






Optimizing Deep Learning Model Parameters with the Bees Algorithm for Improved Medical Text Classification
标题:改进医学文本分类的Bees算法优化深度学习模型参数
作者:Mai A. Shaaban,Mariam Kashkash,Maryam Alghfeli,Adham Ibrahim
机构:Mohamed bin Zayed University of Artificial Intelligence
深度学习模型的一个缺点是需要花费大量的精力来调整超参数。本文介绍了一种新的机制以获得构建深度神经网络所需的最优超参数,使用Bees算法,这是最新的群智能算法之一。适用于长短时记忆( Long短时记忆,LSTM ),用于基于医疗文本的疾病分类。实验表明,Bees算法取得了较好的效果,显著提高了LSTM的性能。优化问题是在给定要在一定次数的迭代中调整的初始超参数的情况下,最大化基于医学文本的疾病分类的准确度。实验包括两个不同的数据集:英文和阿拉伯文。使用长短时记忆(LSTM)和Bees算法在英语数据集上实现的最高准确率为99.63%,
Introduction:
本文工作的第一步是执行词项正规化、去停用词、生成词向量等文本预处理技术。
然后,针对英文数据集,建议使用长短期记忆( Long Short-Term Memory,LSTM )深度神经网络,以词向量作为输入,预测输出。然而,LSTM作为深度学习模型存在陷入局部最优的风险。这是因为权重及其参数的值是随机初始化的。Bees算法( BA )是群智能算法中的一种。它是一种基于种群的算法,同时模仿自然界中蜜蜂觅食的行为。在提出的工作中,使用了Bees算法来增强LSTM的超参数调优过程。
对于阿拉伯语数据集,使用Ara BERT进行情感分类。
Methods
1、Text Augmentation
针对英文和阿拉伯文数据集中分别有706和152个数据样本在丢弃重复后数据规模缩小的问题,采用文本增强的方式提升深度学习模型性能,降低过拟合概率。应用该方法后,在英语和阿拉伯语数据集上,数据规模分别增加到2829和342个数据样本。
文本增强是一种常用的技术,通过生成给定文本数据的不同版本来放大数据样本。使用nlpaug工具
2、Exploratory Data Analysis
探索性数据分析无缺失值的平衡数据是具有良好泛化模型的必要前提。数据分析对于从数据集中识别模式和提取实际信息至关重要。
一个平衡的数据集应该包含每个类别相对接近的出现百分比。阿拉伯语数据集具有不平衡的类分布。将数据增强应用于阿拉伯语数据集后,数据变得平衡。
此外,我们分析了英语数据集中的词频。
为了阐明这两个数据集是如何用于疾病分类的,添加了图4来说明带有提示(标签)的医学文本。
3、Data Preprocessing
对于机器学习或深度学习算法,必须将文本数据转换成数值表示。
评估文本语料转化为数词的方法多种多样,各有优缺点。例如Tf - Idf、one-hot编码、word Embedding等。
- 词频-逆文档频率( Term Frequency-Inverse Document Frequency,TF-IDF )技术是文本挖掘中用来反映词对文档在语料库中重要性的一种技术。
- One - Hot编码将短语中的单词拆分成一组,并将每个单词转换成上下文中的数字序列,而不考虑上下文中的含义。
