






LeNet
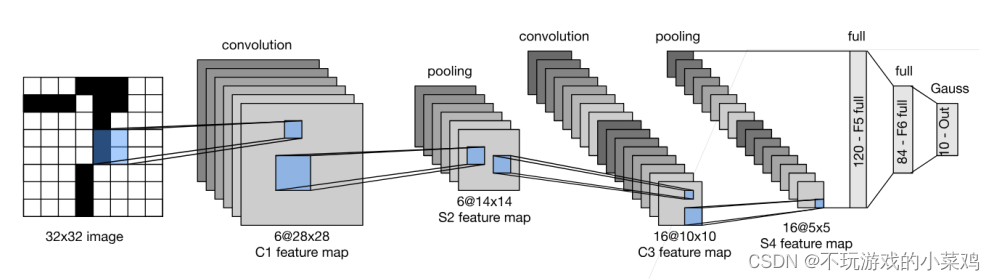
- LeNet是早期成功的神经网络
- 先使用卷积层来学习图片空间信息
- 然后使用全连接层来转换到类别空间
最早的 LeNet 有 7 层网络,包括 3 个卷积层, 2 个池化层,
2 个全连接层,其中输入图像的尺寸是 32x32。
C1 层为卷积层,有 6 个 5*5 的卷积核,原始图像送入卷积层,因此生成了
6 个(32-5+1) x(32-5+1) =28x28 的 feature map, 这一层需要训练的参数为
(5x5+1) x6=156 个参数,其中 5x5 是卷积核尺寸, 1 是偏置参数, 所以对应 6
个 28x28 feature map,连接数为 6x26x28x28=122304;
S2 层为池化层,所用到的是 2x2 最大池化来进行降维,得到 6 个 14x14 的feature map, 池化的过程是通过将每四个输入相加乘以一个系数再加上一个偏置参数,因此 S2 层所需要训练的参数为 2x6=12 个,连接数为(4+1)x6x14x14=5880;之后通过 Sigmoid 函数激活,送入下一层;
C3 层是卷积层,有 16 个卷积核,每一个卷积模板是 5x5,每一个模板有 6个通道,但是这一层并不是全连接,而是与输入层部分连接,以 feature map0为例,用到的是 3 通道的 5x5 卷积核分别与上一层的 feature map 0,1,2 连接,得到的新的 feature map 大小为(14-5+1) x(14-5+1) =10x10,因此输出为 16个 10x10 的 feature map, 所需要训练的参数为(25x3+1) x6+(25x4+1) x9+
(25x6+1) =1516 个参数;连接数为 1516x10x10=151600;
S4 层为池化层,与 S2 层相同, 2x2 最大池化,得到了 16 个 5x5 的 feature map, 送入 Sigmoid 激活函数送入下一层;需要的参数是 2x16=32,连接数为(4+1) x16x5x5=2000;
C5 层为卷积层,有 120 个卷积核,每一个卷积模板是 5x5,每一个模板有
16 个通道,得到 120 个 1x1 feature map; 训练参数为 120x(5x5x16+1)=48120,连接数为 48120;
F6 层为全连接层,有 84 个神经元,与上一层 120 个 1x1feature map 全连接,得到 84 维特征向量;连接数为 120x84=10080;最后利用 84 维特征向量进行分类预测;
O7 层为输出层, 每一个类有一个RBF(Euclidean Radial Basis)功能单元,每个单元有 84 个输入,输出 yi 按照如下公式计算
也就是计算输入向量与参数向量之间的欧式距离。
AlexNet
做特征提取
- 在LeNet提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气,但卷积神经网络并没有主导这些领域,因为虽然LeNet在小数据集上取得了很好的效果,但是在更大、更真实的数据集上训练卷积神经网络的性能和可行性还有待研究
