







 本文探讨了在移动预测中使用的三种熵值概念:随机熵、时间无关熵和真实熵,并详细介绍了它们的计算方法及如何应用于连续变化的资源预测问题。通过熵值分析,可以评估预测的不确定性并确定预测的上下界。
本文探讨了在移动预测中使用的三种熵值概念:随机熵、时间无关熵和真实熵,并详细介绍了它们的计算方法及如何应用于连续变化的资源预测问题。通过熵值分析,可以评估预测的不确定性并确定预测的上下界。
最近看了一些和熵值有关的论文,在此总结一下。
一、 随机熵、时间无关熵、真实熵

(2010)考虑用户的活动轨迹,Q的值在这里指的是用户所访问的不同的位置。
从预测人类和电子病毒的传播到城市规划和移动通信中的资源管理,一系列的应用都依赖于我们对个人的去向和流动的预测能力,这提出了一个基本问题:人类行为在多大程度上是可预测的?在这里,我们通过研究匿名手机用户的移动模式,探索人类动态中可预测性的局限性。通过测量每个个体轨迹的熵,我们发现整个用户群的用户移动性有93%的潜在可预测性。


下面这张图清楚的反映了这三种熵值的区别:随机熵代表用户访问这些地点的概率是相等的;时间无关熵则没有考虑访问这些地点的时间顺序,仅考虑访问这些地点的频率,也就是访问这些地点的概率不同;真实熵则考虑了访问这些地点的时间顺序。
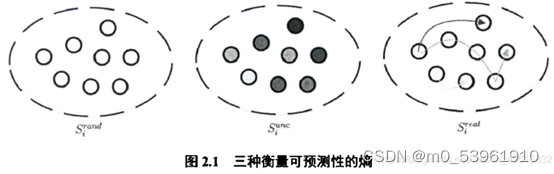
上述文章提出了三种熵值的概念,但是我们想要将它利用到流量预测等预测目标在数值上是连续变化的问题上。

