







文章目录
前言
为什么要学YOLO V1:YOLO是当前目标检测领域性能最优模型之一,基本上所有人工智能和计算机视觉领域的开发者、学生…都要用它开发各行各业的应用,后面的YOLO版本都是在V1的基础上改进升级的,所以弄懂YOLO V1很重要。
一、算法精讲-预测阶段(前向推断)
在模型已经训练成功之后输入未知图片,来对未知图片进行预测。
YOLO V1网络结构

输入:448x448x3的图像
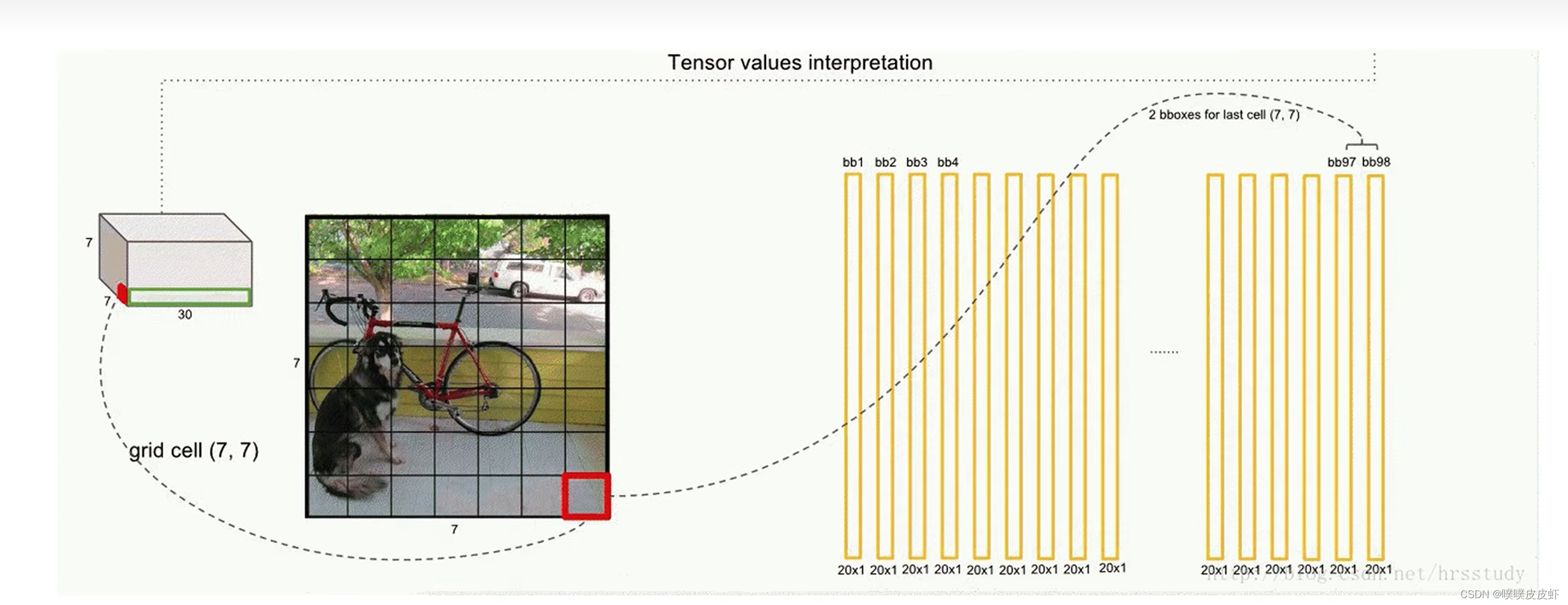
输出:7x7x30张量tensor(包含所有预测框坐标,置信度,类别结果)
在预测阶段,这个YOLO就是一个黑箱子,输入的是448×448×3的图像,7×7×30维的张量tensor。这些tensor中就包含了所有预测框的坐标、置信度和类别结果,最后只需要解析7×7×30维的张量就可以获得目标检测的结果。
为什么输出是7×7×30呢?
