






 本文介绍基于Transformer的NIDS方法,使用基于流的网络数据,减少分析量。阐述Net - flow背景,构建基于Transformer的NetFlow框架。详细介绍FlowTransformer框架,包括组件、实现步骤,如数据集摄入、预处理等,还提及模型训练、评估指标、超参数等内容。
本文介绍基于Transformer的NIDS方法,使用基于流的网络数据,减少分析量。阐述Net - flow背景,构建基于Transformer的NetFlow框架。详细介绍FlowTransformer框架,包括组件、实现步骤,如数据集摄入、预处理等,还提及模型训练、评估指标、超参数等内容。
基于transformer的NIDS的方法
FlowTransformer允许替换各种Transform组件,包括输入编码、transformer、分类头部、数据集,对基于transformer的NIDSs进行评估
发现是分类头部的选择对模型的性能影响最显著
- 引言
Transformer架构用于捕获各种类型序列数据中的复杂模式和关系(各种数据类型),数据捕获成数据包或流的序列
使用基于流的网络数据
- 减少分析的数据量,使其具有扩展性,有助于处理大量的网络流量
- 大多数网络都已经运行基于流的收集器
- Net-flow背景
本文使用netflow版本,以此进行网络流量的收集以及监控协议,也可以用其他流标准IPFix和SFlow
- 用于NIDS的transformer
基于transformer的NetFlow框架:将netflow导出器聚合的流输入到transformer模型来为每个记录进行分类
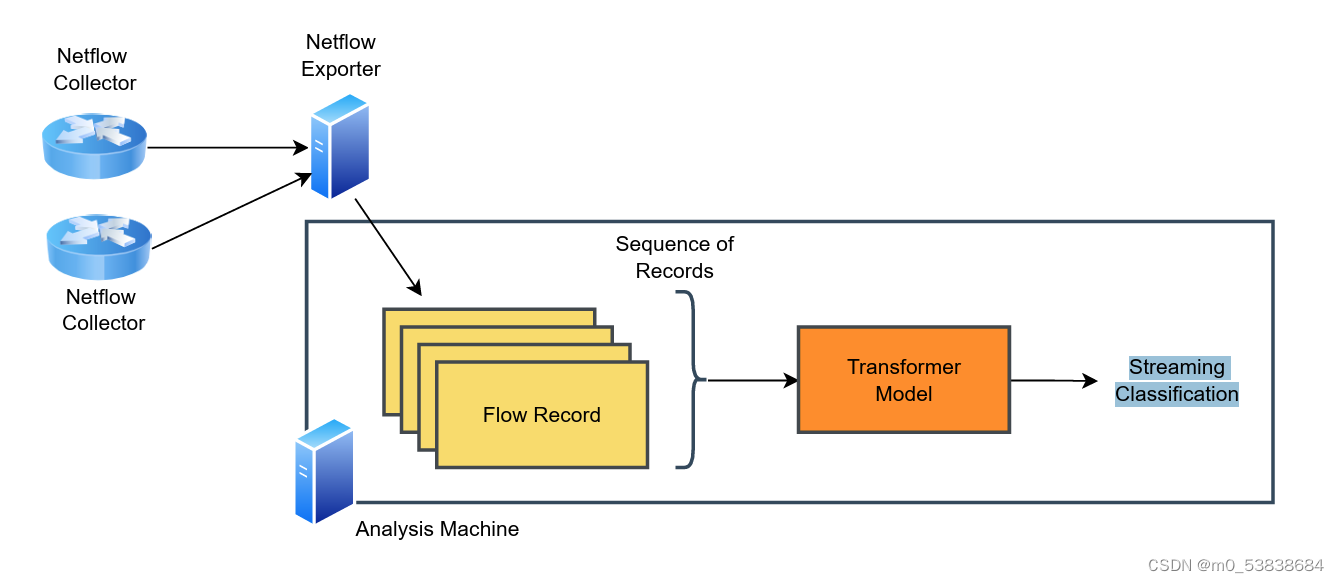
基本的transformer分为三个部分:输入编码器、transformer、输出头部
