






众所周知,run_dbcan是CAZyme注释的最经典软件
而run_dbcan的结果通常储存在overview.txt文件之中:
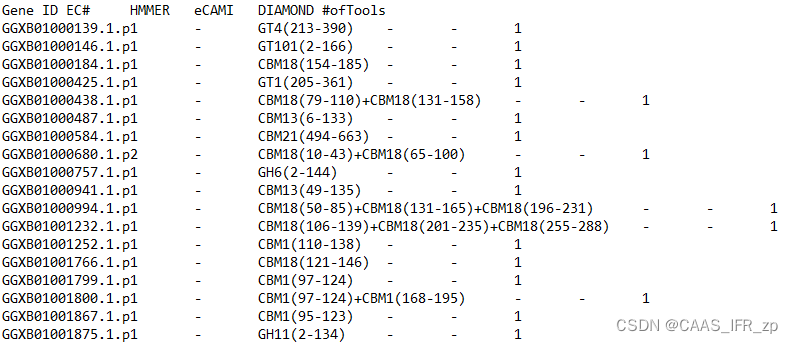
这里选择的是HMMER方式跑的,所以只有第三列有注释的结果
为了统计overview.txt文件的各个家族情况,写下一个简单的代码:
inputTXT = args.inputTXT
output = args.output
f = open("%s" %(inputTXT), "r")
db= {}
for line in f.readlines():
line = line.split("\t")[2]
if "HMMER" not in line:
line = line.split("+")
for i in line:
i = i.split("(")[0]
if i in db:
db[i] += 1
if i not in db:
db[i] = 1
f2 = open("%s" %(output),"a")
print("\t"+inputTXT,file=f2)
for ID, seq in db.items():
ID_3 = ID.strip()
print(ID_3,end="\t",file=f2)
print(seq,file=f2)
f.close()
f2.close()统计结果为
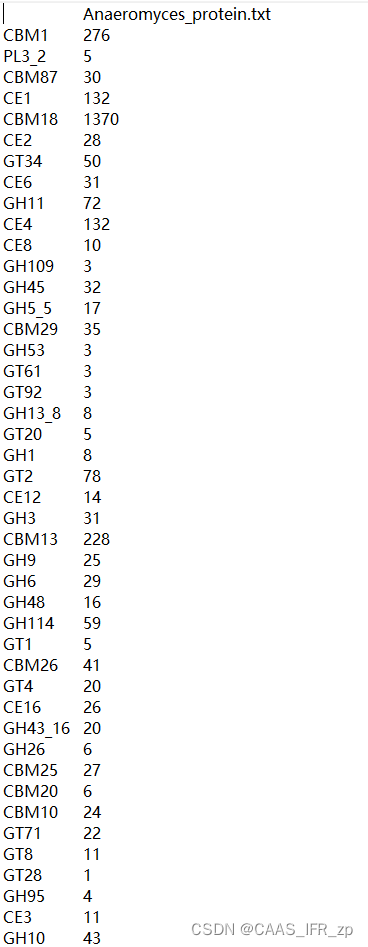
但是,当我们有好几个overview文件之后,因为每个文件的第一列的类型不一样,不能随便的进行文件组合,不好分析,所以想写一个脚本组合之后方便分析。
ls_xijie_result = []
ls_domain_result = {}
ls_db_result = []
for txt in os.listdir(os.getcwd()):
if "_xijie.txt" in txt:
ls_xijie_result.append(txt)
for file in ls_xijie_result:
f = open("%s" % (file),"r")
for line in f.readlines():
if ".txt" not in line:
line = line.split("\t")[0].strip("\n")
ls_domain_result[line] = 0
f.close()
file_count=0
for file in ls_xijie_result:
f2 = open("%s" % (file), "r")
file_count += 1
db=str(file)
db=ls_domain_result.copy()
for line in f2.readlines():
if ".txt" in line:
line = line.split("\t")[1].strip("\n")
file_name=line
if ".txt" not in line:
domain = line.split("\t")[0].strip("\n")
count = line.split("\t")[1].strip("\n")
if domain in db.keys():
db[domain]=count
ls_db_result.append(db)
f2.close()
header=[]
for key in ls_domain_result.keys():
header.append(key)
with open('merge_overview_2.csv', 'a', encoding='utf-8', newline='') as f3:
dictWriter = csv.DictWriter(f3,header)
dictWriter.writeheader()
dictWriter.writerows(ls_db_result)
f3_rows=[]
f3 = open('merge_overview_2.csv',"r")
for line in f3.readlines():
f3_rows.append(line)
f3.close()
f4 = open('merge_overview_3.csv',"a")
print("",end=",",file=f4)
print(f3_rows[0].strip("\n"),file=f4)
row_count=0
for i in ls_xijie_result:
row_count += 1
print(i,end=",",file=f4)
print(f3_rows[row_count].strip("\n"),file=f4)
f4.close()
结果如下
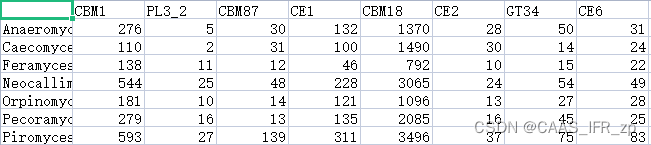
在excel中,复制为转置之后,再排序一下,就可以很直观的分析了!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









