







一.使用mini_batch
1.为什么使用mini_batch可以加速神经网络的收敛
使用mini-batch能够提高神经网络的训练速度,原因主要包括以下几点:
(1)并行化计算:GPU,擅长并行处理多个计算任务。mini_batch允许同时处理多个样本,从而利用这种并行性来加速计算。
(2)减少梯度计算的延迟:与全批量(batch)梯度下降相比,mini_batch只需要对一小部分数据进行梯度计算,因此每个步骤的计算速度更快,减少了每次更新参数所需的时间。
(3)内存效率更高:相比于处理整个数据集或大批次数据,mini_batch只需要将一小部分数据加载到内存中,这样可以更有效地利用有限的内存资源,尤其是在处理大型数据集时。
(4)减少数据之间的通信:对于处理大批此数据,隐藏单元层必须时刻注意着上一层的单元层是否处理完数据,完成数据同步,这个过程中通信次数多,对于mini_batch每一层的隐藏单元层都在独立处理其分配的数据批次。
(5)更好的泛化能力:mini_batch有助于模型更好地泛化,因为mini_batch算法第一步便是将数据集打乱,避免了数据集中部分数据段的相似性。
(6)适应性学习率调整:在使用自适应学习率算法(如Adam、RMSprop等)时,mini-batch可以更快地适应不同参数的更新需求,因为这些算法依赖于二阶矩(如梯度的方差)的估计,而mini-batch提供了更加稳定的估计。
(7)避免冗余计算:在处理大数据集时,全批量或大批量可能会导致大量的冗余计算,因为每次迭代只更新一次权重。mini-batch可以减少这种冗余,因为它可以频繁地更新权重。
(8)减少收敛时间:由于上述所有因素的综合作用,mini-batch通常可以减少模型达到一定精度所需的总时间。
2.mini_batch_size的取值
m为数据集样本数
mini_batch_size=1—stochastic grandient descent(随机梯度下降)—、噪声多,最后会在最优点处“徘徊”
mini_batch_size=m—batch gradient descent(批量梯度下降)-----步子很大,不够精细
mini_batch_size=between(1,m) —mini_batch gradient descent
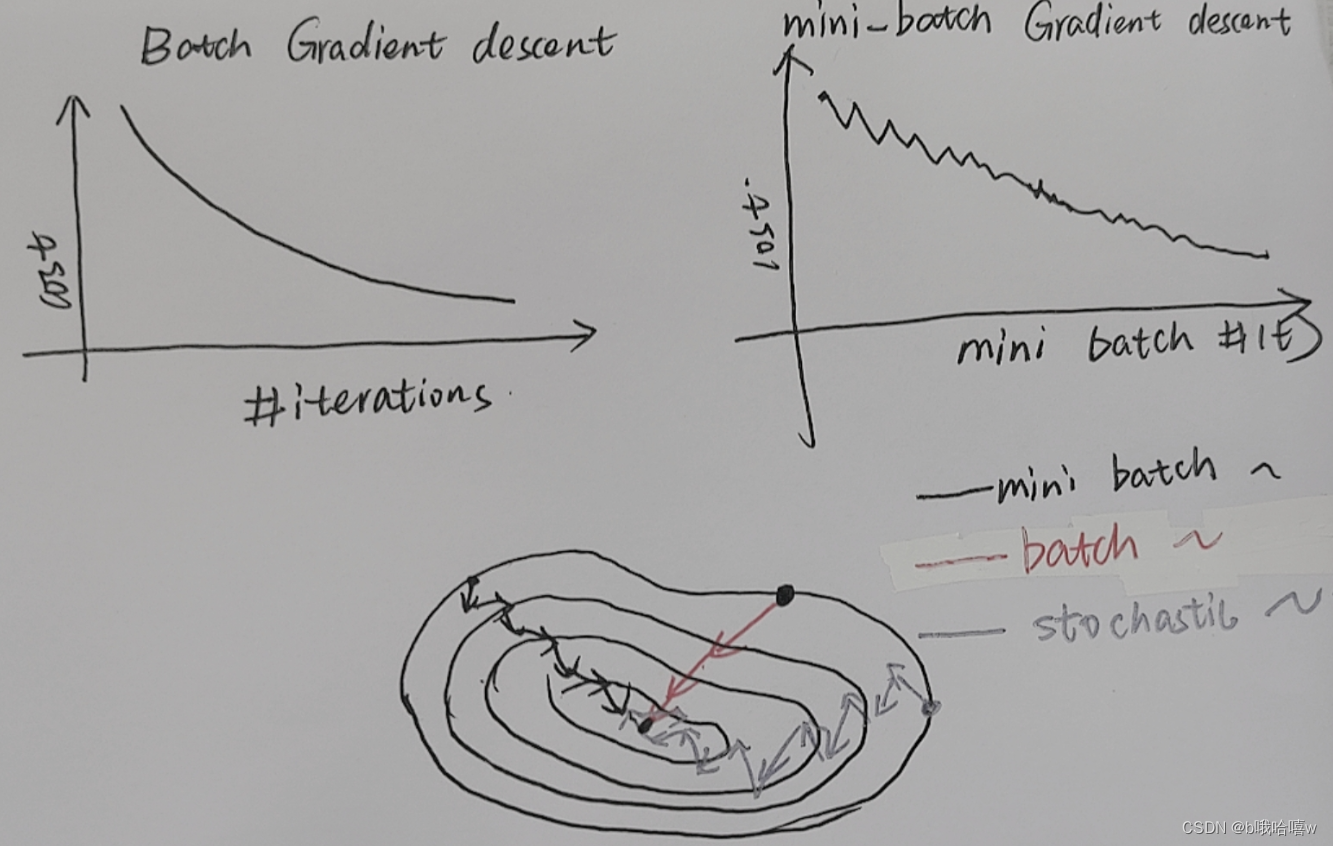
tips:
-
若训练集(m<=200)过小,可以使用SGD
-
一般mini_batch_size=32,64,128,(考虑到计算机的布局和计算方式,size的取值一般为2的指数)
-
保证每一个batch都可以放入GPU中
3.使用步骤
3.1.打乱顺序
因为数据集中会有连续类似的数据段,打乱数据集能够提高模型的泛化能力以及训练数据的随机性。
利用np.random.permutation()函数来对数据集进行打乱。np.random.permutation()函数会返回一个新数组,不会改变原始数据,有利于保护数据的完整性。
m=X.shape[1]
# permutation是原数组索引号构成的list
permutation=np.random.permutation(m)
shuffled_X=X[:,permutation]
shuffled_Y=Y[:,permutation].reshape((1,m))
print(shuffled_X)
3.2.切分
# 2.切分数据集
mini_batches=[]
# 2.1对于整出部分数据的处理
for i in range(n):
mini_batch_x=shuffled_X[:,i*mini_batch_size:(i+1)*mini_batch_size]
mini_batch_y=shuffled_Y[:,i*mini_batch_size:(i+1)*mini_batch_size]
mini_batch=(mini_batch_x,mini_batch_y)
mini_batches.append(mini_batch)
# print(mini_batches)
# print(i)
#2.2对于剩下的数据额外处理---
if m%mini_batch_size!=0:
mini_batch_x=shuffled_X[:,mini_batch_size*n:]
mini_batch_y=shuffled_Y[:,mini_batch_size*n:]
mini_batch=(mini_batch_x,mini_batch_y)
mini_batches.append(mini_batch)
return mini_batches
二.使指数加权平均(指数加权滑动平均)
1.概念是什么?