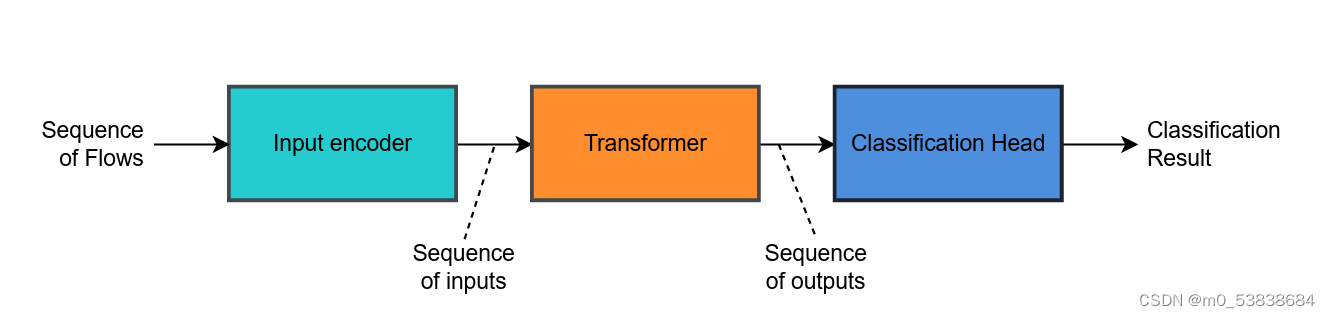
输入编码:
将文本输入进来转换成一系列固定长度的向量以便transformer模型处理(GPT模型使用变体的字节实现)。NIDS中就是让网络流转换为向量。输入编码器在不断学习然后继续编码
Transformer块:
一堆transformer块组成,每个块都执行转换,这些块可以使编码器或者解码器,编码器块主要是将输入序列转换为固定长度的特征表示,解码器块接收特征表示输出一个序列。NIDS里,编码器块将每个流转化为固定长度的特征向量,解码器块将特征向量输出成流记录。传统的是一堆编码器和一堆解码器,但在NIDS中,由于输入流输出的是单个分类输出,故解码器对可以替换成分类头,比如BERT就是只用了编码器,GPT只用的解码器
分类头:
输入输出都是序列,NIDS中输出的是分类
- flowtransformer框架
flowtransformer组件有预处理技术、输入编码、transformer块、分类头.
(1)数据预处理:数据预处理这些表格有两种方法(性能最高的是限制频率的独热编码)
-
-
- 分类字段单独编码,将其转换为具有上下文含义的连续向量,将这些向量与数值字段连接起来形成特征向量
- 同时嵌入所有字段,同时处理数值和分类字段,分类字段可用独热编码然后与数值链接传递给编码层
-
(2)输入编码
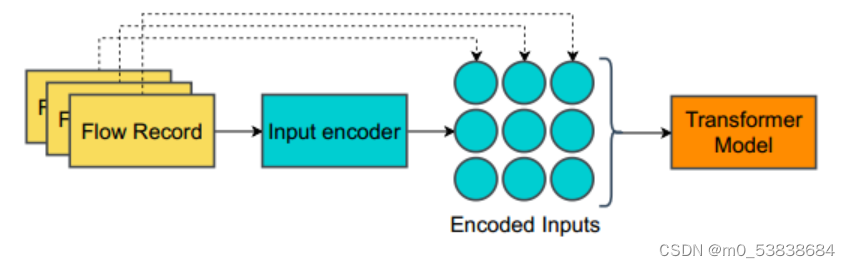
流记录:表格数据,每个流的字段是已知且固定的,该数据包包含数值字段和分类字段。
输入编码将每个流转换为可被transformer处理的特征向量,不同的分类类型输入编码也要适当处理,确保生成的特征向量捕获了transformer要使用的相关信息。
此步骤对分类字段编码的方法:(都是降维)
- 查找的嵌入层:查找嵌入层将分类输入的唯一值映射到连续特征向量集,训练时学习向量的值
