







笔记(1)中是关于点云配准方向的,(2)和(3)(4)中是点云变化检测和点云分割的,实际上我认为这两种任务的差别不大。都是密集的分类任务,主要是在变化检测中的双时相输入如何好的融合以及融合后映射到特征空间中。由于点云变化检测的论文较少,中间也看了不少的图像变化检测的论文。
CDRL-2022-CVPRW
Noh_Unsupervised_Change_Detection_Based_on_Image_Reconstruction_Loss_CVPRW_2022_paper
一种利用时相域转换后在同一域后,利用空间注意力和通道注意力串联后进行的图片二值变化检测。
提出的原因
①本文认为尽管无监督下的双时相图像相对容易获得,但是仍然需要双时相图像,因此提出使用一个时相的图像并通过光度变化的该图像作为一对进行输入。
新颖点
①通过单时相的图像作为输入,利用源图像和光度变换后的源图像作为不变对进行学习,以此来让网络适应这种由光度变化带来的误差变化。
②通过不同光度的相同图像,以此作为无监督学习的输入的话最终学到的模型最终就是可以忽略
网络架构
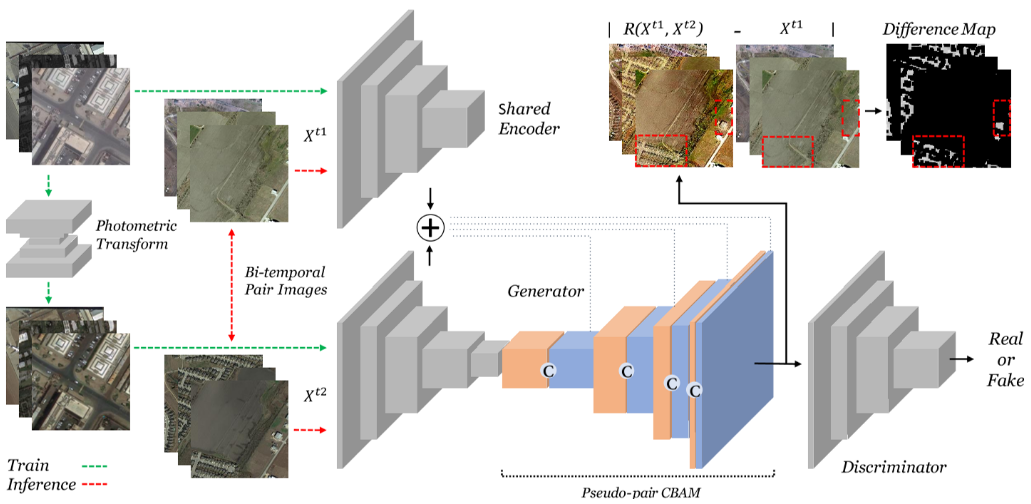
首先对于单时相的图进行光度变换(利用CycleGAN进行风格转换的光度变换,这是因为简单规则下进行光度变化没法模拟真实世界中的光度变换,CycleGAN包括了两个生成器和两个判别器,生成器分别G,F分别代表从X->Y和从Y->X,判别器分别判断从X->Y和从Y->X,保持了对抗的过程,同时加上了循环一致性损失用于得到好的生成器),用于得到初始的伪不变多时相图,在训练中,将这两个图像作为输入,然后利用UNet的基础结构作为重构器,首先是提取特征,然后利用CBAM进行注意力机制,为了在训练中不要过于注重X1图片的结构(因为在测试的时候X1位置是需要判断变化检测的图片,如果过于注重的话最终的结果重建的损失也会很低,也就是过拟合了),因此这里提出了CBAM,在X1图像这里利用通道注意力机制关注风格,在X2图像这里关注结构,然后重构回去的图片就是X2的结构,X1的风格了。
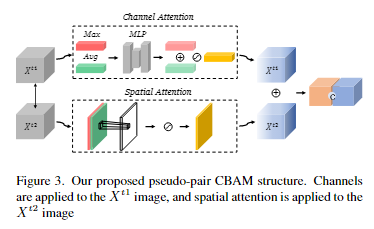
CBAM的做法是对X1先按通道平均池化和最大池化,然后利用多层感知机得到最终的权重,然后求和后对原始X1进行通道的权重分配,同理对于X2得到空间的权重进行分配得到X2’,对这两个进行拼接即可。
在训练时仍然存在过拟合的现象,因此本文使用了一个判别器用于加强对抗的过程,对于生成器来说,想要尽可能生成和X1相似的图片,因此判别器就要从X1和生成的图片中判断谁是真实的。
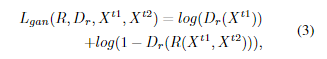
实验方法
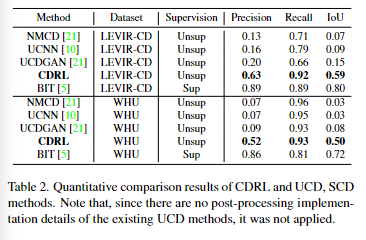
现有的UCD方法的预测结果非常嘈杂,对小的结构变化非常敏感,因此它们具有高的召回率和低的精确度。实验结果表明,CDRL对小的结构变化和风格变化都很稳健(为什么说很稳健,我认为是在Cycle的时候生成的另一个域的伪不变图片时将其噪声波动等风格也学进去了,因此最终训练是在有着噪声等干扰的情况下进行的,对于不同域的变化有着鲁棒性)。与有监督的BIT相比,CDRL具有相似的召回率,但明显较低的精确度。本文认为CDRL没有明确学习像素级变化区域,所以它只能定位大致的位置。其次有监督变化检测可以明确地训练关于感兴趣的变化对象的信息,因此它可以明确地学习一辆汽车是被创建的,或一个湖泊是发生变化或未发生变化的,但CDRL预测它们都发生了变化。
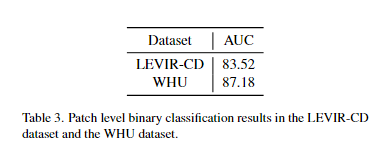
本文在patch是否变化进行检测也做了实验,最终得到了较好的结果。
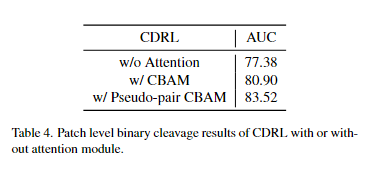
消融实验
①注意力模块:
②对抗训练:
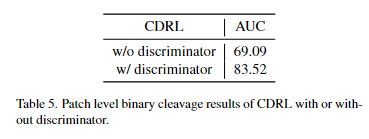

从图六可以看到,当没有判别器时,重建的图像是模糊的。
而当有判别器时,可以看到边界被更清晰地重建。这些结果表明,对抗训练(即使用判别器)在CDRL中也是有效的。
KPCA-MNet-2022-ITC
Unsupervised_Change_Detection_in_Multitemporal_VHR_Images_Based_on_Deep_Kernel_PCA_Convolutional_Mapping_Network-ITC-2022
一种利用KPCA得到的主成分变化矩阵作为卷积核进行图像特征提取,最终生成包含角度和距离的图片,并对距离使用阈值分割产生二值变化图,对分割后的角度进行聚类得到多值变化图的伪网络结构。
提出的原因
①传统的图像转换方法主要探索低级特征。
②KPCA是一种非线性版本的PCA,能够提取更加具有代表性的特征,特别是对于想要区分的数据是需要在非线性的空间中区分的。
③数据标注的问题。
KPCA
核主成分分析的本质解释将原先的特征维度空间通过一个映射,映射到高纬度的特征空间,然后在这个高纬度的特征空间中通过PCA进行特征抽取。但是通过映射映射到高维空间时,这个映射是复杂多样的,而在求解PCA的过程中通过内积的运算发现可以不需要显式的映射,只需要定义核函数p(x,y),也就是x样本和y样本的内积就能求得最终的主成分方向,因此称为核主成分,具体求解过程:
ϕ
:
N
−
>
D
,样本为
X
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
ϕ
(
x
)
ϕ
T
(
x
)
p
=
λ
p
,
p
为
D
维特征空间的特征向量。
因为对于
λ
=
0
的特征向量不取,则有
p
=
ϕ
(
x
)
ϕ
T
(
x
)
p
λ
所以有
p
=
ϕ
(
x
)
α
所以有
ϕ
(
x
)
ϕ
T
(
x
)
ϕ
(
x
)
α
=
λ
ϕ
(
x
)
α
同时左乘
ϕ
T
(
x
)
,令
K
(
x
,
y
)
=
ϕ
(
x
)
ϕ
T
(
y
)
则有
K
2
α
=
λ
K
α
,即
K
α
=
λ
α
,通过定义核函数
K
(
x
,
y
)
可以无需定义映射得到
α
,然而
p
=
ϕ
(
x
)
α
,对特征特征向量进行归一化
p
T
p
=
α
K
α
T
=
λ
α
T
α
,因此对特征向量归一化即让
α
=
α
/
(
λ
)
最终得到的主成分投影
t
i
=
ϕ
(
x
i
)
p
a
=
∑
α
i
j
K
i
j
\phi :N->D,样本为X=[x1,x2,...,xn] \\ \phi(x)\phi^T(x)p=λp,p为D维特征空间的特征向量。\\ 因为对于λ=0的特征向量不取,则有p=\frac{\phi(x)\phi^T(x)p}{λ} \\ 所以有p=\phi(x)α \\ 所以有\phi(x)\phi^T(x)\phi(x)α=λ\phi(x)α \\ 同时左乘\phi^T(x),令K(x,y) = \phi(x)\phi^T(y) \\ 则有K^2α=λKα,即Kα=λα,通过定义核函数K(x,y) \\ 可以无需定义映射得到α,然而p=\phi(x)α,对特征特征向量进行归一化 \\ p^Tp=αKα^T=λα^Tα,因此对特征向量归一化即让α=α/\sqrt(λ)\\ 最终得到的主成分投影ti=\phi(x_i)p_a=\sum{α_{ij}K_{ij}}
ϕ:N−>D,样本为X=[x1,x2,...,xn]ϕ(x)ϕT(x)p=λp,p为D维特征空间的特征向量。因为对于λ=0的特征向量不取,则有p=λϕ(x)ϕT(x)p所以有p=ϕ(x)α所以有ϕ(x)ϕT(x)ϕ(x)α=λϕ(x)α同时左乘ϕT(x),令K(x,y)=ϕ(x)ϕT(y)则有K2α=λKα,即Kα=λα,通过定义核函数K(x,y)可以无需定义映射得到α,然而p=ϕ(x)α,对特征特征向量进行归一化pTp=αKαT=λαTα,因此对特征向量归一化即让α=α/(λ)最终得到的主成分投影ti=ϕ(xi)pa=∑αijKij
中心化的计算:

PCA提取图像特征的方法
线性:首先对于图像每一个像素点提取以其为中心的一块patch,所有通道都要包括在内,最终都到hw块patch,随机挑选n个patch(否则数量级太大了,计算很复杂)然后计算彼此的协方差矩阵,得到s1s2c*s1s2c的矩阵,求解特征值的前k个特征向量s1s2c,对于所有的patch用这k个特征向量s1s2c进行加权求和就得到了一个像素中的k维特征,最终F为h*w*k维度。因此这里也称利用线性PCA作为卷积核进行特征提取(确实很像)。
那么对于非线性的,就是对每一块patch首先进行非线性的映射,然后对于映射后的patch进行同样的主成分操作即可。把线性的看作核函数是简单的h(x,y)=xy。
网络架构
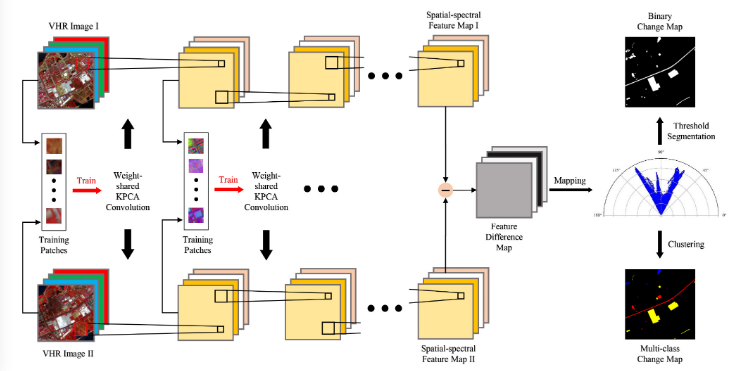
首先对于每个像素,提取其周围s1长,s2宽,所有通道宽的一块作为patch,共有h*w块patch,对于这些patch随机选择n个,计算彼此之间的核函数矩阵s1s2c*s1s2c,然后进行特征向量矩阵的计算,取前k个特征值对应的特征向量s1s2c,然后对每一个patch进行利用特征向量进行投影,最终得到每一个像素的k维特征,重复l次得到深层次的光谱特征图,计算特征差异图,对于特征差异图,通过下述公式,得到单层的Θ和ρ图,也就是从原来的d维简化到二维极坐标平面,θ由原差异图的各通道的变化图通过对应的特征值进行加权得到,ρ由特征差异图平方后求和得到。对于二值变化检测图直接使用ρ进行阈值分割法得到结果,对于多分类的变化检测图,首先利用ρ阈值分割法得到变化的点,然后在变化的点中对θ使用聚类算法得到多分类的变化检测图。
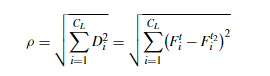
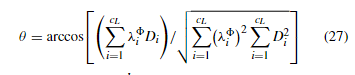
实验方法
二值
数据集
①GF-2搜集的WH,VHR图像对由四个光谱波段组成,1000*1000像素,空间分辨率为4m,②QuickBird在武汉大学收集的QU,四个光谱波段,358*290像素,空间分辨率为2.4m,
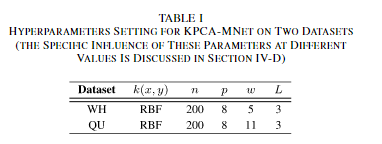
超参数的设置如上
其他的无监督CD方法
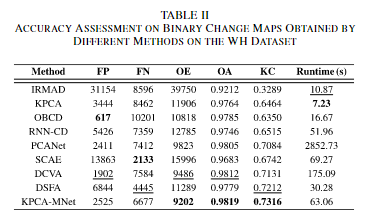
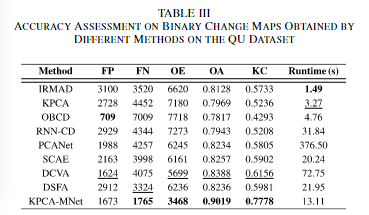
IMRMAD/KPCA/BOBCD/RNNCD/PCANet/SCAE/DCVA/DSFA,其中RNNCD是提出的基于RNN 的 CD 网络,在 CD 中表现出良好的性能。PCANet方法利用Gabor小波和FCM作为预检测方法来选择训练样本,然后用选定的图像补丁训练一个PCANet模型。堆叠卷积 AE (SCAE) 是一种通过堆叠多个 CAE 构建的无监督 DL 方法。通过分层贪婪训练,SCAE可以提取输入数据的基本特征。DCVA 是一种无监督的 CD 方法,它利用预训练的 DCNN 来提取深度空间光谱特征。DSFA是一个基于dl的CD框架,它使用双流DNN提取非线性特征,并使用SFA算法检测变化区域。采用K-means、OTSU和FCM作为阈值分割方法,选取最佳结果作为最终结果。
评价指标
FP、FN、OE、OA、KC=(OA-PE)/(1-PE),其中PE=((TP+FP)(TP+FN)+(TN+FN)(FP+TN))/N^2

实验结果
对于WH数据集:IRMAD 的性能并不令人满意,大量未更改的区域被错误检测到。此外,一些改变的建筑物被错误分类为不变的建筑物。与IRMAD相比,KPCA得到的二元变化图更好。然而,由于只考虑光谱信息,一些小物体没有被正确分类,很多建筑物的边缘被错误地检测为变化的像素。由于OBCD的结果,几乎没有椒盐噪声。然而,由于仅使用低级特征,没有检测到许多建筑物变化。RNN-CD的二值变化图比KPCA和OBCD得到的二值变化图更准确。然而,RNN 架构不能有效地提取空间特征,导致建筑物边缘的错误检测和变化区域的内部碎片。PCANet结果如图6(e)所示。通过级联线性PCA滤波器,噪声得到了很好的抑制。通过几个CAEs从图像中学习基本特征,SCAE产生了不错的结果,其中几乎所有的变化像素都被正确分类。但是,一些未更改的像素被错误地检测为更改的像素。通过预训练的深度 CNN 提取深度特征,DCVA 的结果在视觉方面很好。通过双流 DNN 学习非线性表示,DSFA 很好地保留了大部分变化区域,定量结果如下

