







S 2 T U L S^2TUL S2TUL: A Semi-Supervised Framework for Trajectory-User Linking
本文发表于2023年的WSDM,电子科技大学。
本文主要提出一种半监督的学习框架,能够对用户匿名轨迹分类达到较好的效果。
创新点:
- 采用了一种半监督的轨迹分类方法,能够缓解数据稀疏问题。
- 不仅考虑了轨迹内的关系,还考虑了一种轨迹间的关系表示,并且从时间,空间,人类流动重复性三种类型中采样三种关系图来增强轨迹表征。
- 采用了一种用户轨迹贪婪重连接的方法进行测试。
- 保证了时间重叠跨度约束。
框架优点:
1.稳定性高。
2. 效果较好
3.重视了时间重叠跨度约束。
4.数据集稀疏得到缓解。
缺点:
1.没有在大规模数据集上实验。
2.可能会很耗时?
ABSTRACT
S
2
T
U
L
S^2TUL
S2TUL由五个部分组成:
1.轨迹级别的图构建模块。
2.轨迹相关性建模模块。
3.位置级别的顺序建模模块。
4.分类层。
5.一个测试用的贪心用户轨迹重连接模块。
然后大概阐述了框架的原来。读完后我有三个问题:1.什么是将离散特征转为隐藏表征。2.什么是细粒度的轨迹内信息。3.什么是时间跨度重叠约束。
解释:
1.从轨迹级图构建出来时节点是离散的,通过RGCN将离散的节点表示映射到隐藏空间表示。
2.我的理解是更细致的轨迹内位置信息,通过LSTM将轨迹内位置顺序信息提取并且映射如低维向量。
3.具有重叠时间跨度的两条轨迹不能分配给同一个人,因为用户不能同时处于不同的位置地点。
1 INTRODUCTION
已经有很多努力致力于 TUL 问题,主要集中在建模顺序性和位置之间的转换模式。(modeling sequentiality and transition patterns among locations)然而,大多数研究都没有利用轨迹级别的信息(trajectory-level information),例如(挑战 I),这有助于识别用户。 此外,大多数都没有考虑轨迹的空间和时间特性,并且在标记数据方面存在稀疏性问题(挑战 II)。 此外,这些研究将 TUL 视为一般的顺序分类问题(suquential classification),例如文本分类,并忽略了轨迹-用户对之间的时间跨度重叠约束,即具有重叠时间跨度的两条轨迹不能分配给同一个人,因为用户不能同时处于不同的位置 地点(挑战 III)。