用每一年的温度为例
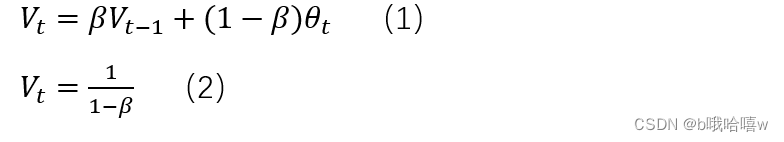
其中V_t表示前1/(1-β)天的平均气温,θ_t表示第t天的温度,公式(1)使用V_t代替θ_t来表示温度
当β=0.5时,V_t表示前2天平均的温度,如紫色线所表示,即第三天的温度是前两天温度的平均值
当β=0.9时,V_t表示前10天平均的温度,如红色线所表示,即第11天的温度是前10天温度的平均值
当β=0.98时,V_t表示前50天平均的温度如蓝色线所表示…
 如图所示,当β值越大,曲线会越平滑,波动更小,β值越小,噪声越多,更容易受到异常值的影响,但是它可以更好地适应温度变化
如图所示,当β值越大,曲线会越平滑,波动更小,β值越小,噪声越多,更容易受到异常值的影响,但是它可以更好地适应温度变化
一般β值等于0.9
2.为什么能优化
-
减少抖动,加快时间,由上一部分可以知道,当我们使用小批量算法时,代价函数是震动的。使用加权平均,可以使得曲线光滑。
-
减少历史数据对当前梯度的干扰。

由图片可以知道,时间越远,历史数据对当前数据的影响越小,这是符合自然规律的,所以,指数加权平均算法能够很好的减弱历史数据的影响。 -
减少内存开销,内存只需要存储前x个数据就行。
3.指数加权平均数偏差修正
3.1 为什么要修正偏差
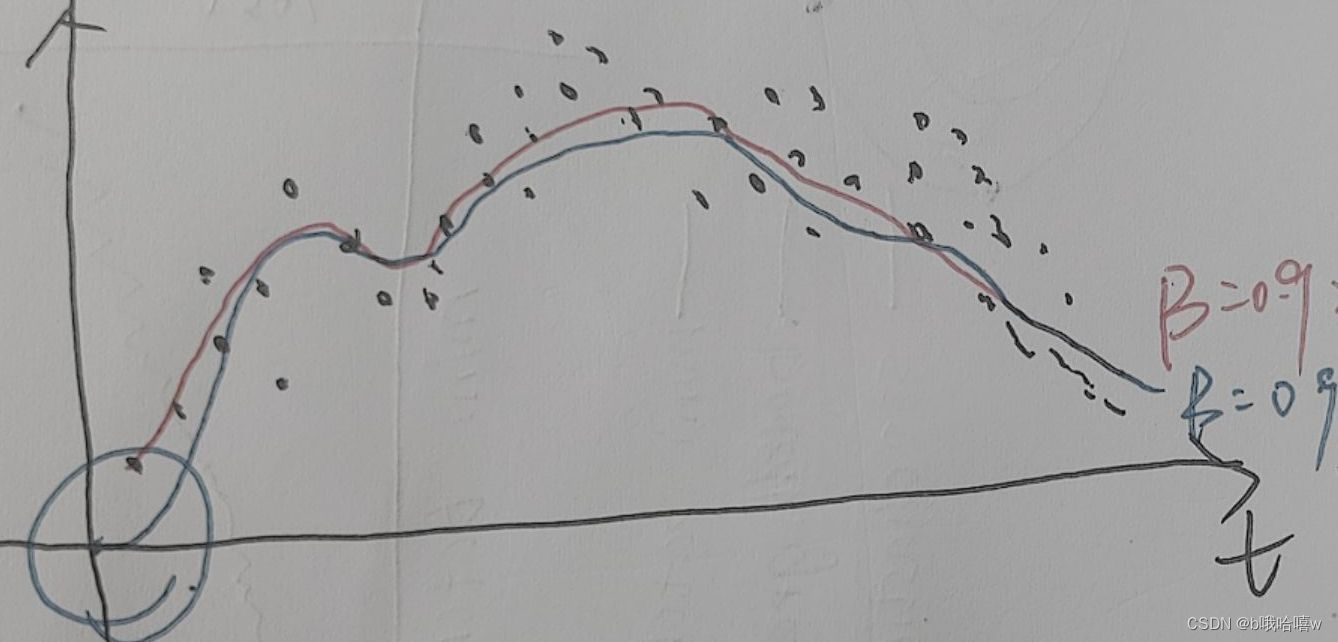 理论上会得到红色线的图像,但实际会得到像蓝色一样的线,这是由于前期缺少数据,
理论上会得到红色线的图像,但实际会得到像蓝色一样的线,这是由于前期缺少数据,
eg
当V_0=0,θ_1=40,θ_2=30
V1=0.9V_0+0.1θ_1=4
V2=6.6这显然是不符合逻辑的
3.2 具体做法
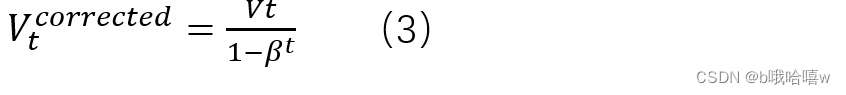
三.Momentum(动量梯度下降)
1基本概念
动量梯度下降:主要思想就是运用指数加权平均,使用这个梯度来更行权重优化代价函数,
Momentum算法主要是在梯度的更新方向上做优化,使得代价函数的曲线变得更加光滑。如下图所示。(让纵向变慢,横向变快)
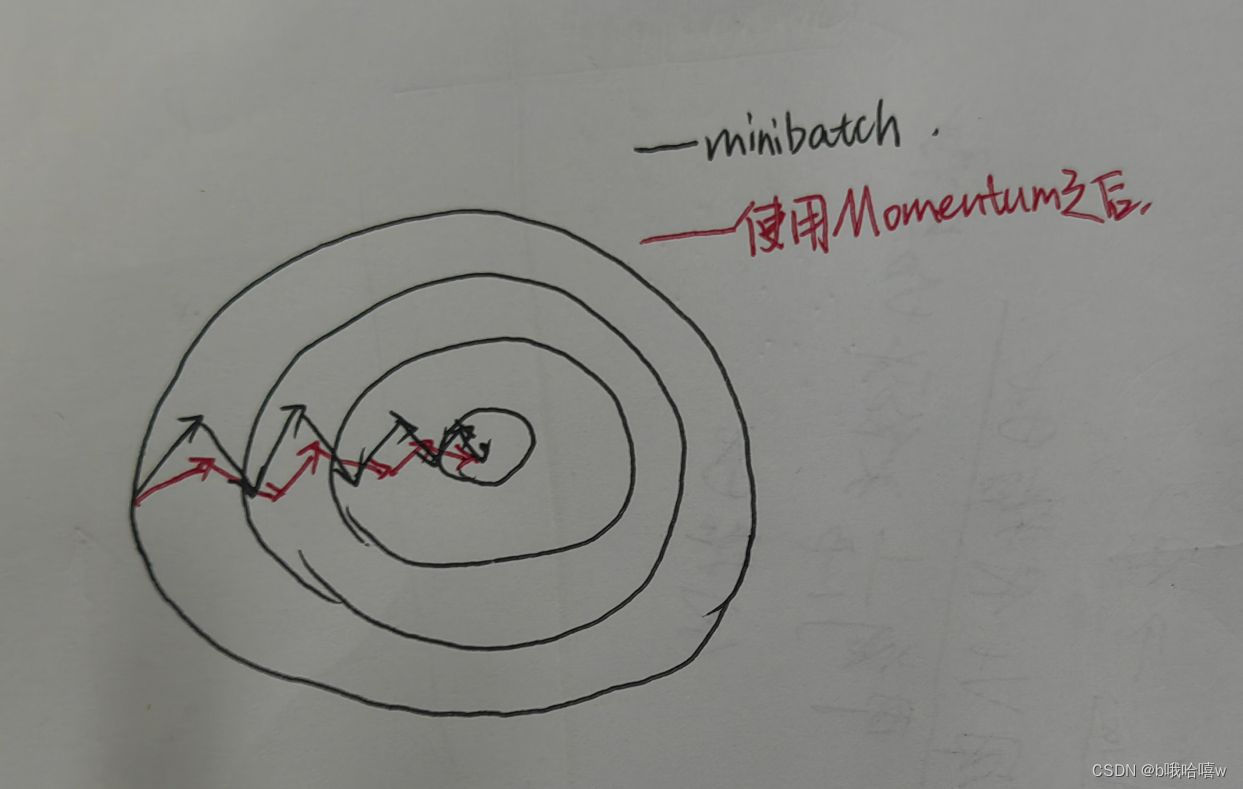
主要公式如下:
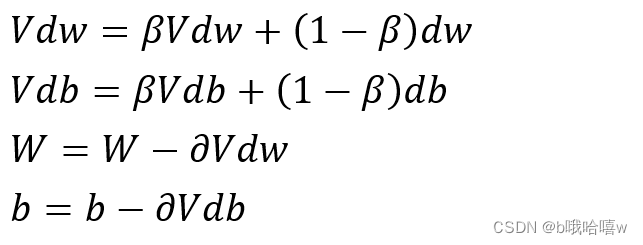
2步骤
2.1 初始化 Vdb与Vdw,用他们来代替db和dw
# 2.1 初始化 Vdb与Vdw,用他们来代替db和dw
def initialize_velocity(parameters):
'''
:param parameters: 里面包含每一层隐藏单元层的w,b
:return:
'''
V={}
L=len(parameters)//2
for i in range(L):
V["dW"+str(i+1)]=np.zeros_like(parameters["W"+str(i+1)])
V["db"+str(i+1)]=np.zeros_like(parameters["db"+str(i+1)])
return V
2.2 更新参数 Vdw,Vdb,w,b,超参数有beta,learning_rate
def update_parameters_with_momentun(parameters,grads,V,beta=0.9,learning_rate=0.01):
"""
:param parameters: 存储W1,W2...b1,b2... 的字典
:param grads: 存储dW1,dW2...db1,db2... 的字典
:param V:包含了Vdw,Vdb....的词典
:param beta:
:param learning_rate:
:return:
"""
L=len(parameters)//2
# 2.2.2 根据公式计算出Vdw,Vdb
for i in range(L):
V["dW"+str(i+1)]=beta*V["dW"+str(i+1)]+(1-beta)*grads["dW"+str(i+1)]
V["db"+str(i+1)]=beta*V["db"+str(i+1)]+(1-beta)*grads["db"+str(i+1)]
# 2.2.3 根据公式更新W,b
parameters["W"+str(i+1)]=parameters["W"+str(i+1)]-learning_rate*V["dW"+str(i+1)]
parameters["b"+str(i+1)]=parameters["b"+str(i+1)]-learning_rate*V["db"+str(i+1)]
return parameters,V
四.均方根传递法(RMSprop)
学习链接
1.基本概念
均方根传递法也是利用了指数的加权平均算法的思想,目的是为了消除纵向的抖动,加快收敛速度
Momentum算法主要是在梯度的更新方向上做优化,而RMSprop主要是从数值的大小上做优化,在数值较大的方向上进行适当的缩小不发,在较小的方向上适当的增大步伐。如图所示。

其公式如下:
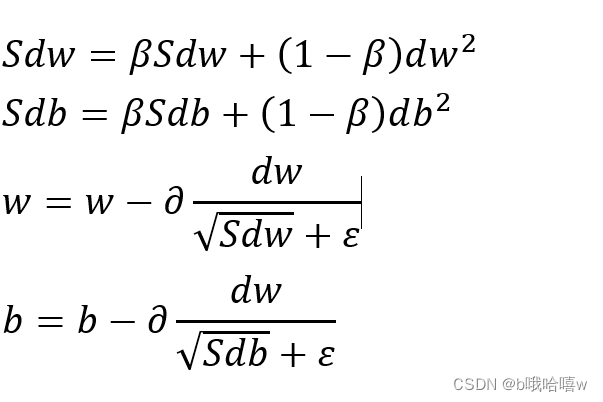
其中ε是保证数值的稳定性,防止分母为0
这里的β值常用0.999,ε常用值为10的-8次方
2.步骤
基本步骤和Momentum一致
2.1 初始化
def initialize_rmsprop(parameters):
L=len(parameters)//2
S={}
for i in range(L):
S["dW"+str(i+1)]=np.zeros_like(parameters["W"+str(i+1)])
S["db"+str(i+1)]=np.zeros_like(parameters["b"+str(i+1)])
return S
2.2 更新参数
def update_parameters_with_rmsprop(parameters,grads,S,beta=0.999,learning_rate=0.001,epsilon=1e-8):
L=len(parameters)//2
for i in range(L):
# 3.2.1得到Sdw,Sdb
S["dW"+str(i+1)]=beta*S["dW"+str(i+1)]+(1-beta)*grads["dW"+str(i+1)]*grads["dW"+str(i+1)]
S["db"+str(i+1)]=beta*S["db"+str(i+1)]+(1-beta)*grads["db"+str(i+1)]*grads["db"+str(i+1)]
# 3.2.2得到w和b
parameters["W"+str(i+1)]=parameters["W"+str(i+1)]-learning_rate*grads["dW"+str(i+1)]/(np.sqrt(S["dW"+str(i+1)])+epsilon)