对于QU数据集:在IRMAD得到的结果中,错误检测到部分变化区域,存在大量椒盐噪声。在KPCA的二元变化图中[见图7(b)],许多变化的像素被错误分类。此外,一些未更改的建筑物被错误地检测为更改的建筑物。在OBCD生成的结果中,许多明显变化的区域没有被识别,如中央游乐场的变化。在图 7(d) 中,主变化区域由 RNN-CD 正确分类。然而,缺失区域中的一些细节被遗漏,大量不变的建筑物和道路被错误检测到。在图7(e)中,与RNN-CD相比,PCANet的二元变化图中噪声较小。在 SCAE 的结果中,大部分未更改的像素被正确检测。尽管如此,部分更改的像素被错误地归类为未更改的像素。如图7(g)和(h)所示,DCVA和DSFA在QU数据集上获得了不错的变化图。定量结果如下
关于超参数选择的讨论
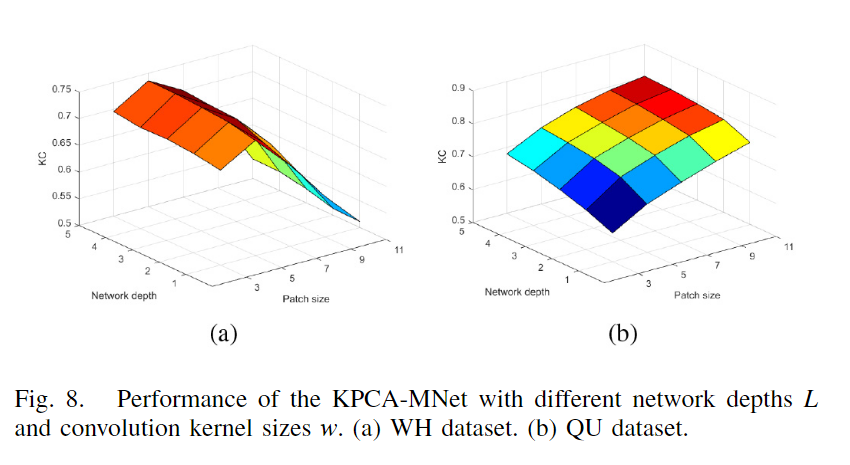
对于网络深度无疑是越深越好,但是考虑到运行的负担与提升的性能,最终选择在2到4之间,而卷积核的大小与网络的视觉野有关,因此随着数据集的分辨率不同有所不同,对于4m分辨率的WH,从3到5在增加,但是再大就开始下降,对于2.4m分辨率的QU数据集,随着w增加,网络性能不断增加,最终经过了本文的不同数据集的实验,认为在20-30m的视野范围即为KPCA卷积核的合适大小。
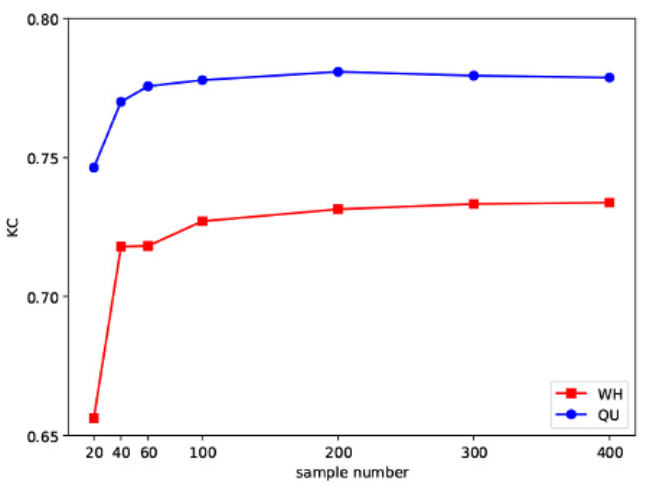
对于样本数量n来说,训练样本的数量 n 将影响 KPCA 卷积特征提取能力。训练样本越多,KPCA卷积提取的空间光谱特征更具代表性。但过多则会导致计算成本的增加,在n=200时即为最佳选择。
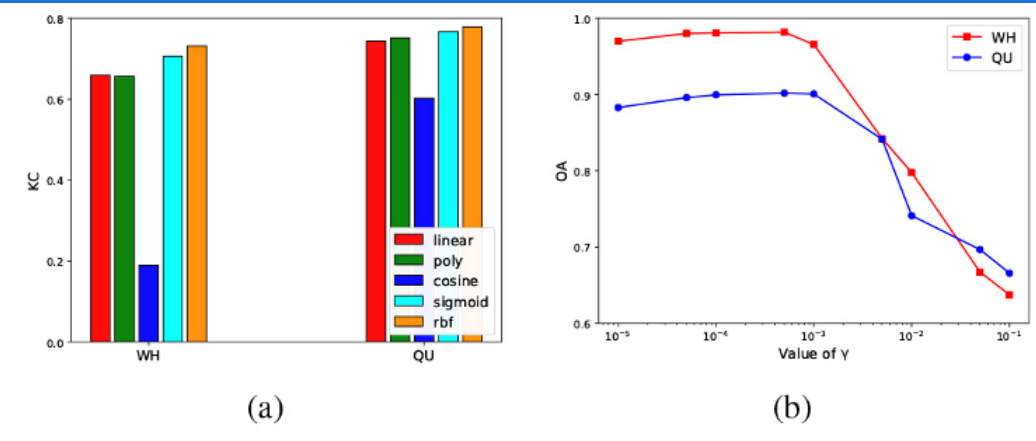
在核函数的选择以及核函数中的参数选择上,对于 KPCA 卷积,核函数的选择是显着的,因为不同的核函数具有不同的映射能力。在图 10(a) 中,比较了 KPCA-MNet 在两个数据集上具有五个常用核函数的性能。RBF是KPCA卷积的最佳选择,可以使网络提取更具代表性的非线性特征。sigmoid 内核也显示出良好的性能。与线性 PCA 卷积相比,选择 RBF 或 sigmoid 作为核函数可以显着提高 CD 性能,这证明了将线性 PCA 卷积推广到 KPCA 卷积的必要性。此外,RBF核γ的传播也会影响KPCA-MNet的性能。在图10(b)中,我们给出了两个数据集CD精度和γ之间的关系曲线。随着 γ 的降低,KPCA-MNet 的准确率迅速增加。当 γ < 1e-3 时,准确度变得稳定。当 γ = 5e-4 时,可以获得最佳性能。
对于卷积核的数量,根据经验设置为8。
多值
数据集
HY数据集,两幅图像之间的土地覆盖变化主要涉及城市变化(建筑物或道路到其他人工设施)、水变化(水域到裸土或植被)和土壤变化(土壤到人工设施或水域)。红色表示城市变化,蓝色表示水变化,黄色表示土壤变化,绿色表示不变区域,其余像素未定义。

超参数的设置:n=200,p=8,2层KPCA卷积层
其他的无监督多类别CD方法
PCC/2D-CVA/C^2VA/PCA/IRMAD/SAE/RandNet,其中PCC 是多类 CD 中广泛使用的框架。在实验中,利用无监督聚类算法ISODATA来获得多时相分类图。在 2D-CVA 中,选择两个波段来计算光谱变化向量的大小和方向,以检测各种变化。通过跟踪和测试或一些先验信息选择最佳组合。C2 VA将所有波段压缩为光谱变化向量的大小和方向,进行阈值分割和聚类,得到多类CD结果。在基于 PCA 的方法中,计算前两个主成分的大小和方向以生成多类变化图。至于IRMAD,最后两个MAD变量用于计算大小和方向,因为它们包含最变化的信息。在SAE中,首先从VHR图像中提取空间光谱特征,然后采用C2 VA中提出的相同方式利用这些特征进行CD。而RandNet则是直接将KPCA-MNet中的卷积核改成了随机高斯分布形成的卷积核,除此之外,还加上了还映入了LinearPCA-MNet的变体,一眼就知道是将KPCA换成了LinearPCA。
评价指标
OA和KC
实验结果

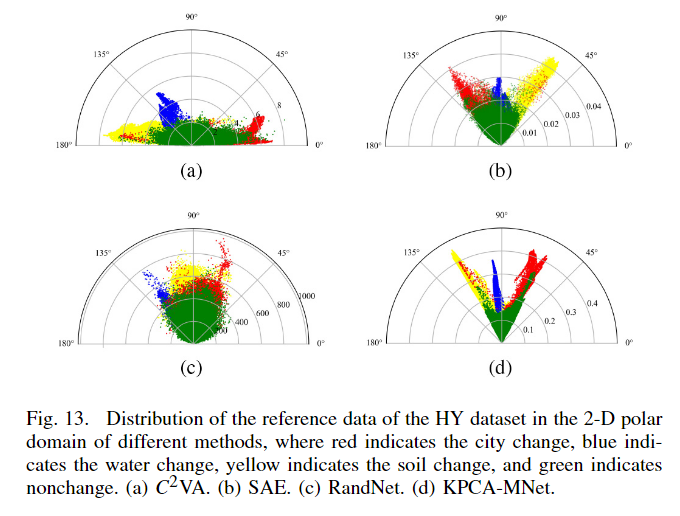
PCC 生成的变化图在视觉上并不好,因为聚类技术在准确分类土地覆盖方面是无力的。在 2D-CVA的结果中,正确检测到主要变化和未变化区域。然而,由于只使用了两个波段的变化信息,水的变化不被归类为土壤变化,没有检测到一些土壤变化。通过利用来自所有波段的变化信息,C2 VA 获得的多类变化图优于 2DCVA 的特征图。然而,由于 C2 VA 仅使用光谱信息,各种变化区域具有内部碎片,未变化区域具有椒盐噪声。对于 PCA,由于主要变化信息集中在前两个主成分中,PCA 的 CD 结果与 C2 VA 的 CD 结果相似。在图 12(e) 中,IRMAD 正确分类了主要土壤变化和水分变化,但大多数城市变化都没有被检测到。与 C2 VA 相比,空间上下文信息用于检测 SAE 的多类变化。因此,大部分未更改的区域都被正确分类,结果内部碎片和椒盐噪声很小。尽管如此,SAE 没有检测到一些土壤变化和大量的城市变化。如图 12(g) 所示,虽然与 KPCAMNet 共享相同的架构,但 RandNet 在 HY 数据集上表现不佳,这表明随机卷积核不能为多类 CD 提取有效特征。线性PCAMNet检测到的多类变化图是不错的。然而,线性 PCA 卷积提取的特征不够代表,导致 soli 变化和水变化之间的错误分类。相比之下,在 KPCA-MNet 的结果中,大部分变化区域和不变区域都被准确检测到,并且可以有效地相互区分三种变化,这意味着 KPCA 卷积确实从 VHR 图像中提取具有代表性的空间光谱特征,不同类型的变化在 FM(特征幅度,特征差异图D) 和 WFD(加权特征方向,也就是后面的加权到一位特征θ上) 表示的新特征空间中有效区分。定量结果如下图。
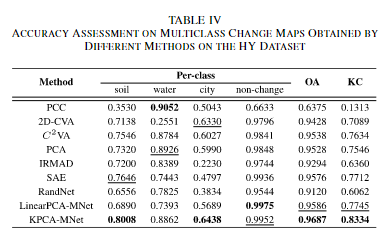
2D极坐标图展示
相比于其他的方法,可以明显看出,在KPCA-MNet中变化类和不变化类可以通过ρ进行分割,而变化类中的三个可以通过θ的角度进行聚类。
为了验证本文提出的WFD方法在多类CD中的优越性,使用了M1(直接在原始特征差异图中进行聚类算法),M2(在聚类前,各通道根据对应的特征值进行加权),M3(从特征差异图中留下两个特征值最大的对应的特征变化图),M4(类似于WFD,但是没有根据特征值对特征差异图的个通道进行加权)。结果如下
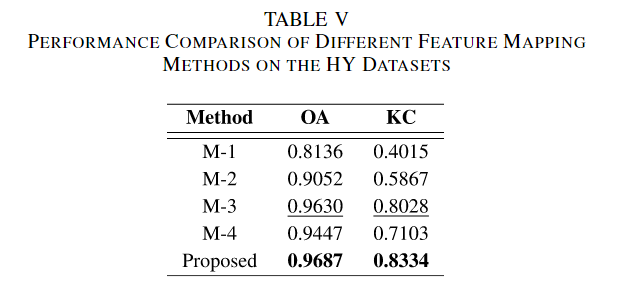
在原始特征图中执行聚类算法M1是无效的,KC仅为0.4015,进行了特征加权后的M2提升了46%为0.5867,只留下两个通道的M3的KC为0.8028,反而比没有特征值加权的M4好,这表明了M4的平等对待所有通道是显然存在问题的,相比于M3可以视作把第一和第二通道平等分而其他通道不分,充分的说明了考虑通道的信息占比是十分重要的,证明了WFD在多类CD中的优越性。
FM携带有关变化是否存在的信息,WFD表示发生了什么样的变化。
MetaChanger-2023-TGRS
Changer_Feature_Interaction_is_What_You_Need_for_Change_Detection-TGRS-2023
一种前期交互后期融合进行二/多值变化检测的网络架构。
提出的原因
①本文认为变化检测中,双时相的特征交互十分重要,而之前的特征交互的研究不够有效。
变化检测的两种方法
基于度量的方法:将两个时相的数据(图像/点云)转化到一个特征空间中,最终通过特征距离度量得到变化图,后面通常使用传统算法得到最终的变化检测图。
基于分类的方法:将变化检测视为一个密集的分类任务,特征在某一个阶段融合后通过网络的分类器生成最终的变化图。
网络架构
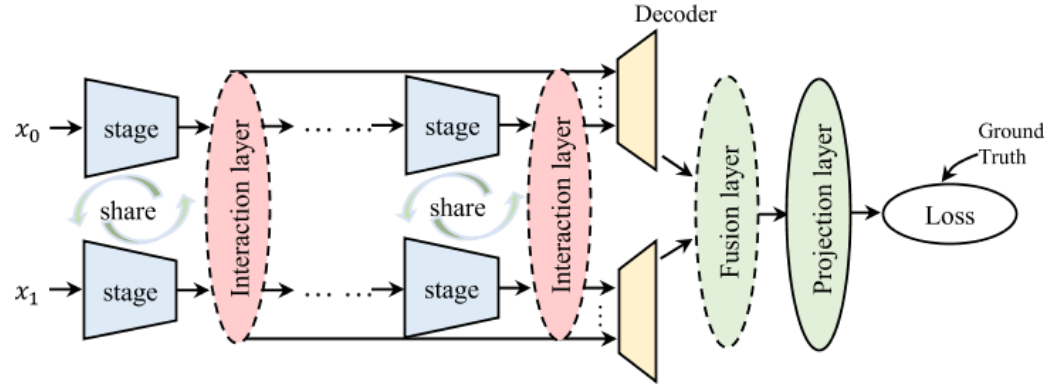
本文主要提出了一种基于分类的方法的框架MetaChanger,首先进行特征交互,对最终的特征图进行特征融合后利用聚合投影得到最终的结果。
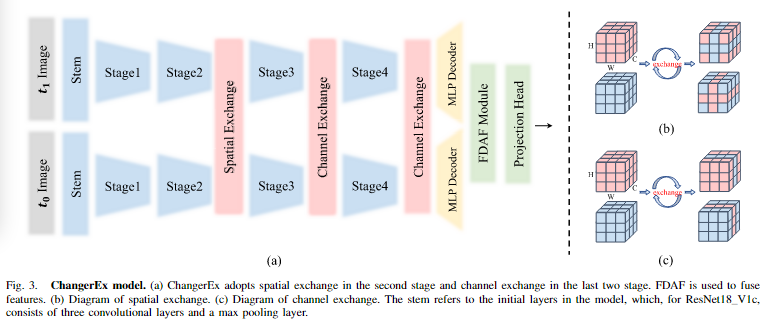
本文认为简单的交互和融合模块就能够达到一个好的性能,因此使用了AD和EX两个特征交互简单的网络和FDAF特征融合的网络。
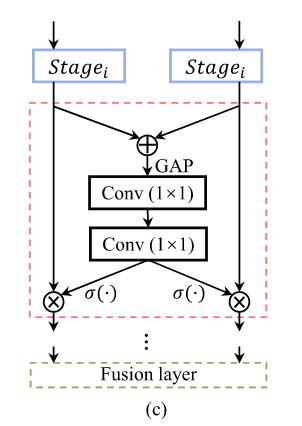
对于AD,首先将两个图特征求和,然后进行全局平均池化后,利用MLP将元素从C到2C,我认为后面是拆分成C,C后给两个特征图逐通道进行注意力机制。
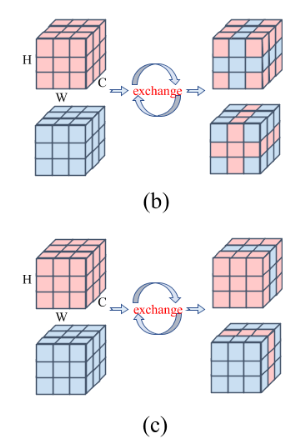
对于EX,通过掩码机制进行特征的交换达到特征交互的目的,包括空间以及通道的,对于空间来说,所有通道下的该处的行和列都要换成另一特征的,对于通道来说,该通道下的所有都要换成另一特征的。
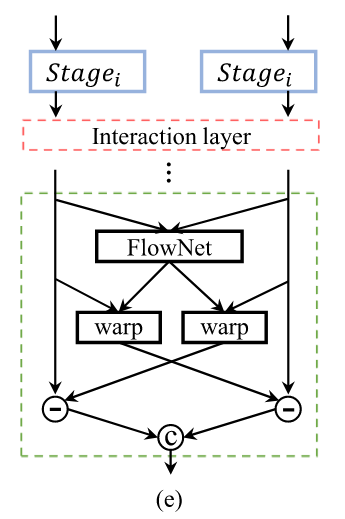
对于FDAF来说 ,将x0和x1拼接后,利用FlowNet得到输出偏移值后,重新进行对准并计算特征差值并拼接作为输出。

实验方法
数据集
S2Looking,包括了5000个图像对(1024*1024,7:1:2用于训练/评估和测试)以及65920个变化注释实力。分辨率为0.5-0.8m
EVIR-CD数据集包含了637个双世泰RS图像对和超过31333个注释的变化实力,1024*1024,分辨率为0.5m,7:1:2。
设置
CE损失和AdamW优化器,权重衰减为0.05,初始学习率为0.001.
评价指标
F1:2Pre*Re/(Pre+Re)
对比方法
FC-EF/FC-Siam-Conc/FC-Siam-Diff、DTCDSCN、STANet、CDNet、BiT、IFN、ChangeFormer、SNUNet,其中FC系列均为基于分类的UNet类模型,EF在早期融合,直接拼接双时相特征,SiamConc和Siam-Diff使用Siamese网络,分别采用拼接和差分进行特征融合。DTCNSCN是一个多任务模型,同时完成变化检测和语义分割任务,通过引入双注意力模块来利用通道和空间位置之间的相互依赖性用于改进特征表示,STANet旨在探索变化检测的时空关系,其中包括了一个权重共享的CNN特征提取器STANetBase,通过度量方法对模型进行优化,BAMand和PAM在Base的基础上配备了基本的时空注意模块(如自注意力机制)和金字塔时空注意力模块,CDNet是一个精调的Siamese CNN模型用于变化检测,通过实例级数据增强(裁剪建筑物移到另一图像中/放缩旋转/改变颜色纹理等/利用GAN生成新的建筑物实例)用于特征的训练,Bit在千层使用卷积块,在深层使用transformer,包括了交叉注意力等,可以有效地在时空域中对上下文进行建模,IFN在宏观层面上延续了FC-Siam-Conc的设计,在微观层面上采用了更复杂的骨干、关注机制,并在解码器中增加了多个辅助头进行深度监督,加快了模型的收敛速度。,ChangeFormer在连体网络中结合了分层变压器编码器和MLP解码器,以有效地呈现远程细节,SNUNet是一个嵌套的U-Net[24]结构。该算法在连体编码器和多个子解码器之间使用密集的跳跃连接,以减轻深度解码器层中空间位置信息的丢失。
实验结果
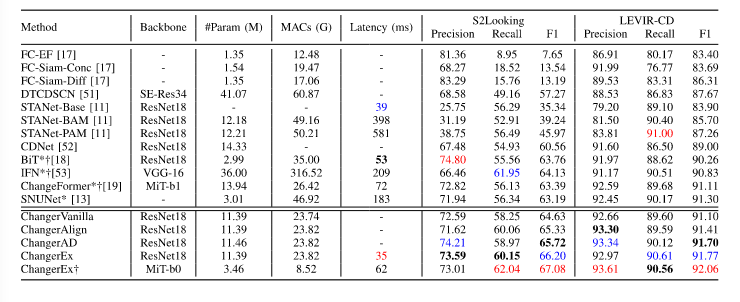
可以看到,仅仅是用最为简单的Vanilla方法也能萌购取得比之前的变化检测方法更好的结果,而使用FDAF的aligent在F1分数上有了提升,AD和EX在特征提取过程中进行特征交互,相比于FDAF来说,在计算成本和参数仅发生了轻微的增加下得到了显著的改进。而且尽管ChangerEx有着比BiT和SNUNet多的参数以及比ChangeFormerb1多的乘加操作,但是却具有着最快的推理速度。