因为网络把图像划分成s×s个grid cell(网格),在YOLOv1中s=7,所以是7×7的网格,如下图中最左边的图展示的。每个grid cell又可以预测出B个bounding box(就是B个预测框,预测框包含了x,y,h,w,c五个参数。x,y,h,w四个定位坐标,中心店坐标和框的宽高,因此就可以确定框的位置。图中置信度由框的线粗细表示,c表示置信度,粗的表示置信度比较高,如下图所示。),在YOLOv1中B=2,就是每个grid cell预测出2个预测框,这2个预测框可能很大也可能很小,无论怎样只要bounding box的中心点落在grid cell里面就行,就能代表这个bounding box是由这个grid cell生成的。
每个grid cell还可以生成所有类别的条件概率。假设它已经包含物体的情况下,是某一个类别的概率,生成下图中的彩色的图。把每个bounding box的置信度×类别的条件概率就可以获得每一个bounding box的各类别的概率。结合bounding box的信息和该grid cell的类别信息就可以获得最后的预测结果。这些信息都是从7×7×30的张量获取的。
30=2(bounding box)*5(x,y,h,w,c)+20(基于VOC数据集的20个类别)

每一个grid cell只有一个条件类别概率概率最高的代表类别,把改grid cell中的两个bounding box都赋予这个类别,在进行一系列后处理(过滤掉低置信度的,非极大值抑制去除掉重复的预测框)就可以得到目标检测预测结果。
完整预测过程
