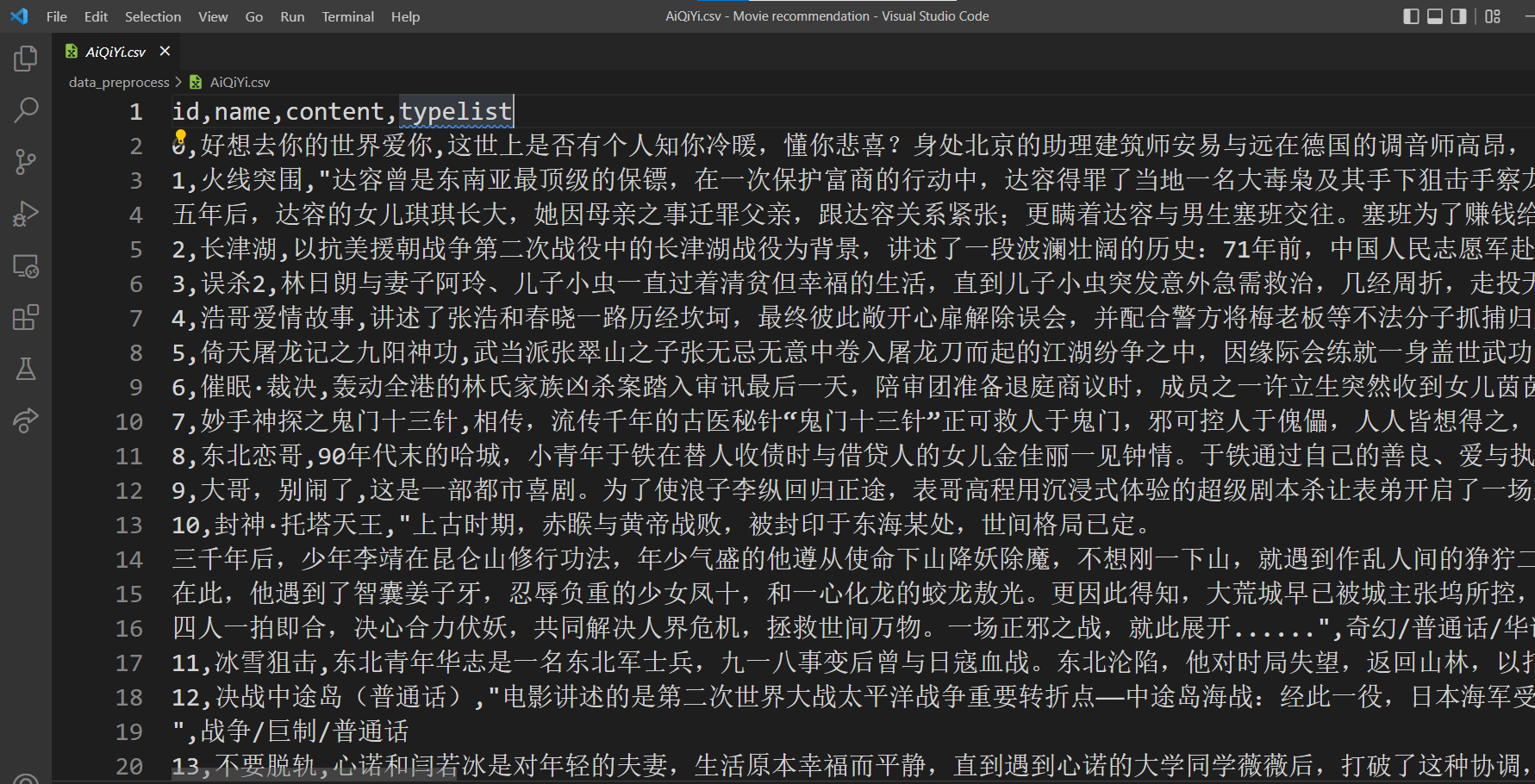
网络上爬取的数据格式为csv,内容包含了id、电影名称、电影简介。
因为考虑到后续的训练,我打算将所有的数据都处理成嵌套的列表,这样就可以直接通过列表的索引,找到相对应的电影。
所需要用到的库
import pandas as pd
import os
from os import path
import jieba
写几个函数处理源数据
def to_name_list(name):
"""
电影名称转化为列表(嵌套)
"""
names_list = []
for i in range(len(name)):
name_list = []
name_list.append(name[i])
names_list.append(name_list)
print("=======电影名称转化列表成功!======")
with open(os.path.abspath('./data_preprocess/data/movie_name.txt'), 'w', encoding='utf-8') as f:
f.write(str(names_list))
f.close()
print("=======电影名称写入文件成功!======")
return names_list
就是简单的列表嵌套,接下来的电影类型和电影介绍也是一样的道理。
def to_contents_list(contents):
"""
简介文本转化为列表(嵌套)
"""
contents_list = []
for i in range(len(contents)):
content_list = []
content_list.append(contents[i])
contents_list.append(content_list)
print("=======简介文本转化列表成功!======")
with open(os.path.abspath('./data_preprocess/data/contents.txt'), 'w', encoding='utf-8') as f:
f.write(str(contents_list))
f.close()
print("=======简介文本写入文件成功!======")
return contents_list
def to_type_list(type):
"""
将电影类型转化为列表(嵌套)
"""
types_list = []
for i in range(len(type)):
type_list = []
type_list.append(type[i])
types_list.append(type_list)
print("=======电影类型转化列表成功!======")
with open(os.path.abspath('./data_preprocess/data/movie_type.txt'), 'w', encoding='utf-8') as f:
f.write(str(types_list))
f.close()
print("=======电影类型写入文件成功!======")
return types_list
然后在主函数中读取文件并调用函数
if __name__ == "__main__":
file = pd.read_csv(os.path.abspath('data_preprocess\AiQiYi.csv'))
name = file['name']
contents = file['content']
types = file['typelist']
contents_list = to_contents_list(contents)
name = to_name_list(name)
type = to_type_list(types)
接下来要对电影的简介做进一步的处理,对它进行切词和去除停用词
首先,导入停用词
def load_stopWords(path):
"""
加载停用词
"""
stopwords = []
