







1.项目背景
随着社会的进步与大众对健康与安全问题的日益关注,酒精消费对社会经济、健康和文化的影响逐渐成为研究热点,尤其在俄罗斯这样一个以酒类文化著称的国家,酒精消费量和消费结构的变化不仅反映了社会经济的动态,还直接影响着公众健康和社会稳定。因此,分析俄罗斯各地区2017年至2023年间的酒精消费数据,不仅能揭示不同酒类的消费特征,还能通过数据支持深入了解区域差异、消费趋势及其潜在影响。
2.数据说明
| 字段 | 说明 |
|---|---|
| Year | 年份(2017-2023) |
| Region | 地区名称 |
| Wine | 每年人均葡萄酒消费量(升) |
| Beer | 每年人均啤酒消费量(升) |
| Vodka | 每年人均伏特加消费量(升) |
| Sparkling wine | 每年人均起泡酒消费量(升) |
| Brandy | 每年人均白兰地消费量(升) |
| Cider | 每年人均苹果酒消费量(升) |
| Liqueurs | 每年人均利口酒消费量(升) |
| Total alcohol consumption (in liters of pure alcohol per capita) | 每年人均纯酒精总消费量(升) |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.decomposition import PCA
from scipy.stats import pearsonr
import statsmodels.formula.api as smf
from statsmodels.stats.outliers_influence import variance_inflation_factor
import statsmodels.api as sm
from scipy.stats import chi2
data = pd.read_csv("/home/mw/input/01069054/Consumption of alcoholic beverages in Russia 2017-2023.csv")
4.数据预览及预处理
print('查看数据信息:')
data.info()
查看数据信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 595 entries, 0 to 594
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Region 595 non-null object
1 Year 595 non-null int64
2 Wine 595 non-null float64
3 Beer 595 non-null float64
4 Vodka 595 non-null float64
5 Sparkling wine 595 non-null float64
6 Brandy 595 non-null float64
7 Сider 595 non-null float64
8 Liqueurs 595 non-null float64
9 Total alcohol consumption (in liters of pure alcohol per capita) 595 non-null float64
dtypes: float64(8), int64(1), object(1)
memory usage: 46.6+ KB
print(f'查看重复值:{
data.duplicated().sum()}')
查看重复值:0
print("数据中Region的唯一值情况:")
print(f'共有:{
len(data["Region"].unique())}条唯一值')
print(data['Region'].unique())
数据中Region的唯一值情况:
共有:85条唯一值
['Belgorod Oblast' 'Bryansk Oblast' 'Vladimir Oblast' 'Voronezh Oblast'