通过可视化可以清楚的看见,在存在小目标的场景中,与其他模型相比,ChangerEx不仅更好地检测了小尺寸的变化区域,而且在细节和边缘上的表现也更好。这在图5的(a)、(b)和(e)中有所显示。在存在密集目标的场景中,如图5(d)所示,ChangerEx能够更好地分离建筑实例,即ChangerEx分割出的区域的边缘更为精细,这有助于后处理变化实例。在图5(g)中,ChangerEx在相邻建筑中出现“消失”和“出现”的场景中表现出优势,这与特征交换在理论上所能实现的是一致的。SNUNet在性能上仅次于ChangerEx,但在变化区域的连接处仍有未检测到的像素。与LEVIR-CD数据集相比,S2Looking数据集的双时相图像之间的风格差异更大。使用特征交换后,双时相分支之间的特征分布更为接近,从而在一定程度上实现了双时相域之间的领域适应,这使得更容易检测到变化。因此,ChangerEx在S2Looking数据集上的改进更为显著。
消融实验
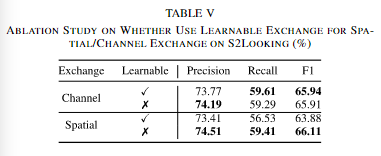
①在什么阶段插入特征交互层
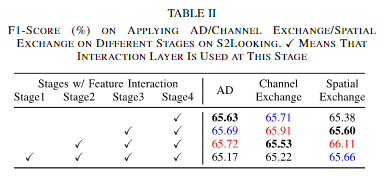
本文在不同的阶段插入包括AD和信道/空间交换在内的交互层。如上表所示,在后三个阶段插入AD层可以获得最佳性能,而在第一个阶段插入交互层会降低性能。在通道交换中也出现了类似的情况,只有在后两个阶段使用交互层才能获得最佳效果。然而,在空间交换中,情况有所不同,最好的两种设置在早期阶段相互作用,如上表所示。本文认为是因为在网络的浅层中,存在较高的空间分辨率和较低的通道维数,更适合空间交互,而在深层中,空间分辨率较低,通道数上升,因此适合交换通道。在此基础上,我们对ChangerEx进行了浅层空间交换和深层通道交换,如图3(a)所示。在ResNet-18中,Stem为一个卷积层,一个归一化层,一个ReLu函数和一个最大池化层,每一个Stage都是包括了两个残差块,每一块通道数随stage向后×2。
②特征交换的比例
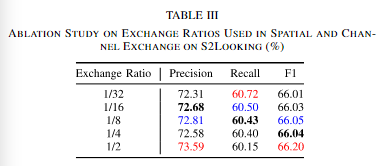
本文认为在各个比例下的性能改变不大,主要是是否发生了交换。
③空间交换中的窗口大小
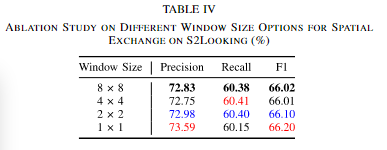
同样和比例一样,性能改变不大,这意味着小的空间结构发生破坏时,模型的性能并不会有太大的影响。
④基于学习的交换
具体的执行策略:
产生软注意力图,然后通过两个分支的软注意力图之间的距离生成交换图,较小的一半被交换,较大的一半被保留。在通道方面略有改善,但是在空间方面大幅度降低。
⑤使用更复杂的backbones在MetaChanger中
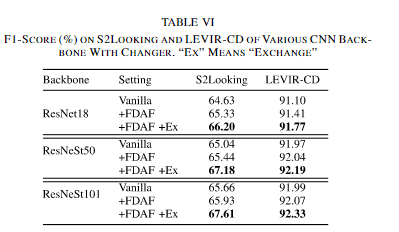
xi昂比喻复杂的ResNet18/ResNets50/101都有着性能的提升,这说明了ChangerEx的可扩展性是很强的,并且能够为大规模数据集中的复杂模型提供更高的增益,这是有前景的。明确地使用ResNeSt101的ChangerEx可获得1.68%的性能提升(F1得分为67.61%)。
⑥为什么交换工作是有效的

使用grad-CAM可视化带特征交换(with exchange)和不带特征交换(no exchange)的Changer模型。由上图可见,t0时刻上半部分大多数建筑在t1时刻消失了。在没有交换的情况下,t0时刻的热力图只有极少的建筑区域被激活。使用特征交换后,t0时刻的情况有所改善但大体相似。但是有趣的是,在特征交换的情况下,t0中存在建筑的区域在t1的热力图中被激活了。也就是说,t0中存在但t1中消失的感知目标,通过特征交换又在t1中被重新激活了。这解释了为什么特征交换可以提高变化检测的效果,重新激活了消失的区域。
本文提到的另一种解释是特征交换增加了样本的多样性,实现了一种网络内的数据增强。在双时相特征中,感兴趣目标的出现和消失顺序被打乱了,但是严格的语义保持和语义对应关系仍然被保证,也就是说,特征交换通过交换目标在双时相特征中出现的顺序,增强了特征的多样性,但由于保证了语义一致性,不会引入无意义的噪声,有效实现了数据增强。
BDNN-2020-TNNLS
Bipartite_Differential_Neural_Network_for_Unsupervised_Image_Change_Detection-ITNNLS-2020
一种通过在原图中添加Mask然后利用网络产生最终一致的特征,迫使Mask能够不断迭代得到最终Mask能够正确表达二值变化检测图的网络。
变化检测中的方法
基于像素的方法,利用共配准后的图像之间的像素差异来变化检测。比如使用颜色信息/时空二值特征,高光谱图像中的光谱信息。但是由于空间分辨率的不同和传感器的不同,一种新的方法——通过将图像转换到另一个图像的域中(代指风格/分辨率等),除了客观发生改变的区域外,其他区域尽可能相同。依赖于精确的配准,但是由于视角的问题,可能很难将两个图像完全对准。
基于对象的方法,首先通过无监督图像分割或者有监督图像分类寻找图中对象后,进行图像比较计算变化检测。依赖于图像分割或者分类的性能。
一些其他方法,如提取关键点,并构建加权图,然后在加权图的支持下测量变化程度;使用迭代特征映射网络检测多个变化。
这些问题也是本文提出的原因。本文提出的基于新型二分差分神经网络(BDNN)的无监督图像变化检测方法,该方法对图像配准误差不太敏感,也不涉及图像分割或分类。
对比散度算法
这是用于解决RBM(受限波尔兹曼机)中对数似然函数中计算量大的情况的一种方法,在RBM中,对模型参数求导后,最终的梯度中包含着一项需要计算2^n+m计算量的算式,对于这一项,通过Gibbs进行采样得到最终梯度的近似解,然后不断迭代,直到最终达到平衡,但是这仍然需要很多的计算量,因此提出了对比散度算法。由来如下,首先计算p0和p∞的散度,经过一次迭代后p1和p∞的散度,而对比散度认为模型参数如果能够使的p0和p∞的散度和p1和p∞的散度差尽可能的小,就能够说明已经达到了平衡,

也就是说让下式尽可能小,而后项在hinton论文中认为值很小可以省略,因此最终结果就是前两项,也就是说模型的梯度超这个去取就能够一步收敛。
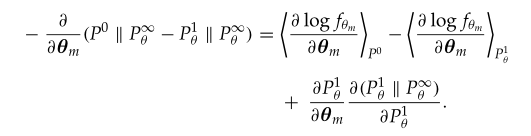
引用:深度学习 — 受限玻尔兹曼机详解(RBM)_rbm初始化-CSDN博客、机器学习工具(一)RBM - 知乎 (zhihu.com)
网络架构
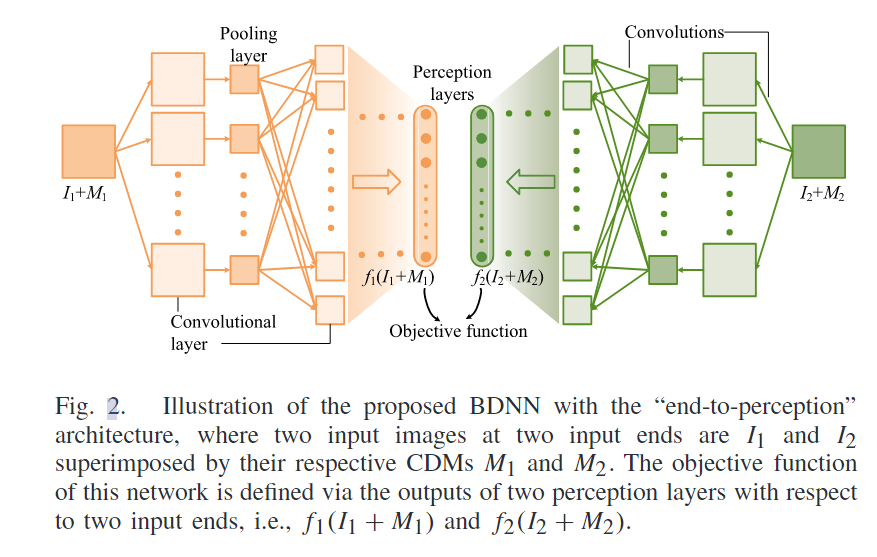
首先对双时相数据中图像I添加一个mask M,然后希望得到的X在经过了一层一层提取特征后,最终的特征能够和另一个特征尽可能相同,这表明这个mask能够完美的预测出变化的区域,然后以此作为变化检测的结果。每次的CDM都是通过迭代训练得到的,而不是应用之前训练得到的模型去产生的CDM。
在训练网络参数的时候,将CDM固定,然后训练网络参数,由于对数似然的损失函数,所以使用对比散度来进行梯度的估计,但是由于本文中的X均匀分布的效果实际会比较差,因此先均匀采样X得到X~后,对其关于高密度区域进行偏导,然后得到采样到高密度区域的X ~,采样到高密度区域的方法就是利用梯度下降法进行迭代,然后将X ~输入到网络中再次得到差异图,就能得到梯度进行网络更新。
在训练CDM参数的时候,把网络参数固定,然后M1和M2的第一项和网络参数一样,剩下的两项的损失函数很容易求。
然后重复固定这两个类型的参数交替训练,得到最终模型参数和CDM,然后输出CDM作为初始的变化检测结果。
由于图像的大小问题,导致深层的网络可能面临着梯度爆炸的问题,所以本文提出多尺度增量训练的方法,首先进行降采样,然后使用较浅的网络进行训练,之后使用稍微大点的图,在这个网络的基础上加深一点,不断增加,知道原始图的大小得到最终的网络参数,并迭代得到CDM。
同时,本文中如果存在未改变的图像对,可以通过这些图像对去进行预训练网络(设M1和M2=0),之后在包含了改变区域的图像对时,以这个预训练网络来初始化BDNN,然后进行微调和M1M2的学习。或者直接固定这个网络,只改变M1和M2去学习变化检测。如果没有训练样本的话,也可以直接在测试的时候随机初始化BDNN,然后反向传播调整得到M1和M2,类似于受限玻尔兹曼机。
损失函数
对数似然损失函数,用于让经过了网络后两个图像的特征尽可能相同。
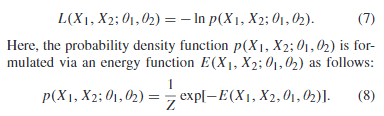
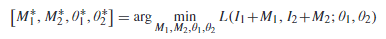
E即为D。
L2损失,尽可能让Mask小。
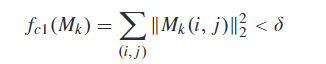
平滑损失函数,让Mask中的像素值变化平滑,不要存在那种噪声点。
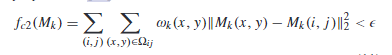
实验方法
本文实验了在共配图像对上以及未配准的图像对上进行实验并比较其他的方法,验证BDNN的优越性
数据集
Bern:遥感二号卫星在1999年4/5月再瑞士伯尔尼市的双时相图像。

Mexico:2000年4月和2002年5月再墨西哥的双时相图像,主要变化在于墨西哥城郊区的植被遭到了火灾的破坏。

这两个数据集是由同一设备进行拍摄,因此属于同构配准图像对。
Yellow River:由光学和雷达传感器分别捕获的异构配准两幅图像,在黄河流域中的一块农田,2008年6月/2021年9月。

第四第五个数据集是由无人机拍摄,包含了街道上车辆的变化,由于无人机的缘故,得到的图像有着不同的视图位置和角度,很难进行共配准。

第六第七个数据集是从谷歌地球免费获取的高分辨率遥感图像,没有预处理的步骤,包含了西电和西北工业大学的建筑变化

最后一个数据集包含了6个相同场景的图像,同一设备拍摄的,将a-e和f配对,生成5对图像进行变化检测,主要用于研究不同视角下的BDNN的敏感度。a=e,bd左右稍微旋转,ce左右较大幅度旋转。

对比方法
基于像素:Log-ratio方法(D(x,y)=log(I1(x,y)/I2(x,y)))和mean-ratio(D(x,y)=2[I1(x,y)-I2(x,y)]/(I1(x,y)+I2(x,y)))方法进行差异图的生成,小波融合的方法。
基于对象:使用地形分类和超像素分割进行分割,然后提取特征对区域进行对齐并比较。如果差异变化大,则意味着发生了改变,比如X中的A在Y中找不到了对应的B了,就说明改变了,或者A对应的B需要进行移动,旋转的,改变的幅度大,也说明改变了。
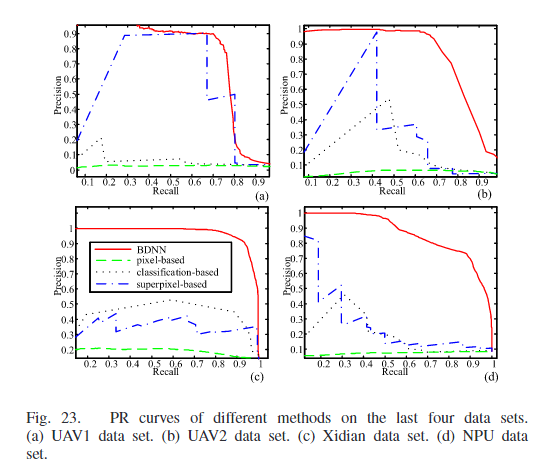
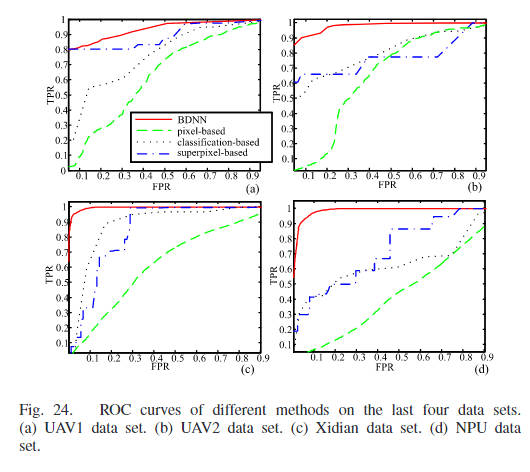
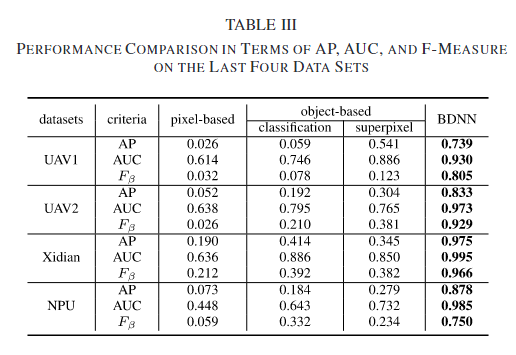
评价指标
PR曲线(pre-recall)、AP(平均精确度)、ROC曲线、AUC面积、F-measur= ( 1 + β 2 ) p r e c i s i o n ∗ r e c a l l β 2 ∗ p r e c i s i o n + r e c a l l \frac{(1+\beta^2)precision*recall}{\beta^2*precision+recall} β2∗precision+recall(1+β2)precision∗recall
BDNN中卷积核大小为5*5,池化层采用2*2,共有7个卷积层和5个池化层,多尺度增量训练中,最小尺度的图像大小设置为32*32,初始学习率为0.1,λ=0.02,η=20,采样X1 ~和X2 ~时迭代10次。
实验结果
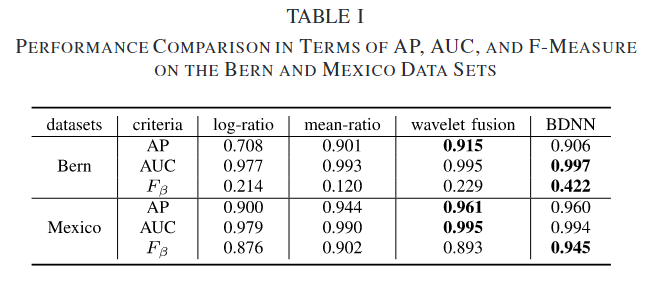
同构配准图像

Log-ratio运算符可以将乘性噪声转化为附加噪声(就是说噪声不是乘以像素,而是变成附加像素了),但变化区域并没有很好地突出显示。Mean-ratio运算符对变化区域表现良好,但对未变化区域表现不佳。小波融合方法被提出来获取互补信息,从而生成更好的差异图像。对于BDNN,由于时共配的图像且同质因此只需要使用浅层的网络(两个卷积一个池化),由于池化的存在,使网络对于位移方差有着鲁棒性,能够有效的减少错误匹配带来的虚假警报,可以看到在d图中的噪声点使很少的。定量结果如下。
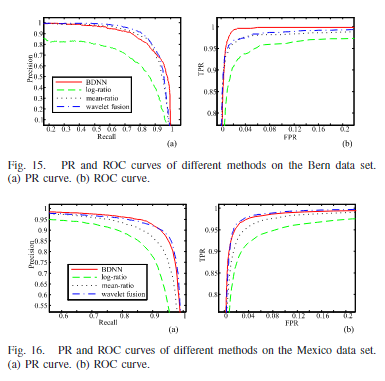
异构配准图像

通过变化检测图可以看到,在基于分类的方法中,由于SAR图像存在较强的散射噪声,这会造成图像分类/分割效果不佳。这些错误会导致同一目标被分割成多个区域,或者不同目标合并成一个区域。在变化检测时,这些错误分割的区域会被识别为变化,出现在差异图像中。在基于超体素的方法中,超像素分割考虑空间信息,可以生成轮廓清晰的区域。超像素试图将同一目标包含在一个区域内,减少分割错误。但是由于超体素的性质,导致最终的结果类似于一块一块的抹布。SCCN在像素上比较两幅图像,但是是将像素的局部特征转换成一致的特征空间,然后通过优化相对于网络参数的目标函数,可以突出显示改变的像素。相比于BDNN,不同之处在于BDNN比较全局特征(最后无需返回到全部图的大小)并产生CDM生成差异图像。SCCN是产生特征然后提取特征比较特征变化程度,BDNN是产生CDM,然后逼迫最终提取的特征变化小。定量结果如下。
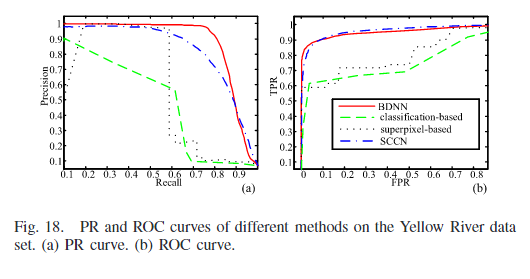
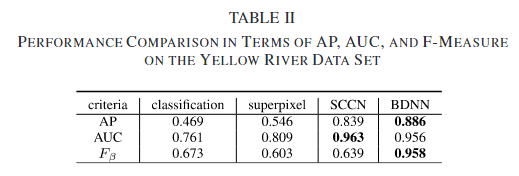
与BDNN相比,SCCN具有更高的AUC和更低的AP。这意味着SCCN不能很好地处理未改变的区域,如图17所示。BDNN在处理未变化区域方面表现良好,这意味着它能够准确地识别那些实际上没有发生变化的区域。虽然BDNN可能无法很好地保留变化区域的边缘,但它可以准确地突出显示这些区域。
同构未配准图像
挑战:从不同角度和视点拍摄的图像的变化检测更为困难,因为在这样的图像中,相应的对象可能位于不同的位置。基于像素的变化检测方法不适合这样的图像。