- Word embeddings方法用一个数字向量表示单词之间的语义相似性。它通过将每个单词转换为反映其在文档内相对意义的词向量来创建稠密向量。
4、Long Short-Term Memory (LSTM)
对于文本等序列数据,RNNs有助于预测特定文本之后会出现什么单词或短语。长短期记忆网络( Long Short-Term Memory Network,LSTM )是一种RNN,其中LSTM单元块代替标准的神经网络层。LSTM模型已经被证明能够取得显著的文本分类性能。LSTM单元由三个不同的单元组成,即输入、遗忘和输出门,用于确定哪些信号可以转发到下一个节点。
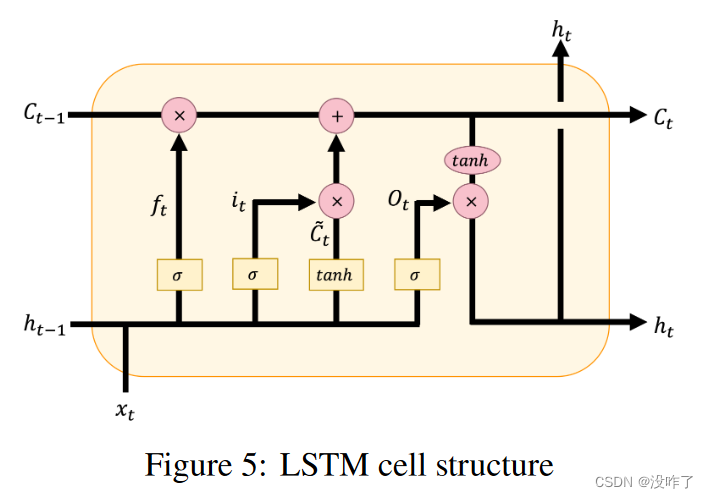
5、The Bees Algorithm
Bees Algorithm是一种模仿自然界中蜜蜂行为进行觅食的基于种群的智能算法。开始时,派出侦察蜂去发现该地区。当这些蜜蜂返回时,它们会执行一个摇摆舞,表明发现批次的质量。之后,招蜂工蜂被送到好的批次取好蜜,提高了蜂蜜的质量和产量。BA通过初始化n只蜜蜂的种群开始。之后,BA的主循环通过选择m只好的蜜蜂来执行局部搜索以利用找到的解以达到最优。精英蜂会招募新蜂来帮助他们在自己的邻域中找到更好的解决方案。同时招募nsp个蜜蜂在剩余的好蜜蜂的邻域内进行搜索。一般情况下,nep应大于nsp。种群中剩余的蜜蜂执行全局搜索来探索所有可用的解决方案。如此循环,直至收敛。
5.1 Hyper-parameter Tuning using the Bees Algorithm
在本文提出的方法中,BA被用来寻找LSTM需要训练的历元数和LSTM网络中的单元数的最优值,以提高系统的精度。因此,所提方法中的蜜蜂由历元值、单元数和运行LSTM得到的精度值组成.
- 先随机生成n个蜜蜂(解)作为初始种群,代表LSTM的n种不同结构。每个参数使用均匀分布函数随机生成。
- 通过对每只蜜蜂训练所提方法来实现评估功能
- 这些蜜蜂根据得到的准确率值进行降序排列
- 选出m只好蜜蜂,并区分它们之间的精英e。有nep和nsp个蜜蜂,分别为m个好蜜蜂和精英e中的每个蜜蜂招募,以增强找到的解。这是通过使用均匀分布函数在原始值的邻域内生成新的历元值和单位参数来实现的。
- epochcur和unitcur分别为当前历元和单位的当前值,epochnew和unitnew分别为历元和单位的新值。而ngh是邻域的大小。新的蜜蜂是在新的精度大于原始蜜蜂的精度的情况下存储的,这是局部搜索所要求的。在实现局部搜索后,对剩余的1nmo运行全局搜索,以发现可以承诺的新解。全局搜索是通过替换每个剩余的蜜蜂1nmo来初始化种群。重复局部搜索和全局搜索,直到收敛或达到BA的最大迭代次数。
Experimental Results
疾病分类英文数据集经过数据增强后包含2829个唯一文本样本。
- 首先,使用数据预处理技术,包括标记化、去停用词和词项正规化。
- 然后,利用词嵌入技术将文本数据转换为数值格式,其中每个词用一个大小为32的向量表示。
- 然后,我们应用10折交叉验证结合LSTM来预测患者的疾病。
- 最后,我们进行了消融研究并对模型进行了评估。
Evaluation Metrics:

为了得到尽可能高的准确率,使用蜂群算法为LSTM模型提取理想的超参数。输出时性能提升明显。














 16万+
16万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