- 密集的嵌入层:将分类输入用非线性转换映射到特征向量,本质上是有激活函数的单层神经网络,训练时学习转换
- 投影层:分类输入现行转换成特征向量
此步骤对分类+数值→记录级别的方法:(流记录的数值部分有共享信息部分,故将整个留记录嵌入到编码器中)
-
- 记录级别嵌入→密集:分类字段用独热编码,并于数值字段链接传递给嵌入层,将最后的记录映射到连续的特征向量
- 记录级别投影:先行转换分类字段能省略了非线性的激活和偏差,其余跟嵌入相同
其他方法:无编码:少量特征的流,分类字段如果进行独热编码,由于流已经经过了预处理,故可直接传递给transformer
(3)transformer模型
比较了四种transformer 架构:浅编码器、浅解码器、深编码器、深解码器(深浅的区别在于深度、注意力头数、内部大小)
浅模型基于基本的多头自注意力模型,并包含2-6个编码或解码器块。
深编码器考虑了两种特定的模型GPT2.0和未遮蔽的BERT。虽然都使用了缩放点积注意力,但BERT注意机制是双向的,GPT只有前面的单向标记
A.GPT2.0→深解码器:12个解码器块,每个块的输入作为下一个块的输出,它的学习是根据输入序列和先前生成的单词的组合生成下一个单词。将输入提示也作为序列的一部分,将每个单词作为上下文的一部分来生成输出,从而预测后续单词
B.BERT→深编码器:bert的设计主要是用于自然语言理解任务而不是文本生成,这个模型进行训练,用来执行掩码语言建模和预测两个句子是否连续。输入序列通过编码器堆进行处理,最后生成序列的固定长度表示
(4)分类头选项
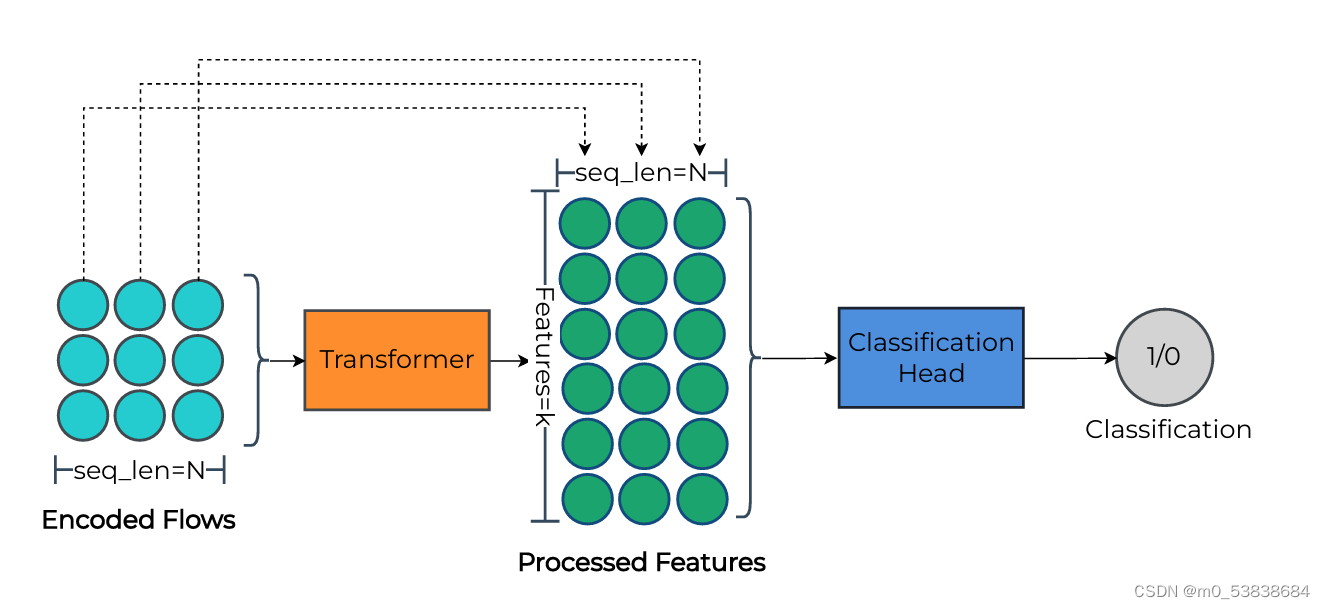
Transformers是序列到序列的模型,故要将序列输出操作传递到MLP中,然后转化为NIDS的分类结果。但是序列长度的增加,参数数量成指数级增长,故需要在传递到MLP之前特征向量要被展平