'Ivanovo Oblast' 'Kaluga Oblast' 'Kostroma Oblast' 'Kursk Oblast'
'Lipetsk Oblast' 'Moscow Oblast' 'Oryol Oblast' 'Ryazan Oblast'
'Smolensk Oblast' 'Tambov Oblast' 'Tver Oblast' 'Tula Oblast'
'Yaroslavl Oblast' 'Moscow' 'Republic of Karelia' 'Komi Republic'
'Nenets Autonomous Okrug' 'Vologda Oblast' 'Kaliningrad Oblast'
'Leningrad Oblast' 'Murmansk Oblast' 'Novgorod Oblast' 'Pskov Oblast'
'Saint Petersburg' 'Arkhangelsk Oblast' 'Republic of Adygea'
'Republic of Kalmykia' 'Republic of Crimea' 'Krasnodar Krai'
'Astrakhan Oblast' 'Volgograd Oblast' 'Rostov Oblast' 'Sevastopol'
'Republic of Dagestan' 'Republic of Ingushetia'
'Kabardino-Balkar Republic' 'Karachay-Cherkess Republic'
'Republic of North Ossetia-Alania' 'Chechen Republic' 'Stavropol Krai'
'Republic of Bashkortostan' 'Mari El Republic' 'Republic of Mordovia'
'Republic of Tatarstan' 'Udmurt Republic' 'Chuvash Republic' 'Perm Krai'
'Kirov Oblast' 'Nizhny Novgorod Oblast' 'Orenburg Oblast' 'Penza Oblast'
'Samara Oblast' 'Saratov Oblast' 'Ulyanovsk Oblast' 'Kurgan Oblast'
'Sverdlovsk Oblast' 'Khanty–Mansi Autonomous Okrug – Yugra'
'Yamalo-Nenets Autonomous Okrug' 'Chelyabinsk Oblast' 'Tyumen Oblast'
'Altai Republic' 'Tuva Republic' 'Republic of Khakassia' 'Altai Krai'
'Krasnoyarsk Krai' 'Irkutsk Oblast' 'Kemerovo Oblast'
'Novosibirsk Oblast' 'Omsk Oblast' 'Tomsk Oblast' 'Republic of Buryatia'
'Sakha (Yakutia) Republic' 'Zabaykalsky Krai' 'Kamchatka Krai'
'Primorsky Krai' 'Khabarovsk Krai' 'Amur Oblast' 'Magadan Oblast'
'Sakhalin Oblast' 'Jewish Autonomous Oblast' 'Chukotka Autonomous Okrug']
Region 列包含了 85 个唯一值,正好与俄罗斯的 85个联邦主体 相符。这些区域名称涵盖了俄罗斯的所有联邦主体,包括:
- 22个共和国(如:Republic of Karelia、Republic of Tatarstan、Republic of Dagestan 等)