- 引起这一个深度学习热潮的第一个网络
- AlexNet诞生于2012年,与另一种观察图像特征的提取方法不同,它认为特征本身应该被学习,在合理的复杂性前提下,特征应该由多个共同学习的神经网络层组成,每个层都有可学习的参数。在机器视觉中,最底层可能检测边缘、颜色和纹理;更高层建立在底层表示的基础上,以表示更大的特征,更高层可以检测整个物体;最终的隐藏神经元可以学习图像的综合表示,从而使不同类别的数据易于区分
深度学习之前的网络
AlexNet P1 - 00:33
- 事实上,在上世纪90年代初到2012年之间的大部分时间里,神经网络往往被其他机器学习方法超越,如支持向量机(support vector machines)
- 传统机器学习方法中,机器视觉流水线是由经过人的手工精心设计的特征流水线组成的;在神经网络中,卷积神经网路的输入是由原始像素值或者是经过简单预处理(例如居中、缩放)的像素值组成的
- 2000年的时候,最火的机器学习的方法其实是核方法

- 这张图中展示的是2000年初期最主要使用的方法
- 核心是:提取特征、选择核函数来计算相关性(如何判断两个点在高维空间上是相关的,如果是线性的话可以做内积,用核方法的话可以通过变换空间,将空间变换成想要的样子)、凸优化问题(通过和函数计算之后就会变成一个凸优化问题,线性模型型是一个凸优化问题,所以它有很好的理论解,可以将显式解写出来)、漂亮的定理(因为是凸优化,所以有比较好的定理)
- 整个核方法最大的特色就是有一个完整的数学定理,能够计算模型的复杂度等,这也是为什么在2000年的时候核方法能够替代深度学习(当时叫神经网络)成为当时机器学习主流的网络
在2000年左右机器学习主要关心的是几何
AlexNet P1 - 03:11
十几年前,在计算机视觉中最重要的其实是特征工程
- 在2012年之前,图像特征都是机械地手动计算出来的,例如常见的特征函数:SIFT、SURF、HOG(定向梯度直方图)和类似的特征提取方法
AlexNet P1 - 05:40

- 整个计算机视觉在深度学习之前其实不那么关心机器学习的模型长什么样子,关键是如何做特征提取,怎样抽取特征使得机器学习能够比较好地学习特征
神经卷积网络取得突破的两大关键因素
1、硬件
- 深度学习对计算资源要求很高,训练可能需要数百个迭代轮数,每次迭代都需要通过代价高昂的许多线性代数层传递数据。这也是为什么在20世纪90年代至21世纪初,优化凸目标的简单算法是研究人员的首选。
- 虽然上世纪90年代就有了一些神经网络加速卡,但仅靠它们还不足以开发出有大量参数的深层多通道多层卷积神经网络。此外,当时的数据集仍然相对较小。除了这些障碍,训练神经网络的一些关键技巧仍然缺失,包括启发式参数初始化、随机梯度下降的变体、非挤压激活函数和有效的正则化技术。
- AlexNet使用了两个显存为3GB的NVIDIA GTX580 GPU实现了快速卷积运算
AlexNet P1 - 07:13

- 图中三行分别是:样本个数、内存大小、CPU计算能力