这里主要引入了三个挑战,以及对三个挑战的解决方法。
挑战1:大多数研究都没有利用轨迹级别的信息,比如可重复性,这有助于识别用户。
挑战2:大多数研究都没有考虑轨迹的空间和时间特性,数据的标记方面存在稀疏性。
挑战3:忽视了轨迹用户对之间的时间跨度重叠约束。
阐述了框架原理:首先,将轨迹抽象为了图的节点,然后再这些节点之间构建三种类型的边,建模不同的轨迹关系,三种关系为:重复性关系,空间性关系,时空性关系,这样产生了三个同质图,两个异质图。然后,利用异构GCN(RGCNs),将图中节点特征映射到潜在表征,保留节点之间多重关系。值得注意的是,所有轨迹都包含在构造图中,无论它们是否被标记,这使得模型能够以半监督的方式进行训练,解决挑战 I 和 II。然后,通过LSTM在轨迹内级别对序列性进行建模。最后,将轨迹间和轨迹内的表示连接起来并送入分类层,以将输入轨迹与其所有者联系起来。通过最小化预测和真实数据之间的交叉熵成本进行训练后,训练后的模型可以直接用于通过选择分类层产生的具有最大概率的用户来链接匿名轨迹(解决挑战3)。基于整个输出,我们提出了一种贪婪的重新链接算法,以确保预测结果符合时间跨度重叠约束。
该框架的创新点是:
1.不仅考虑轨迹内信息,还考虑了轨迹之间的多种关系。
2.半监督的方法可以降低数据稀疏带来的弊端性。
3.提出了一个贪婪轨迹-用户重链接的方法进行测试。
4.保证了时间重叠跨度约束。
2 RELATED WORK
阐述了现有方法的缺陷。
现有的方法大多数都是完全监督学习的方法,无法在未标记的数据下展现较好的性能。并且很多方法没有考虑轨迹与用户之间的时间跨度重叠约束。他们只捕获轨迹内信息并通过现有的序列模型(如 LSTM 或注意机制)获得轨迹的表示。
3 METHODOLOGY
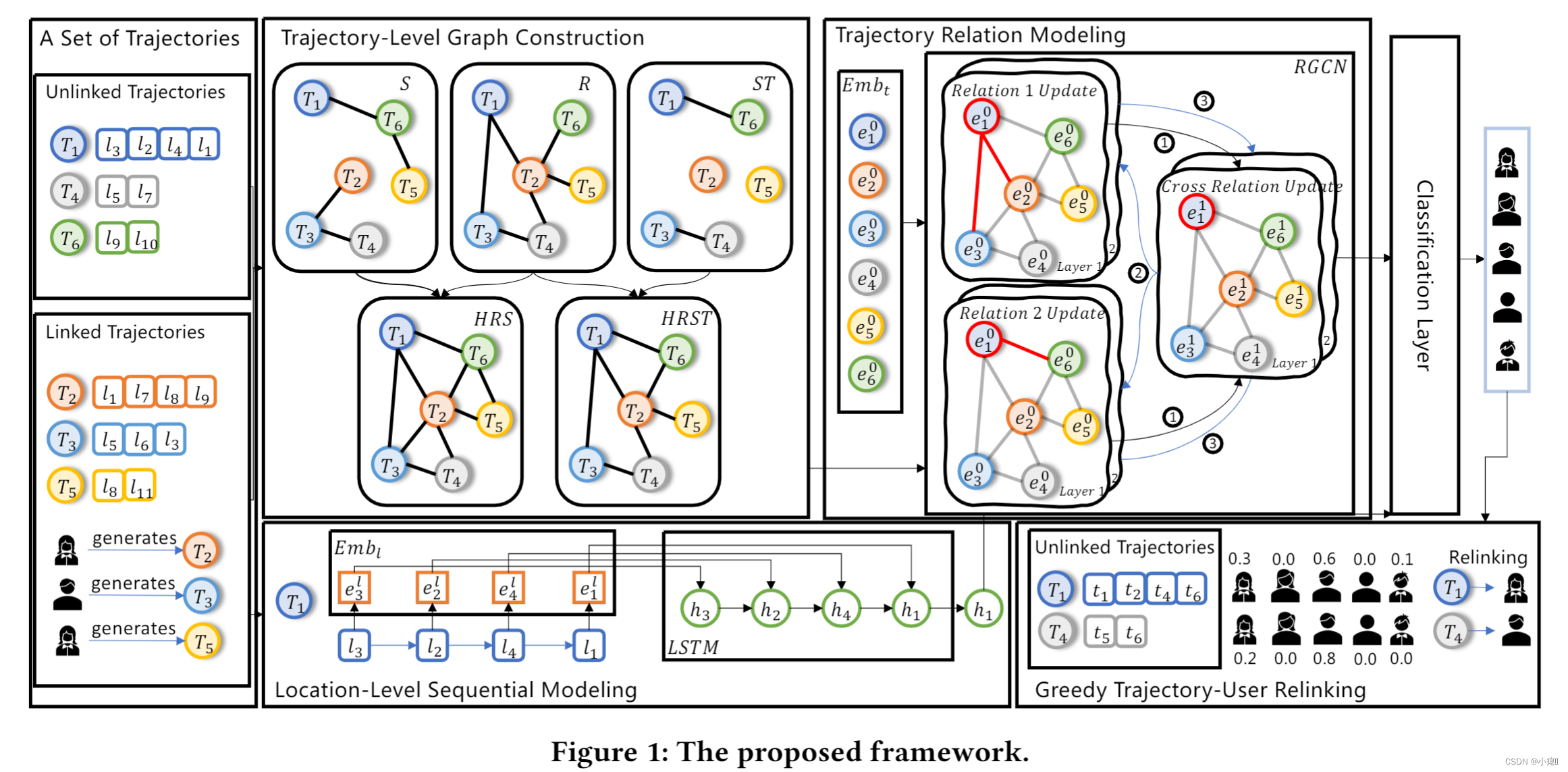
3.1 Framework Overview
主要对这个框架大体进行了介绍。将轨迹看作是图中的节点,传入轨迹级图构建模块中来考虑三种轨迹之间的关系,生成三个异质图:S为空间图,R为重复性图,ST为时空图。因为R与S,ST描述的关系完全不同,所以将R图与其他两个异质图合并,得到HRS,HRST。然后通过轨迹相关性建模模块的RGCN提取构建图的信息。在位置级别顺序建模中,对轨迹的具体位置信息进行建模。最后连接两个级别的表示并且分类,轨迹间种类关系表示与轨迹内信息表示。最后在贪心轨迹用户重组进行测试。
