






 本文介绍了NumPy库中创建数组的方法,如`numpy.array`,`linspace`和`logspace`函数生成等差和等比数列。还详细讲解了数组的属性,如秩、形状、大小和数据类型。此外,讨论了统计功能,包括平均值、中位数、标准差、最大值和最小值的计算,以及加权平均值的实现。最后提到了随机数生成,包括整数和正态分布浮点数的生成方法。
本文介绍了NumPy库中创建数组的方法,如`numpy.array`,`linspace`和`logspace`函数生成等差和等比数列。还详细讲解了数组的属性,如秩、形状、大小和数据类型。此外,讨论了统计功能,包括平均值、中位数、标准差、最大值和最小值的计算,以及加权平均值的实现。最后提到了随机数生成,包括整数和正态分布浮点数的生成方法。
NumPy -- 创建数组
numpy.array(object, dtype = None, copy = True, order = None,subok=False,ndmin = 0)
- object:表示—个数组序列
- dtype:可选参数,道读回到标笋项更改数组的数据类型
- copy:可选参数,当数据源是ndarray时表示数组能否被复制,默认是 True。
- order:可选参数,以哪种内存布局创建数组,有3个可选值,分别是C(行序列)/F(列序列)/A(默认)。
- ndmin:可选参数,用于指定数组的维度。
- subok:可选参数,类型为bool值,默认False。为True,使用object的内部数据类型;False:使用object数组的数据类型。
linspace() -- 创建等差数列
返回在间隔[开始,停止]上计算的num个均匀间隔的样本。数组是一个等差数列构成
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
- start:必填项,序列的起始值
- stop:必填项,序列的终止值,如果endpoint为true,该值包含于数列中
- num:要生成的等步长的样本数量,默认为50
- endpoint:该值为true 时,数列中包含stop值,反之不包含,默认是True
- retstep:如果为True时,生成的数组中会显示间距,反之不显示
- dtype:ndarray的数据类型
logspace() -- 创建等比数列
返回在间隔[开始,停止]上计算的num个均匀间隔的样本。数组是一个等比数列构成np.logspace(start,stop, num=50, endpoint=True, base=10.0, dtype=None)
- start:必填项,序列的起始值,
- stop:必填项,序列的终止值,如果endpoint为true,该值包含于数列中
- num:要生成的等步长的样本数量,默认为50
- endpoint:该值为true时,数列中包含stop值,反之不包含,默认是True.
- base:对数log的底数
- dtype:ndarray的数据类型
np.logspace(A,B,C,base=D)
- A:生成数组的起始值为D的A次方
- B:生成数组的结束值为D的B次方
- C:总共生成C个数
- D:指数型数组的底数为D,当省略base=D时,默认底数为10
NumPy 数组属性
- ndarray.ndim:秩,即轴的数量或维度的数量
- ndarray.shape:数组的维度,对于矩阵,n行m列
- ndarray.reshape:调整维度
- ndarray.size:数组元素的总个数,相当于.shape 中n*m的值
- numpy.resize(a, new_shape):如果新数组大于原始数组,则新数组将填充a的重复副本。eg:np.resize(a, (2, 3))。
- 与a.resize(new_shape)不同,后者用零而不是重复的a填充
- ndarray.dtype:ndarray对象的元素类型
- a.astype('float32' ):numpy数据类型转换,调用astype返回数据类型修改后的数据,但是源数据的类型不会变
- ndarray.itemsize: ndarray对象中每个元素的大小,以字节为单位
求平均值mean()
若想求某一维度的平均值,设置axis参数,多维数组的元素指定
- axis = 0,将从上往下计算平均值
- axis =1,将从左往右计算平均值
a1.mean(axis=0)
中位数np.median
又称中点数,中值
是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值。a2=np.array([5,6,7,8,9])
np.median(a2)
求标准差ndarray.std
在概率统计中最常使用作为统计分布程度上的测量,是反映一组数据离散程度最常用的一种量化形式