- 计算能力和数据所要的算法能力的发展的不同阶段导致对网络选取的偏好差异
2、数据
- 深度学习的再次崛起离不开数据
- 包含许多特征的深度模型需要大量的有标签数据,才能显著优于基于凸优化的传统方法(如线性方法和核方法)
- ImageNet数据集由斯坦福教授李飞飞小组的研究人员开发,利用谷歌图像搜索(Google Image Search)对每一类图像进行预筛选,并利用亚马逊众包(Amazon Mechanical Turk)来标注每张图片的相关类别。这种规模是前所未有的
ImageNet数据集
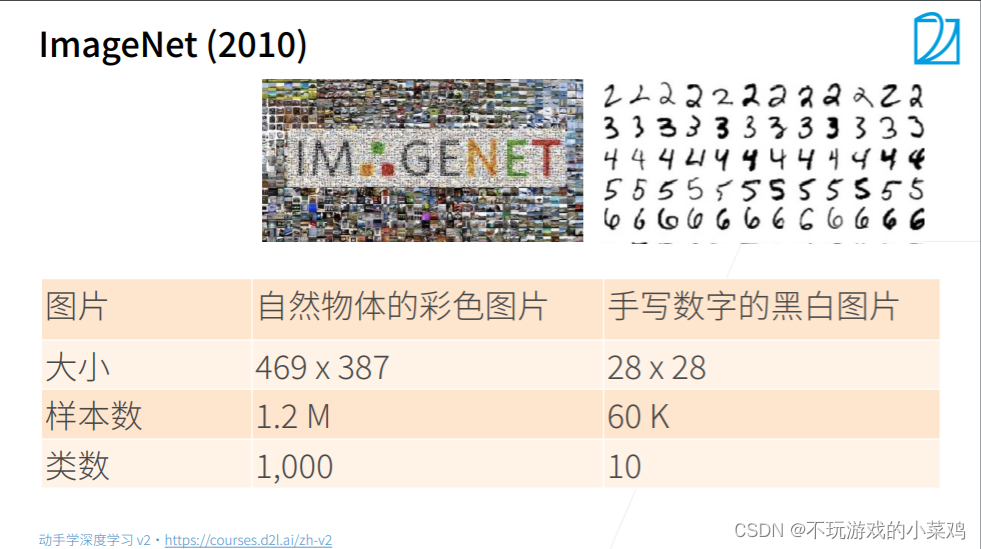
- 上图是ImageNet数据集和MNIST数据集的对比
AlexNet
- 2012年拿到了ImageNet竞赛2012年的冠军
- Alex本质上是一个更深、更大的LeNet,二者在架构上没有本质的区别,主要的改进在于:1、加入了丢弃法;2、激活函数从sigmoid改成了ReLu;3、池化操作从Avgpooling改成了MaxPooling
- 丢弃法可以认为是用来做模型控制,因为模型更大了,所以可以使用丢弃法来做正则
- ReLu和sigmoid相比,它的梯度确实更大,而且ReLu在零点处的一阶导更好,能够支撑更深的模型
- MaxPooling取的是最大值,使得输出比较大,梯度也比较大,从而使得训练而更加容易
- AlexNet不仅仅是更大、更深,更加关键的是观念上的改变:LeNet仅仅被认为只是一个机器学习的模型,但是AlexNet增加了几十倍,量变引起质变,引起了计算机视觉方法论的改变,原本机器学习的专家对于问题的理解主要放在对特征的人工提取上

- 上图左边主要关注点在于SVM需要怎样的特征,右边是一个一起训练的过程(最后的分类器和特征提取的模型是一起训练的,也就意味着CNN学出来的东西很有可能就是softmax所想要的,通过很深的神经网络将原始的像素转换到一个空间当中,使得softmax能够更好地进行分类)
- 这样做的好处是:1、构造CNN相对来说比较简单,而不需要了解太多计算机视觉相关的知识,而且比较容易跨问题、跨学科;2、因为分类器和特征提取的模型是一起训练的,从模型角度来讲,其实就是一个,这样做更加高效
- 深度学习对之前传统的机器学习的主要改变:不在执着于怎样进行人工提取特征,而是端到端的学习过程,使得原始的信息到最后的分类或者预测可以直接通过深度神经网络实现
AlexNet和LeNet的对比
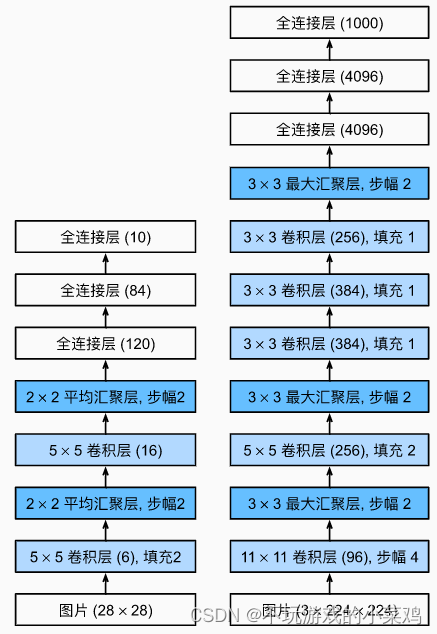
- 左图表示LeNet,右图表示AlexNet
AlexNet



- AlexNet其实就是一个更大、更深的LeNet,由八层组成:5个卷积层、2个全连接隐藏层和一个全连接输出层
- AlexNet的输入是224*224*3的3通道RGB图片,LeNet的输入是32*32*1的单通道灰度图片
- 第一层:AlexNet使用了更大的核窗口(因为图片更大了,需要用更大的卷积窗口来捕获目标),通道数也更多了,从6变成了96(希望能够在第一层识别更多的模式,所以用了比较大的通道数),stride从2变成了4(这是由于当时GPU性能的限制,如果stride比较小的话,计算就会变得非常困难)