输入448x448x3的图像,输出输出:7x7x30长量tensor(包含49个grid cell的90个预测框的坐标,置信度,每一个grid cell的类别),对其进行解析、后处理就获得了最终的目标检测结果。
预测阶段后处理-NMS非极大值抑制
把预测出来的98个预测框进行筛选过滤,把低置信度的过滤掉,把重复的预测框只保留一个,得到目标检测的结果。
7x7x30长量如何变成目标检测结果?

30是由5,5,20构成(第一个5是bounding box的四个位置坐标和置信度坐标,第二个5是bounding box的四个位置坐标和置信度坐标,20是20个类别的条件概率)。
真正类别的概率=20个类别的条件概率*bounding box的置信度
即P(B)=P(B|A)*P(A)
每一列表示对于某一个bounding box而言,20个类别的概率是多少。所以一共有98列。
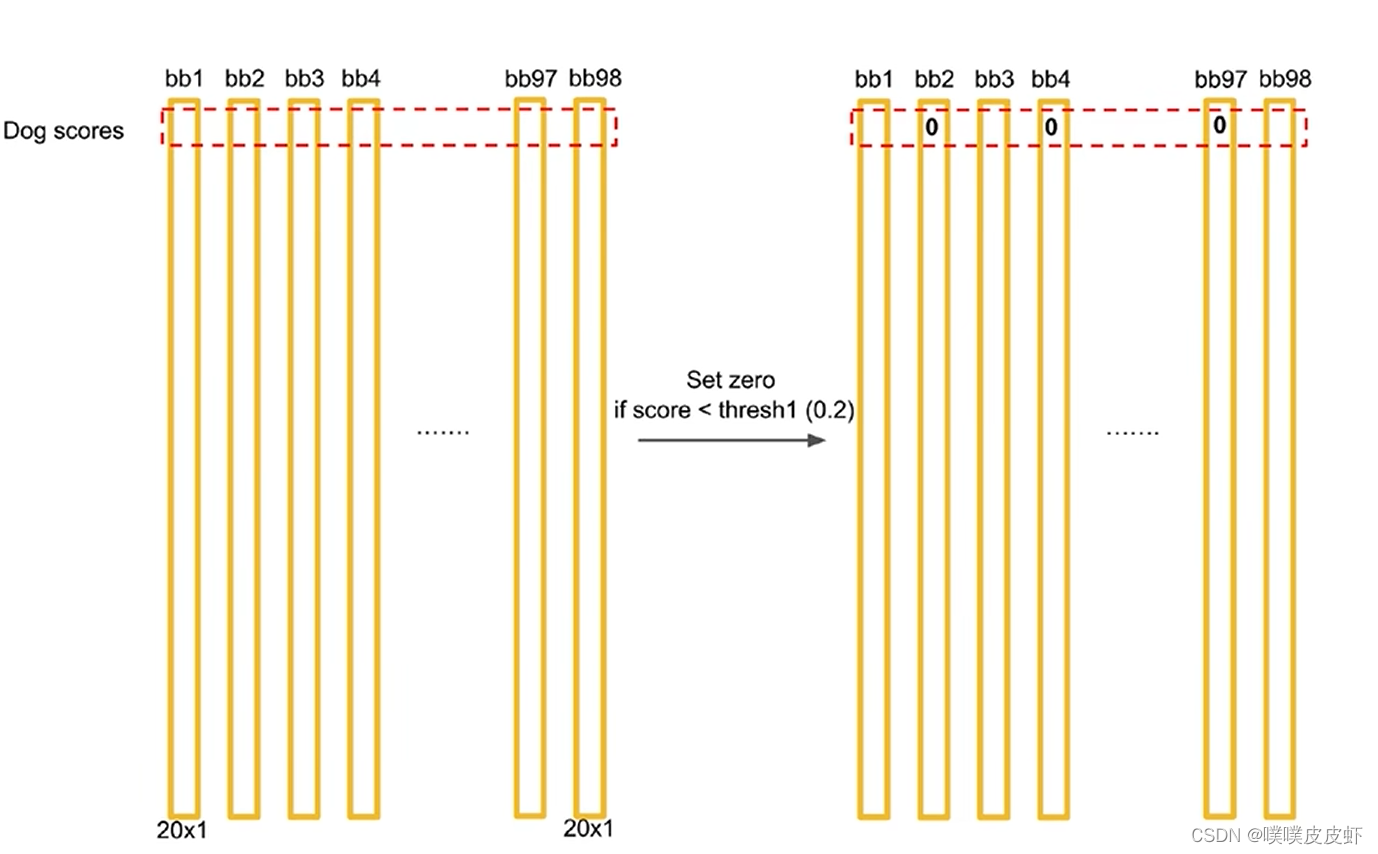
假设第一列就是dog的概率,设置小于0.2的概率设置为0,再按照dog概率由高到低排序,得到下图。
非极大值抑制

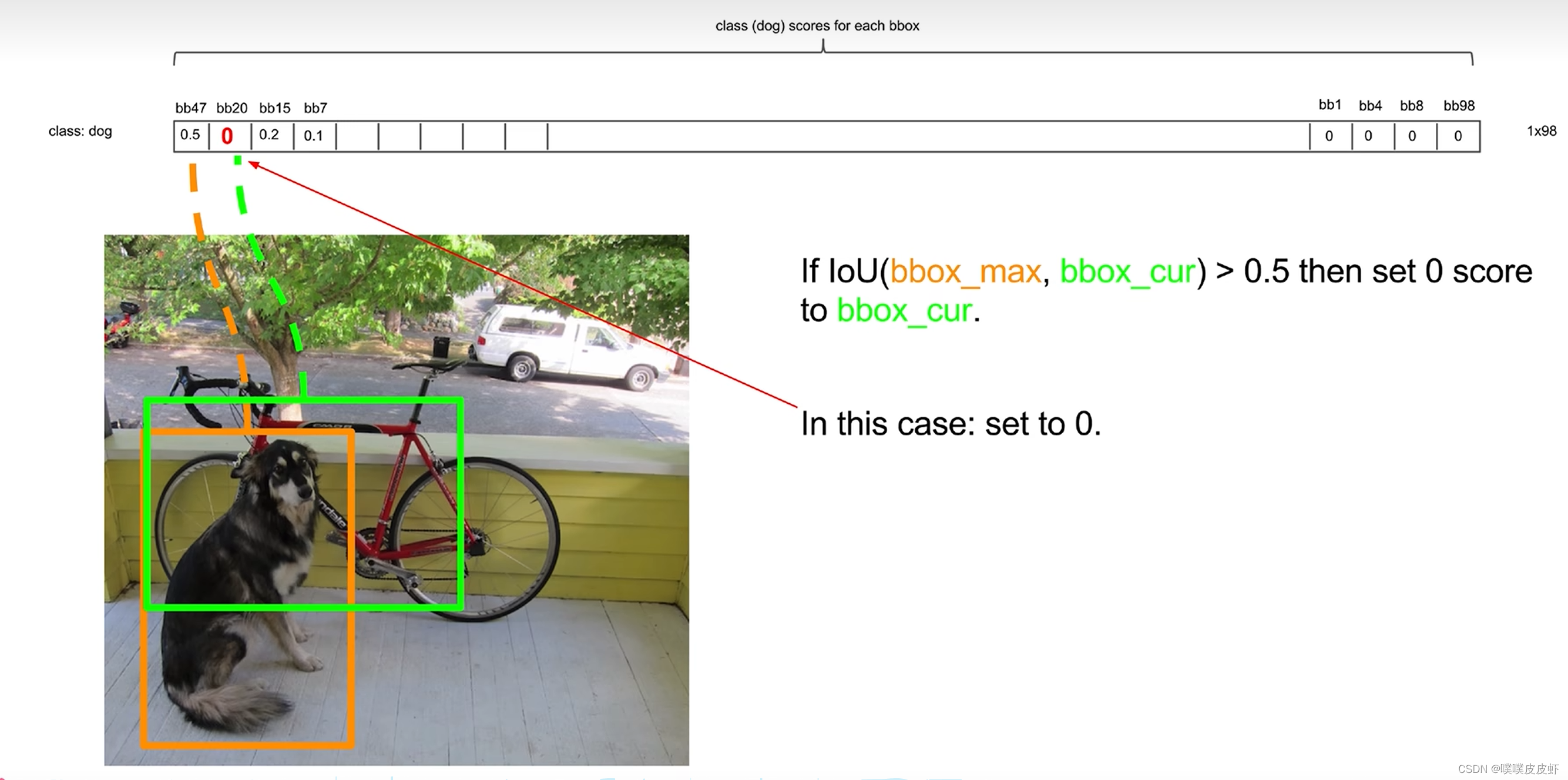
非先把第一个和第二个比较,如果他们的IOU大于某个阈值,则任务他们是重复识别了dog,就把低置信度的置零
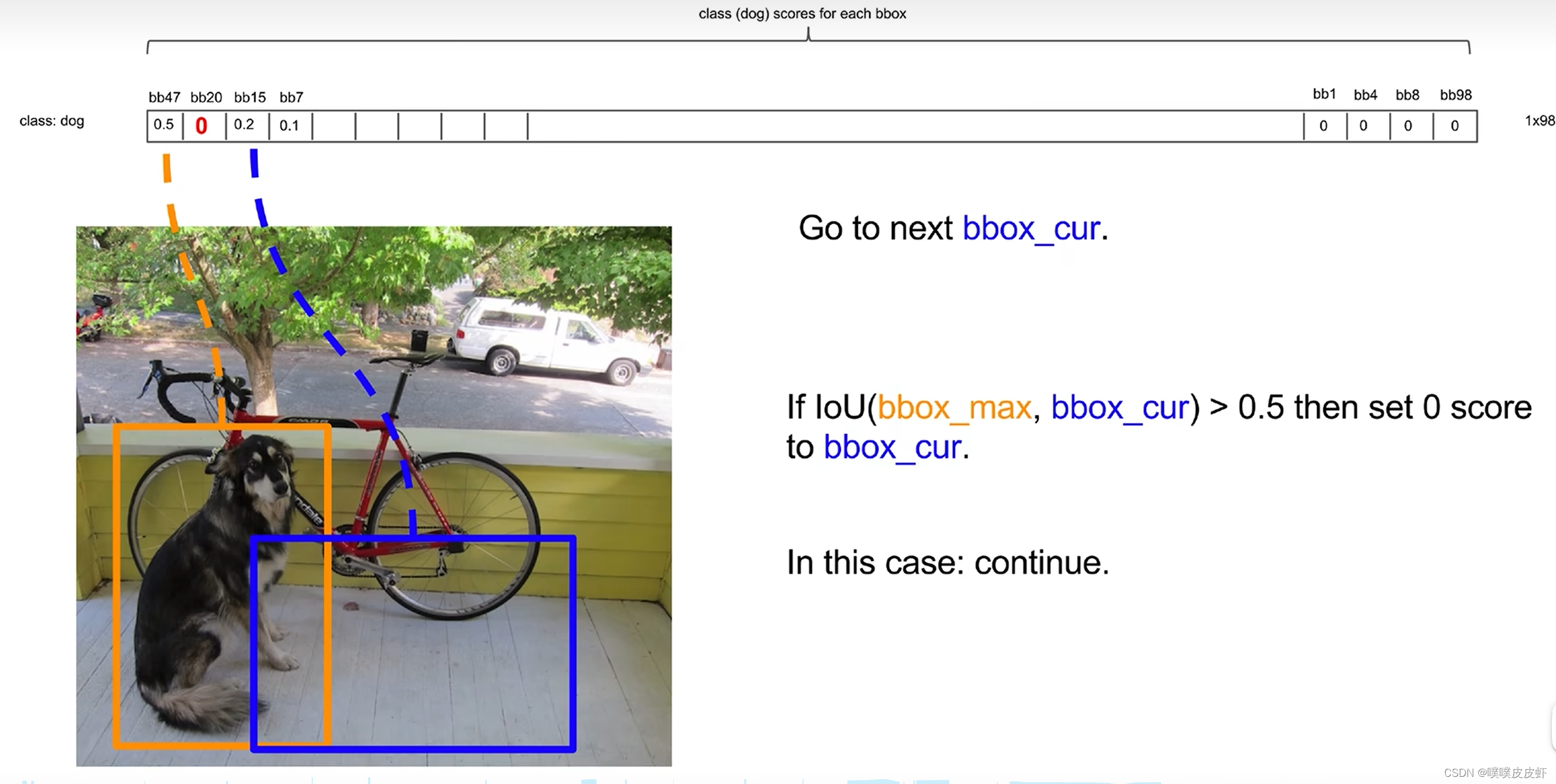
再看下一个蓝框和第一个比较,若IOU没有超过阈值就保留。

重复上述操作即可。
再将第二高的比较…得到下图结果