基于像素的方法对变化的区域不敏感。许多未对齐的区域被误检测,许多物体的边缘被突出显示。基于对象的方法适用于某些数据集。两幅图像中的目标可以通过无监督分类和超像素分割进行分割。无监督分类主要基于强度信息对目标进行分类。超像素将图像分割成许多没有覆盖的小块。斑块的边界附着在相邻物体的边缘上。然后,提取每个目标的特征并进行比较。由于比较是在对象级别,所以不需要对两幅图像进行严格的配准。所提出的BDNN方法对两幅图像进行全局比较,本质上对坐标系不一致不敏感。因此,在差分图像中可以抑制未改变的区域。通过定义CDM,可以突出显示已更改的区域。由于cdm直接添加到原始图像中,因此两个cdm可能会相互影响。因此,图21(f)中变化的区域不突出显示。然而,图21(g)中变化的区域被准确地检测到。定量结果如下。
BDNN通过一个由解决变更检测问题的模型驱动的双层体系结构来实现这个过程。从未配准的平面图像中准确识别变化区域比从共配准的平面图像中准确识别变化区域困难得多。因此,评价标准低于简单数据集,例如伯尔尼和墨西哥数据集。具体而言,在西电数据集上,本文提出的BDNN方法在未注册数据集上的准确率与传统方法在简单数据集上的准确率相当。因此,该方法能够避免由于不同的视图位置和角度而引起的误检测变化。
超参数灵敏度分析
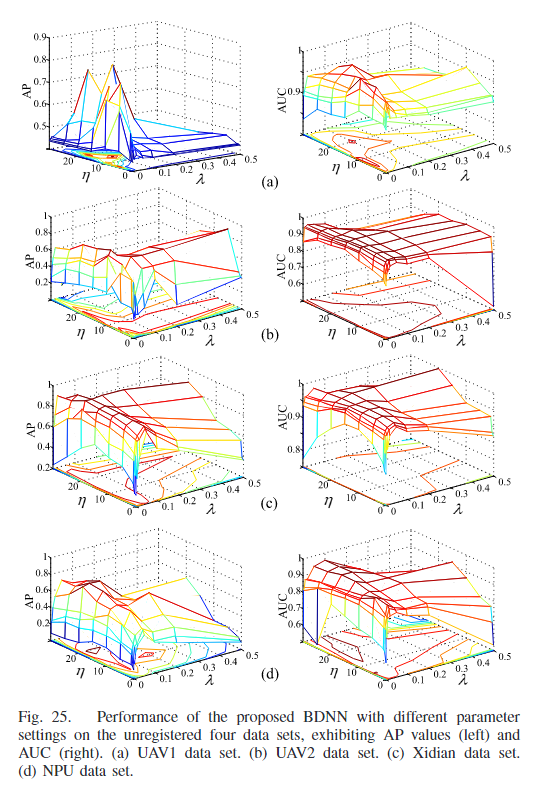
本文利用网格法进行在AP和AUC的指标上进行分析。λ = {0.001, 0.002, 0.005, 0.01, 0.02, 0.05, 0.1, 0.2, 0.5} andη = {0.1, 0.5, 1, 5, 10, 15, 20, 25, 30},对于AUC来说,对于超参数的没那么敏感,有着较宽的选择范围,但是从AP上看,由于变化区域和未变化区域[52]之间的倾斜,选择范围更窄,特别是对于UAV1数据集,其中变化区域远小于未变化区域。而且对于不同的数据集之间的两幅图像在视角、光照和属性等方面的差异也不同,因此最佳的参数设置也不同。但是对于这些数据集大体的趋势是类似的。从上述实验中可以看出,在λ和η设置相同的情况下,BDNN的性能明显优于传统的变化检测方法。
转换程度的敏感性分析
BDNN的网络架构存在一个默认的假设,变化的区域占比更少,如果这个假设被违背,性能可能会下降,本文利用不同左右旋转角度下的图像集进行测试,a,bd这三幅相比于f只有较小变化的视角,而ce有着相对较大的转换,可以看到abd的误差是小于使小于ce的,特别是c有着较大的误差。这表明了BDNN可以容忍一定范围内的变换,但是当变换程度变得相当大时,可能会遇到困难。因此可能需要进行预处理步骤降低至合适范围。

3DCDNet-2023-TGRS
An_End-to-End_Point-Based_Method_and_a_New_Dataset_for_Street-Level_Point_Cloud_Change_Detection-TGRS-2023
一种利用局部特征强化和自身特征强化得到优良的点云特征并在最终利用k近邻平均特征进行差异点云生成,进行点云二值变化检测的网络。
提出的原因
①现有的大多数方法都是通过将非结构化点云光栅化为另一个规则数据来实现3DCD任务,这不可避免地会导致信息丢失。
②由于点云是非结构化数据,因此很难从原始点中提取语义特征。这需要有意识地设计一种有效的方法来探索和嵌入三维点的语义信息。此外,如何从提取的语义特征中识别变化是另一个关键问题。
③街道级3DCD数据集的缺乏阻碍了街道级3D光盘算法的研究。大多数3DCD数据集都在遥感领域;街道级别的变化对象检测也需要更多的关注。
网络架构
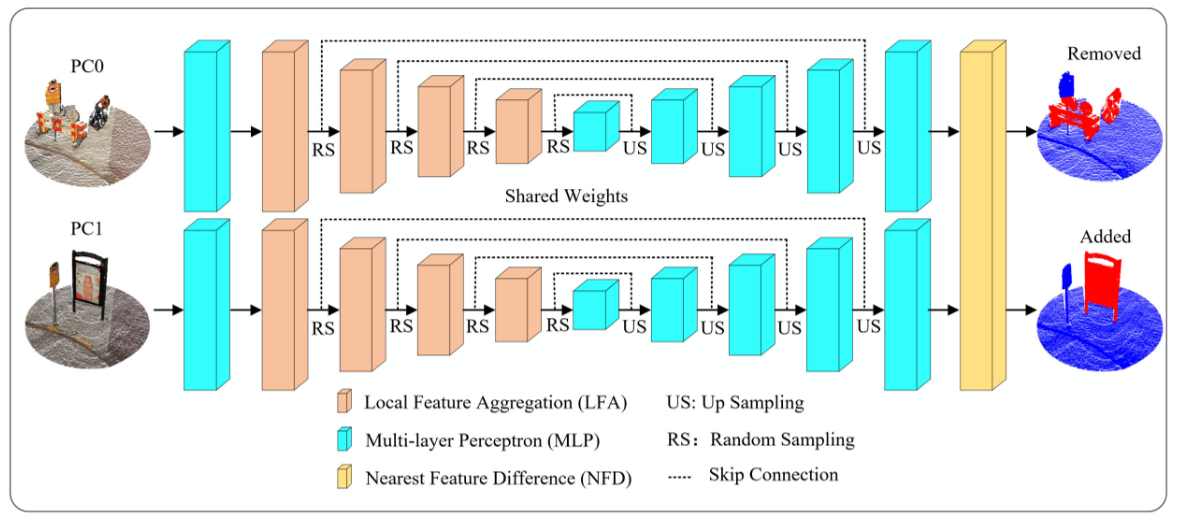
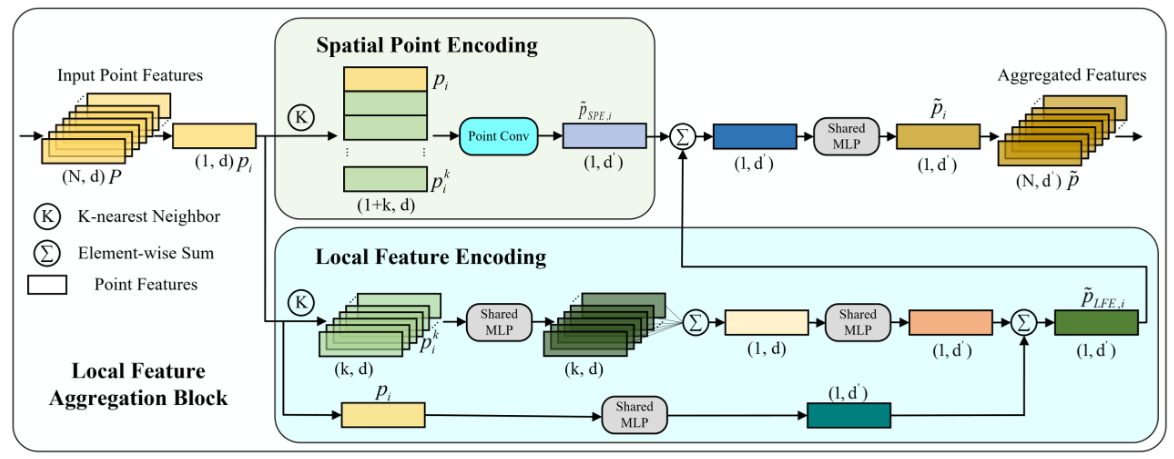
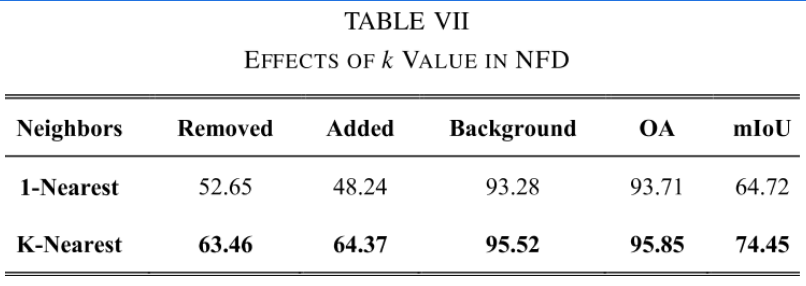
整体为UNet架构,在encoder层中使用LFA模块,decoder层中使用MLP,LFA模块分为两部分,一部分是利用周围的k近邻做卷积,得到局部空间特征;一部分聚合周围点的特征以及对自身进行MLP来增强中心点的表达能力。都是比较简单的模块。在最近邻特征差异NFD模块中,由于最近邻不一定正确,因此选择k近邻,并将他们的特征进行均值后计算特征差异点云然后进行分类投影。
实验方法
数据集
SLPCCD:本文提出的一个用于3DCD的街景数据集,从Change3D中进行注释得到,Change3D包含2016/2020年获得的彩色点云,包括了XYZRGB信息。共有621对样本,其中398/95/128。共计85219716个点
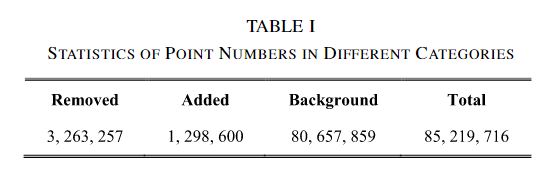
生成过程:①根据Change3D数据集中的标注的变化场景的中心点,在其周围提取一个xy平面半径为3m的圆柱体。②在两个点云的对应区域中比较数据的变化信息,并标注变化的对象。③包括Remove(删除的对象)和Added(新增的对象)。
扩展:Change3D是场景变化分类的数据集,包括了变化场景的大致中心位置。

实验设置
地面的点云中因为遮挡、不同的视角以及噪声导致不一致和不完整,而实际地面没有改变且在本数据集中不考虑地面场景,因此在输入网络之前,将高度低于0.5m的点视为地面点并进行删除。在输入网络之间,对点云数据进行下采样到8192个点,K值为16,使用adam,batchsize = 8,初始学习率为0.001,指数衰减,0.95,epoch=40,。
评价指标
OA、IoU、mIoU
实验结果
由于3DCD的方法较少,本文在自身的框架下,将LAF模块换成PointNet、PointNet++、PointMLP、PointConv、DGCNN等模块用于提取特征,然后用NFD模块上进行特征差异点云的计算后投影出最终结果。
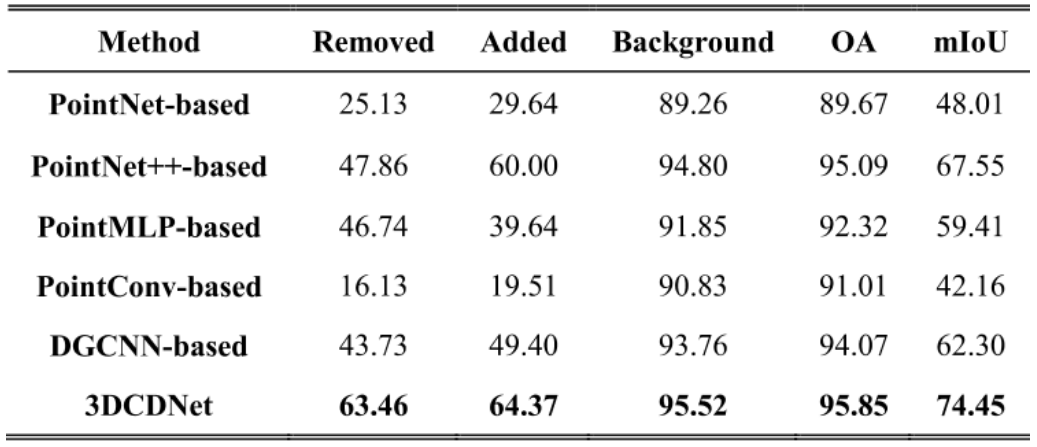
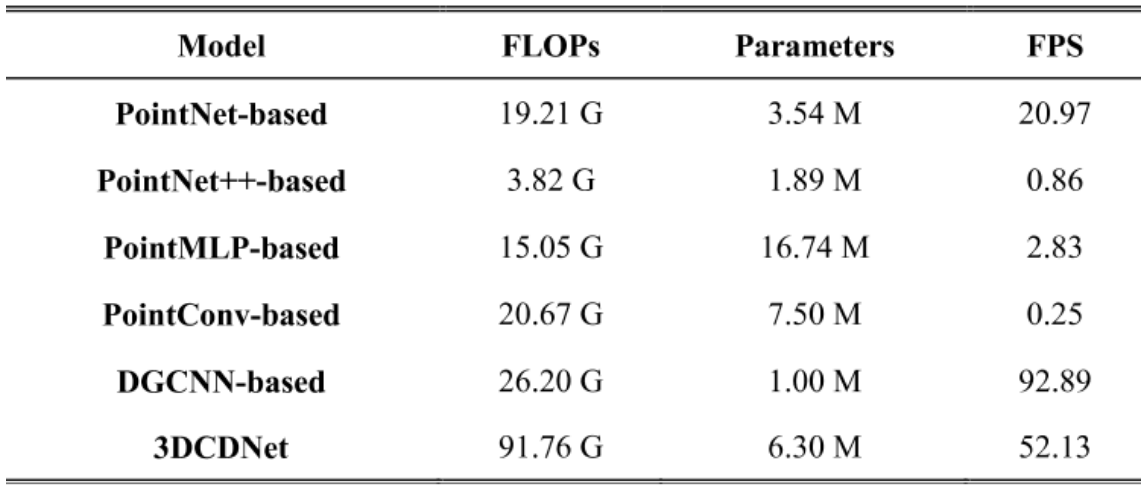
可以看到,在各方面3DCDNet都取得了最好的结果。同时在网络效率方面,虽然浮点运算为91.76G,但是网络的参数却只有6.3M,推理速度达到了52.13。