- 第二层:AlexNet使用了更大的池化层,stride都是2,因为LeNet的池化层窗口大小也是2,所以它每次看到的内容是不重叠的。2*2和3*3的主要区别是:2*2允许一个像素往一边平移一点而不影响输出,3*3的话就允许一个像素左移或者右移都不影响输出;stride都等于2使得输出的高和宽都减半
- 第三层:AlexNet有一个padding为2的操作,它的作用就是使得输入和输出的大小是一样的;AlexNet的输出通道是256,使用了更多的输出通道来识别更多的模式
- ALexNet新加了3个卷积层
- AlexNet的全连接层也用了两个隐藏层,但是隐藏层更大(在最后一个卷积层后有两个全连接层,分别有4096个输出。 这两个巨大的全连接层拥有将近1GB的模型参数。 由于早期GPU显存有限,原版的AlexNet采用了双数据流设计,使得每个GPU只负责存储和计算模型的一半参数)
- Alex的激活函数从sigmoid变成了ReLu:1、ReLU激活函数的计算更简单,它不需要sigmoid激活函数那般复杂的求幂运算;2、当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易;3、、当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数,相反,ReLU激活函数在正区间的梯度总是1。 因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
- LeNet只使用了权重衰减,而AlexNet在全连接层的两个隐藏层之后加入了丢弃层(dropout、暂退法),来做模型的正则化,控制全连接层的模型复杂度
- 为了进一步扩充数据,AlexNet还做了数据的增强:对样本图片进行随机截取、随机调节亮度、随即调节色温(因为卷积对位置、光照等比较敏感,所以在输入图片中增加大量的变种,来模拟预测物体形状或者颜色的变化;因为神经网络能够记住所有的数据,通过这种变换之后来降低神经网络的这种能力,因为每次变换之后的物体都是不一样的)
- 池化出来的维度和卷积核算法一样((n-f+2p)/s)+1;n为输入维度,f为核维度,p为填充值,s为步幅,可以参考吴恩达的理论课
AlexNet和LeNet模型的复杂度对比
AlexNet P1 - 30:49
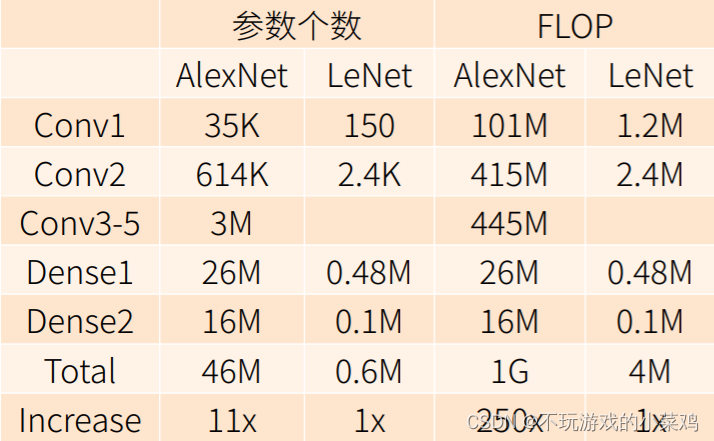
- AlexNet使用了7*7的卷积核,而且通道数增加了,所以参数个数增加的比较多
- AlexNet在可学习的参数个数上比LeNet多十倍左右
- FLOP:每秒所执行的浮点运算次数(floating-point operations per second)
总结
- AlexNet是更大更深的LeNet,但是整个架构是一样的,AlexNet的参数个数比LeNet多了10倍,计算复杂度多了260倍