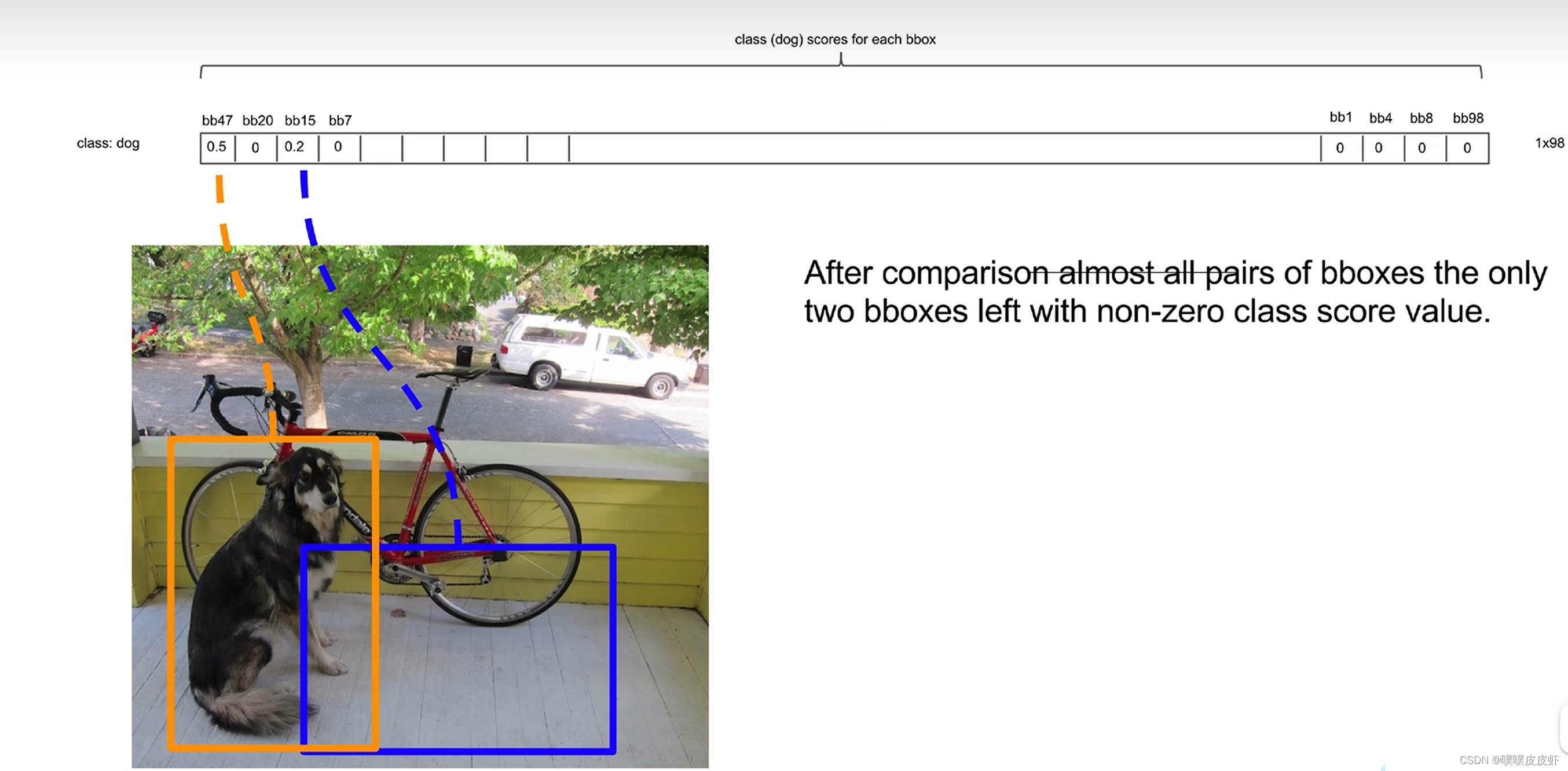
再对每一个类别(每一行)都进行这种操作就得到了一个稀疏矩阵
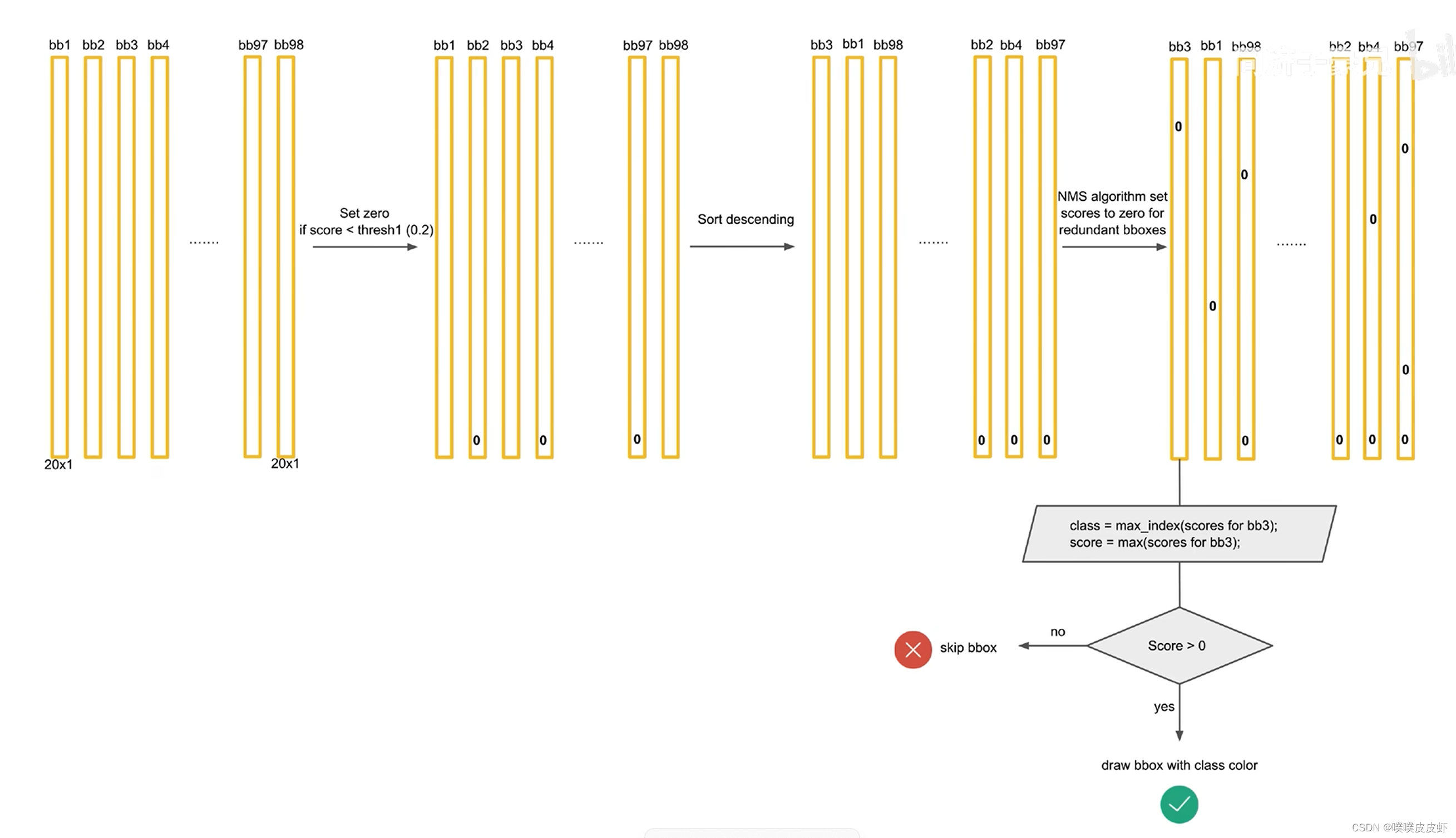
最后把不为0的索引、概率找出可视化在目标检测结果上即可。
二、训练阶段(反向传播)
1.训练
通过梯度下降、反向传播方法迭代的微调神经元中的权重,是的损失函数最小化的过程。
而目标检测是典型的监督学习问题,即在训练集上图标已经被人工标注了GT,而算法就要让预测结果尽可能拟合GT,是使得loss最小。

而GT的中心点落在哪个grid cell里面,就要又哪个grid cell预测出的bounding box去拟合这个GT。并且grid cell输出的类别就应该是这个GT的类别。