3.2 Trajectory-Level Graph Construction
Repeatability Graph
是上图的Trajectory-Level Graph Construction模块的R图。
重复性图建立在用户经常访问之前他们访问的地点的假设之上。构建规则是两条轨迹之间存在一条边,当且仅当这些轨迹共享至少一个 POI。创建重复性图之前先创建了一个轨迹-位置图的邻接矩阵,然后用该矩阵×自己转置得到重复性图的邻接矩阵。
如𝑇1 = ((𝑙3, 𝑡1), (𝑙2, 𝑡2), (𝑙1, 𝑡4), (𝑙4, 𝑡6)), 𝑇3 = ((𝑙5, 𝑡5), (𝑙6, 𝑡6), (𝑙3, 𝑡8)), and 𝑇4 = ((𝑙5, 𝑡5), (𝑙7, 𝑡6)).
T1 和 T3 有重复的兴趣点,T3和T4有重复的兴趣点,但是T1和T4没有,所以连接T1,T3两个被抽象的节点,还有T3和T4也连接起来。(见上图R图,依次推类)
然后构建重复图邻接矩阵,在此之前先创建trajectory-location graph: A t l A_{tl} Atl
注意
A
t
l
[
i
,
j
]
A_{tl}[i,j]
Atl[i,j]如果第 j 个位置被包含在第 i 个轨迹中,对应邻接矩阵的元素为1,否则为0.

具体的位置名称,内容都用一个离散的数字替代了,比如上面矩阵的列,第一列代表一个地点,第二列代表一个地点,等等。
Spatial Graph
空间图建立在假设用户访问的位置在空间上是局部的,即用户更喜欢访问在空间上靠近他/她之前访问过的位置的 POI。
空间图建立在用户访问的位置在空间上是局部的,即用户更喜欢访问在空间上靠近他/她之前访问过的位置的 POI的假设之上。为什么创建空间图呢?因为重复性图只考虑了人类移动的可重复性,空间属性没有保证。空间图在定义前需要先定义空间邻近度。

空间邻近度:两组轨迹间存在一个小于或等于空间因子的距离,则称两个轨迹是空间接近的。
空间图:空间图中的节点是轨迹,如果两个节点(两个轨迹的抽象化)满足空间邻近的条件,则两个节点间用一条边连接。