- AlexNet新加入了一些小技巧使得训练更加容易:丢弃法(dropout)、ReLu、最大池化层、数据增强
- AlexNet首次证明了学习到的特征可以超越手工设计的特征,以很大的优势赢下了2012年的ImageNet竞赛之后,标志着新一轮的神经网络热潮的开始
- 尽管今天AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步
- Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤
VGG
- Alexnet虽然证明了深层神经网络是有效果的,但是它最大的问题是模型不规则,结构不是很清晰,没有提供一个通用的模板来指导后续的研究人员设计新的网络。如果模型想要变得更大、更深,则需要很好的设计思想,使得整个框架更加规则
如何使模型更深更大:
- 更多的全连接层(缺点是全连接层很大的话会占用很多的内存)
- 更多的卷积层(AlexNet是先将LeNet的模型给扩大之后,再加了三个卷积层,不好实现对模型进一步的加大、加深;VGG的思想是先将卷积层组成小块,然后再将卷积层进行堆叠)
- 将卷积层组合成块(VGG提出了VGG块的概念,其实就是AlexNet思路的拓展:AlexNet中是三个一模一样的卷积层(3*3,384通道,padding等于1)加上一个池化层(3*3,最大池化层,stride=2)组成了一个小块:VGG块是在此基础上的拓展,它并不限制块中卷积层的层数和通道数),最大池化层重新用回了LeNet中的最大池化层窗口(2*2,最大池化层,stride=2)
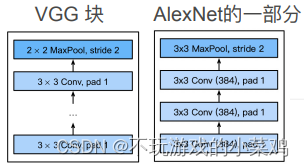
VGG的核心思想是使用大量由一定数目的3*3的卷积层和一个最大池化层组成的VGG块进行堆叠,最终得到最后的网络
- 为什么使用的卷积层是3*3,而不是5*5?5*5的卷积层也用过,但是5*5的卷积层的计算量更大,所以层数就不会太大,VGG块就会变得浅一点,最终通过对比发现,在同样的计算开销之下,大量的3*3的卷积层堆叠起来比少量的5*5的卷积层堆叠起来的效果更好,也就是说模型更深、卷积窗口更小的情况下,效果会更好一点
- VGG块由两部分组成:多个填充为1的3*3卷积层(它有两个超参数:层数n、通道数m)和一个步幅为2的2*2最大池化层
经典卷积神经网络的基本组成部分:
- 带填充的卷积层(用填充来保持分辨率)
- 非线性激活函数(如ReLu)
- 汇聚层(如最大汇聚层)
VGG基本组成部分:
- 带有3*3的卷积核、填充为1(为了保持宽度和高度)的卷积层
- 带有2*2汇聚窗口、步幅为2(每个块后的分辨率减半)的最大汇聚层
VGG架构
- 其实就是使用多个VGG块进行堆叠来替换掉AlexNet中的卷积部分

- VGG块重复的次数不同可以得到不同的架构,比如VGG-16、VGG-19,···
- 最后还是使用了两个4096的全连接层得到输出
- VGG对AlexNet最大的改进是:将AlexNet在LeNet的基础上新加的卷积层抽象出了VGG块,替换掉了AlexNet中原先并不规则的部分
