







1.项目背景
随着二手车市场的快速发展,消费者对二手车的需求逐渐增加,然而,由于二手车的定价涉及多种复杂因素,不同条件下的车辆价值差异较大,如何精准地评估二手车的市场价值成为了一个亟待解决的问题。本项目通过数据分析和机器学习建模,尝试识别并量化影响二手车价格的主要因素,并构建一个价格预测模型,为消费者和行业从业者提供数据支持。
2.数据说明
| 字段 | 说明 |
|---|---|
| id | 唯一标识符 |
| brand | 品牌 |
| model | 具体型号 |
| model_year | 汽车的制造年份 |
| milage | 汽车的行驶里程 |
| fuel_type | 汽车所使用的燃料类型 |
| engine | 发动机规格 |
| transmission | 变速器类型 |
| ext_col | 外观颜色 |
| int_col | 内饰颜色 |
| accident | 车辆是否有事故或损坏的历史记录 |
| clean_title | 是否拥有健全良好的所有权证明 |
| price | 汽车标价 |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import re
from scipy.stats import chi2_contingency,ks_2samp,spearmanr,f_oneway
from datetime import datetime
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import RidgeCV, Ridge
from sklearn.preprocessing import StandardScaler
train_data = pd.read_csv("/home/mw/input/10128271/train.csv")
test_data = pd.read_csv("/home/mw/input/10128271/test.csv")
4.数据预处理
4.1数据预览

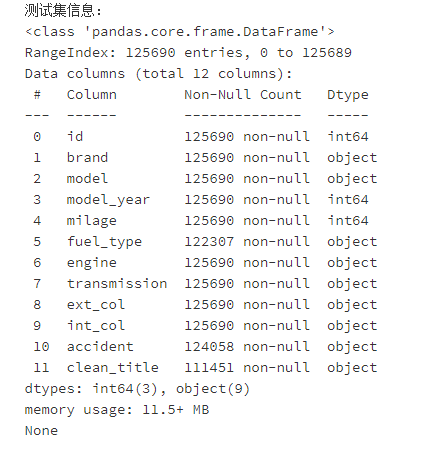
两个数据均存在不同程度的缺失值。
训练集中存在的重复值:0
测试集中存在的重复值:0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