所以空间图通过枚举所有轨迹并找到满足两个定义来创建,这会导致指数级增长的计算量。在创建空间图之前先创建了一个位置邻近图,它的维度是轨迹数x轨迹数,当i条轨迹与j条轨迹小于等于空间因子则该元素为1,否则为0。空间邻接矩阵由两个公式得出,M是一个对角为0其余元素为1的矩阵,目的是使位置邻近图满足空间近邻度欧氏距离不为0的条件。
Spatio-Temporal Graph
时空图建立在假设用户访问的位置在空间和时间上是局部的,即用户更喜欢定期访问在空间上靠近他/她之前访问过的位置的 POI。
我们假设用户访问的位置在空间和时间上是局部的,即用户更喜欢定期访问在空间上靠近他/她之前访问过的位置的 POI。与前面的定义相比,多了定期地。即考虑空间和时间。时间信息是有帮助的,人类流动性具有周期性,所以创建了一个时空图。

时空邻近度:要同时满足空间因子和时间因子的距离(欧式距离和时间间隔)才能满足时空邻近度。
时空图中,轨迹也被抽象为节点来表示。满足定义3则两个节点间连接一条边。可以看出,时空图是空间图的一个子图,时空图的边是空间图的子集。作者于是枚举空间图的邻接矩阵中的非0元素,然后检查对应非0元素的轨迹对的空间距离和时间间隔是否同时满足定义3。满足定义3的话就链接对应的节点,构建ST图。
由于轨迹的可重复性不同于空间性和时空性,我们可以将𝑅与𝑆或𝑆𝑇合并以丰富构建图的表现力。 具体来说,我们获得了两个异构图,
A
H
R
S
A_{HRS}
AHRS(即合并可重复性和空间图)和
A
H
R
S
T
A_{HRST}
AHRST(即合并可重复性和时空图),其中边类型保留在合并图中,因为这些关系的重要性不等。
3.3 Trajectory Relation Modeling
上面构建的轨迹级图,由于节点的离散表示(即节点的特征)和图的任意架构,分类层不能直接利用它们将轨迹链接到生成的用户。因此,该模块的目标是将节点映射到潜在表示中,其中可以对节点之间的不同关系进行建模。
总的来说,该模块为同一关系种类下的节点和不同关系种类下的节点进行建模。即𝑅𝐺𝐶𝑁由两部分组成。 一种是更新内部关系中的表示,即
∑
k
∈
N
r
(
i
)
\sum_{k \in N_r(i)}
∑k∈Nr(i),另一种是更新相互关系中的表示,即
∑
r
∈
R
\sum_{r \in R}
∑r∈R,这使 𝑅𝐺𝐶𝑁 具有区别性学习来自具有不同关系的邻居的节点的表示。