- 类似于AlexNet、LeNet,VGG网络也可以分成两部分:第一部分主要由卷积层和汇聚层组成,第二部分由全连接层组成。从AlexNet到VGG,本质上都是块设计

- 原始的VGG网络有5个块,前2个块各有一个卷积层,后3个块个包含两个卷积层;第一个模块有64个输出通道,每个后续模块将输出通道的数量翻倍,直到达到512,由于该网络使用了8个卷积层和三个全连接层,因此通常被称为VGG-11(这里为什么是5块?因为原始输入图像的大小是224,每经过一个VGG块,输出的通道数会翻倍、高宽会减半,当减到第五次时输出的高宽为7,就不能再经过VGG块进行减半了)
发展
LeNet(1995)
- 由2个卷积层+池化层和2个全连接层组成
AlexNet(2012)
- 比LeNet更大更深
- 加入了ReLu、Dropout、数据增强
VGG
- 实际上就是一个更大更深的AlexNet
GluonCV Model Zoo
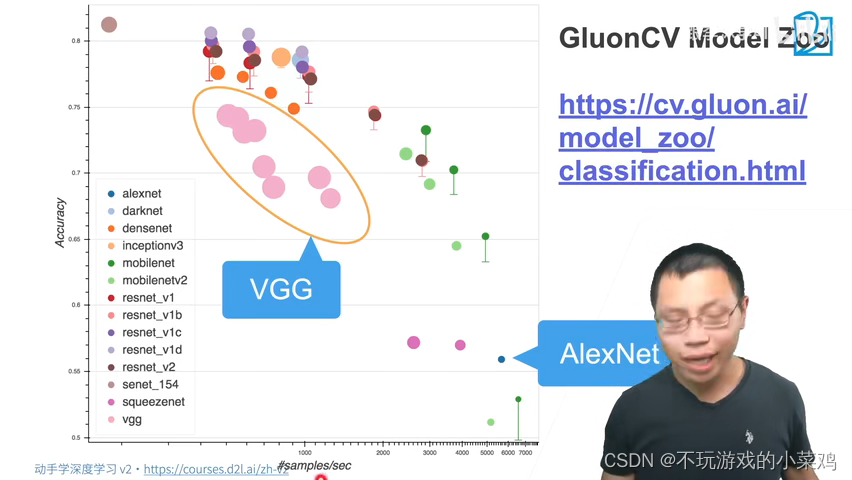
- X轴表示不同的模型每秒钟所做的推断(Inference)的个数,越往右表示越快
- Y轴表示模型在ImageNet上的准确率(Accuracy),越往上表示准确率越高
- AlexNet很快,但是精度并不是很高
- VGG相比于AlexNet来说提升较大,但是代价就是牺牲速度来换取模型深度的增加,速度大概是AlexNet的1/6到1/5左右
- 图中圆圈的大小表示内存的使用,圆圈越大表示所占用的内存就越多,可以看到,VGG所占用的内存较大
- 因为VGG中可以选择不同的VGG块的个数,所以就产生了一系列的VGG模型,模型越小精度越低但速度越快,模型越大精度越高但速度越慢
- VGG模型虽然相比于AlexNet来说速度较慢,但是随着硬件的提升,二者的在速度上的差距会越来越小
总结
- VGG使用可重复使用的卷积块来构建深度卷积神经网络(将ALexNet中不规则的部分抽象出来做成了VGG块,它是一种可复用的卷积块)
- 通过配置不同的卷积块个数和通道数可以得到不同复杂度的变种(不同的VGG模型可以通过每个块中卷积层数量和输出通道数量的差异来定义)
- 这个思想在之后被大量使用:1、使用可重复的块来构建深度神经网络;2、网络产生不同的配置
- 块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
- 深层且窄的卷积(3×3)比浅层且宽的卷积更有效
NiN
- 这个网络现在用的不多,但是它所提出的很多重要的概念在之后的很多网络中都会被用到
LeNet、AlexNet和VGG
- LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与汇聚层来提取空间结构特征,然后通过全连接层对特征的表征进行处理
- AlexNet和VGG对LeNet的改进主要在于如何扩大和加深卷积层和汇聚层这两个模块
全连接层的问题
- 在AlexNet和VGG的最后面都使用了两个比较大的全连接层,最后再通过一个全连接层作为输出(全连接层比较占用网络参数空间,整个网络的绝大多数参数都集中在全连接层)
- 最重要的问题是会带来过拟合