parameters["b"+str(i+1)]=parameters["b"+str(i+1)]-learning_rate*grads["db"+str(i+1)]/(np.sqrt(S["db"+str(i+1)])+epsilon)
return parameters,S
五.Adam(自适应矩估计)
1.基本概念
结合了Momentum算法和RMSprop算法,其公式如下:

其中t为当前迭代次数,
一般β1=0.9,β2=0.999,ε=1e-8
2.步骤
2.1 初始化
def initialize_with_adam(parameters):
V={}
S={}
L=len(parameters)//2
for i in range(L):
V["dW"+str(i+1)]=np.zeros_like(parameters["W"+str(i+1)])
V["db"+str(i+1)]=np.zeros_like(parameters["b"+str(i+1)])
S["dW"+str(i+1)]=np.zeros_like(parameters["W"+str(i+1)])
S["db"+str(i+1)]=np.zeros_like(parameters["b"+str(i+1)])
return (V,S)
2.2 更新参数
def update_parameters_with_adam(parameters,grads,V,S,t=2,beta1=0.9,beta2=0.999,epsilon=1e-8,learning_rate=0.01):
"""
:param parameters:
:param grads:
:param V:
:param S:
:param t: 当前迭代次数
:param beta1:
:param beta2:
:param epsilon:
:param learning_rate:
:return:parameters,v,s以便于下次的运算
"""
L=len(parameters)//2
V_corrected={}
S_corrected={}
for i in range(L):
# 4.2.1 得到vdw,vdb,v-corrected[dw],v_corrected[db]
V["dW"+str(i+1)]=beta1*V["dW"+str(i+1)]+(1-beta1)*grads["dW"+str(i+1)]
V["db"+str(i+1)]=beta1*V["db"+str(i+1)]+(1-beta1)*grads["db"+str(i+1)]
V_corrected["dW"+str(i+1)]=V["dW"+str(i+1)]/(1-np.power(beta1,t))
V_corrected["db"+str(i+1)]=V["db"+str(i+1)]/(1-np.power(beta1,t))
# 4.2.1 得到Sdw,Sdb,S-corrected[dw],S_corrected[db]
S["dW"+str(i+1)]=beta2*S["dW"+str(i+1)]+(1-beta2)*np.square(grads["dW"+str(i+1)])
S["db"+str(i+1)]=beta2*S["db"+str(i+1)]+(1-beta2)*np.square(grads["db"+str(i+1)])
S_corrected["dW"+str(i+1)]=S["dW"+str(i+1)]/(1-np.power(beta2,t))
S_corrected["db"+str(i+1)]=S["db"+str(i+1)]/(1-np.power(beta2,t))
# 4.2.3 更新W,b
parameters["W"+str(i+1)]=parameters["W"+str(i+1)]-learning_rate*V_corrected["dW"+str(i+1)]/(np.sqrt(S_corrected["dW"+str(i+1)])+epsilon)
parameters["b"+str(i+1)]=parameters["b"+str(i+1)]-learning_rate*V_corrected["db"+str(i+1)]/(np.sqrt(S_corrected["db"+str(i+1)])+epsilon)
return (parameters,V,S)
六.学习率的改变
要想加速神经网络收敛,除了以上算法,还可以改变学习率的大小,因为步长的大小与学习率相关。

七.使用各种优化算法实现结果
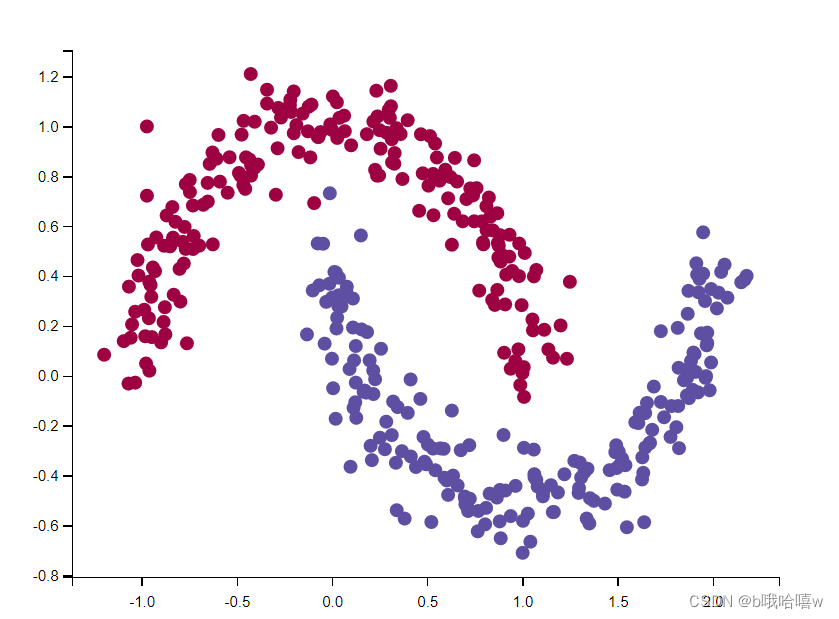
1.加载数据集
def load_dataset(is_plot=True):
np.random.seed(3)
train_X,train_Y=sklearn.datasets.make_moons(n_samples=400,noise=0.1)
# 可视化图片
if is_plot:
plt.scatter(train_X[:,0],train_X[:,1],c=train_Y,cmap=plt.cm.Spectral)
plt.show()
train_X = train_X.T
train_Y = train_Y.reshape((1, train_Y.shape[0]))
return train_X, train_Y
显示结果:
2.定义模型
def model(X,Y,layers_dims,optimizer,learning_rate=0.0007,mini_batch_size=64,beta=0.9,beta1=0.9,beta2=0.999 ,epsilon=1e-8,num_epochs = 10000,print_cost=True,is_plot=True):
"""
:param X: 数据集特征值
:param Y: 分类结果
:param layers_dims:隐藏单元数
:param optimizer: 优化算法
:param learning_rate:
:param mini_batch_size: 批次大小
:param beta:
:param beta1:
:param beta2:
:param epsilon:
:param num_epochs: 迭代次数
:param print_cost:
:param is_plot:
:return: parameters
"""
L = len(layers_dims)
costs=[]
# 迭代次数t
t=0
seed=10
# 6.1初始化参数
# 6.1.1 初始化w,b
parameters=opt_utils.initialize_parameters(layers_dims)
# 6.1.2选择优化算法
# 无优化算法
if optimizer=="gd":