详细地说,在RGCN中,共有两层卷积层,先在其中一种关系图中以一跳邻居滤波的方式学习当前节点及其邻居节点表征,学习完后学习下一个关系中的表征,然后在统一交叉学习刚刚两种关系的表征。经过两层相同操作,在最后一个交叉学习结束后传入分类层。

𝑬𝑡 是embedding层的待训练参数。𝐸𝑚𝑏𝑡 通过索引𝑬𝑡 将轨迹的特征转换为隐藏表示。激活 𝑅𝐺𝐶𝑁 的输出会降低链接的准确性。 因此在接下来的实验中,每次图卷积后都没有激活。
3.4 Location-Level Sequential Modeling
上面模块得到了轨迹级的信息,这个模块则得到位置级的信息。采用了LSTM来建模轨迹的序列信息。一个嵌入层将签到点的位置转化为隐藏表征。然后这些表征通过LSTM得到一个轨迹序列性的潜在向量。
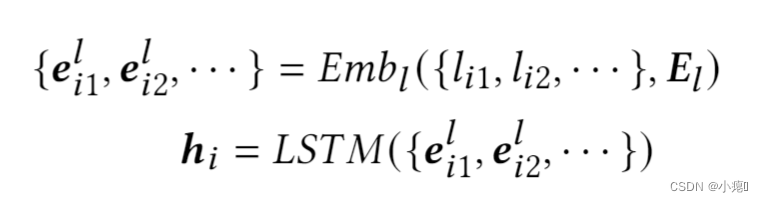
3.5 Classification Layer
轨迹级表征和位置级表征合并然后馈送入分类层分类,最小化交叉熵降低损失,得到的最大概率即为该用户制定的轨迹。
连接操作和softmax操作:
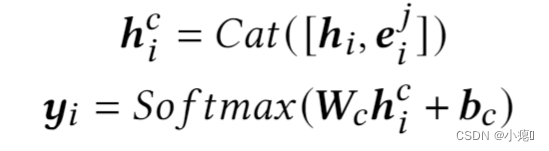
交叉熵损失函数:
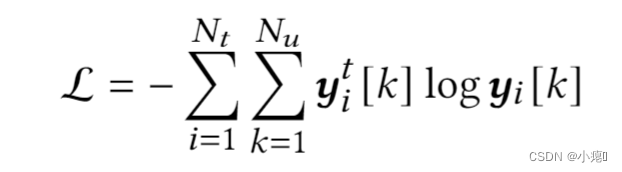
3.6 Greedy Trajectory-User Relinking
这里指出TUL不是一个简单的分类问题,因为存在时间跨度重叠约束问题。具有重叠时间戳的轨迹不能链接到同一用户,因为用户不能同时在不同的地方。如果没有重新链接算法来实现时间重叠约束,则由于位置之间的相似性,它们可能链接到同一用户。
如𝑇1 = ((𝑙3, 𝑡1), (𝑙2, 𝑡2), (𝑙1, 𝑡4), (𝑙4, 𝑡6)) and 𝑇4 = ((𝑙5, 𝑡5), (𝑙7, 𝑡6)),他们在
t
6
t_6
t6时间段时间重叠了,这说明这条轨迹是两个不同用户产生的,而不可能是一个用户。
所以这个模块的原理就是,在测试阶段将预测轨迹重新链接到用户。将所有的预测值进行排序,然后循环执行以下操作:如果轨迹 𝑖 没有链接 并且 轨迹 𝑖 的时间跨度不与用户 𝑘 已经分配的轨迹重叠的话,就把轨迹 i 分配给用户 k ;否则就跳过该轨迹继续循环直到遍历完列表。这样一个用户可能会链接多个轨迹,但是在不同的时间段。这样可以保证,用户的轨迹不存在在相同时间段在不同的地点的情况。保证了时间跨度重叠约束。