每一个grid cell会预测出两个bounding box,和GT交并比IOU大的bounding box去拟合。
所以loss函数的设计就要让负责拟合物体的预测框和GT尽可能重合。
2.loss
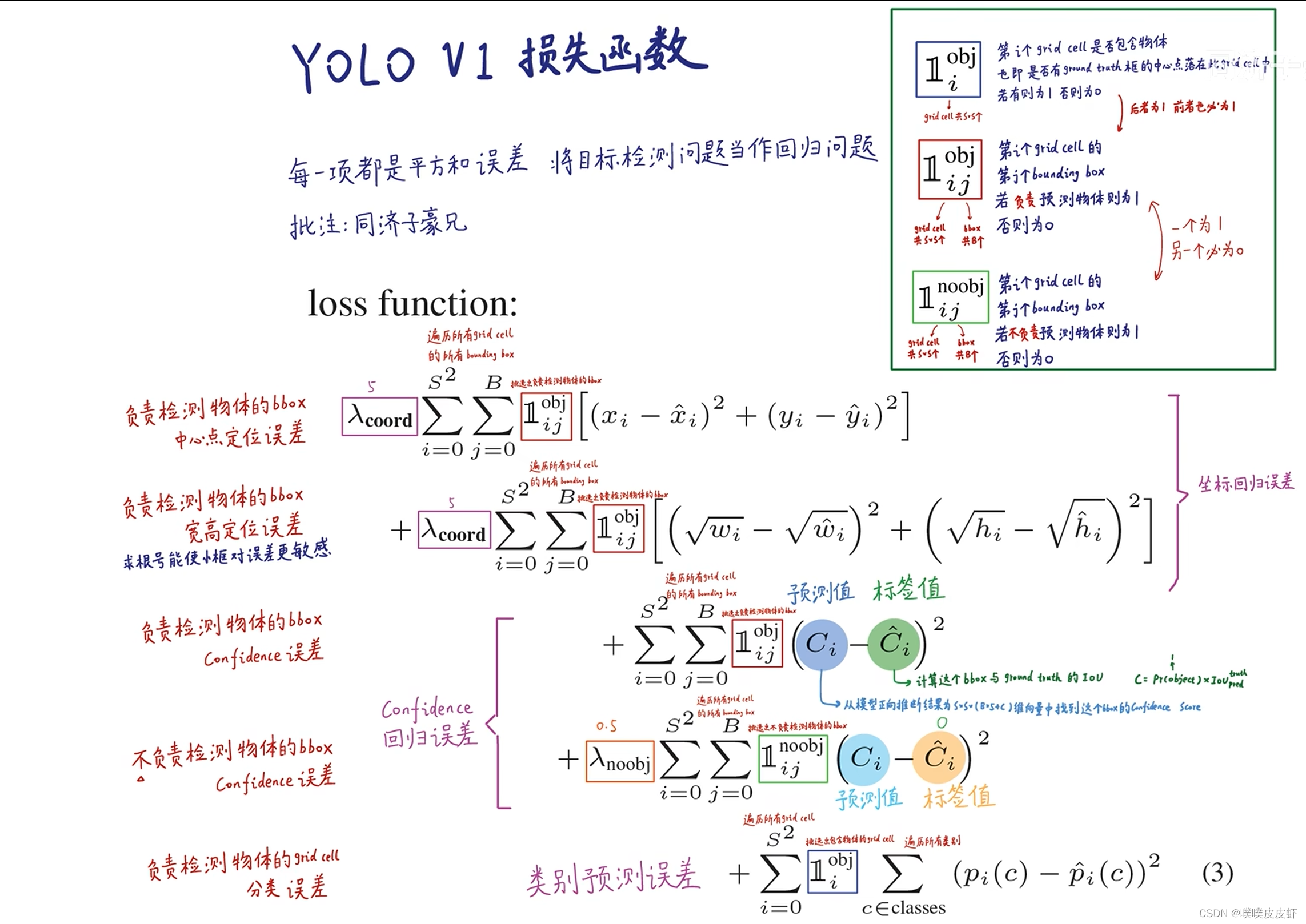
第一项是负责检测bounding box的中心点定位误差,实际就是负责预测物体的框要和groundtruth从横纵坐标、宽高上尽量一致,所以损失给它们构造了一个残差平方和这么一个回归问题(预测出一个连续的值,把这个值和标注值进行比较,这两个值越接近越好)的损失函数。这5项其实都是回归问题的损失函数,YOLO就是把目标检测问题当做回归问题解决,
第二项是负责检测物体的bbox宽高定位误差。
第三项是检测物体的bbox confidence(置信度)误差。预测出的置信度和IOU越接近越好。
第四项是不负责检测物体的bbox confidence误差,它们预测出的置信度越低(接近0)越好。
第五项负责检测物体的grid cell分类误差,条件概率越接近1越好。
总结
可以把神经网络看做一个黑箱
输入:448x448x3的图片
输出:7x7x30tensor(包含90个预测框位置,置信度,类别),在对这些框进行非极大值抑制,就可以得到最终目标检查结果
说明:该笔记参考b站同济自子豪兄
讲的很详细!!















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