pass
# momentum算法
elif optimizer=="momentum":
V=initialize_velocity(parameters)
# RMSprop
elif optimizer=="rmsprop":
S=initialize_rmsprop(parameters)
elif optimizer=="adam":
V,S=initialize_with_adam(parameters)
else:
print("optimizer出错了")
exit(1)
#6.2 开始迭代
for i in range(num_epochs):
seed+=1
# 6.2.1获得minibatches
minibatches=random_mini_batches(X,Y,mini_batch_size,seed)
# 6.2.2 对于每一个minibach进行迭代
for minibatch in minibatches:
(minibatch_X,minibatch_Y)=minibatch
# 6.2.2.1前向
A3, cache = opt_utils.forward_propagation(minibatch_X, parameters)
# 6.2.2.2计算误差
cost=opt_utils.compute_cost(A3,minibatch_Y)
# 6.2.2.3反向
grads=opt_utils.backward_propagation(minibatch_X,minibatch_Y,cache)
# 6.2.2.4更新参数
# 无优化算法
if optimizer == "gd":
parameters=update_parameters_with_gd(parameters,grads,learning_rate)
# momentum算法
elif optimizer == "momentum":
parameters,V=update_parameters_with_momentun(parameters,grads,V,beta,learning_rate)
# RMSprop
elif optimizer == "rmsprop":
parameters,S=update_parameters_with_rmsprop(parameters,grads,S,beta,learning_rate,epsilon)
elif optimizer == "adam":
t+=1
parameters,V,S=update_parameters_with_adam(parameters,grads,V,S,t,beta1,beta2,learning_rate,epsilon)
# 6.2.3 ,每迭代100次记录一次cost
if i%100==0:
costs.append(cost)
if print_cost and i%1000==0:
print("第"+str(i)+"次遍历整个数据集,当前误差值"+str(cost))
# 6.3 绘制曲线
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('t(100)')
plt.title("learning rate="+str(learning_rate))
plt.show()
return parameters
3.测试
3.1 无优化算法
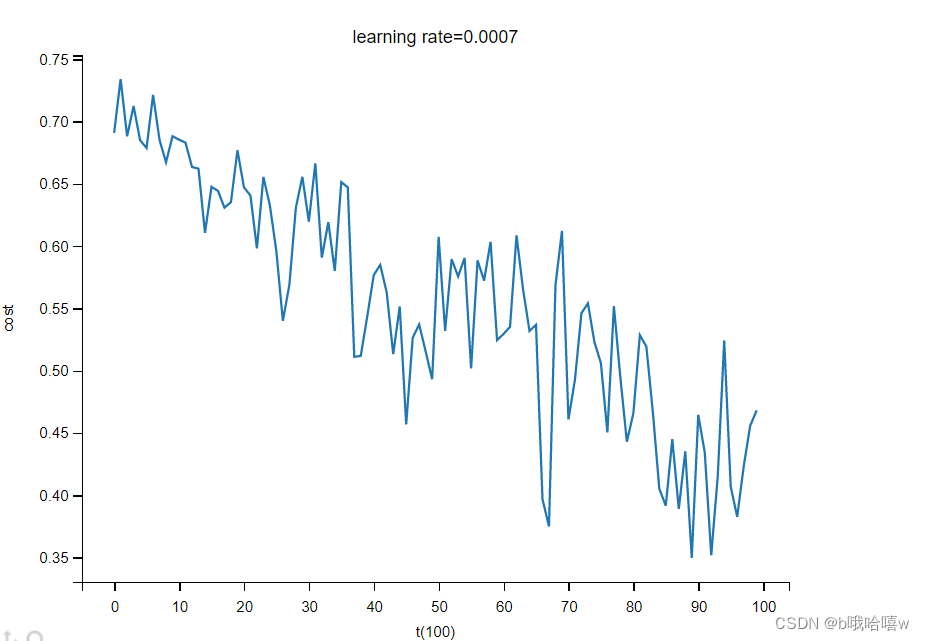
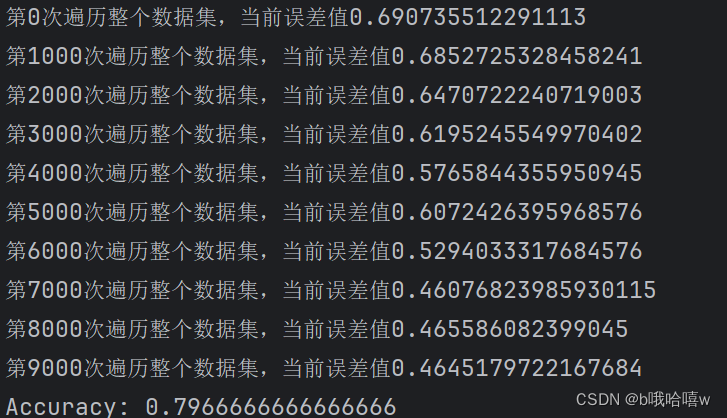
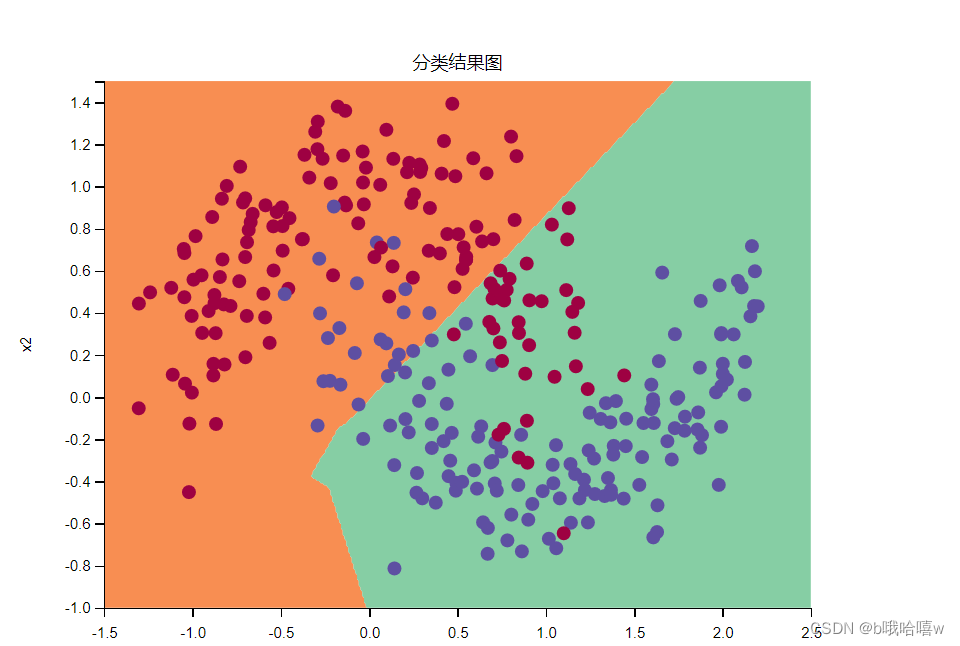
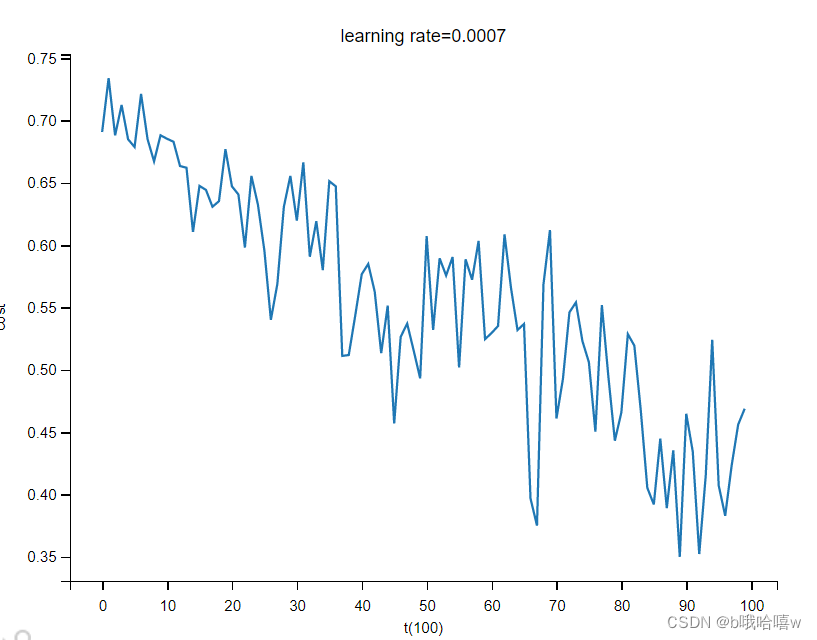
3.2 momentum算法
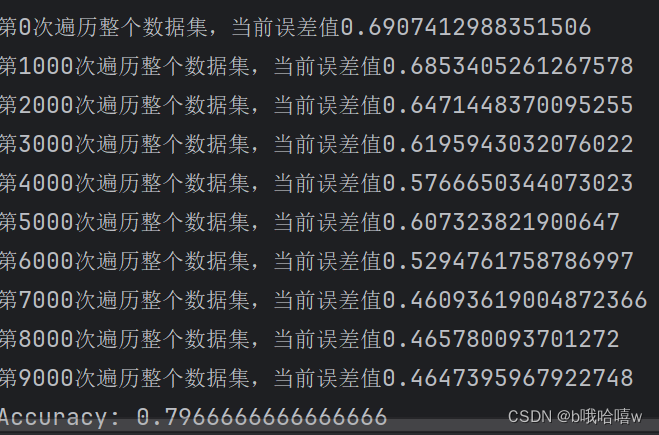
误差不大,是因为数据集太小,数据不够复杂
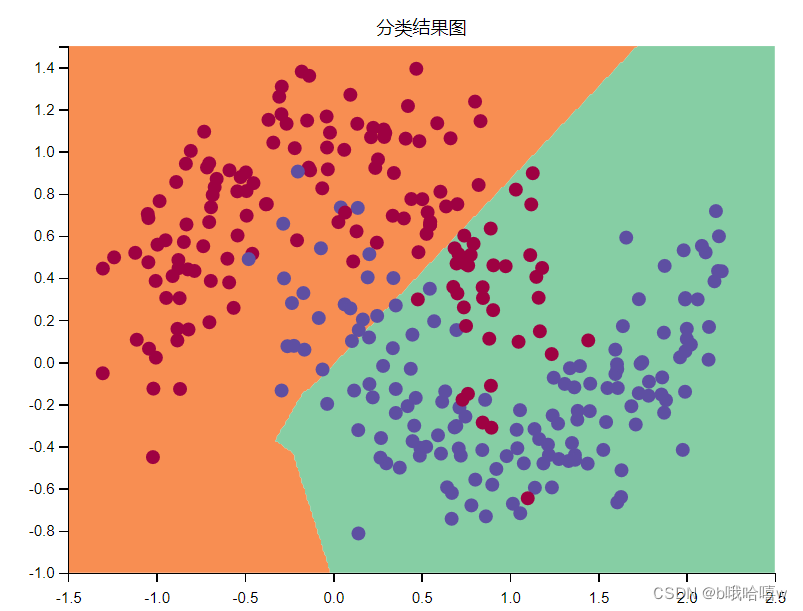
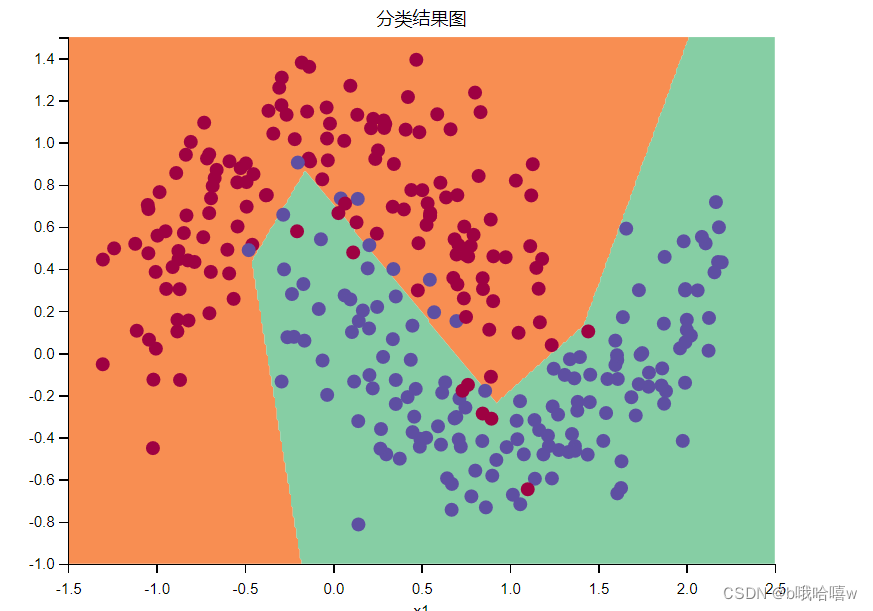
3.3 rmsprop算法
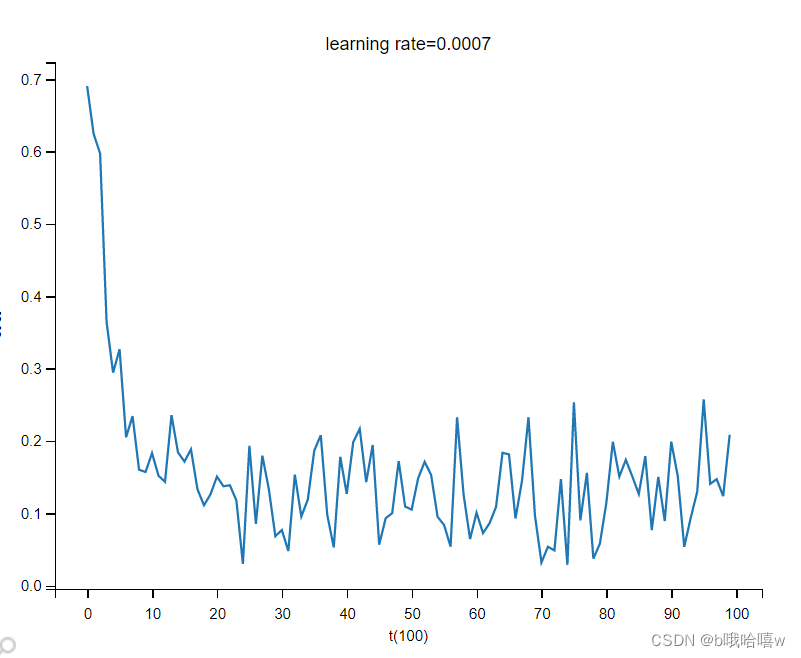
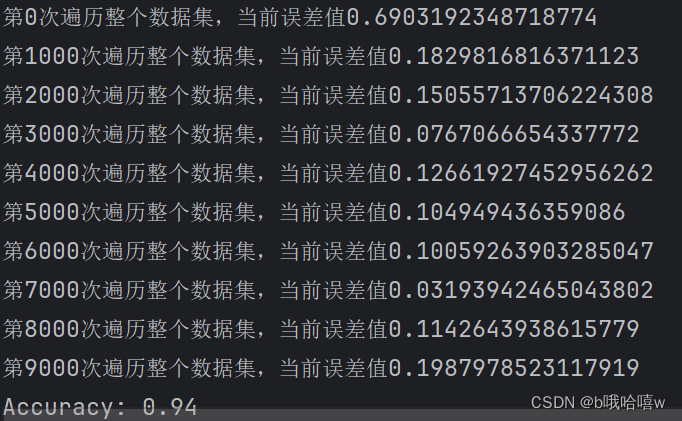
3.4 adam算法
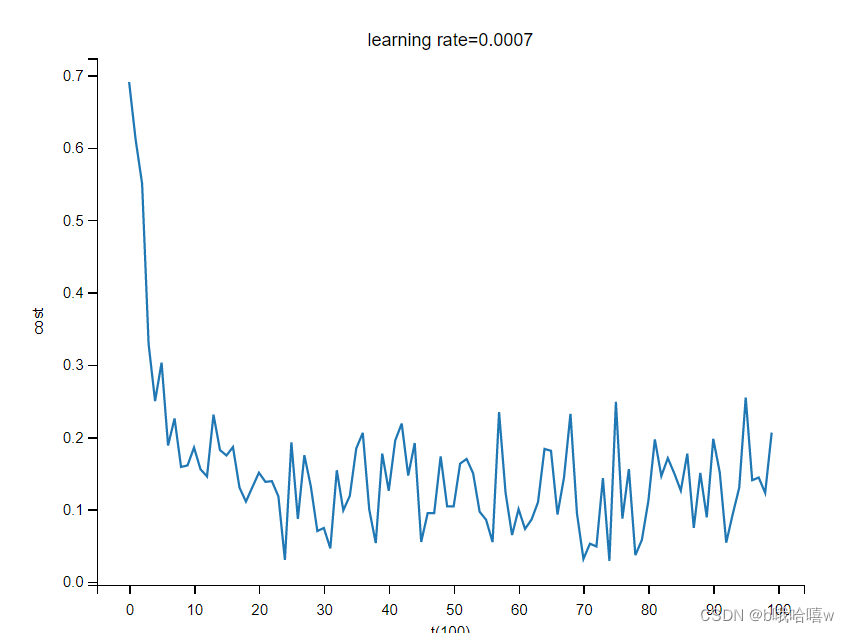

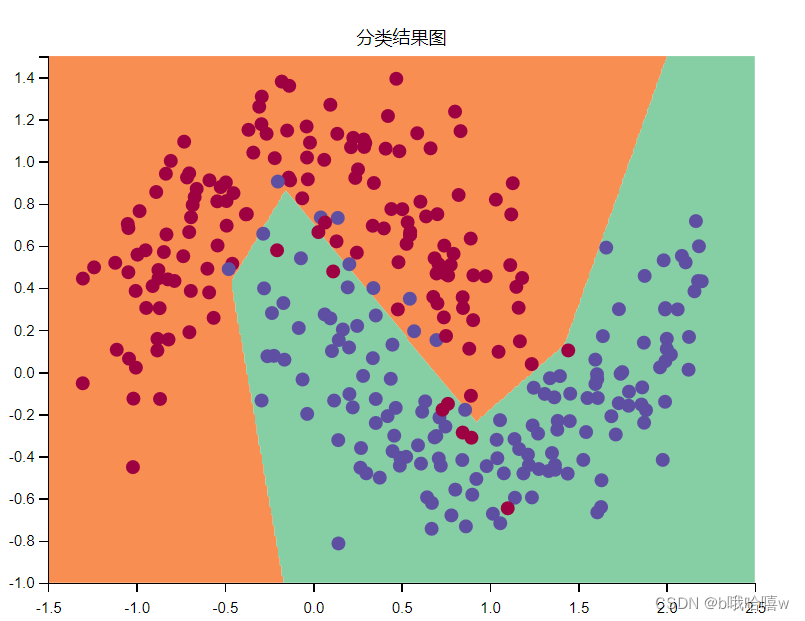
从图可以看出这里的adam算法主要是rmsprop算法起作用。
八.附加代码
minibatch.py
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定使用中文字体
import opt_utils
# 一、mini_batch
def random_mini_batches(X, Y, mini_batch_size=64,seed=0):
"""
:param X:
:param Y:
:param mini_batch_size:
:param seed:
:return:
"""
# 1.打乱数据集
np.random.seed(seed)
m=X.shape[1]
# print(m)
# permutation是原数组索引号构成的list
permutation=np.random.permutation(m)
shuffled_X=X[:,permutation]
shuffled_Y=Y[:,permutation].reshape((1,m))
# print(shuffled_X)
n=int(m/mini_batch_size)
# n=math.floor(m/mini_batch_size)
# print(n)
# 2.切分数据集
mini_batches=[]
# 2.1对于整出部分数据的处理
for i in range(n):
mini_batch_x=shuffled_X[:,i*mini_batch_size:(i+1)*mini_batch_size]
mini_batch_y=shuffled_Y[:,i*mini_batch_size:(i+1)*mini_batch_size]
mini_batch=(mini_batch_x,mini_batch_y)
mini_batches.append(mini_batch)
# print(mini_batches)
# print(i)
#2.2对于剩下的数据额外处理---
if m%mini_batch_size!=0:
mini_batch_x=shuffled_X[:,mini_batch_size*n:]
mini_batch_y=shuffled_Y[:,mini_batch_size*n:]