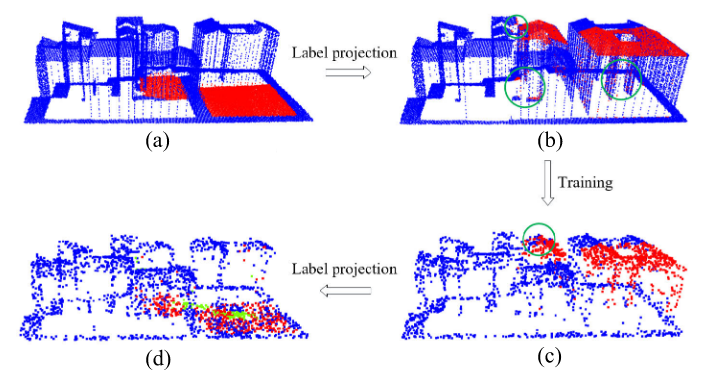
从判断的结果可以看到,3DCDNet基本上识别到了所有的变化的物体,对于第一对样本,PointNet-based和PointConv-based方法都未能正确检测到移除和添加的对象;PointMLP-based方法在建筑物墙面区域存在较多的误报;DGCNN-based方法只检测到了点云2016中的一个移除指示器;PointNet++和3DCDNet方法取得了最佳的检测结果。对于第二对样本,除了PointConv-based方法,其他方法都未能正确检测到灯柱上的移除警告牌;3DCDNet和PointNet-based方法在小型指示器的检测上表现出色,而PointMLP-based和PointConv-based方法存在较多误报。在第三对样本中,仅有提出的方法成功地检测到了移除的警告牌。第四和第五对样本的情景更加复杂,包含了多个变化对象,各种方法只能部分检测到变化对象。对于所有的方法,检测小变化对象的能力都很弱。在最后一对样本中,除了PointConv-based方法,2020年的点云中新增的物体被所有其他方法都遗漏了。
在Urb3DCD数据集上的补充实验
从真实城市的3D模型中模拟出来的城市点云数据集,精度达到了LoD2水平。根据分辨率、噪声和传感器的差异,Urb3DCD包括五个子数据集。特别地,子数据集1包含三个不同大小的训练数据集:大规模、正常规模和小规模。
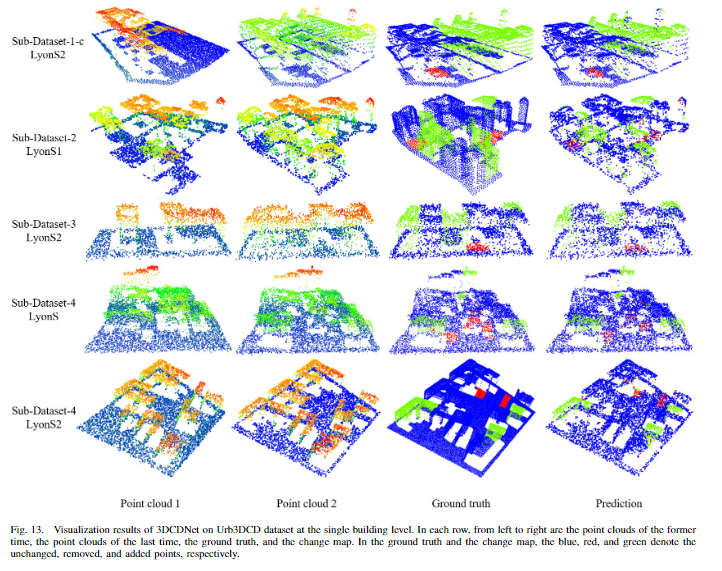
在Urb3DCD数据集中后期点云上标注的关于移除的标注投影到前期点云上以获得和SLPCCD数据集一样的数据,使用曼哈顿距离进行搜索投影。(a)标记了移除区域的点,最近邻搜索在前期点云是(b)图,有一部分投影出现问题(b)图中绿圈中的点,用于训练得到结果©新增了一部分检测点。(d)中漏检了一部分结果。
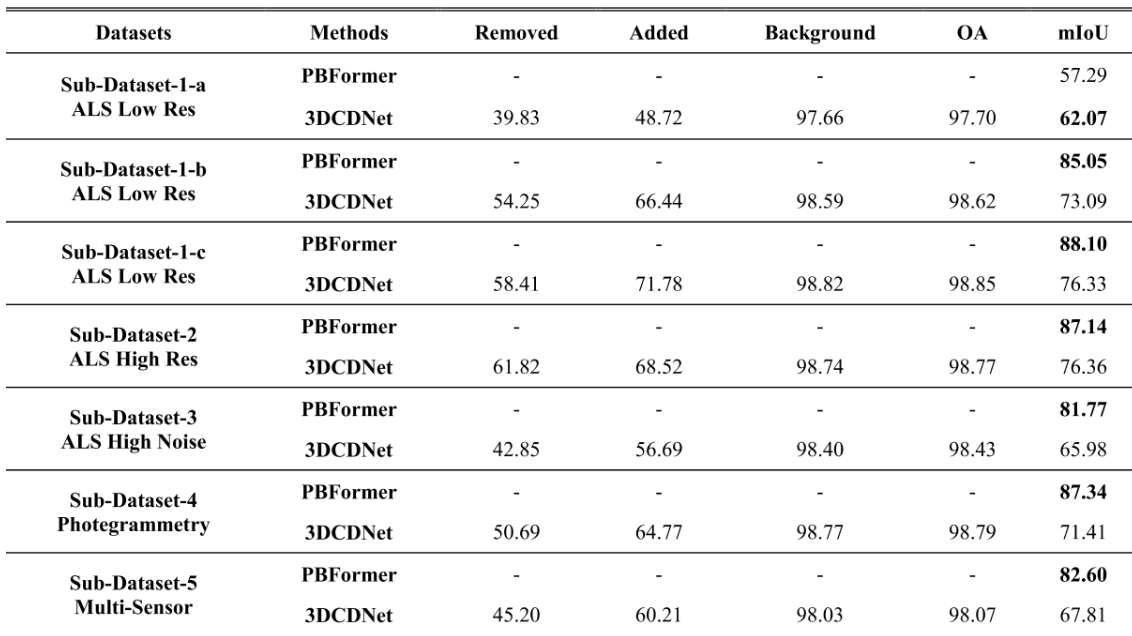
和PBFormer进行比较。几乎所有的mIoU都比PBFormer差。。。,在所有子数据集中,“添加”的IoU大于“删除”的IoU,这是因为为了能在Urb3DCD数据集使用3DCDNet,做的最近邻投影操作带来的不可避免的损失,而导致的性能差异,可以从可视化的最近邻搜索的过程看到问题所在。另一个性能差异点是在3DCDNet中存在下采样用于计算资源的节省,而PBFormer使用了Transformer。
随着数据集的规模的增加,性能也在不断增加,相比于小规模的数据集,中规模提升了11%的mIoU。再提升数量,性能的增加就不大了。
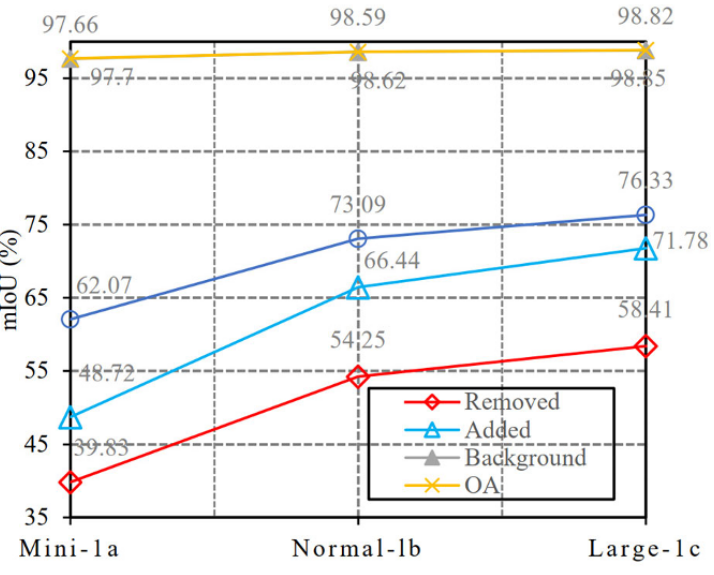
消融实验
①输入点的数量
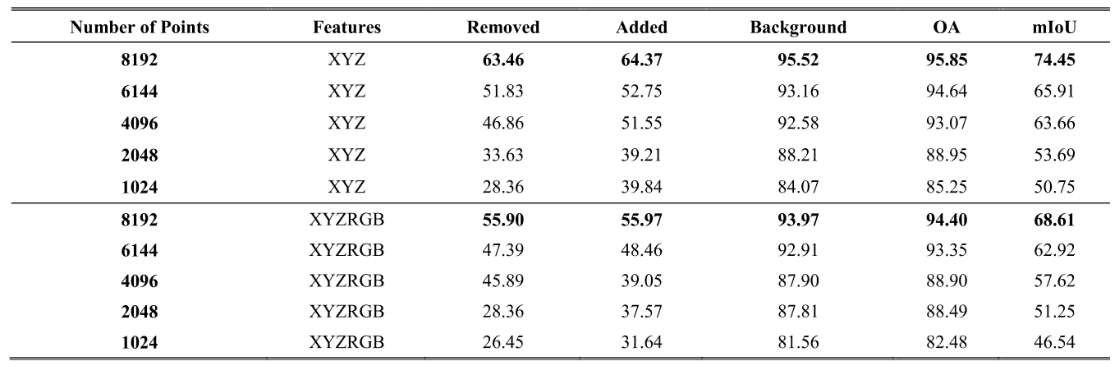
符合直观感觉,随着点数的增加,性能也在上升,但是对于相同的点数,只使用空间信息的性能却优于包含了颜色信息的性能。这是由于本文中关于变化的定义是结构性的变化才被检测,因此颜色的改变反而会误导网络做出错误的判断。
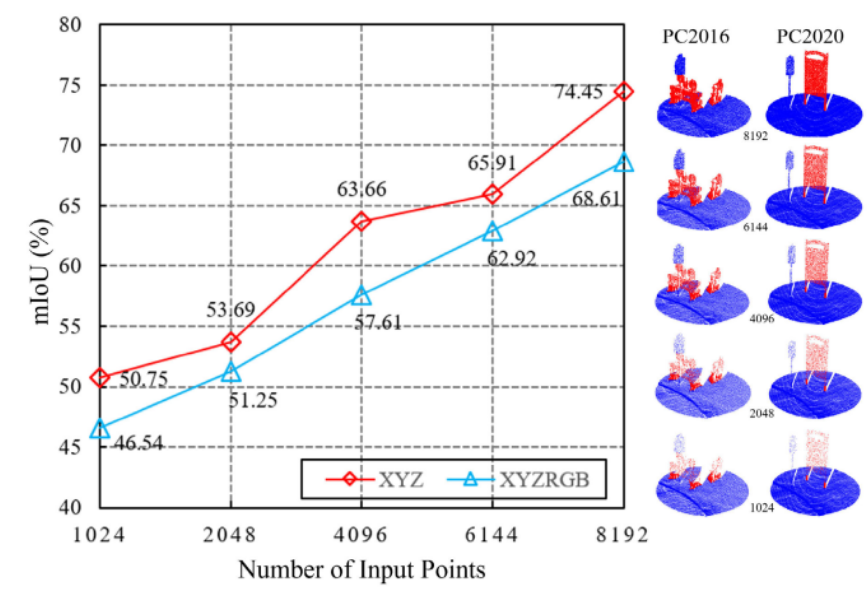
②LFA模块
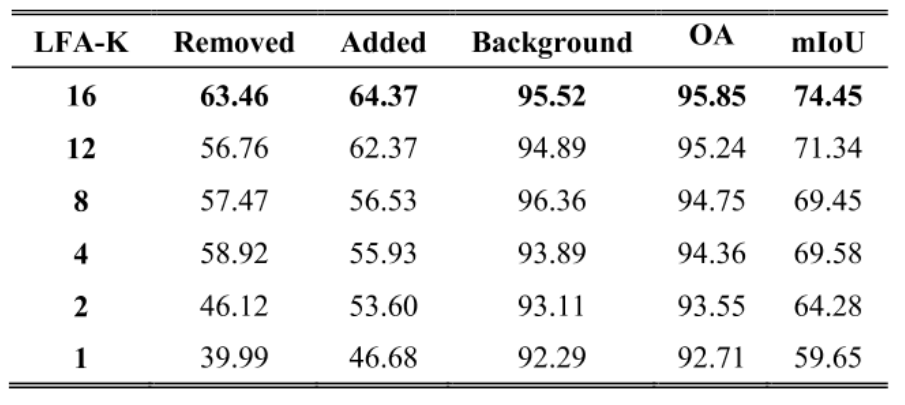
LFA中的k值:
如图,当k值为16的时候,获得了最佳的性能,说明了较大的视觉野能够使得网络的性能显著的提升。
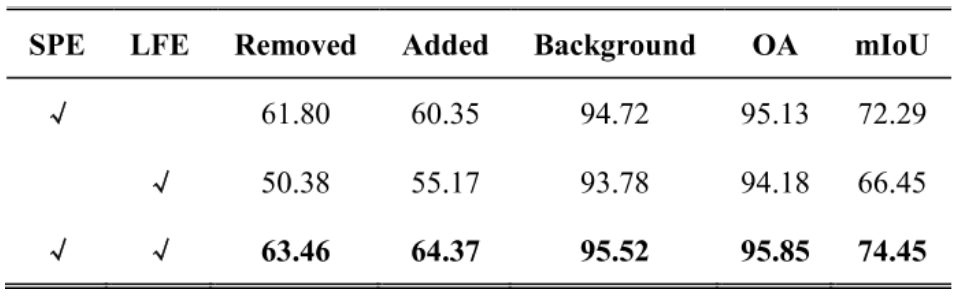
SPE和LFE的比较:
通过两个结构的消融实验,可以看到SPE是更加有效的。相比于LFE提升了6%的mIoU。当SPE和LFE都集成到LFA中时,模型的性能优于仅使用SPE或LFE。这证明了所提出的SPE和LFE对于特征聚合是有益的。
③NFD模块
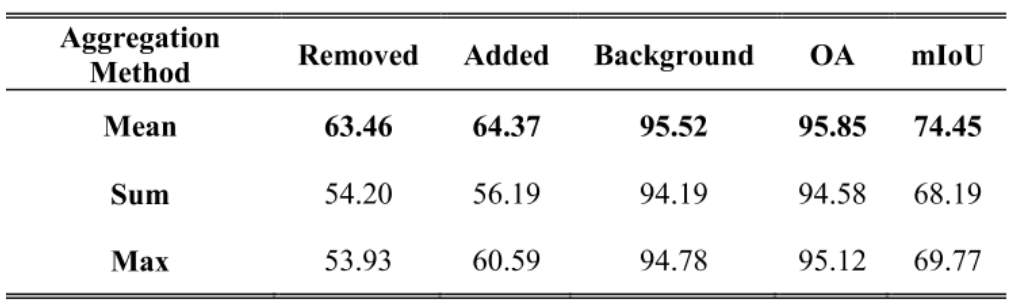
k近邻相比于最近邻来说,在mIoU上提升了10%、OA上提升了2%,这是因为相比于最近邻来说,k近邻能够降低次近邻才是对应点的这种问题的误差,因此性能有着较大的提升。在提出的NFD模块中,使用了其他的聚合方法进行比较。对于最大化、求和来说,平均取得了最好的效果,我认为是因为“求和比平均差是因为平均后权重之和为1才能达到和另一点云中特征一样的情况,否则权重为k过大导致效果很差,而网络如果对着Sum进行修正,也就导致了性能的下降。相比于Max来说也是更差的也是这个原因,因为Max最终也就是权重之和为1,而Sum的权重之和为k。这种情况在k越大会越显著。”
IFN-2020-IJPRS
A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images-2020-IJPRS
一种利用空间注意力和通道注意力串联并在decoder阶段不同尺度中进行监督的网络。
传统变化检测的方法
①基于算法的:直接在像素级别比较图像的像素值,生成图像差异图,然后利用阈值将像素进行划分,近年提出了一些基于机器学习的方法去区分对图像差异图进行划分。
②基于变换的:将像素映射到其他的空间,如比率变换、PCA变换又或者是神经网络变化,将原先的像素映射到了其他特征空间后再进行和基于像素的方法类似的操作。
③基于分类的:首先对图像进行分割,得到不同的对象,然后提取对象特征后,进行比较。比如对象的中心、对象的状态,然后在双时相图像中进行比较,得到变化检测图。
基于深度学习的变化检测的方法
①基于像素的:类似于传统中的基于变换的方法,但是使用的是深度神经网络去进行特征的转换。首先利用深度特征选择和猪像素比较生成差异图,然后采用基于阈值、聚类、变化向量分析方法对差异图进行变化像素的识别。
②基于对象的:首先进行图像分割(对象或者超体素),利用深度神经网络进行对象的特征提取,然后分析提取的特征(确定对应关系可以通过对象的中心进行最近邻去对应)之间的差异,并使用聚类或阈值分类。
为了克服以上两种方法不使用标注数据的缺点,引入了端到端的深度学习框架(摒弃了所有传统方法的应用),在处理双时相图像方面分为两类:在早期融合(不同时间点拍摄的图像被堆叠成一个多通道输入图像,如两个三通道的图像合并成六通道的图像,然后输入FCN)和晚期融合(首先分别提取两幅图像的特征,然后在网络后面的层中将这些特征结合起来啊,生成变化地图)
③基于深度特征的:以端到端的方式将原始图像特征提取和图像差异识别集成到fcn中。网络中的参数通过反向传播自动更新。经过一组训练周期后,对网络中的参数进行微调,使其具有检测变化的能力。
存在的问题
由于现有的框架是在单点云分割的基础上提出的。
①早期融合方法中存在的问题:早期融合的网络通过简单的将双时相图像拼接输入网络,而且最终会通过跳跃连接将低层特征和深层特征结合,导致了早期融合网络能提供有用的深层特征来帮助图像重建,导致生成的变化图中对象边界不清晰和对象内部紧凑性差。
②晚期融合方面存在的问题:网络的低层负责特征提取,深层负责差异识别,但是由于加上了差异识别模块,导致网络的加深,伴随着梯度消失的问题,最终低层的识别能力较差,获得的特征代表性较差,深层差异识别受到图像质量的影响生成的变化图的质量也差。
③d12为浅层的特征构成的能够代表着原始图像的变化差异,f1和f2代表着从图像中提取的深度特征,具有高度的语义信息,可以用于重建,但是无法直接用于差异识别,因此需要使用f1,f2和原始差异图d12结合起来,指导最终变化检测图的产生,如何设计结合的模块成为关键。
对于②提到的问题,本文使用预训练的DFEN网络权重去尝试缓解。
网络架构
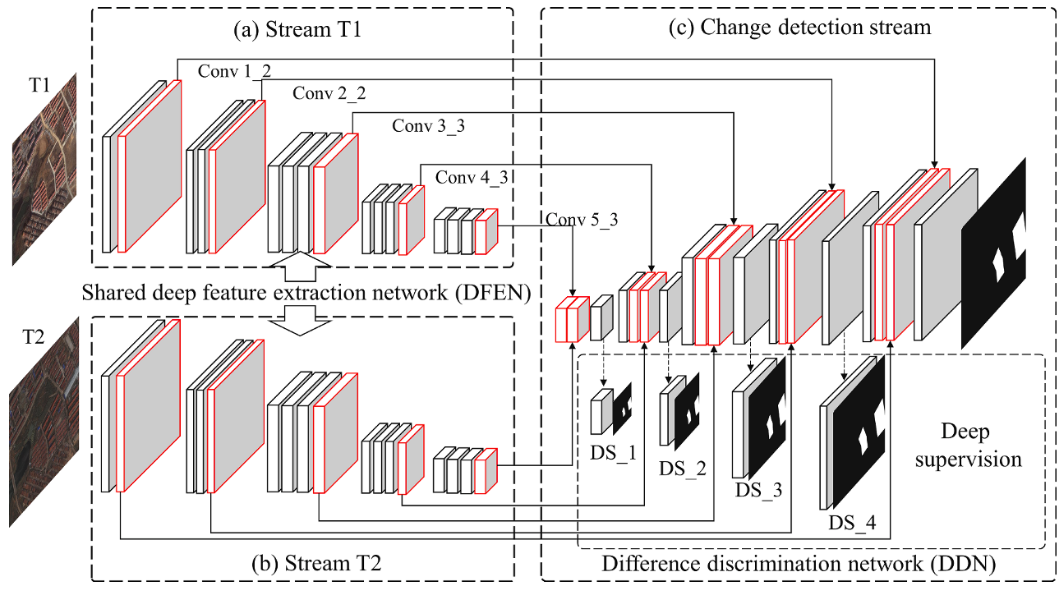
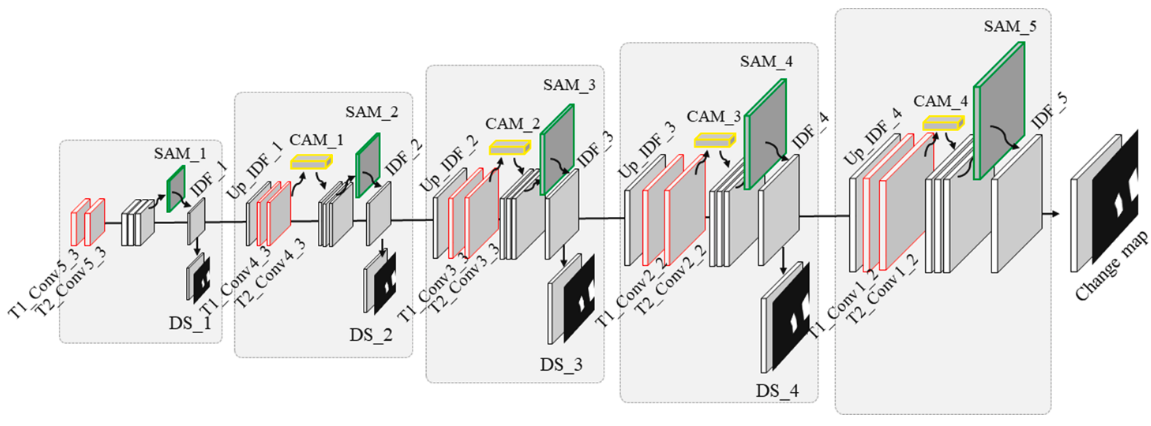
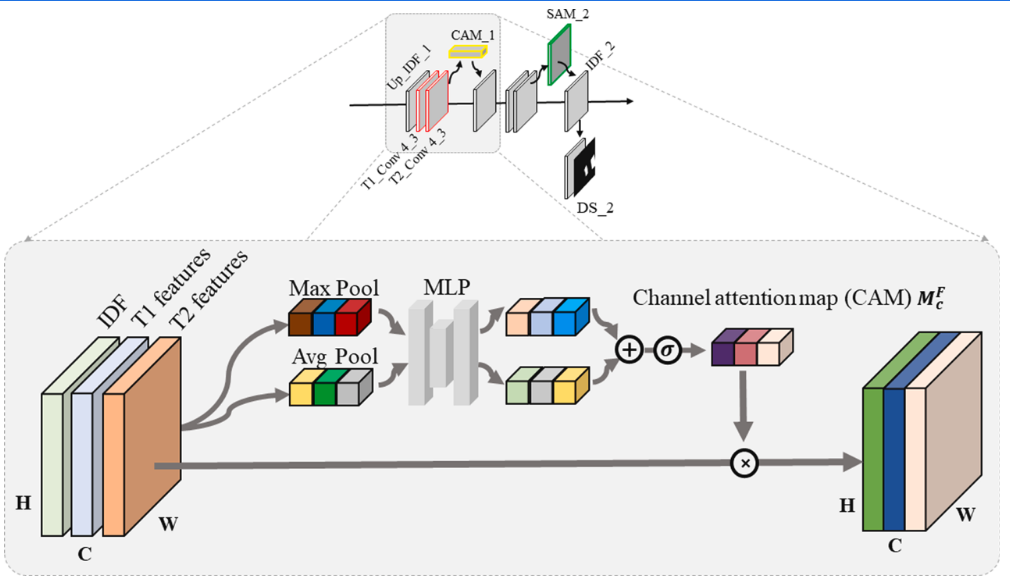
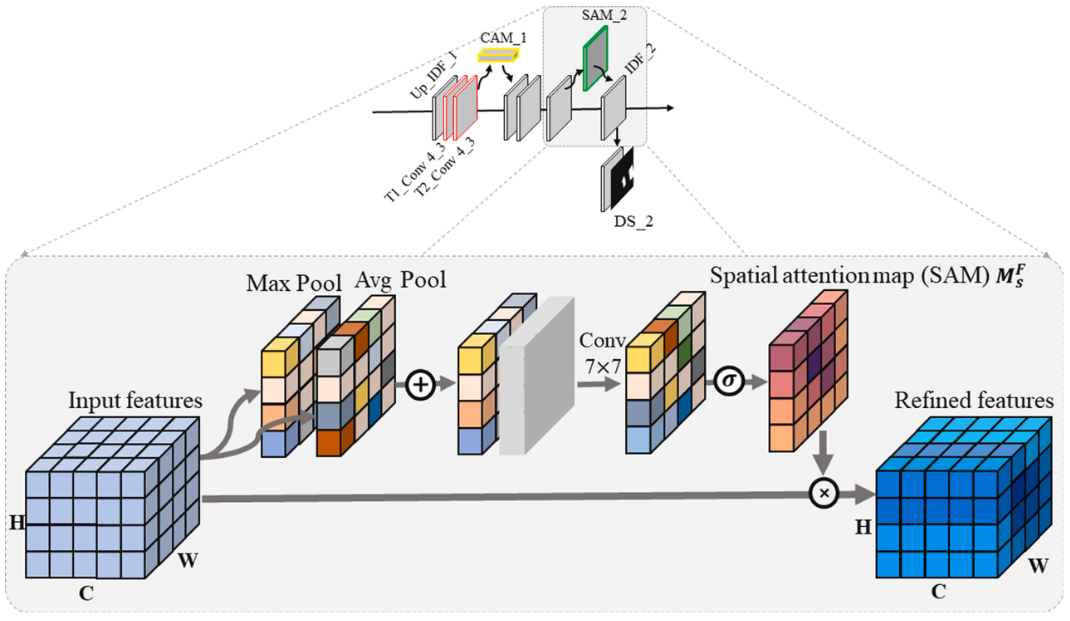
首先利用vgg16的pool5之前的网络作为DFEN的骨干网络,同时为了缓解梯度消失带来的训练缓慢,特征代表性不强的问题,使用了预训练的权重。提取了高度特征后输入到变化检测器中,一层一层对应还原到初始大小,同时通过跳跃层将低级特征传至对应层级中指导差异图的生成,由于在低级特征中会存在着图像特征不共域的情况(比如在提取的特征中,A和B中某个通道代表着当时的天气情况,可能两者有较大的差异),因此加入了一个通道注意力机制去缓解低级特征不共域的情况(用于强调与目标相关的通道,同时抑制与目标无关的通道),然后卷积以后再跟着使用一个空间注意力机制用于聚焦变化的区域。并在每一级进行差异图的监督训练。同时本文为了解决梯度消失的问题,还在每一层都输出特征差异图进行损失函数用于有效传播梯度。
实验方法
模型训练过程
数据增强:双时相图像对选择45/90/135/180/270°,图像翻转,加入椒盐噪声、利用高斯模糊滤波器产生模糊图像,图像平滑,后两个只针对前期图像。
对于DFEN使用imageNet数据集预训练后的VGG16,对于DDN的每一级的输出都使用sigmoid二值交叉熵损失函数去进行监督,但是由于类不平衡的原因,本文额外添加了一个筛子系数损失函数用于使网络模型直接专注于使预测的变化点和实际的变化点重合。
L = 1 − D = 1 − 2 ∣ Y ∩ T ∣ ∣ Y ∣ + ∣ T ∣ L=1-D=1-\frac{2|Y∩T|}{|Y|+|T|} L=1−D=1−∣Y∣+∣T∣2∣Y∩T∣,可以类比于IoU。
数据集
Lebedev、Google Earth手动收集的具有挑战性的数据集,不同于以往研究中使用相同区域的图像进行模型的训练和测试,这个数据集的目的是通过使用不同区域的图像来评估模型的泛化能力。训练集包含不同城市(北京、成都、深圳、重庆和武汉)的图像,这增加了区分变化区域和过滤由噪声引起的图像差异的难度。另一个城市(西安)的图像被用于测试模型,以此挑战模型的泛化能力。在模型训练阶段,北京、成都、深圳、重庆和武汉的双时相图像被切割成394对子图像,每对图像大小为512×512像素。经过数据增强,获得了3940对双时相图像。随机选择其中90%的数据用于模型训练,剩下的10%用于模型验证。西安的图像对被切割成48对,用于模型测试。
实验设置
所有卷积层中卷积核大小均为3*3,在拼接层之后,下一个卷积层的滤波器被设为特征通道数的一半,比如512+512的拼接后,就只设置512。在每一级的损失函数都是sigmoid二值交叉熵损失函数+筛子系数,共5级,权重相等。出事学习率为0.0001,如果5个周期损失不下降,学习率下降10%,20周期没有改变退出训练模型。
对比的方法
Unet++_MSOF(早期融合的模型)/FC-Siam-conc(第一个使用Siamase网络用于变化检测的方法)/FC-Siam-diff(在解码流中使用的是深度特征差异的绝对值)/FCN-PP(利用金字塔进行多尺度池化,增大视觉野)
实验结果
评价指标:Pre、Rec、F1、OA


