






尽管生成式人工智能取得了重大进展,但由于缺乏有效的指标和标准化基准,科学评估仍然具有挑战性。
例如,广泛使用的 CLIPScore 可以测量(生成的)图像和文本提示之间的对齐程度,但它无法为涉及对象、属性和关系组合的复杂提示产生可靠的分数。
- VQAScore.我们提出了一个简单的指标,其表现优于现有技术,而无需使用昂贵的人工反馈或专有模型(例如 ChatGPT 和 GPT4-Vision)。
- CLIP-FlanT5 .我们的内部 VQA 模型实现了最先进的文本到图像/视频/3D 评估的 VQAScore,为 CLIPScore 提供了强有力的替代方案。
- GenAI-Bench .我们引入了一个文本到视觉的基准,该基准具有真实世界的构图提示,以评估生成模型和自动化指标,超越了现有基准的难度。

与词袋CLIPScore(红色) 相比,基于我们的 CLIP-FlanT5 模型的VQAScore(绿色)与人类对涉及属性绑定、空间/动作/部分关系和否定和比较等高阶推理的组合文本提示生成的图像的判断具有更好的相关性。
VQAScore 非常简单但有效。可以使用现成的 VQA 模型端到端计算,因为“是”的概率取决于图像和一个简单的问题,例如“此图是否显示“{text}”?请回答是或否。 ”
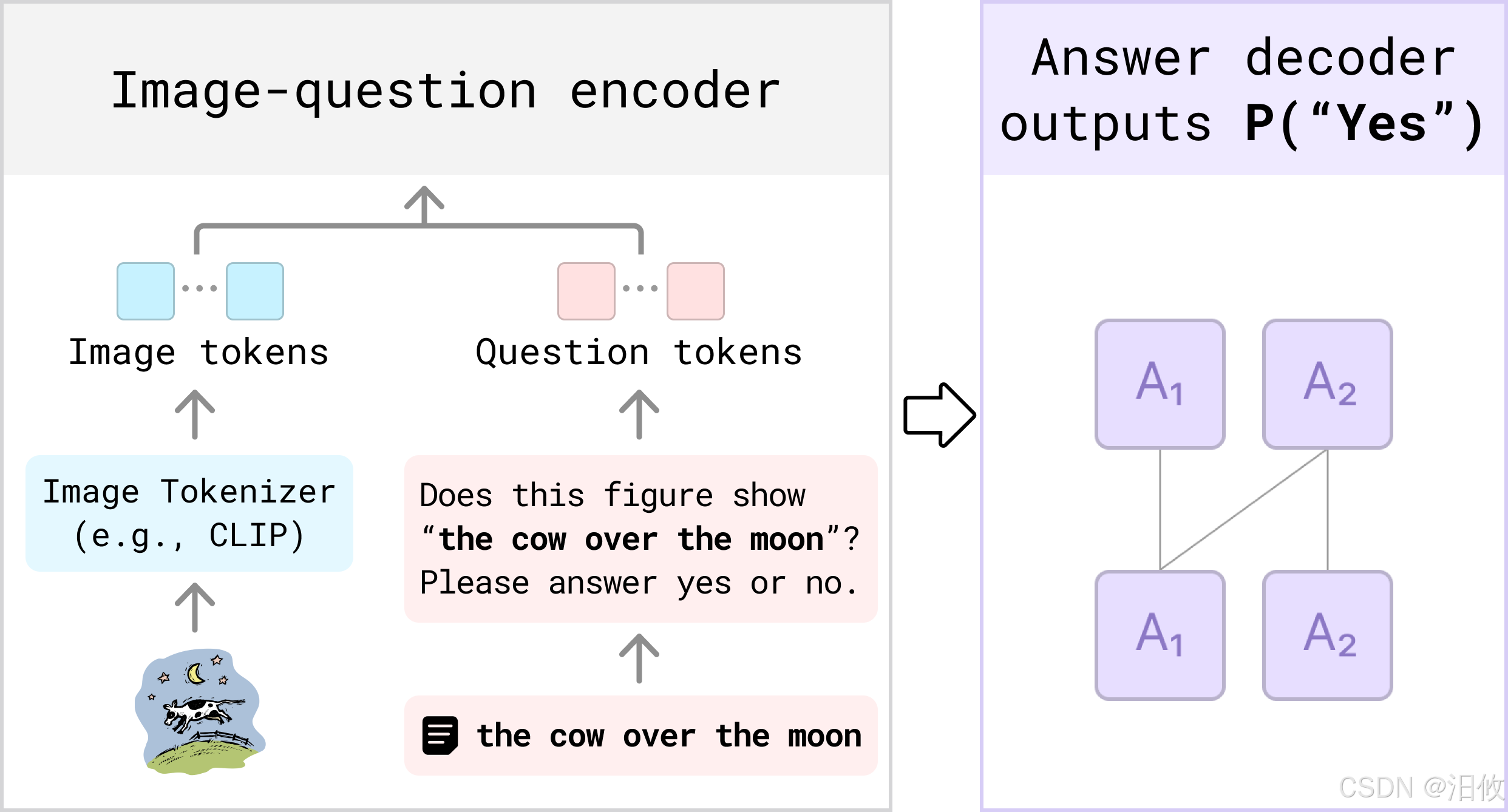
我们发现使用双向图像问题编码器非常有益,它允许视觉嵌入受到所提问题的影响(反之亦然)。我们通过在公共 VQA 数据集上微调CLIP-FlanT5模型来实现这一点。该模型在文本到图像/视频/3D 评估中树立了新的领先地位,而无需使用昂贵的人工反馈。