mini_batch=(mini_batch_x,mini_batch_y)
mini_batches.append(mini_batch)
return mini_batches
def update_parameters_with_gd(parameters, grads, learning_rate):
"""
使用梯度下降更新参数
参数:
parameters - 字典,包含了要更新的参数:
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
grads - 字典,包含了每一个梯度值用以更新参数
grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
learning_rate - 学习率
返回值:
parameters - 字典,包含了更新后的参数
"""
L = len(parameters) // 2 # 神经网络的层数
# 更新每个参数
for l in range(L):
parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * grads["dW" + str(l + 1)]
parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * grads["db" + str(l + 1)]
return parameters
# 二、动量梯度下降与加权平均
# 2.1 初始化 Vdb与Vdw,用他们来代替db和dw
def initialize_velocity(parameters):
'''
:param parameters: 里面包含每一层隐藏单元层的w,b
:return:
'''
V={}
L=len(parameters)//2
for i in range(L):
V["dW"+str(i+1)]=np.zeros_like(parameters["W"+str(i+1)])
V["db"+str(i+1)]=np.zeros_like(parameters["b"+str(i+1)])
return V
# 2.2 更新参数 Vdw,Vdb,w,b,超参数有beta,learning_rate
def update_parameters_with_momentun(parameters,grads,V,beta=0.9,learning_rate=0.01):
"""
:param parameters: 存储W1,W2...b1,b2... 的字典
:param grads: 存储dW1,dW2...db1,db2... 的字典
:param V:包含了Vdw,Vdb....的词典
:param beta:
:param learning_rate:
:return:
"""
L=len(parameters)//2
# 2.2.2 根据公式计算出Vdw,Vdb
for i in range(L):
V["dW"+str(i+1)]=beta*V["dW"+str(i+1)]+(1-beta)*grads["dW"+str(i+1)]
V["db"+str(i+1)]=beta*V["db"+str(i+1)]+(1-beta)*grads["db"+str(i+1)]
# 2.2.3 根据公式更新W,b
parameters["W"+str(i+1)]=parameters["W"+str(i+1)]-learning_rate*V["dW"+str(i+1)]
parameters["b"+str(i+1)]=parameters["b"+str(i+1)]-learning_rate*V["db"+str(i+1)]
return parameters,V
# 3.RMSprop
# 3.1 初始化参数
def initialize_rmsprop(parameters):
L=len(parameters)//2
S={}
for i in range(L):
S["dW"+str(i+1)]=np.zeros_like(parameters["W"+str(i+1)])
S["db"+str(i+1)]=np.zeros_like(parameters["b"+str(i+1)])
return S
# 3.2 更新参数
def update_parameters_with_rmsprop(parameters,grads,S,beta=0.999,learning_rate=0.001,epsilon=1e-8):
L=len(parameters)//2
for i in range(L):
# 3.2.1得到Sdw,Sdb
S["dW"+str(i+1)]=beta*S["dW"+str(i+1)]+(1-beta)*grads["dW"+str(i+1)]*grads["dW"+str(i+1)]
S["db"+str(i+1)]=beta*S["db"+str(i+1)]+(1-beta)*grads["db"+str(i+1)]*grads["db"+str(i+1)]
# 3.2.2得到w和b
parameters["W"+str(i+1)]=parameters["W"+str(i+1)]-learning_rate*grads["dW"+str(i+1)]/(np.sqrt(S["dW"+str(i+1)])+epsilon)
parameters["b"+str(i+1)]=parameters["b"+str(i+1)]-learning_rate*grads["db"+str(i+1)]/(np.sqrt(S["db"+str(i+1)])+epsilon)
return parameters,S
# 4.Adam
# 4.1 初始化参数
def initialize_with_adam(parameters):
V={}
S={}
L=len(parameters)//2
for i in range(L):
V["dW"+str(i+1)]=np.zeros_like(parameters["W"+str(i+1)])
V["db"+str(i+1)]=np.zeros_like(parameters["b"+str(i+1)])
S["dW"+str(i+1)]=np.zeros_like(parameters["W"+str(i+1)])
S["db"+str(i+1)]=np.zeros_like(parameters["b"+str(i+1)])
return (V,S)
# 4.2 更新参数
def update_parameters_with_adam(parameters,grads,V,S,t=2,beta1=0.9,beta2=0.999,epsilon=1e-8,learning_rate=0.01):
"""
:param parameters:
:param grads:
:param V:
:param S:
:param t: 当前迭代次数
:param beta1:
:param beta2:
:param epsilon:
:param learning_rate:
:return:parameters,v,s以便于下次的运算
"""
L=len(parameters)//2
V_corrected={}
S_corrected={}
for i in range(L):
# 4.2.1 得到vdw,vdb,v-corrected[dw],v_corrected[db]
V["dW"+str(i+1)]=beta1*V["dW"+str(i+1)]+(1-beta1)*grads["dW"+str(i+1)]
V["db"+str(i+1)]=beta1*V["db"+str(i+1)]+(1-beta1)*grads["db"+str(i+1)]
V_corrected["dW"+str(i+1)]=V["dW"+str(i+1)]/(1-np.power(beta1,t))
V_corrected["db"+str(i+1)]=V["db"+str(i+1)]/(1-np.power(beta1,t))
# 4.2.1 得到Sdw,Sdb,S-corrected[dw],S_corrected[db]
S["dW"+str(i+1)]=beta2*S["dW"+str(i+1)]+(1-beta2)*np.square(grads["dW"+str(i+1)])
S["db"+str(i+1)]=beta2*S["db"+str(i+1)]+(1-beta2)*np.square(grads["db"+str(i+1)])
S_corrected["dW"+str(i+1)]=S["dW"+str(i+1)]/(1-np.power(beta2,t))
S_corrected["db"+str(i+1)]=S["db"+str(i+1)]/(1-np.power(beta2,t))
# 4.2.3 更新W,b
parameters["W"+str(i+1)]=parameters["W"+str(i+1)]-learning_rate*V_corrected["dW"+str(i+1)]/(np.sqrt(S_corrected["dW"+str(i+1)])+epsilon)
parameters["b"+str(i+1)]=parameters["b"+str(i+1)]-learning_rate*V_corrected["db"+str(i+1)]/(np.sqrt(S_corrected["db"+str(i+1)])+epsilon)
return (parameters,V,S)
# 5.加载数据集
train_X,train_Y=opt_utils.load_dataset(is_plot=False)
# 6.定义模型
def model(X,Y,layers_dims,optimizer,learning_rate=0.0007,mini_batch_size=64,beta=0.9,beta1=0.9,beta2=0.999 ,epsilon=1e-8,num_epochs = 10000,print_cost=True,is_plot=True):
"""
:param X: 数据集特征值
:param Y: 分类结果
:param layers_dims:隐藏单元数
:param optimizer: 优化算法
:param learning_rate: xuexilv
:param mini_batch_size: 批次大小
:param beta:
:param beta1:
:param beta2:
:param epsilon:
:param num_epochs: 迭代次数
:param print_cost:
:param is_plot:
:return: parameters
"""
L = len(layers_dims)
costs=[]
# 迭代次数t
t=0
seed=10
# 6.1初始化参数
# 6.1.1 初始化w,b
parameters=opt_utils.initialize_parameters(layers_dims)
# 6.1.2选择优化算法
# 无优化算法
if optimizer=="gd":
pass
# momentum算法
elif optimizer=="momentum":
V=initialize_velocity(parameters)
# RMSprop
elif optimizer=="rmsprop":
S=initialize_rmsprop(parameters)
elif optimizer=="adam":
V,S=initialize_with_adam(parameters)
else:
print("optimizer出错了")
exit(1)
#6.2 开始迭代
for i in range(num_epochs):
seed+=1
# 6.2.1获得minibatches
minibatches=random_mini_batches(X,Y,mini_batch_size,seed)
# 6.2.2 对于每一个minibach进行迭代
for minibatch in minibatches:
(minibatch_X,minibatch_Y)=minibatch
# 6.2.2.1前向
A3, cache = opt_utils.forward_propagation(minibatch_X, parameters)
# 6.2.2.2计算误差
cost=opt_utils.compute_cost(A3,minibatch_Y)
# 6.2.2.3反向
grads=opt_utils.backward_propagation(minibatch_X,minibatch_Y,cache)
# 6.2.2.4更新参数
# 无优化算法
if optimizer == "gd":
parameters=update_parameters_with_gd(parameters,grads,learning_rate)
# momentum算法
elif optimizer == "momentum":
parameters,V=update_parameters_with_momentun(parameters,grads,V,beta,learning_rate)
# RMSprop
elif optimizer == "rmsprop":
parameters,S=update_parameters_with_rmsprop(parameters,grads,S,beta,learning_rate,epsilon)
# adam
elif optimizer == "adam":
t+=1