可以看到,对于大面积的变化检测来说,IFN 能够成功地识别出变化区域,并保持完整的边界和高度的内部紧凑性。而对于小面积的变化检测,几乎所有小面积的变化对象都在变化地图中被区分出来。即使双时相图像 T1 和 T2 包含一些噪声,IFN 也能够成功地过滤掉这些噪声(比如由于季节变化掉落的树叶被识别为未发生变化的区域),并且变化地图准确显示了实际发生变化的像素。

从定量结果来看,充分的证实了上述结论,IFN以最高的 OA (97.71%)、P (94.96%) 和 F1 (0.930) 实现了最佳性能Unet++MSOF 的 R 最高,为 87.11%,略好于 IFN (R 86.08%)。一个可能的原因是存在一些图像噪声,影响了双时间图像之间的一些变化/未改变的对象。嵌入更改/未更改对象中的噪声将产生图像差异特征,其中更改/未更改的像素具有更高的值。因此,Unet++MSOF 检测到更多更改的像素。同时,由于缺乏从单个原始图像特征的指导,Unet++MSOF倾向于将更多不变的像素误分类为变化的像素,导致OA较低(89.54%)。与 FCN-PP、FC-Siam-conc 和 FC-Siam-diff 相比,IFN 在 P 和 F1 分数上都取得了显着的改进。与Unet ++_MSOF相比,IFN在P上增加了5.42%,F1增加了0.027。




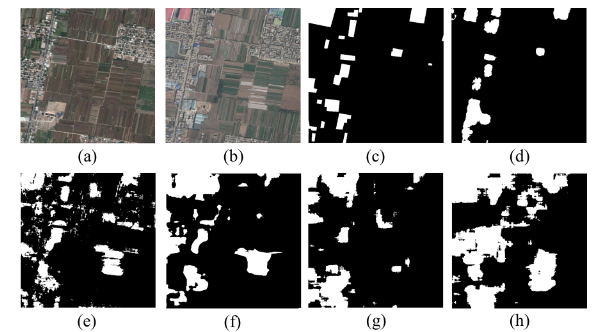
在更具挑战性的数据集上,IFN仍能获得最好的变化检测结果,它能够检测出完整的变化区域,并保持变化对象的内部紧凑性。与 IFN 相比,Unet++_MSOF 方法未能检测到某些变化区域,并且错误地将一些未变化的区域分类为变化区域。FCN-PP、FC-Siam-conc 和 FC-Siam-diff 这三种方法倾向于将更多未变化的像素错误分类为变化像素,导致生成的变化地图在对象紧凑性和边界精度上较差。对于较小的变化对象(如图9至11所示),尽管 IFN 未能检测出一些小变化对象,但它在与其他四种方法的比较中仍然表现最佳,这些方法生成的变化地图粗糙,并且有严重的椒盐噪声(即图像中随机分布的亮点和暗点)。
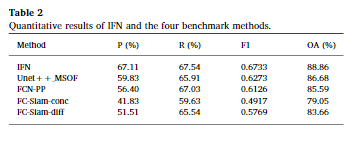
从上表的定量结果中,可以看到IFN在所有的指标上有着最好的表现。FC-Siam-conc 和 FC-Siam-diff 这两种方法在几个关键性能指标上表现最差,特别是精确度、F1分数和总体精度。这可能是因为用于提取原始图像特征和区分差异的孪生网络没有能够有效地代表深层次的原始图像特征,从而影响了变化区分的能力。Unet++_MSOF 和 FCN-PP 的表现优于FC-Siam-conc和FC-Siam-diff,但是由于它们采用的是早期融合策略(将两个时间点的图像直接连接为网络的单一输入),因此在网络的初始阶段就开始了图像差异的区分。尽管通过跳过连接(skip-connections)合并了中间特征图,但原始图像的深层特征几乎无法提供帮助进行图像重建。这就导致了由于深层原始图像特征的缺乏,导致变化图显示出断裂的对象边界和较差的对象内部紧凑性。
监督的有效性验证:
通过基于IFN的架构并逐渐减少损失函数的监督进行比较,从©图可以看到与其他四个网络相比,IFN的训练损失曲线以最快的速度下降。IFN 是最好的训练模型。此外,在(f)图中,IFN 的逐渐降低验证损失曲线达到最小值,证明了 IFN 具有出色的泛化能力。相比之下,IFN-DS_0 的模型收敛速度最慢,此外,IFN-DS_0 获得了最差的泛化能力,准确度最小,F1 分数如图 12d 和图 12e 所示。其他 3 个网络,即 IFNDS_1、IFN-DS_12 和 IFN-DS_123 的性能优于 IFN-DS_0。
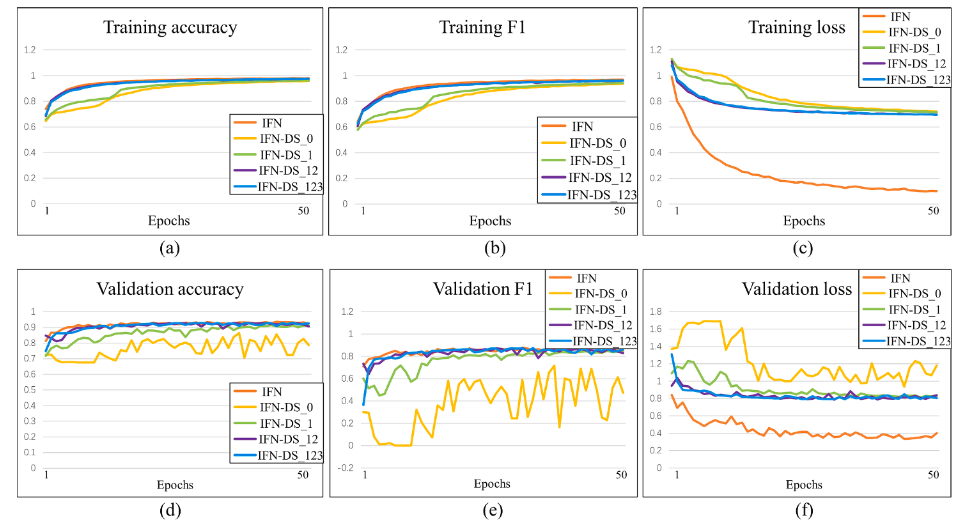
从生成的变化检测途中,也能清楚的发现,IFN-DS_0 生成了最差的变化地图(图13b和图14b),特征是碎裂的边界和较低的对象紧凑性。IFN 生成的变化地图(图13f和图14f)显示了更完整的对象边界和更高的内部紧凑性,这表明当网络中涉及更多深度监督分支时,变化检测性能得到改善。