GenAI-Bench
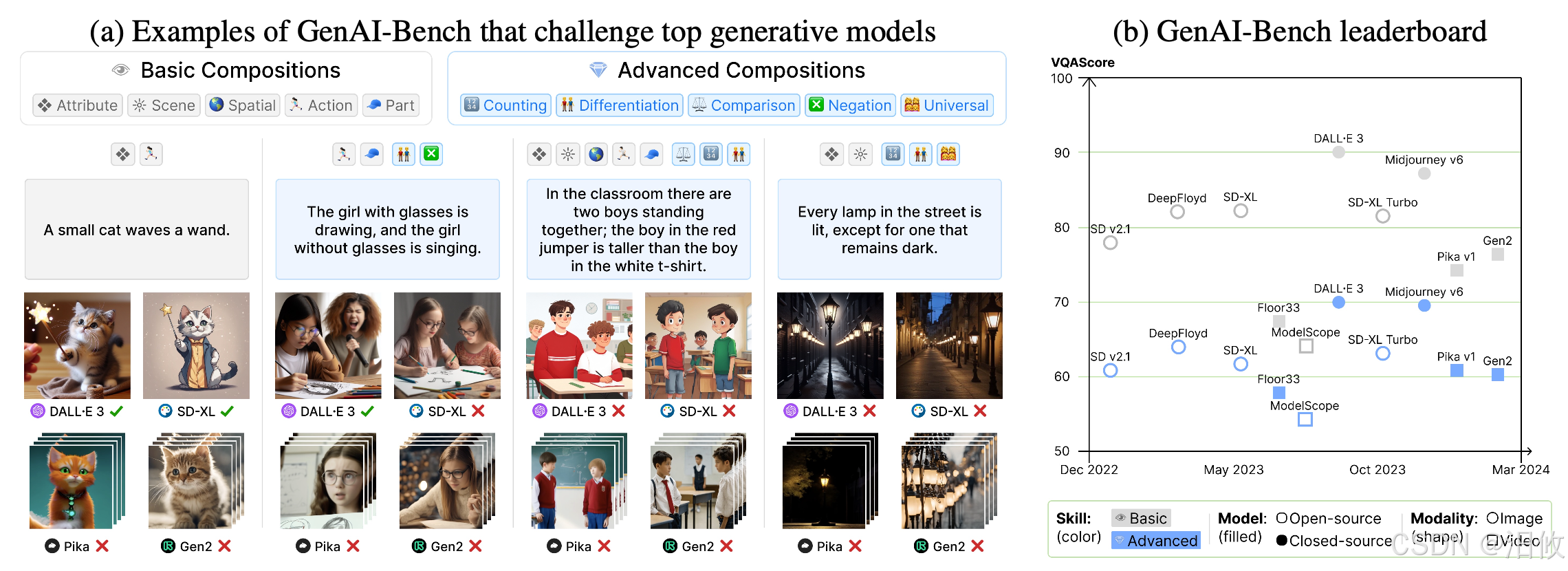
我们引入了全面的文本到视觉生成基准,甚至挑战了 DALL-E 3 和 Gen2 等领先模型。
GenAI-Bench 为基本(属性/场景/关系)和高级(计数/区分/比较/逻辑)组合推理技能提供了细粒度的标签。
与 VQAScore 一起使用,GenAI-Bench 可以对生成模型进行可重复的评估。为了验证 VQAScore 与人类判断的一致性,我们还收集了十个图像和视频生成模型的大量人工评分。我们计划发布这些评分以评估未来的自动化指标。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