with open(path, "r", encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stopwords.append(line.strip())
print("=====加载停用词成功====")
return stopwords
我把停用词做成一个列表,等切词结束之后直接将不在停用词列表中的词添加列表就可以了
def cut_content(contents_list):
"""
jieba库切词
:return:cutted_conttents_list
"""
cutted_contents_list = []
for content in contents_list:
cutted_segments = [' '.join(jieba.cut(content[0]))]
temp_list = []
for word in cutted_segments[0].split(' '):
if word not in stopwords:
temp_list.append(word)
else:
pass
cutted_contents_list.append(temp_list)
print("======切词完成!======")
with open(os.path.abspath('./data_preprocess/data/cutted_contents.txt'), 'w', encoding='utf-8') as f:
f.write(str(cutted_contents_list))
f.close()
print("========写入文件完成!========")
return cutted_contents_list
切词函数,其实就是不断地读取列表中的内容并操作,一步一步打印也没什么难度
修改一下主函数
if __name__ == "__main__":
file = pd.read_csv(os.path.abspath('data_preprocess\AiQiYi.csv'))
name = file['name']
contents = file['content']
types = file['typelist']
contents_list = to_contents_list(contents)
name = to_name_list(name)
type = to_type_list(types)
stopwords = load_stopWords(os.path.abspath(
'./data_preprocess/stopwords/cn_stopwords.txt'))
cutted_contents = cut_content(contents_list)
将数据预处理了之后就可以进行模型的训练。
模型训练
所需要用到的库
import os
from os import path
from gensim.models import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
因为是要将文本向量化,所以用到的就是Doc2Vec模型
该模型训练需要先将文本转化为TaggedDocument类
def train_model():
"""
训练模型
"""
data_file = os.path.abspath('./data_preprocess/data/cutted_contents.txt')
model_file = os.path.abspath('./model/doc2vec.model')
# 将数据转换为TaggedDocument类
with open(data_file, encoding='utf-8') as file:
contents = file.read()
train_data = []
for index, content in enumerate(eval(contents)):
document = TaggedDocument(content, tags=[index])
train_data.append(document)
model = Doc2Vec(vector_size=50, min_count=2)