- 9个边疆区(如:Krasnoyarsk Krai、Primorsky Krai、Altai Krai 等)
- 46个州(如:Moscow Oblast、Bryansk Oblast、Leningrad Oblast 等)
- 3个联邦城市(如:Moscow、Saint Petersburg、Sevastopol)
- 4个自治区(如:Khanty–Mansi Autonomous Okrug、Yamalo-Nenets Autonomous Okrug 等)
考虑:Total alcohol consumption (in liters of pure alcohol per capita)列名太长了,这里缩短一些。
data = data.rename(columns={
"Total alcohol consumption (in liters of pure alcohol per capita)": "Pure Alcohol"})
feature_map = {
'Wine': '每年人均葡萄酒消费量(升)',
'Beer': '每年人均啤酒消费量(升)',
'Vodka': '每年人均伏特加消费量(升)',
'Sparkling wine': '每年人均起泡酒消费量(升)',
'Brandy': '每年人均白兰地消费量(升)',
'Сider':'每年人均苹果酒消费量(升)',
'Liqueurs':'每年人均利口酒消费量(升)',
'Pure Alcohol':'每年人均纯酒精总消费量(升)'
}
plt.figure(figsize=(20, 10))
for i, (col, col_name) in enumerate(feature_map.items(), 1):
plt.subplot(2, 4, i)
sns.boxplot(y=data[col])
plt.title(f'{
col_name}的箱线图', fontsize=14)
plt.ylabel('数值', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
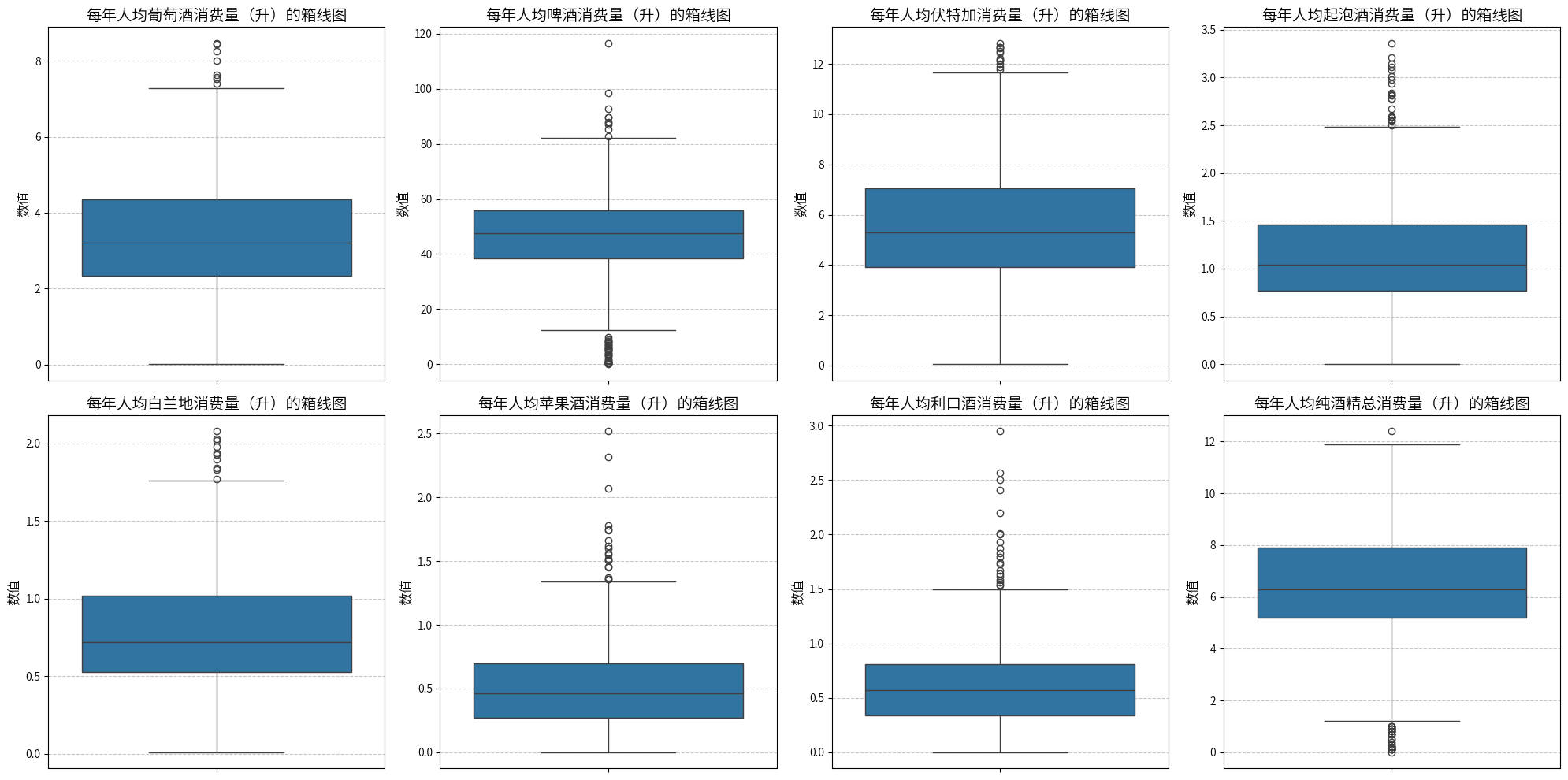
数据来自Federal Service for Alcohol Market Regulation(俄罗斯联邦酒类市场监管局),因此虽然存在部分的异常值,但仍然可以认为数据是真实有效的,故不处理。
5.时间趋势分析
alcohol_mapping = {
"Wine": "葡萄酒",
"Beer": "啤酒",
"Vodka": "伏特加",
"Sparkling wine": "起泡酒",
"Brandy": "白兰地",
"Сider": "苹果酒",
"Liqueurs": "利口酒",
"Pure Alcohol":"纯酒精消费量",
"Total": "总酒精消费量"
}
# 按年份聚合数据,计算各酒精类型的总消费量
trend_data = data.groupby('Year')[["Wine", "Beer", "Vodka", "Sparkling wine", "Brandy", "Сider", "Liqueurs","Pure Alcohol"]].sum()
# 计算所有酒精类型的总消费量
trend_data["Total"] = trend_data.iloc[:,:-1].sum(axis=1)
# 计算增长率
growth_rate = trend_data.pct_change() * 100 # 按年份计算增长率(百分比)
fig, axes = plt.subplots(3, 3, figsize=(20, 16))
# 遍历每种酒精类型进行绘制
for i, alcohol in enumerate(trend_data.columns):
row, col = divmod(i, 3) # 计算子图的行和列
ax1  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









