







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
随着ai的发展,ai-agent变得越来越常见。因为磕cp的时候,很难找到符合自己心意的cp文学,本文介绍了一种基于Langchain和Deepseek的cp文学生成器,更加的私人定制,符合心意。
一、Langchain
LangChain 是一个开源框架,用于构建基于大型语言模型(LLM)的应用程序。LLM 是基于大量数据预先训练的大型深度学习模型,可以生成对用户查询的响应,例如回答问题或根据基于文本的提示创建图像。LangChain 提供各种工具和抽象,以提高模型生成的信息的定制性、准确性和相关性。例如,开发人员可以使用 LangChain 组件来构建新的提示链或自定义现有模板。LangChain 还包括一些组件,可让 LLM 无需重新训练即可访问新的数据集。
官方文档:[https://www.langchain.com/]
二、Langchain的基本组件

- prompt:可选
langchain中提供了可选择的Langchain Template,可以用于指导模型的相应,帮助理解上下文并生成相关的输出。
同样在langchain中由几种不同类型的提示词模板: - 字符串提示词模板
这些提示词模板用于格式化单个字符串,通常可以更简单的输入。
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke about {topic}")
prompt_template.invoke({
"topic": "cats"})
- 聊天提示词模板
这些提示词模板用于格式化消息列表。不仅如此,使用这种模板可以设置system,即设置模型的语言风格。
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
("user", "Tell me a joke about {topic}")
])
prompt_template.invoke({
"topic": "cats"})
在上述示例中,当调用此 ChatPromptTemplate 时,将构造两个消息。 第一个是系统消息,没有变量需要格式化。 第二个是 HumanMessage,将由用户传入的 topic 变量进行格式化。输出结果如下图所示:
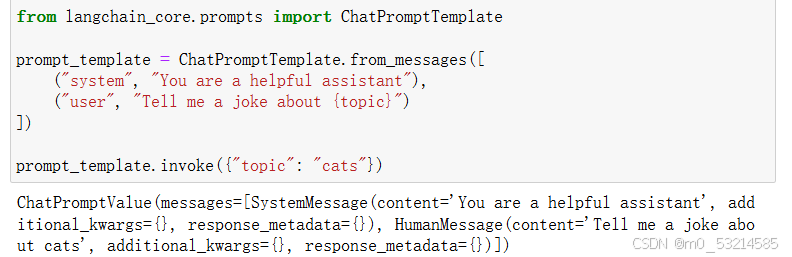
-
Retriever
检索器是一个接口,给定非结构化查询返回文档。 它比向量存储更为通用。 检索器不需要能够存储文档,只需返回(或检索)它们。 检索器可以从向量存储创建,但也足够广泛,包括维基百科搜索和亚马逊Kendra。检索器接受字符串查询作为输入,并返回文档列表作为输出。
-
Model
Langchain 支持多种模型,均可在Langchain中的openAI部分找到。 -
Parser
LangChain 有许多不同类型的输出解析器。这是 LangChain 支持的输出解析器列表。下表包含各种信息:- 名称: 输出解析器的名称
- 支持流式处理: 输出解析器是否支持流式处理。
- 有格式说明: 输出解析器是否有格式说明。通常在以下情况下可用: (a) 所需的模式未在提示中指定,而是在其他参数中(如 OpenAI 函数调用),或 (b) 当 OutputParser 包装另一个 OutputParser 时。
- 调用 LLM: 此输出解析器是否自己调用大型语言模型。通常只有那些试图纠正格式错误输出的输出解析器才会这样做。
- 输入类型: 预期的输入类型。大多数输出解析器适用于字符串和消息,但某些(如 OpenAI 函数)需要带有特定关键字参数的消息。
- 输出类型: 解析器返回的对象的输出类型。
- 描述: 我们对这个输出解析器的评论以及何时使用它。
Langchain 支持多种信息流的输出,如json、xml格式。
-
工具
工具是设计用于被模型调用的实用程序:它们的输入旨在由模型生成,输出旨在返回给模型。 每当您希望模型控制代码的某些部分或调用外部API时,都需要工具。
一个工具由以下部分组成:- 工具的名称。
- 工具的 描述。
- 定义工具输入的 JSON schema。
- 一个 函数(可选地&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