model.build_vocab(train_data)
model.train(train_data, total_examples=model.corpus_count, epochs=80)
print("======模型训练完成!========")
model.save(model_file)
print("======模型保存完成!========")
假如不关心模型的参数,只是单纯的训练模型。Doc2Vec模型的训练并不难,只需要将数据转化为TaggedDocument类就行。
然后再写一个测试函数
def test_model():
"""
测试模型,并将文段向量化
推荐与之相似的电影
"""
model_file = os.path.abspath('./model/doc2vec.model')
movie_name_file = os.path.abspath('./data_preprocess/data/movie_name.txt')
movie_type_file = os.path.abspath('./data_preprocess/data/movie_type.txt')
model = Doc2Vec.load(model_file) # 模型加载
with open(movie_name_file, encoding='utf-8') as file:
movie_name = file.read()
movie_name_list = eval(movie_name) # 准备电影名称列表
with open (movie_type_file, encoding='utf-8') as file:
movie_type = file.read()
movie_type_list = eval(movie_type)
text = ['世上', '是否', '个人', '知', '冷暖', '懂', '悲喜', '身处',
'北京', '助理', '建筑师', '安易', '远', '德国', '调音师', '高昂',
'一场', '意外', '脑电波', '相连', '听觉', '味觉', '触觉',
'神奇', '共享', '被迫', '绑定', '日子', '方寸大乱', '笑料',
'百出', '无时无刻', '陪伴', '成为', '互相', '懂', '......',
'', '', '一次', '误会', '二人', '产生', '隔阂', '面对', '遥远',
'距离', '未知', '将来', '是否', '会', '坚定', '去往', '世界',
'感谢', '看透', '一直', '陪', '身边']
vector_dm = model.infer_vector(text) # 向量化
similar = model.docvecs.most_similar(vector_dm, topn=2) # 导出最相似的电影
for index, content in enumerate(similar):
print(f'电影名称:{movie_name_list[similar[index][0]][0]} 电影类型:{movie_type_list[similar[index][0]][0]}')
主函数
if __name__ == '__main__':
train_model()
test_model()
函数就是将文本向量化之后,比较出相似度最高的前几个电影。我直接拿了数据中的第一个爱情主题的电影简介来进行预测。
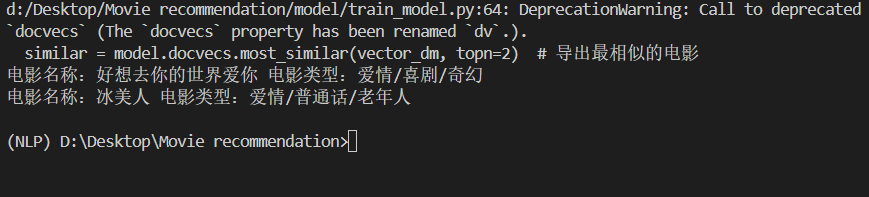
结果确实是可以匹配到爱情主题的电影
我们再尝试多一点电影
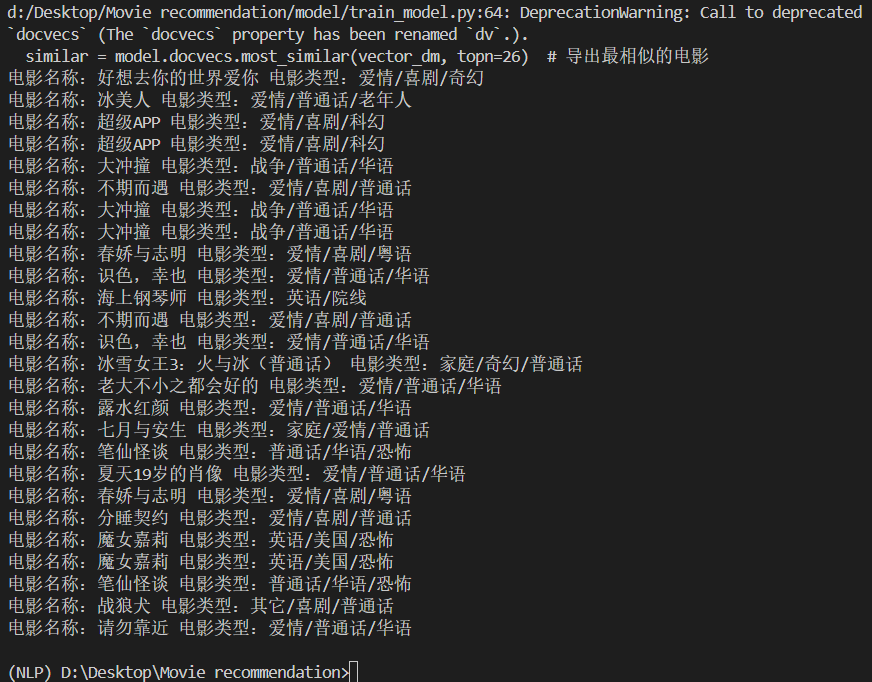
我们发现基本都是爱情主题的电影
结束
从结果上看这个模型好像还不错,接下来我们还可以对它进行评估,优化以及封装成一个web网站或者也可以是微信小程序。
至此电影推荐的核心部分就介绍完了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