(2015) 对连续时间序列的值进行分析,需要将连续时间序列的值进行量化。
1.数据预处理
节点以及边上的资源需求为连续变化的数据,将其量化为Q个级别来便于后续处理。从中选取其中n个连续变化的变量Si={ X1,X2,…,Xn},然后对其进行量化处理:
2.熵值分析
(1)随机熵:,Q为量化水平数),Mi是节点或边对应的时间变化序列Si中所含的不同量化值的个数。随机熵表示节点或边以相同的概率取得序列Si中的值。注:这里有两种表达方式,一种是
,也就是随机熵不随时间变化,是一个固定的值;第二种就是这里提到的,假如所选时间段Si中的量化值只有M(M<Q),则对应该Si的随机熵为
。
(2)时间无关熵:,
是根据节点或链路i的历史时间序列Si求出的值为j的概率,该值考虑了节点或边对应资源需求的不均匀性。时间无关熵其实就是信息熵。
(3)真实熵:,为时间序列Si'出现在序列Si中的概率。因此真实熵不仅取决于不同级别的资源需求出现的概率,还取决于资源需求出现的时序顺序。在实践中,为了从历史频谱测量中计算真实熵,使用了基于Lempel-Ziv数据压缩的估计器,该估计器可以快速收敛时间序列的真实熵。对于长度为n的时间序列,熵值计算:
, Λk从第k个时隙开始的最短子序列的长度,该子序列以前没有从时隙1到时隙k出现过。
Lempel-Ziv数据压缩example:离散序列ℰ = {43,44,43,44,44}
i=1时
t'1=43
t'1之前的序列为sequence=[ ]
序列[t'1]=[43]不在sequence序列中,那么未重复出现的最短序列为[43]
因此序列长度为Λ1 = 1
i=2时
t'2=44
t'2之前的序列为sequence=[43]
序列[t'2]=[44]不在sequence序列中,那么未重复出现的最短序列为[44]
因此序列长度为Λ2 = 1
i=3时
t'3=43
t'3之前的序列为sequence=[43, 44]
序列[t'3]=[43]在sequence序列中
因此再往后增加一个构成序列[t'3, t'4] = [43, 44]
序列[t'3, t'4]在sequence序列中
因此再往后增加一个构成序列[t'3, t'4, t'5] = [43, 44, 44],
序列[t'3, t'4, t'5]不在sequence序列中,那么未重复出现的最短序列为[43, 44, 44]
因此序列长度为Λ3 = 3
i=4时
t'4=44
t'4之前的序列为sequence=[43, 44, 43]
序列[t'4]=[44]在sequence序列中
因此再往后增加一个构成序列[t'4, t'5] = [44, 44]
序列[t'4, t'5]不在sequence序列中,那么未重复出现的最短序列为[44, 44]
因此序列长度为Λ4 = 2
i=5时
t'5=44
t'5之前的序列为sequence=[43, 44, 43, 44]
序列[t'5]=[44]在sequence序列中
t'5之后再无元素,因此找不到这样的序列
那么Λi= 𝑛 − 𝑖 + 2 作为序列长度,因此Λ5=5-5+2=2
3.可预见性分析
熵值表示时间序列中量化后的资源需求出现的不确定性。当熵值为0时,说明资源需求不存在任何不确定性,下一时刻的资源需求由历史资源需求时间序列决定。在这种情况下,可预见性,可以准确描述下一时刻对应的资源量化水平的可能性。
对于任何序列。熵值越大说明序列中的数值越是随机。当序列中的数值以相同的概率出现时,对应的随机熵为这三种熵值中最大的。
,说明序列中数值的变化是完全规律的,可以被准确预测;
,说明序列中数值的变化遵循一个相当随机的模式,因此我们无法以超过1/Q的精度对其进行预测。因此,可以利用Fano不等式建立熵值和可预见性之间的关系。
(1)可预见性上界
根据这种关系,对于每个节点或边,通过给定Q和的数值计算,我们可以得到可预测性的上界
。
(2)可预见性下界
4.实验代码
对数据进行归一化和Q级量化,这里Q=10
def quantize_data(train_data, Q):
sc = MinMaxScaler()
'''Q level并向下取整'''
train_data = Q * (sc.fit_transform(train_data))
# print(train_data[0:1, :]) #[[0.23848355 0.41008046 0.14991555 6.49276005 2.93099027 2.35357819 2.61941976 2.86433143 3.1837211 2.79195728]]
# print(np.floor(train_data[0:1, :])) #[[0. 0. 0. 6. 2. 2. 2. 2. 3. 2.]]
return np.floor(train_data)(1)随机熵,这里偷一个懒,给出随机熵的简单形式
'''train_data的随机熵log2Q'''
E_rand = math.log2(Q)
print("随机熵:", E_rand)(2)时间无关熵,也就是信息熵,
'''计算train_data的时间无关熵'''
def E_unc(DataList):
'''
计算随机变量的时间无关熵
'''
array = []
counts = len(DataList) # 总数量806
counter = Counter(DataList) # 每个变量出现的次数
# print(counter)
prob = {i[0]: i[1] / counts for i in counter.items()} # 计算每个变量的概率p
H = - sum([i[1] * math.log2(i[1]) for i in prob.items()]) # 计算熵p*log(p)
return H(3)真实熵,
'''真实熵'''
def contains(small, big):
for i in range(len(big) - len(small) + 1):
if big[i:i + len(small)] == small:
return True
return False
def E_actual(DataList):
n = len(DataList)
sequence = []
sum_A = 0
for i in range(0, n):
for j in range(i + 1, n + 1):
s = DataList[i:j]
if not contains(list(s), sequence): # s is not contained in previous sequence
# print(f'i={i + 1}, s:{list(s)}, Λ{i + 1}={len(list(s))}, 序列:{sequence}')
sum_A += len(s) # sum_Λ
sequence.append(DataList[i])
break
else:
if j == n:
# print(f'i={i + 1}, s:不存在这个序列, Λ{i + 1}={n - (i + 1) + 2}, 序列:{sequence}')
sum_A += n - (i + 1) + 2
sequence.append(DataList[i])
ae = 1 / (sum_A / n) * math.log(n)
return ae结果展示,这里由于我是对我的数据集进行的处理,数据集中主要包括不同的节点,为了有效对这些节点的值进行同时展示,因此对输出结果进行了拼接处理(注:这里的各种熵值是针对数据序列Si={ X1,X2,…,Xn}进行处理的,最终输出为一个值,图中所示结果为16个独立的熵值拼接起来的结果)。最终的结果展示如下:


















 3944
3944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