- 标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。简单来说,标准差是一组数据平均值分散程度的一种度量。
- 一个较大的标准差,代表大部分数值和其平均值之间差异较大
- 一个较小的标准差,代表这些数值较接近平均值。
a = np. array ([95,85,75,65,55,45])
b = np. array ([73,72,71,69,68,67])
np.std(a),np.std(b) # (17.07825127659933, 2.160246899469287)
求最大值ndarray.max()
求最小值ndarray.min()
int8:-128~127
加权平均值numpy.average()
即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数numpy.average(a, axis=None, weights=None, returned=False)
- weights:数组,可选。与a中的值关联的权重数组。a中的每个值都根据其关联的权重对平均值做出贡献。权重数组可以是一维的(在这种情况下,它的长度必须是沿给定轴的a的大小)或与a具有相同的形状。如果weights=None,则假定 a中的所有数据的权重等于1。一维计算是:avg = sum(a * weights) / sum(weights)。对权重的唯一限制是sum(weights)不能为0。`
xiaoming = np.array([80,90,95]) xiaogang = np.array([95,90,80]) #权重: weights = np.array([0.2,0.3,0.5]) #分别计算小明和小刚的平均值 print(np.mean(xiaoming)) print(np.mean(xiaogang)) #分别计算小明和小刚的加权平均值 print(np.average(xiaoming, weights=weights)) print(np.average(xiaogang, weights=weights)) #对比得到结果
numpy.random.randint()
numpy.random.randint (low,high=None,size=None,dtype=’1’)
- 返回随机整数,范围区间为[low,high),包含low,不包含high
- 参数: low为最小值, high为最大值,size为数组维度大小,dtype为数据类型,默认的数据类型是np.int
- high没有填写时,默认生成随机数的范围是[0,low)
# 返回-5到5之间不包含5的2块3行4列的随机整数 np.random.randint(-5,5,size=(2,3,4))
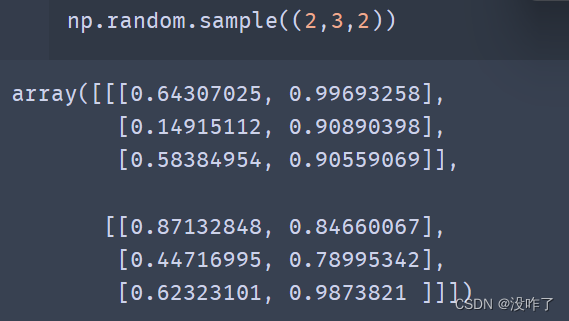
numpy.random.sample
numpy. random. sample(size=None)
- 返回半开区间内的随机浮点数[0.0,1.0]
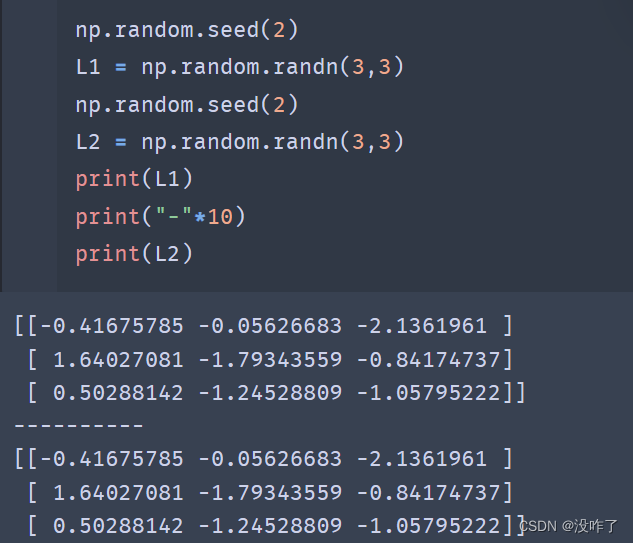
随机种子np.random.seed()
- 使用相同的seed()值,则每次生成的随机数都相同,使得随机数可以预测
- 但是,只在调用的时候seed()一下并不能使生成的随机数相同,需要每次调用都seed()一下,表示种子相同,从而生成的随机数相同。
正态分布Inumpy.random.normal
numpy. random. normal(loc=0. 0,scale=1.0, size=None)
- 返回一个由size指定形状的数组,数组中的值服从u=loc,o=scale的正态分布
- loc : float型或者float型的类数组对象,指定均值
- scale : float型或者float型的类数组对象,指定标准差
- size : int型或者int型的元组,指定了数组的形状。如果不提供size,且loc和scale为标量〈不是类数组对象),则返回一个服从该分布的随机数。
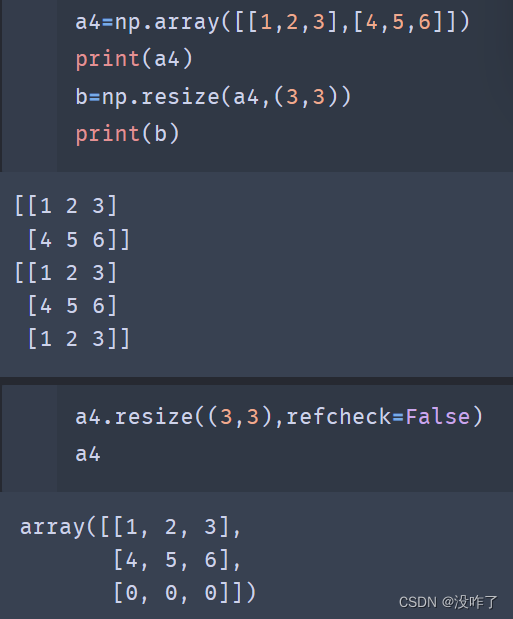
numpy.resize()
numpy.resize(arr,shape)
numpy.resize()返回指定形状的新数组。
numpy.resize(arr,shape)和ndarray.resize(shape, refcheck=False)区别
numpy.resize(arr,shape),有返回值,返回复制内容.如果维度不够,会使用原数组数据补齐
ndarray.resize(shape, refcheck=False),修改原数组,不会返回数据,如果维度不够,会使用0补齐

















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