NLP分类的方法:①全局平均池化:对特征向量中整个序列上的该值的平均值。在流的情况下,如果只有序列中最后一个流正在被分类,那么对先前流的上下文平均,那么不是一个好方法 ②时间分布式:模型对序列中不同的流赋予不同的权重。NIDS的分类任务中,只关注最后一个流的类别,故transformer仅仅使用最后一个上下文嵌入就可以,然后将其用作分类头的输入
执行多个任务的模型,引入一个特殊的标志,指示模型执行特定的任务,故在流序列末尾标记分类,使用transformer相应输出来执行分类来测试在NIDS领域的有效应。优点是泛化性好
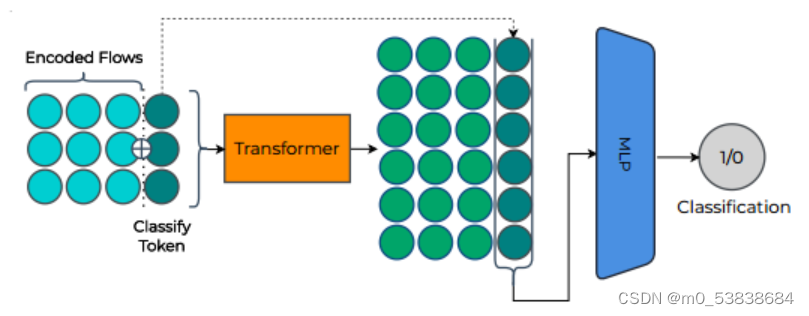
- 实现
Flowtransformer框架包括几个可互换的模块,形成一个处理管道。一下是flowtransformer组件
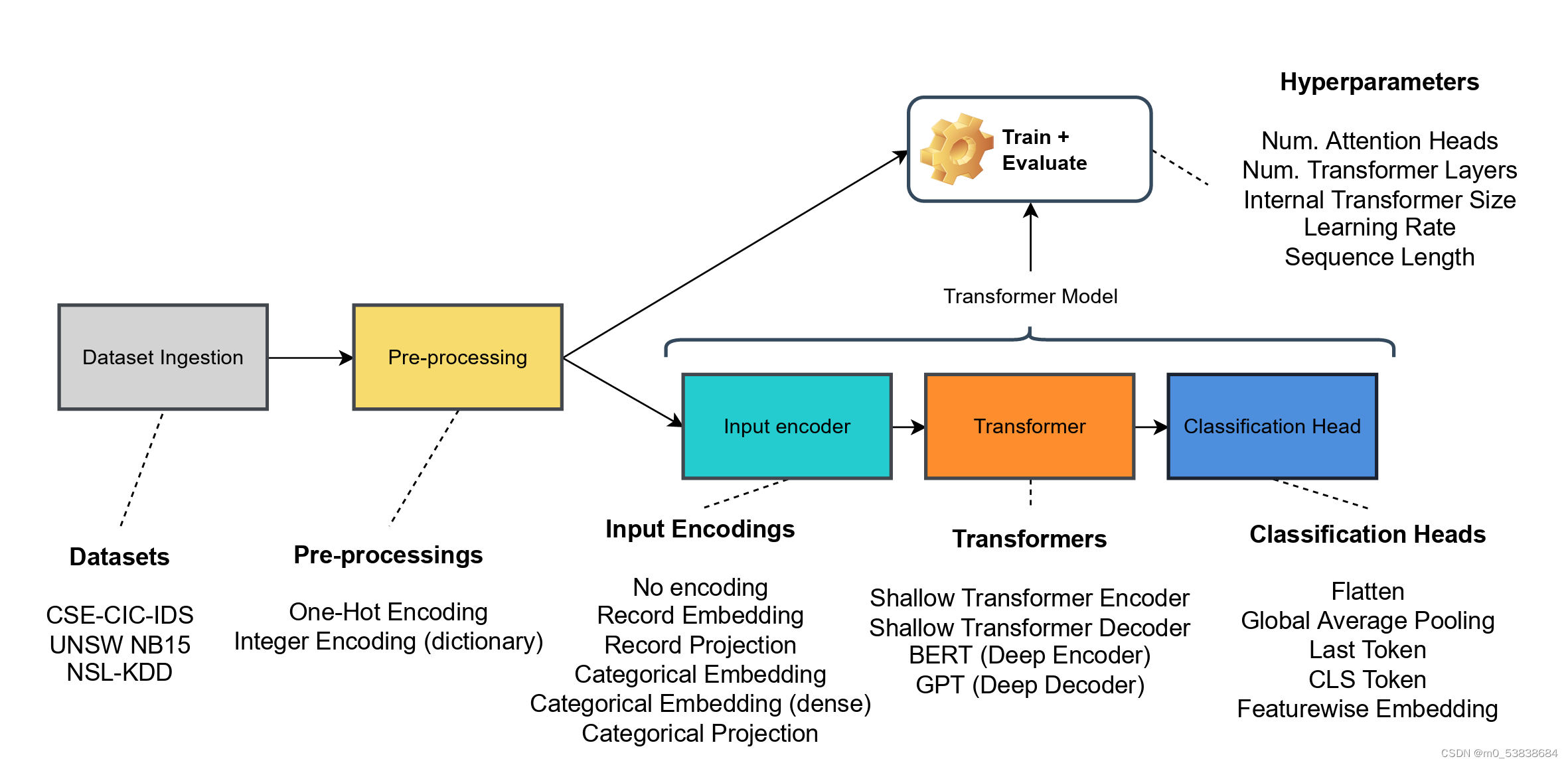
- 数据集摄入:
该组件可容纳任何表格数据集,与各种流量数据格式兼容,也会自动处理超过范围或者缺失的值。因为要应用与特定数据集,所以必须要提供数据及规范,首先要列出数据集的分类和数值特征,供预处理和输入编码阶段使用,还要规范训练的类别列出来和良性流量标签,用于识别恶意和合法流量。提供数据规范后,flowtransformer就可以在后续阶段摄入数据集而无需编码
- 预处理
收到数据集后,flowtransformer加载并分割用于预处理训练与评估拆分。本文以90%和10%来划分。预处理先适用训练数据(训练期间没有信息泄漏到评估数据集),在应用于整个数据集。并且跟读输入编码器的要求,对分类变量进行独热编码或整数编码,对N个最常见的分类特征进行编码,取完对数后对数值特征进行最小-最大缩放
- 模型管道
Transformer的模型,构建为TensorFlow模型,可以独立编译和训练,有输入编码器、输出编码器、transformer