- 假设使用卷积层的话,参数的个数等于输入的通道数(Ci) * 输出的通道数(Co) * 卷积窗口的高度(k) * 卷积窗口的宽度(k),但是如果使用全连接层的话,它的参数个数就等于整个输入的像素(也就是输入通道数) * 输入的高 * 输入的宽 * 输出中所有的像素(也就是输出通道数)
- 在卷积层的最后一层的输出并没有变成 1 * 1,很多情况下就是 7 * 7,这样的话其实对于全连接层来说输入的像素还是比较多的
- 另外,如果使用全连接层,可能会完全放弃表征的空间结构

- LeNet中16是最后一个卷积层的输出通道数,5 * 5表示经过卷积操作之后最终输出压缩成了5 * 5的大小,120是输出的隐藏层的大小(下一个全连接层的输入通道数)
- AlexNet中最后一个卷积层的输出通道数是256
- VGG最后一个卷积层的输出通道数变成了512,经过多次卷积操作之后最终输出的大小也只压缩到了7 * 7,因此它所占用的内存量确实是比较大的,差不多占用700M左右,其中绝大部分参数都集中在卷积层之后的第一个全连接层
大量的参数会带来很多问题
- 占用大量的内存
- 占用很多的计算带宽(一个很大的矩阵乘法根本不是受限于计算,而是几乎是受限于不断访问内存所带来的限制)
- 很容易过拟合(某一层的参数过多很容易导致模型收敛特别快,反过来讲,就需要使用大量的正则化避免该层学到所有的东西)
NiN
为了解决这些问题,就提出了NiN
- NiN的思想是完全不要全连接层(比如2021年由谷歌提出的MLP-Mixer,提出MLP又能够替代CNN了,但是实际上它和NiN是一个东西,只是NiN认为全连接层不是很好,所以就用卷积层来替代全连接层,不要全连接层;而MLP-Mixer认为卷积层不行,还是得用全连接层,所以实际上是一个东西),在每个像素的通道上分别使用多层感知机,也就是在每个像素位置(针对每个高度和宽度)应用一个全连接层。这样将权重连接到了每个空间位置,可以将其视为1 * 1的卷积层,或者看作在每个像素位置上独立作用的全连接层,从另一个角度讲,就是将空间维度中的每个像素视为单个样本,将通道维度视为不同特征
NiN
NiN中最重要的概念叫做NiN块(VGG之后的网络基本上都有自己局部的卷积神经网络架构,也就是块状结构)
NiN块的结构如下图所示

- 回顾:卷积层的输入和输出由四维张量组成,张量的每个轴分别对应样本、通道、高度和宽度;全连接层的输入和输出通常是分别对应于样本和特征的二维张量
- NiN块由一个卷积层和两个全连接层(实际上是窗口大小为1 * 1、步幅为1、无填充的卷积层)组成(因为1 * 1的卷积层等价于全连接层,所以这里使用的是1 * 1的卷积层;步幅为1,无填充,所以卷积层输出的形状和输入的形状是一样的,也就是不会改变输入的形状,同时也不会改变通道数)
- NiN块中两个1 * 1的卷积层其实是起到了全连接层的作用,这两个卷积层充当了带有ReLu激活函数的逐像素全连接层
- 1 * 1的卷积运算如下图所示
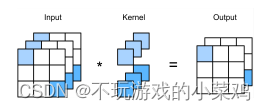