parameters,V,S=update_parameters_with_adam(parameters,grads,V,S,t,beta1,beta2,epsilon,learning_rate)
# 6.2.3 ,每迭代100次记录一次cost
if i%100==0:
costs.append(cost)
if print_cost and i%1000==0:
print("第"+str(i)+"次遍历整个数据集,当前误差值"+str(cost))
# 6.3 绘制曲线
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('t(100)')
plt.title("learning rate="+str(learning_rate))
plt.show()
return parameters
# 7.测试
layers_dims=[train_X.shape[0],5,2,1]
parameters=model(train_X,train_Y,layers_dims,optimizer="adam",is_plot=True)
# 8. 绘制分类情况
#预测
preditions = opt_utils.predict(train_X,train_Y,parameters)
#绘制分类图
plt.title("分类结果图")
axes = plt.gca()
axes.set_xlim([-1.5, 2.5])
axes.set_ylim([-1, 1.5])
opt_utils.plot_decision_boundary(lambda x: opt_utils.predict_dec(parameters, x.T), train_X, train_Y)
# plt.show()
opt_utils.py
# -*- coding: utf-8 -*-
# opt_utils.py
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- sigmoid(x)
"""
s = 1 / (1 + np.exp(-x))
return s
def relu(x):
"""
Compute the relu of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- relu(x)
"""
s = np.maximum(0, x)
return s
def load_params_and_grads(seed=1):
np.random.seed(seed)
W1 = np.random.randn(2, 3)
b1 = np.random.randn(2, 1)
W2 = np.random.randn(3, 3)
b2 = np.random.randn(3, 1)
dW1 = np.random.randn(2, 3)
db1 = np.random.randn(2, 1)
dW2 = np.random.randn(3, 3)
db2 = np.random.randn(3, 1)
return W1, b1, W2, b2, dW1, db1, dW2, db2
def initialize_parameters(layer_dims):
"""
Arguments:
layer_dims -- python array (list) containing the dimensions of each layer in our network
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layer_dims[l], layer_dims[l-1])
b1 -- bias vector of shape (layer_dims[l], 1)
Wl -- weight matrix of shape (layer_dims[l-1], layer_dims[l])
bl -- bias vector of shape (1, layer_dims[l])
Tips:
- For example: the layer_dims for the "Planar Data classification model" would have been [2,2,1].
This means W1's shape was (2,2), b1 was (1,2), W2 was (2,1) and b2 was (1,1). Now you have to generalize it!
- In the for loop, use parameters['W' + str(l)] to access Wl, where l is the iterative integer.
"""
np.random.seed(3)
parameters = {}
L = len(layer_dims) # number of layers in the network
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l - 1]) * np.sqrt(2 / layer_dims[l - 1])
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
assert (parameters['W' + str(l)].shape == layer_dims[l], layer_dims[l - 1])
assert (parameters['W' + str(l)].shape == layer_dims[l], 1)
return parameters
def forward_propagation(X, parameters):
"""
Implements the forward propagation (and computes the loss) presented in Figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape ()
b1 -- bias vector of shape ()
W2 -- weight matrix of shape ()
b2 -- bias vector of shape ()
W3 -- weight matrix of shape ()
b3 -- bias vector of shape ()
Returns:
loss -- the loss function (vanilla logistic loss)
"""
# retrieve parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
z1 = np.dot(W1, X) + b1
a1 = relu(z1)