4 EXPERIMENTS
4.1 Datasets and Baselines
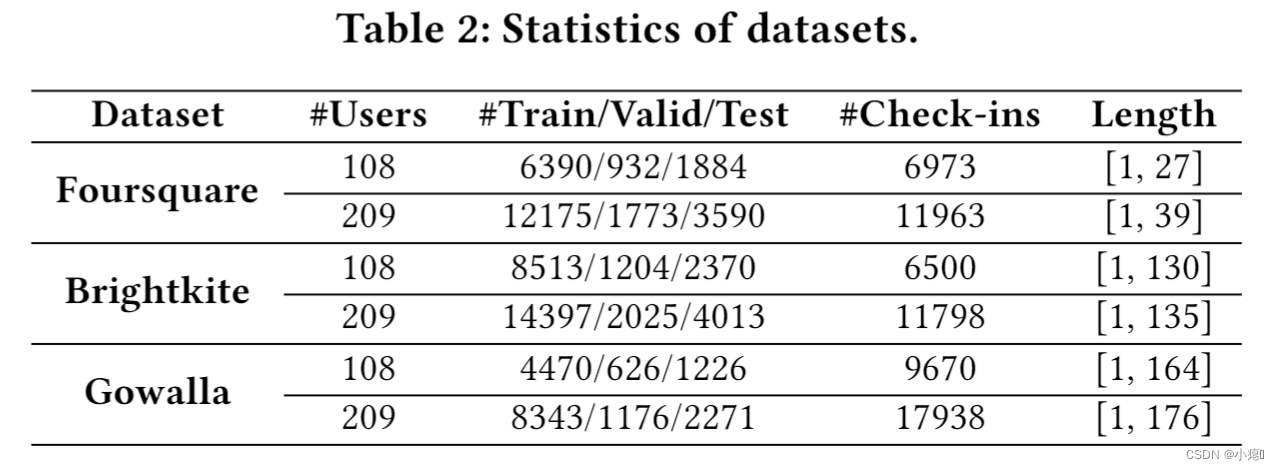

为了模拟 TUL 问题,对于每个用户,首先按时间顺序对签到进行排序,然后根据时间戳将原始轨迹拆分为多个子轨迹,即如果签到在同一天,会整理成一个子轨迹。将数据集拆成许多子集,然后过滤掉少于20个子轨迹的用户,然后随机选择108和209名用户实验,前70%为训练集,中间20%测试集,后10%验证集。baseline见论文。
4.2 Experimental Settings
超参数设置与度量方法。
4.3 Overall Comparison
总结了几种baseline的产生的实验结果的原因。然后阐述了本文模型的不同变体的实验结果,以及论述了不同变体之间所代表的关系的有效性。最后得出本文模型优于其他模型的结论。证明了一个重要性关系:重复性>空间性>时间性。
首先,𝑆2𝑇𝑈𝐿-𝑅可以始终优于大多数竞争对手,因为它考虑了人类移动的可重复性,并且轨迹级图使模型能够进行半监督训练(因为连接的轨迹和未连接的轨迹都被嵌入了节点表征中)。 此外,较高的 Macro@P 值也验证了 LCSSKNN 中的观察结果,即可重复性有助于精确识别用户。
其次,𝑆2𝑇𝑈𝐿-𝐻𝑅𝑆在大多数指标上优于𝑆2𝑇𝑈𝐿-𝑅,因为它根据空间假设将轨迹之间的空间关系纳入可重复性图中。 特别是在 Brightkite 和 Gowalla 数据集上,链接精度,即 Acc@1 和 Acc@5,得到了很大的改进,例如,在 Brightkite (#User=108) 上,Acc@1 of 𝑆2𝑇𝑈 𝐿-𝐻𝑅𝑆 和 𝑆2𝑇𝑈 𝐿- 𝑅分别为74.47和61.51。
第三,在大多数情况下,𝑆2𝑇𝑈𝐿-𝐻𝑅𝑆𝑇或𝑆2𝑇𝑈𝐿𝐻𝑅𝑆𝑇𝑆与其他实例相比表现最好,这表明时间信息和顺序性对于将轨迹链接到生成的用户很有用。 然而,这些方法的改进是有限的,这表明这些因素并不重要。

4.4 Effect of Main Factors
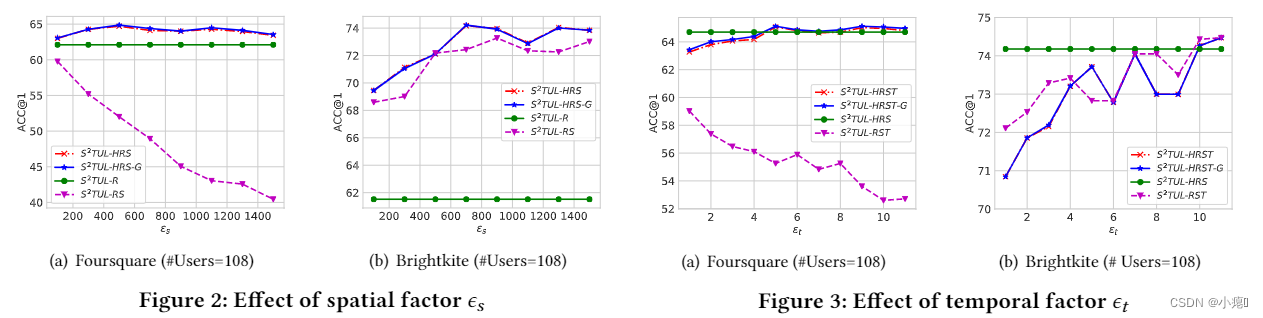
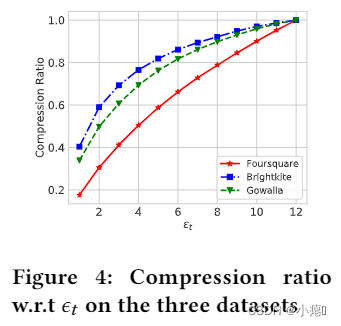
