







这篇文章发表于2021年的ICC 2021,电子科技大学。
收获:1.通过应用GNN解决TUL问题。
2.采取的网络结构是通过GNN网络提取embedding,然后传入分类 器中进行分类。分类器采用BiLSTM提取双向时序特征,最后放入 多层感知机进行分类。
3.作者关注了更多签到点的特征信息,比如时间因素,地理位置因 素,用户访问偏好,天气因素绝对也是原因之一。
INTRODUCTION
Trajectory-User Linking (TUL) 是指将轨迹分类为相应生成的用户,已成为一项重要的时空数据挖掘任务,具有广泛的应用范围,从个性化位置推荐和行程规划到犯罪行为检测和对象跟踪 . 尽管最近基于深度学习的人类移动学习模型取得了进展,但与个人背景和用户位置交互相关的一些关键因素尚未得到充分探索。 此外,由于轨迹学习和上下文位置嵌入的复杂性增加,现有作品存在高计算成本问题。 在这项工作中,我们提出了一种名为 GNNTUL 的新型端到端模型,该模型由图形神经网络 (GNN) 模块和分类器组成,可有效且高效地学习人类移动性并将痕迹与在线社交网络中的用户相关联。 GNNTUL 是第一个基于 GNN 的人类移动学习模型,它利用在线社交网络中稀疏用户轨迹背后的隐式转换模式,同时提取用户独特的运动特征并区分运动轨迹。 在两个真实世界的数据集上进行的大量实验证明了 GNNTUL 在链接准确性和学习效率方面优于几个最先进的基线。
METHODOLOGY
A.Problem defination

B.Trajectory segmentation
每个用户轨迹长度不一,时间跨度不一样。并且用户签到存在周期性,所以轨迹需要分割,按照一定的时间间隔。
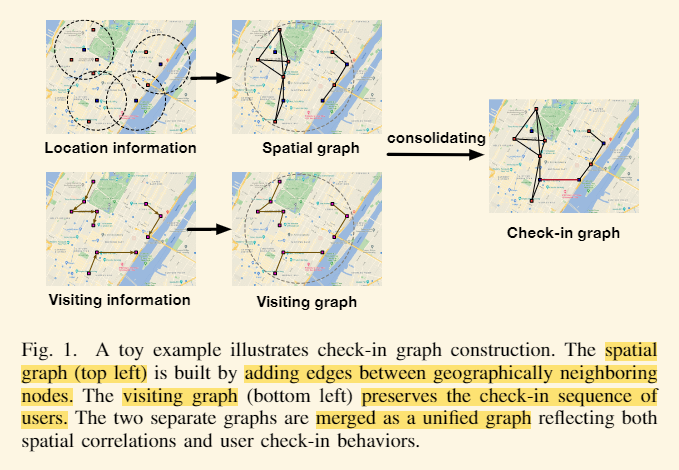
C.Check-in Graph Construction
作者分别制定了两个图,位置信息图和访问信息图。目的是说明签到点的地理特征和用户访问偏好,然后合并这两个图以生成最终签到图。位置信息图是一个签到地点位置信息图,以各点距离为基准,以一个距离阈值连接不超过这个阈值的点,组成无向图。访问信息图是一个有向图,表示一个轨迹访问地点的顺序。作者合并这两个图,并且将他们不重复的地方叠加起来。
D.GNN-TUL
由GNN与分类器组成。
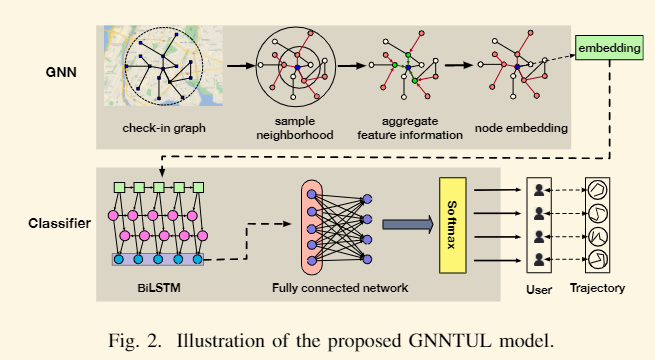
GNN:构建一个由点集合,边集合,单位特征矩阵初始化组成的原始图。并且有一个格外的签到点类别矩阵,他包含每个签到点的类别信息,是一个多维矩阵,每一维度代表该签到点的某一类的特征。然后把它和特征矩阵结合组成embedding。GNN的每层聚合节点及其周围节点的特征,然后通过多个层的叠加交互捕获高阶特征。作者在聚合任务中采用的是中值聚合操作。
分类器:采用的是BiLSTM和一个全链接网络。BiLSTM用于处理时序的轨迹信息,作者使用这个是为了加强网络对轨迹的记忆能力,得到一个具有良好轨迹记忆的trajectory embedding。然后最后放入FCN中进行分类。
EXPERIMENTS
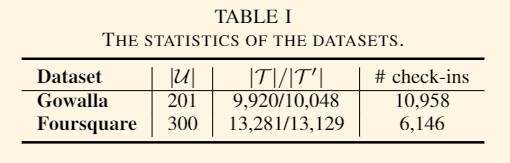
使用的数据集:
基线方法的实验设置遵循他们论文中报告的设置。 对于 GNNTUL,超参数设置如下:GNN 模块中的层数 L 为 1; GNN模块的输出维度为128; 优化器是 Adam,学习率为 0.005。
作者说明了大多数方法都存在一个数据集数据稀疏导致的问题,因为用户的签到并不是必须的,很多用户缺少签到。 作者尝试嵌入稀疏和高阶交互的方法,而不是明确地从 LBSN 数据中学习轨迹分布。 作者说明 GNNTUL 和基线之间的关键区别在于学习位置嵌入的方式。 不是仅仅依赖确定性 RNN 模型或利用稀疏轨迹中编码的随机变量,而是从构建的签到图中学习用户位置交互,这使模型能够探索训练数据中有限访问行为之外的模式。 此外,GNN 模块捕获位置之间的空间和高阶相关性,并通过合理的转换模式将不存在引入到编码的位置嵌入向量中。

效率实验:
耗时短。
GNNTUL 中的超参数是 GNN 模块中的层数。 直观地说,更多的层会导致更好的位置嵌入性能,从而提高 TUL 性能。 图 3 显示了结果,我们可以观察到随着层数的增加,模型性能略有下降。 这一结果最初是违反直觉的,这可以通过 GNN 的性质和轨迹数据的内在特征来理解。 一方面,由于 GNN固有的过于光滑的特性,GNN 通常会遇到浅模型问题。 另一方面,节点聚合将在我们的数据集中经过两跳后到达大多数邻居,这意味着节点/签到的表示将变得非常相似且区分度较低。















 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