-
- 输入编码器
通过上述说的分类方法将数据转换为适合transformer的编码格式
-
- transformers
可替换任何一个模型
-
- 输出编码器
分类头接受输出,并转换为分类,支持二元以及多元分类
- 训练+评估支持
为了更快加载数据集,需要优化,从而使超参数搜索更快
- 方法论:
收集结果时,执行一个网格搜索。本文的维度:输入编码、transformers块类型,transformer深度、transformer前馈大小、注意力头数、分类头、学习率
- 模型训练和网格搜索
对目标空间进行网格搜索时,至少重复每个实验3次,选择最佳重复的结果。模型训练使用早停法(模型调优,防止过拟合,提升泛化能力)和一次迭代限制。早停设置为5次迭代的耐心等待,最大迭代次数限制为20。使用Adam优化器(自适应学习率优化算法,自动调整学习率,适应不同的数据分布和模型结构)进行训练,参数在论文中定义,学习率在实验中指定
- 数据集
NSL-KDD
UNSW-NB15
CSE-CIC-IDS2018
- 评估指标
F1分数(主要指标)、误报率、检测率,使用TP/TN/FP/FN训练
- transformer超参数
除了比较输入编码方法和分类头外,还有各种transformer配置及相应的超参数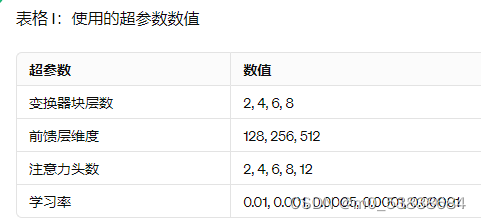
- 推断时间和训练时间
GPU清空,从a warm TensorFlow状态开始计时,训练时间通过,计时每个批次 来衡量,再除以 批次大小,并将训练过程中使用的 所有批次 求平均,使用的是TensorFlow的“train on batch”函数

















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