评估了空间因子,时间因子,异质图,贪婪重连接对实验的影响。
空间因子影响:每个数据集中,不同的空间因子效果表现不一样,最优表现的空间因子取值也不同。而且观察到𝑆2𝑇𝑈𝐿-𝐻𝑅𝑆,即红色虚线,在两个数据集上始终优于𝑆2𝑇𝑈𝐿-𝑅,即绿色实线,其中空间信息通过提出的轨迹级建模模块。这一观察结果进一步验证了轨迹之间空间关系在识别生成用户方面的有效性。
时间因子的影响:表明时间信息可以影响链接的准确性,但不是关键因素。
轨迹级图的异质性的影响:错误的融合将轨迹图的同质图融合为异质图实验结果将大打折扣。这一观察表明,以不正确的方式合并空间信息会对链接精度产生不良影响。这些观察结果表明,不同的信息来源,例如可重复性和空间性,发挥着不同的作用,应该区别对待。
贪心轨迹用户重新链接的影响:该方法的效果提升很小,具有有效性。然而,重新链接方法的改进是有限的,这可能是由于轨迹在时空上是稀疏的,并且大多数返回结果的时间跨度,即预测的轨迹-用户对,不冲突。 因此,重新链接算法对分类层直接返回的预测影响很小(即𝒚)。
4.5 Robustness Study
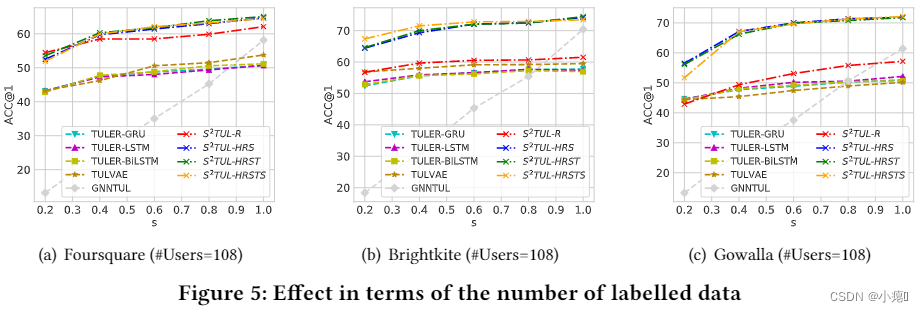
因此,作者在训练集中随机抽取一部分数据,并在保持测试集不变的情况下屏蔽未抽样数据的标签,其中抽样比例记为𝑠(即屏蔽了未标记的数据集,然后从所有有标记的数据集中抽样)。
上图中可以看见论文提出的模型是稳定的,并且比其他几个baseline平稳的多。
但S2TUL-HRSTS在各个数据集的s= 0.2 阶段表现不好,可能是因为位置嵌入是随机初始化和仅通过 TUL 任务的错误反向传播更新的,这很难用稀缺的标记数据很好地训练。
此外,与其他方法相比,TULER 的三种变体的性能相对稳定。 这是因为它们的位置嵌入首先使用所有数据(即未标记和标记轨迹)进行预训练。 在 TUL 任务上训练时,这些嵌入被冻结,只有其他参数会被更新,这可以帮助该模型在标记数据稀缺的情况下表现良好。 这一观察启发我们可以使用高级图形预训练方法在 RGCN 中预训练节点嵌入(即等式 3 中的𝑬𝑡)以进一步提高链接准确性,这将留作未来的工作。















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