z2 = np.dot(W2, a1) + b2
a2 = relu(z2)
z3 = np.dot(W3, a2) + b3
a3 = sigmoid(z3)
cache = (z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3)
return a3, cache
def backward_propagation(X, Y, cache):
"""
Implement the backward propagation presented in figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat)
cache -- cache output from forward_propagation()
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3) = cache
dz3 = 1. / m * (a3 - Y)
dW3 = np.dot(dz3, a2.T)
db3 = np.sum(dz3, axis=1, keepdims=True)
da2 = np.dot(W3.T, dz3)
dz2 = np.multiply(da2, np.int64(a2 > 0))
dW2 = np.dot(dz2, a1.T)
db2 = np.sum(dz2, axis=1, keepdims=True)
da1 = np.dot(W2.T, dz2)
dz1 = np.multiply(da1, np.int64(a1 > 0))
dW1 = np.dot(dz1, X.T)
db1 = np.sum(dz1, axis=1, keepdims=True)
gradients = {"dz3": dz3, "dW3": dW3, "db3": db3,
"da2": da2, "dz2": dz2, "dW2": dW2, "db2": db2,
"da1": da1, "dz1": dz1, "dW1": dW1, "db1": db1}
return gradients
def compute_cost(a3, Y):
"""
Implement the cost function
Arguments:
a3 -- post-activation, output of forward propagation
Y -- "true" labels vector, same shape as a3
Returns:
cost - value of the cost function
"""
m = Y.shape[1]
logprobs = np.multiply(-np.log(a3), Y) + np.multiply(-np.log(1 - a3), 1 - Y)
cost = 1. / m * np.sum(logprobs)
return cost
def predict(X, y, parameters):
"""
This function is used to predict the results of a n-layer neural network.
Arguments:
X -- data set of examples you would like to label
parameters -- parameters of the trained model
Returns:
p -- predictions for the given dataset X
"""
m = X.shape[1]
p = np.zeros((1, m))
# Forward propagation
a3, caches = forward_propagation(X, parameters)
# convert probas to 0/1 predictions
for i in range(0, a3.shape[1]):
if a3[0, i] > 0.5:
p[0, i] = 1
else:
p[0, i] = 0
# print results
# print ("predictions: " + str(p[0,:]))
# print ("true labels: " + str(y[0,:]))
print("Accuracy: " + str(np.mean((p[0, :] == y[0, :]))))
return p
def predict_dec(parameters, X):
"""
Used for plotting decision boundary.
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (m, K)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
# Predict using forward propagation and a classification threshold of 0.5
a3, cache = forward_propagation(X, parameters)
predictions = (a3 > 0.5)
return predictions
def plot_decision_boundary(model, X, y):
# Set min and max values and give it some padding
x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1
y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole grid
Z = model(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral)
plt.show()
def load_dataset(is_plot=True):
np.random.seed(3)
train_X, train_Y = sklearn.datasets.make_moons(n_samples=300, noise=.2) # 300 #0.2
# Visualize the data
if is_plot:
plt.scatter(train_X[:, 0], train_X[:, 1], c=train_Y, s=40, cmap=plt.cm.Spectral);
train_X = train_X.T
train_Y = train_Y.reshape((1, train_Y.shape[0]))
return train_X, train_Y















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