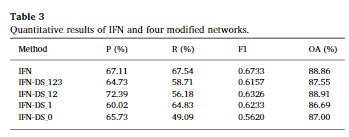
从定量数据中可以得到,IFN在F1分数(0.6733)和召回率R(67.54%)上都达到了最高。与此相对,IFN-DS_0的F1分数和R分数最低(分别为0.5620和49.09%)。IFN-DS_1、IFN-DS_12和IFN-DS_123在IFN-DS_0和IFN之间取得了中等水平的表现。IFN-DS_12获得了最高的整体准确率OA(88.91%),与IFN相当(OA 88.86%),但它的F1分数要低得多。
DTCDN-2021-IJPRS
A deep translation (GAN) based change detection network for optical and SAR remote sensing images-2021-IJPRS.pdf
一种通过图片域转换并利用UNet++改进的多尺度监督的网络。
提出的原因
①SAR图像不受光照和天气条件限制,可以全天时、全天候获得图像,但缺乏丰富的频谱信息,且容易受到析纹噪声的影响。
②光学图像具有更丰富的目标频谱信息,能够反映目标的光谱特征和几何形状,但易受大气条件影响。
基于异构图像的变化检测方法
① 参数方法,利用高斯分布或多元正态分布的混合来估计不同传感器图像之间的关系,通过求解这些参数来提取相关的变化指标。
②非参数方法,对图像对建立能量关系E(a,b),要求每个E(a,b)满足某个阈值要求,然后得到变化检测的结果。
③基于不变相似性度量的方法,具有高相似度的图像块会被标记为未变化的像素,相似度异常的值对应的是变化的像素。比如:对于图相对的同一位置,提取图像块,计算图像块的互信息作为相似度。
④基于分类的方法,首先对图像分割分类后比较各个块/类的结果。受到分割分类性能的影响。
⑤基于转换和投影的方法,其主要思想是将异构或多模态图像转换为相同的特征空间,使图像在CD任务中更具可比性。有两个主要子类别,包括传统的转换和基于深度学习的转换。机器学习和统计方法是具有代表性的传统变换,如齐次像素变换(HPT) (Liu et al. 2018b)、聚类分割和合并识别(Luppino et al. 2017)和基于分形投影和基于马尔可夫分割的方法(FPMSMCD) (Mignotte 2020)。最近出现了基于深度学习的转换。例如,对称卷积耦合网络 (SCCN) (Liu et al. 2018a)、条件生成对抗网络 (cGAN) (Niu et al. 2019)、X-Net 和 ACE-Net 方法使用循环对抗网络 (Luppino et al. 2020)。深度学习模型利用深度特征将图像从原始不同领域统一到同一领域,以方便比较。总的来说,由于泛化和解释简单,基于转换和投影的方法是异质CD的一个有前途的方向。
在生成图像后对图像的正确使用也是十分重要的,而之前的方法仍采用传统的差分和阈值分割的方法,而原始图像和生成图像的关系难以描述,导致变化检测的精度下降,而目前采取的深度学习的方法提取特征,并用于变化检测,得到了出色的性能。
网络架构
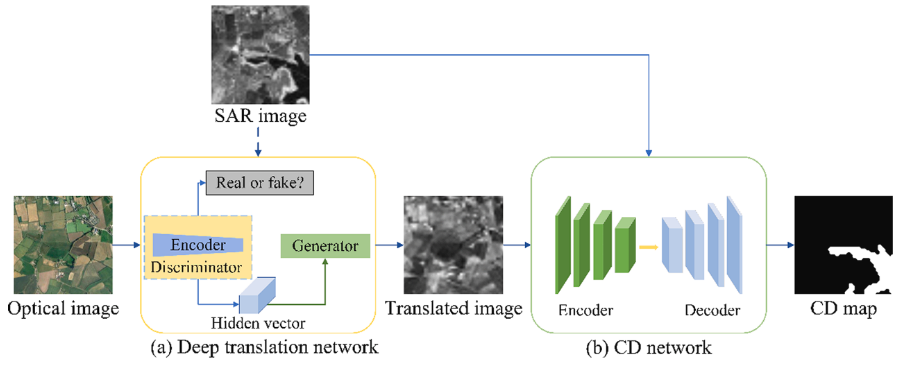
由于光学图像更具有纹理性等细微特征,因此从光学图像转换到SAR图像是简单点的,首先将光学图像通过深度转换网络,转换至SAR图像后,对于现在的SAR图像对运用同构CD网络生成变化检测图。
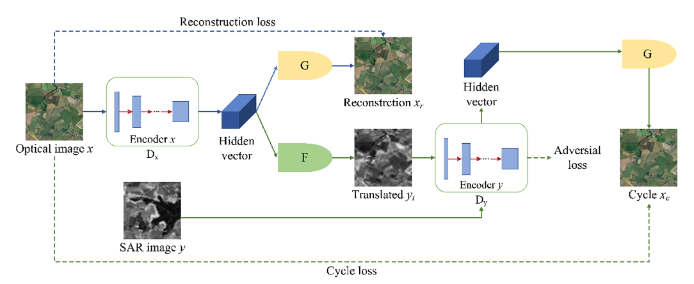
在深度变换网络中,首先将光学图像通过Encoder产生Hidden vector(同时判别器也会进行判别是否是生成的图像),一个分支用自身的生成器去重建光学图像,另一分支用SAR的生成器去重建SAR图像,重建了SAR图像,然后通过Encode产生Hidden vector(同时判别器也会进行判别是否是生成的图像),利用光学重建器重建光学图像。
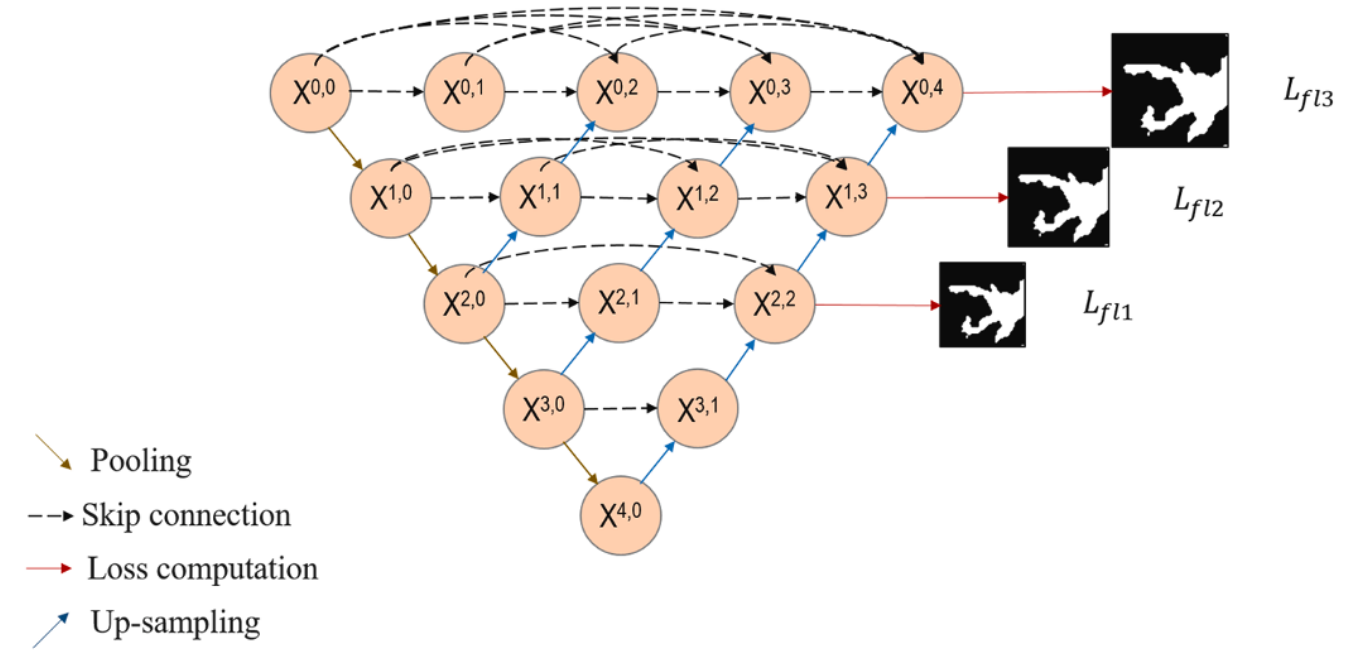
在变化检测网络当中,采用密集的UNet++网络,在所有下采样的结点中都采用上采样进行还原,同时还在每层都进行密集的跳跃连接。
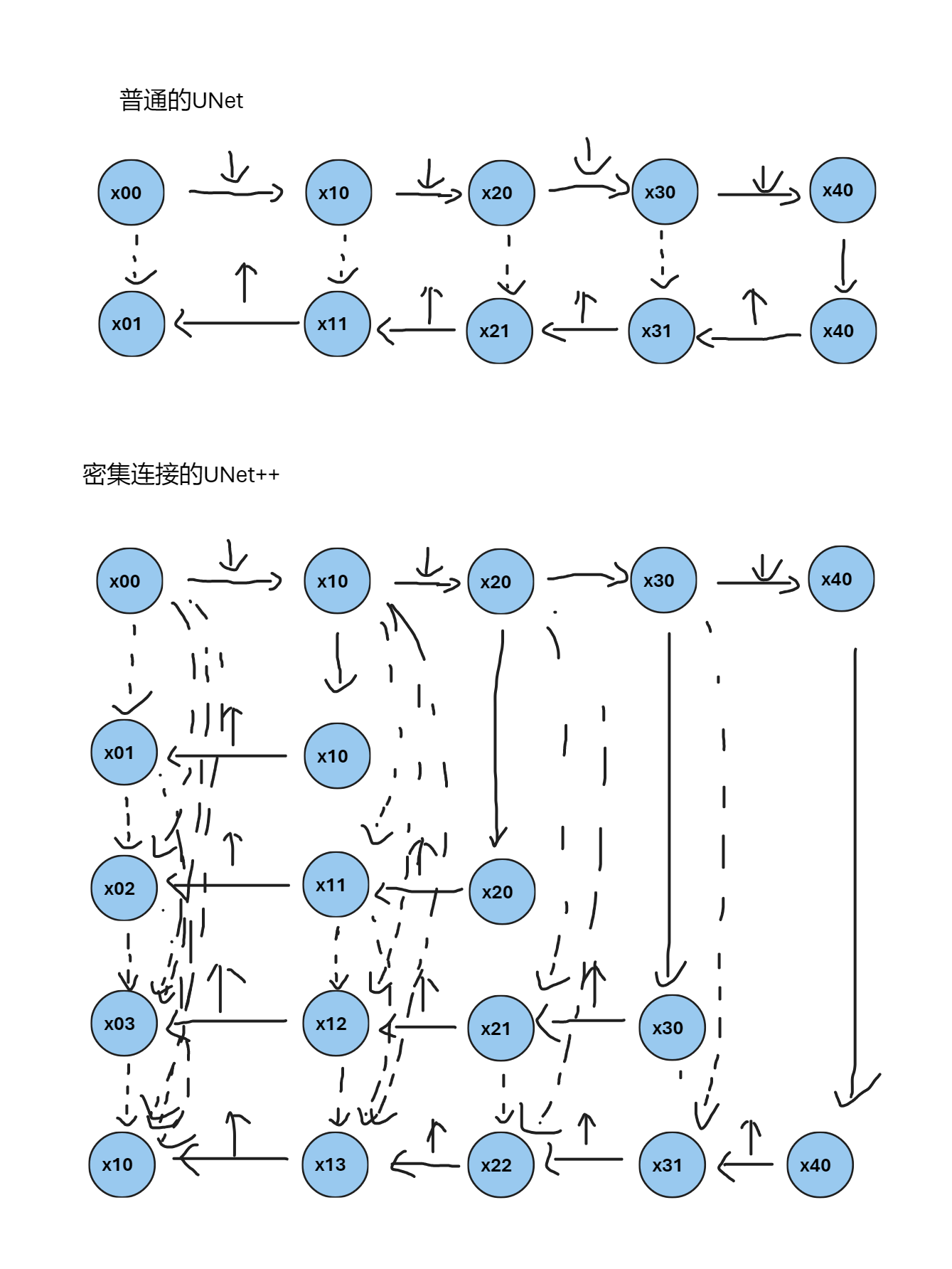
可以看到,如果使用常规的卷积,比如对于x04来说,有着从00,01,02,03来的特征,那么他的通道数为原来的五倍,此时进行卷积带来的计算量很大的,因此本文采用深度隔离卷积替代标准的卷积操作。深度隔离卷积核将空间卷积和通道卷积分离开来,首先进行空间卷积,对于每一个通道用一个卷积核卷积,如WHC的卷积后只改变空间信息,通道不变,即W’H’C,然后再使用通道卷积,如果使用C’个卷积核,则最后结果为W’H’C’,对于标准卷积来说,参数为W1H1CC’,对于深度隔离卷积来说,参数为W1H1C+CC’
损失函数
在GAN网络中的损失函数
①让判别器判别是否是真实的图像,让生成器生成接近真实的图像,不断增强判别器和生成器的水平,用于对抗过程的对抗损失函数:
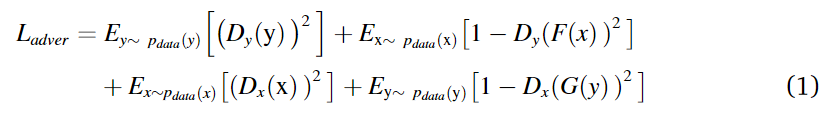
②用于重构的损失函数,对于x图像提取特征后,利用特征重建和原来一样的图像。
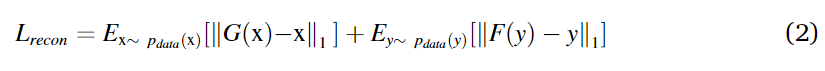
③用于循环的损失函数,对于x图像提取特征后,重建到y图像的域中,然后对重建的再提取特征,然后重建到x域的图像,让转换回来后的图像不变。
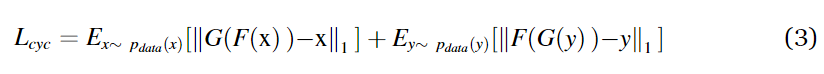
在变化检测网络中的损失函数
①焦点损失函数,用于缓解类不平衡的问题,其中pt表示距离真值的概率,二值交叉熵损失函数加了前面的权重,对于二值函数来说,变化类和不变化类的提供的损失是一样的,但是对于焦点损失函数来说,对于难以分别的点会提供更大的损失,比如在二值交叉熵损失函数中,对于某个变化的点,但是分在了不变化的点中,但是由于平等的问题,可能并不专注于改善这个地方,但是对于焦点损失函数来说,对于分类错误的点,由于系数的原因,提高损失的比重,强迫网络注意这里并进行改进。

②多尺度损失函数,在原图尺度,第二尺度和第三尺度上进行不同权重的焦点损失函数。

实验方法
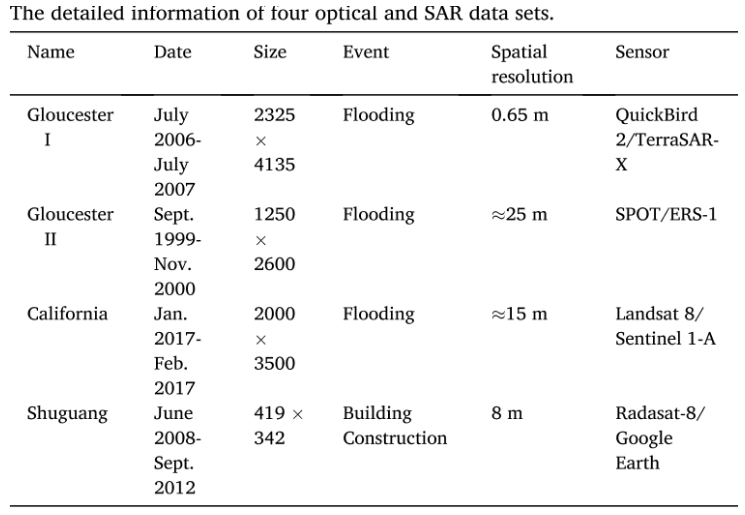
数据集
四对不同地区的光学和SAR遥感数据集,英国Gloucester两个、美国加州、中国曙光村。
对比的方法
Reed Xiaoli、INLPG、SCCN、cGAN、X-Net、ACE-Net、HPT
其中RX假设背景遵循多元正态分布,构建似然比检测算子;INLPG构造 K-NN 图并计算非局部块相似性结构差异来衡量变化程度。SCCN: 通过耦合层从两个编码图像中获得差分图像;cGAN: 通过转换网络将光学图像转换成 SAR 图像;X-Net: 利用亲和性信息作为先验知识,通过循环 GAN 网络变换图像后获得差异图像;ACE-Net: 引入潜在空间,在此空间中通过四个网络的结构转换图像;HPT: 是一种通过映射像素使用 K 最近未变化像素来实现转换的监督异构变化检测方法。由于以上的异构图像变化检测中存在没有转换的网络,因此本文中也同样进行了没有转换的网络结构,直接将原始图像导入CD网络中。
实验设置
图像转换中选择了具有6层残差块的生成器,七层编码器的判别器。adam,初始学习率为0.0005,对于CD网络来说,编码器的卷积层有{32,64,128,256}的滤波器个数,输入的大小为两个图像拼接起来的大小为256*256*C,C为图像通道综合,w1,w2,w3=0.2,0.3,0.5,焦点损失参数中,γ=2, α \alpha α=0.25,
评价指标
对于深度转换:FID、KID
F I D = ∣ ∣ μ r − μ g ∣ ∣ 2 + T r ( ∑ r + ∑ g − 2 ∑ r ∑ g ) FID=||μ_r-μ_g||_2+Tr(\sum_r+\sum_g-2\sqrt{\sum_r\sum_g}) FID=∣∣μr−μg∣∣2+Tr(∑r+∑g−2∑r∑g),其中r,g分别表示真实图像和生成图像的特征,μ为均值, ∑ \sum ∑为协方差矩阵。
K I D = E [ k ( r , r ′ ) − 2 k ( r , g ) + k ( r , g ′ ) ] , k ( θ , θ ′ ) = ( 1 d θ T θ ′ + 1 ) 3 KID=E[k(r,r')^-2k(r,g)+k(r,g')],k(\theta^,\theta')=(\frac{1}{d}\theta^T\theta'+1)^3 KID=E[k(r,r′)−2k(r,g)+k(r,g′)],k(θ,θ′)=(d1θTθ′+1)3,其中r代表真实图像分布中采样的图像,g是从生成图像中采样的图像,k()代表着能够表示相似度的多项式核函数。
对于CD:TP、TN、FP、FN、F1、OA

实验结果
Gloucester I数据集
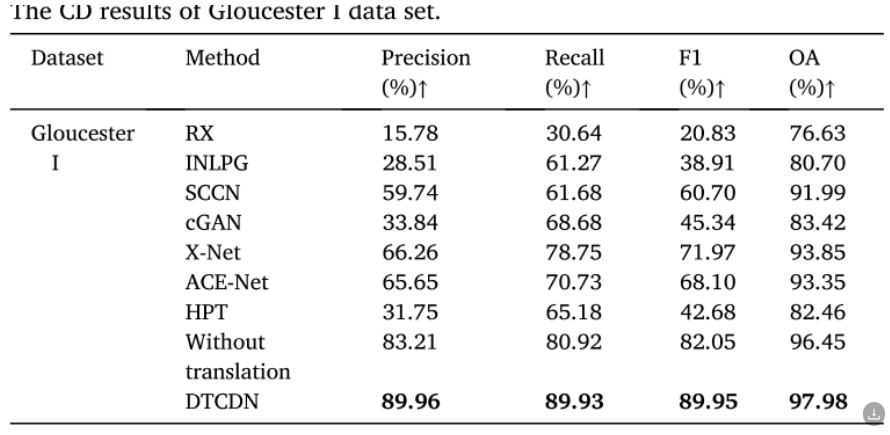
相对于其他方法,研究中提出的方法(DTCDN)在 Gloucester I 数据集上的变化检测结果具有明显的优势。DTCDN 在检测变化区域和未变化区域以及误分类方面表现更好。特别是在 F1 指标方面,DTCDN 有显著的提高,这意味着其他方法存在更多的错误检测和漏检。RX 方法由于精度最低,错误地将许多未变化的像素视为变化像素,因此性能较差。INLPG 具有较高的召回率,但性能仍然不佳。基于深度学习的大多数方法表现良好,其中 X-Net 和 ACE-Net 具有相似的结构,具有第二高的 F1 和 OA。SCCN 是唯一一种非GAN-based方法,位于中间位置。cGAN 的整体结果不佳,主要是由于精度较低。HPT 方法相对于一些无监督方法在变化检测任务中表现不佳,即使在使用未变化像素作为监督的情况下,它的性能也不如其他方法。由于CD网络特征分析具有出色的能力,没有转换的方法获得了第二高的评价,而DTCDN具有更好的识别能力,在识别变化像素方面具有最好的性能。

从可视化的结果可以看到,DTCDN 方法被发现在变化检测任务中表现最佳,具有更好的可辨识性,能够最准确地识别变化像素。对比结果的可视化图表(Fig. 9)也显示了 DTCDN 在检测变化区域形状方面的卓越性能。RX 方法在检测洪水区域方面表现最差,而INLPG 方法漏掉了许多变化像素。SCCN 方法的预测结果出现了断裂和模糊现象。基于对抗编码器网络的 X-Net 和 ACE-Net 方法获得了相似的结果。cGAN 方法在一般情况下看起来是第三好的结果。HPT 方法的预测结果包含许多不连续的小噪声。具体来说,对于第 1-4 行,DTCDN [图 9 (k)] 模型可以在洪水区域检测到更多的空白孔。此外,第5行和第6行的红色帧中包含了未更改的建筑和道路。由于其特征与SAR遥感图像中的洪水相似,大多数其他方法将它们视为变化区域。通常,DTCDN 在完全准确地检测变化区域的形状方面具有最佳性能。
Gloucester II数据集
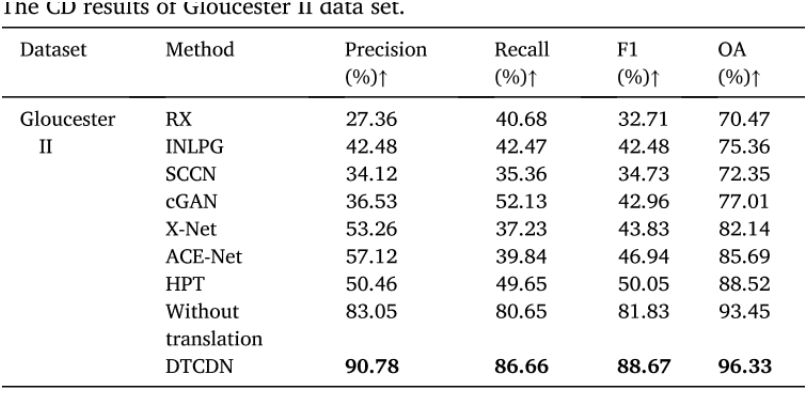
与第一个数据集相似,DTCDN 在性能上明显优于其他检测方法。不同于 Gloucester I 数据集,监督方法 HPT 在这个数据集上表现更好,优于其他无监督方法。RX 仍然由于对图像关系的简单假设而表现最差。在无监督方法中,基于深度学习的 X-Net、ACE-Net 和 cGAN 获得了比 INLPG 更高的得分。SCCN 在识别变化像素方面表现次差。由于图像特征更接近,DTCDN 在没有进行图像转换的情况下实现了更高的准确性。

