







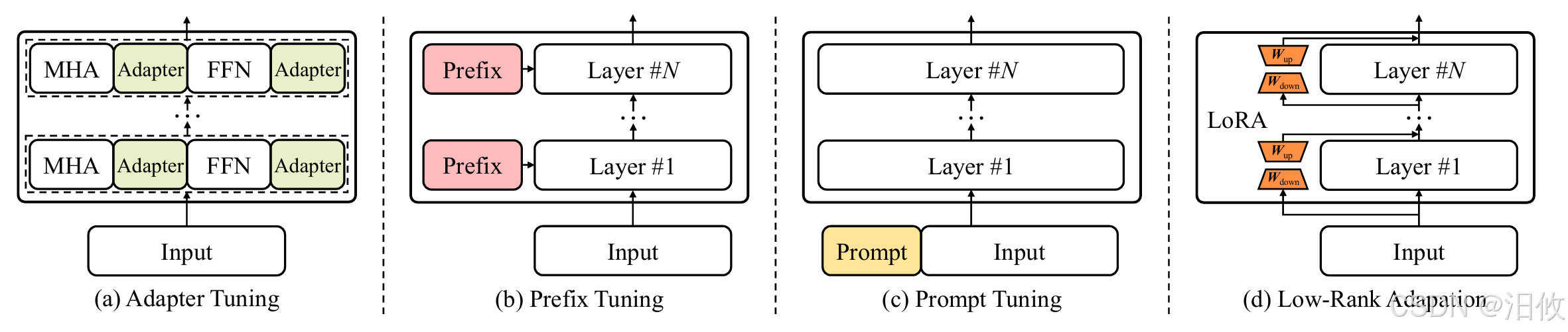
LoRA 微调方法的主要优势
预训练模型参数可以被共享,用于为不同的任务构建许多小的 LoRA 模块。冻结共享模型,并通过替换矩阵 A 和 B 可以有效地切换任务,从而显著降低存储需求和多个任务切换的成本。
当使用自适应优化器时,由于不需要计算梯度以及保存太多模型参数,LoRA 使得微调效果更好,并将微调的硬件门槛降低了 3 倍。
低秩分解采用线性设计的方式使得在部署时能够将可训练的参数矩阵与冻结的参数矩阵合并,与完全微调的方法相比,不引入推理延迟。
LoRA 与其它多种微调方法不冲突,可以与其它微调方法相结合,比如下节实训将要介绍的前缀调优方法等。
Prefix-tuning 微调方法
在模型中加入 prefix,即连续的特定任务向量,微调时只优化这一小段参数
p ϕ ( z i + 1 ∣ h ≤ i ) = s o f t m a x ( W ϕ h i ( n ) ) pϕ(zi+1∣h≤i)=softmax(Wϕhi(n)) pϕ(zi+1∣h≤i)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2580
2580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