- NiN块可以认为是一个简单的神经网络:一个卷积层+两个全连接层。唯一的不同是这里的全连接层是对每一个像素做全连接,对于每个输入的每个像素的权重都是一样的,不会根据输入的具体情况发生变化,所以可以认为是按照输入的每个像素逐一做全连接
NiN架构
- 没有全连接层
- 交替使用NiN块和步幅为2的最大池化层(最大池化层的作用的就是高宽减半),逐步减小高宽(输出的尺寸)和增大通道数
- 最后使用全局平均池化层得到输出(全局平均池化层:该池化层的高宽等于输入的高宽,等价于对每一个通道取平均值(这里应该是取平均值吧,视频中沐神说的是最大值,应该是口误吧),作为这个类别的预测,再通过softmax就能得到每个类别的概率了),其输入通道数是标签类别数,最后不需要使用全连接层,也是一个比较极端的设计
VGG net 和 NiN net
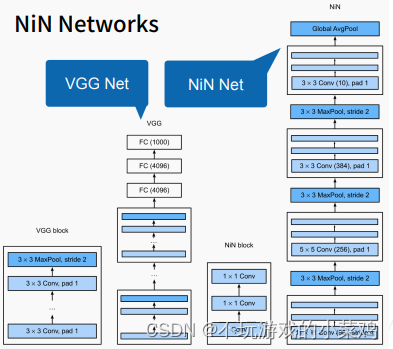
- VGG块由多个卷积层和一个最大池化层组成;NiN块由一个卷积层和两个当做全连接层用的1 * 1的卷积层
- VGG网络由四个VGG块和两个大的全连接层,最后通过一个输出通道数为1000的全连接层得到1000类
- NiN网络由一个NiN块和一个步幅为2、3 * 3的最大池化层不断重复,如果将最后重复部分的NiN块的通道数设置为标签类别的数量的话,则最后就可以用全局平均池化层(global average pooling layer)代替全连接层来得到输出(一个对数几率(logits)),也就是对每个类的预测(这里说NiN网络是由一个NiN块和一个最大池化层不断重复堆叠组成的,为什么上图中NiN网络里每个最大池化层都是一样的,而每个NiN块都长得不一样?NiN块中第一层的卷积窗口形状通常是由用户设置,随后的卷积窗口形状固定为1 * 1,这里应该是受到AlexNet的启发,使用了窗口形状为11 * 11、5 * 5、3 * 3的卷积层,输出通道数与AlexNet中相同)
- 第一个NiN块的第一个卷积层的步幅为什么是4?通过长为4的步幅的卷积操作使得输出的尺寸大幅度减小
- NiN完全取消了全连接层,这样做的好处是减少了模型所需参数的数量,但是在实践中,这种设计有时会增加模型的训练时间
总结
- NiN的核心思想是NiN块,NiN块是一个卷积层加上两个1 * 1的卷积层作为全连接层来使用(也就是说对每个像素增加了非线性,或者说对每个像素的通道数做了全连接层,而且是非线性的,因为有两层)
- NiN使用全局平均池化层(通道数量为所需的输出数量)来替代VGG和AlexNet中的全连接层(全局全连接层因为比较大,所以也不需要学一个比较大的全连接层),这样做的好处是不容易过拟合,显著减少网络参数的数量
- 整体来讲,NiN的架构比较简单,就是NiN块和最大池化层的重复堆叠,直到最后的全局平均池化层,因为完全放弃了全连接层,所以它的参数个数大大减少了,使得参数的总量与类别数的多少无关
- NiN的设计影响了许多后续卷积神经网络的设计















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