除了 DTCDN 以外,其他方法更容易丢失大部分的变化像素(第1和2行),并且检测到不属于变化类别的额外区域(第3和4行)。DTCDN 能够很好地处理这两个问题,但是有一些相对较小的区域被认为是未变化的,但实际上属于地面真实的变化区域。
California 数据集
SAR图像是由多极化VV和VH数据合成的。
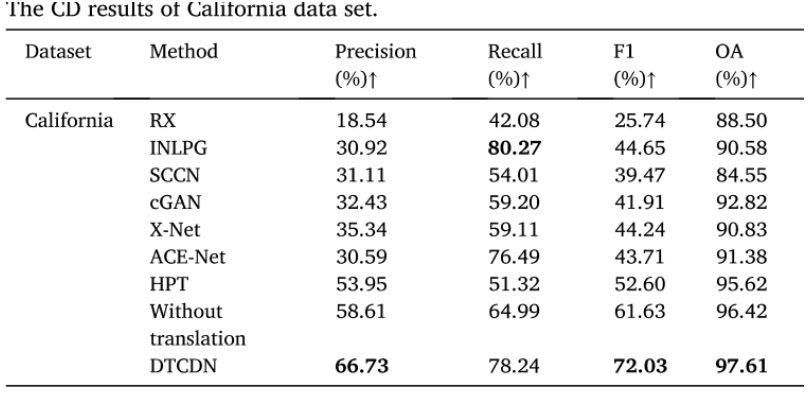
DTCDN 在大多数评估指标上取得了最高的分数。RX 方法在这个数据集中仍然表现最差。HPT 在F1和OA方面获得第三高的分数。此外,INLPG 在召回率方面表现最佳,但精度较低,这意味着它容易将未变化像素误分类为变化像素。类似地,ACE-Net 在召回率方面只略低于DTCDN,但在精度方面表现较差。cGAN 和 X-Net 的精度和召回率非常相似。结果表明,图像转换对最终的变化检测结果产生影响,没有进行图像转换的方法在所有评估中都不如DTCDN。

INLPG、SCCN 和 ACE-Net 在一些本应分离的区域中连接了白色的变化区域,这表明它们包含了更多的误报像素。此外,图表中的一些区域包含了未变化的像素,它们在光学图像和SAR图像上的颜色和纹理与变化像素相似。DTCDN 能够避免将这些像素误分类为变化像素,而其他方法都将它们识别为变化像素。此外,HPT 忽略了许多小的变化对象。
上海数据集
曙光村数据集包括了建筑物的重建和河流的变化,可能是由于洪水或其他自然事件引起的。由于数据集较小,作者采用了交叉验证方法来处理变化区域。
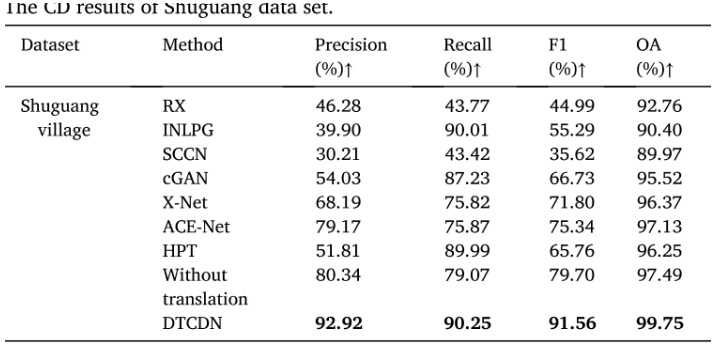
SCCN 方法在所有评估指标上表现最差。X-Net 和 ACE-Net 在精度方面明显优于 cGAN,因此性能更好。HPT 和 INLPG 都在召回率方面获得了良好的结果,接近90%,但它们也误检测了一些变化像素,导致 F1 分数降低。值得注意的是,DTCDN 模型在 F1 方面实现了超过90% 的性能。总体而言,由于未变化像素占据图像的大部分,所有算法在OA方面表现出较高的值,但其中DTCDN表现最佳。

直观来看,DTCDN 的结果更符合地面真实情况,正确分类的像素较多,意味着误报样本较少。在建筑区域,尽管DTCDN 在检测建筑物边界方面表现最佳,但存在一些无法完全识别的空洞。
由Gloucester II相同传感器在同一时间收集的另外两个图像(同构数据集)
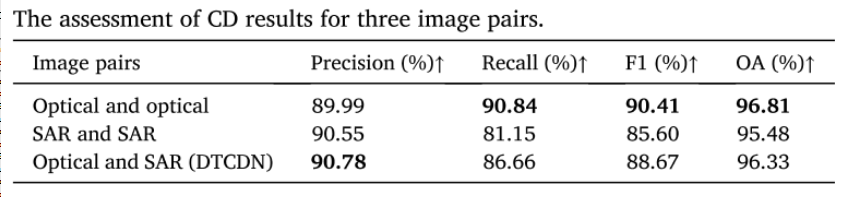
光学图像对获得了最佳性能,这是符合预期的。令人惊讶的是,异质图像对的大多数评估指标都优于同质SAR图像对。特别是与SAR图像对相比,异质图像对在召回率、F1和OA方面分别提高了5.51%、3.07%和0.85%。作者认为这可能是由SAR图像的质量问题导致的,这证明了他们的方法可以提高图像质量并减少一些错误,尤其是在进行SAR图像的转换时。

仅展示了T1和T2光学图像对,因为它们足以展示变化区域。显然,光学图像对提供了有效的光谱和空间信息,因此具有最佳的结果。然而,作者指出,DTCDN 方法在结果中存在一些误报和漏报,需要在未来改进。
结果分析
深度变换的效果
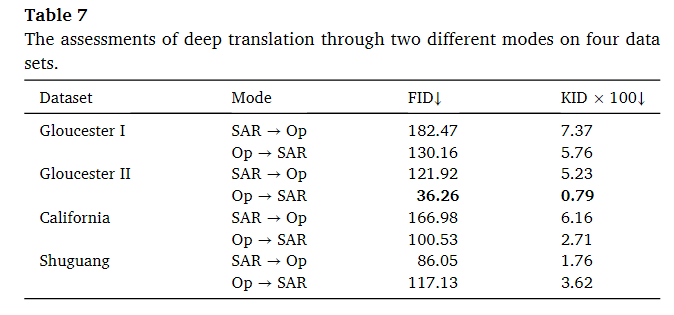
可以看出,四个数据集的FID值都在200以下,其中光学图像转换成SAR图像的效果最好的是 Gloucester II 数据集。然而,相反的转换(SAR图像到光学图像)效果最差,这可能受原始SAR图像的影响,因为原始SAR图像中包含了一定数量的散斑噪声(speckle noise)。California数据集的转换结果优于Gloucester I数据集。而在曙光村数据集上,两种不同的转换方式的性能都不错。此外,四个数据集的两种转换模式之间存在一些差异。对于California、Gloucester I 和 II数据集,生成的SAR图像更接近于参考图像。这是因为光学图像包含更多信息,比SAR图像更复杂,因此生成光学图像是一个更困难的过程。相反,对于曙光村数据集,转换为光学图像的效果更好,可能是因为该数据集的规模较小。

转换后的图像可以准确匹配原始图像的纹理信息和一些颜色信息,但风格更接近参考图像。对于更改的像素,转换后的图像保留了较大的差异,而在非更改区域,它几乎可以显示与参考相同的特征。在图 15 (a) 所示,在应该淹没的红色区域中,尽管它不能直接转换为水对象,但它被转换为与周围特征不一致的坑的形状。例如,在图 15 (d) 的红色帧中,原始光学图像中的建筑物在转换的光学图像中变化很大,可以更容易地识别。
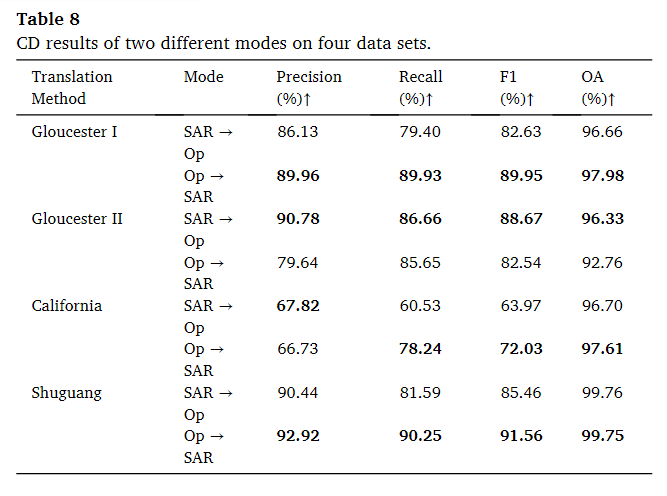
FID(Fréchet Inception Distance)和KID(Kernel Inception Distance)用于表示转换后的图像与真实图像之间的相似度。它们是一种度量生成图像与真实图像之间差异的指标,通常用于评估图像转换的质量。较低的FID和KID值表示生成图像与真实图像更相似。但是对于变化检测(CD),并不是说生成的图像与真实图像越接近就越好。因为CD的目标是检测图像中的变化区域,而不仅仅是匹配图像的外观。因此,CD的评价标准与FID和KID等相似度指标不同。从光学图像到SAR图像和从SAR图像到光学图像的转换。实验结果显示,不同数据集对这两种转换方向的效果不同。其中,Gloucester I、California和Shuguang数据集在从光学到SAR图像的转换方向上表现更好,而Gloucester II数据集在SAR到光学图像的转换方向上表现更好。从光学图像到SAR图像和从SAR图像到光学图像的转换。实验结果显示,不同数据集对这两种转换方向的效果不同。其中,Gloucester I、California和Shuguang数据集在从光学到SAR图像的转换方向上表现更好,而Gloucester II数据集在SAR到光学图像的转换方向上表现更好。

在Gloucester I数据集中,从光学到假SAR图像的转换可以检测到更多的洪水区域,导致更高的召回率。这表明,假SAR图像并没有导致误检测,并且其形状更与地面特征一致。虽然FID和KID等距离指标可以衡量生成图像与真实图像之间的相似度,但它们不能绝对解释最终变化检测效果。CD的成功与图像转换质量、原始图像噪声等因素有关,因此,需要综合考虑多个因素来评估CD的效果。
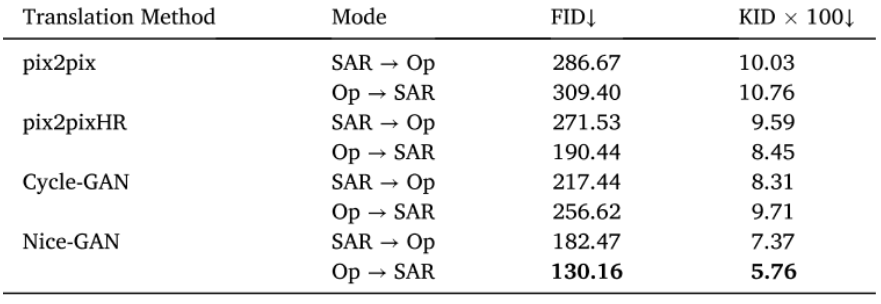
将本文中的Nice-GAN和其他的GAN网络比较,NICE-GAN在两种模式下都具有较低的FID和KID值。NICE-GAN将分类器和编码器结合在鉴别器阶段,从而提高了图像转换的性能。pix2pix和pix2pixHR没有循环结构,需要双倍训练时间,可能会影响转换效率,并且在某些模式下表现不佳。Cycle-GAN和pix2pix在将SAR图像转换为光学图像时具有较高的FID和KID值,而在另一种转换模式下表现更好。相比之下,pix2pixHR和NICE-GAN在将图像转换为SAR图像时表现更好。

从变换得到的SAR图像来看,NiceGAN[图17 (g)]和Cycle-GAN[图17 (f)]在样式转移上都取得了很好的效果,并且保留了原有的特征。pix2pix[图17 (d)]在噪声和模糊效果下是最差的。此外,由于pix2pixHR[图17 (e)]更适合生成更高分辨率的图像,平移后的图像过于平滑。Cycle-GAN[图17 (f)]生成的图像虽然与NICE-GAN[图17 (g)]相似,但存在如第一行红色框所示的盐噪声,可能会影响CD结果。此外,图17中的第二行和第三行显示了一些图像对,其中包含光学图像和SAR图像之间的变化区域。在NICE-GAN的转换SAR图像中,变化的淹没像元没有显示出洪水特征,这导致了原始SAR图像和转换图像的区分。这一现象说明图像平移不仅可以减少未变化像素的差异,而且可以保持变化像素的一定区别。图像转换的结果启示我们,一个鲁棒的转换模型可以产生更有效的CD网络输入。
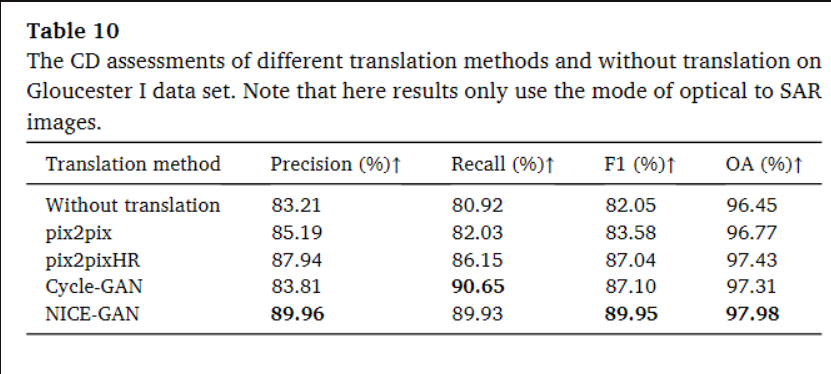
不同深度图像平移方法的CD结果如表10所示。很明显,CD经过转换后是可以改进的。通过Nice-GAN转换,其精度提高了0.06,召回率提高了0.09,使得F1提高了0.07。不出所料,pix2pix在四种转换方法中效果最差。pix2pixHR的结果更接近CycleGAN。Cycle-GAN在召回率方面略优于NICE-GAN,而NICE-GAN在精度、F1和OA方面表现最好。

NICE-GAN[图18 (g)]优于其他方法,其转换FID和KID较小。尽管Cycle-GAN[图18 (f)]的效果很好,但它不能完全检测到第2行红色帧中的一些变化区域。同样,pix2pixHR[图18 (e)]存在大量的泄漏检测。与不平移相比[图18 ©], pix2pix[图18 (d)]只是因为生成的图像有很多噪声而有一点提高。准确的预测结果在一定程度上证明了在光学和SAR图像的CD中图像平移是可行的。同时,研究结果表明,随着图像平移方法的改进,光学和SAR遥感图像的CD效果将得到增强。
UNet++中可分离卷积的效果
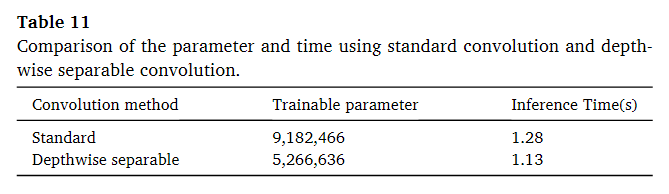
对于标准卷积来说,参数为W1H1CC’,对于深度隔离卷积来说,参数为W1H1C+CC’,可以看到参数大致只有原来的40%,每张图的推理减少了0.15s。
深度可分离卷积将标准卷积核默认为在特征图的通道维度上具有线性组合特性的分解特性。标准卷积核需要同时学习空间和通道之间的相关性,而深度可分离卷积则明确分离了这两种相关性。
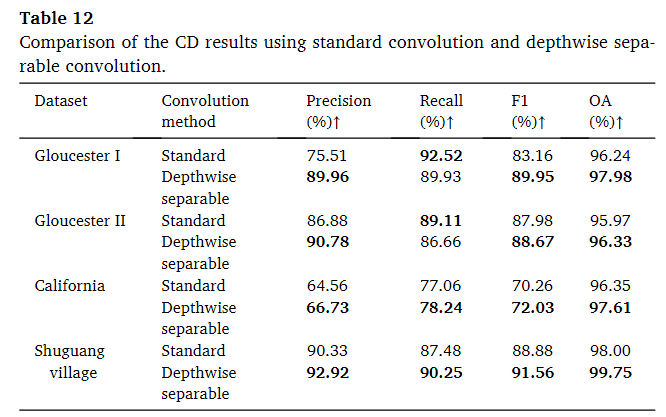
对于这四个数据集,大多数评价通过深度可分卷积得到了改进。特别是在Gloucester I数据集上,F1几乎增加了6.5%。在该数据集中,标准卷积的召回率略高于深度可分方法,而深度可分卷积在精度上大大优于深度可分方法。然而,对于Gloucester II数据集,增益不那么突出,最大的F1增益小于1%。在另外两个数据集中,我们的模型在所有标准上都高于标准卷积。

使用深度可分离卷积生成的二值变化地图 [Fig. 19 (d)] 在视觉性能上表现更好,相比标准卷积生成的地图 [Fig. 19 ©] 更具优势。具体来说,深度可分离卷积的算法能够更准确地检测变化区域的边缘,同时对于小型地面对象(例如最后一行的河流)的提取效果也更好。
UNet++中多尺度损失的效果
原始的UNet++是在X0n的维度进行损失函数的,也就是在全图尺寸的除了第一层的所有层进行,而本文的是在每个尺寸的最后一层进行,除了最小的两个尺寸。
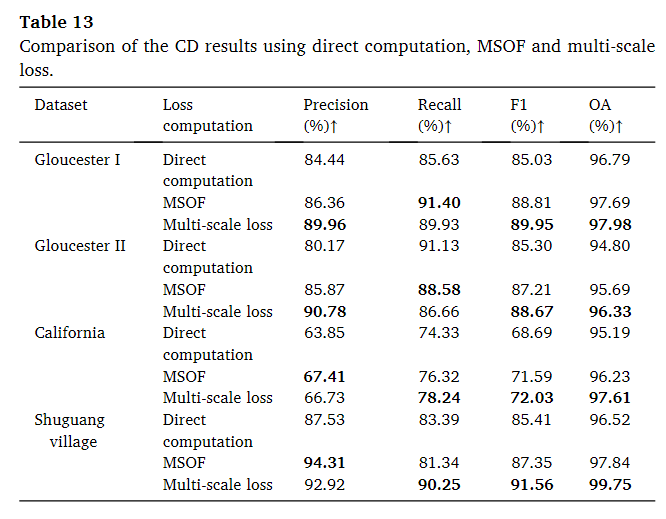
可以看到表中直接计算、MSOF 和多尺度损失的定量评估。与直接计算最后一个特征的损失相比,MSOF 和多尺度损失实现了改进。在所有这些数据集中,在大多数评估指标中,多尺度损失高于 MSOF。由于其能够利用上下文信息并映射不同分辨率的特征的能力,可以在详细和全局检测中获得更好的结果。

多尺度损失的整体效果与ground-truth的相似度高于其他两种方法。从第1行和第2行的红色帧来看,没有检测到直接损失函数的一些变化像素,这代表了较高的假阳性率。在第 4 行,虽然我们的方法错过了小的更改像素,但它不会导致更严重的错误,即许多其他两种方法将许多未更改的像素识别为更改的像素。此外,如第 5 节和第 6 行所示,直接计算的损失在检测建筑物和河流的变化方面的准确率最低。与多尺度损失一样,MSOF 可以检测到建筑物的完整边界,但它无法检测到其中的孔洞。在检测接近或变化区域的不变像素的结果方面,我们的算法比 MSOF 具有更好的性能。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









