







一、回顾YOLO V1
算法总结
YOLO把整个图分成了7*7个grid cell,每一个grid cell预测2个bounding box。在训练阶段人工的标注框中心点落在了哪个grid cell,就由该grid cell去负责预测出的两个bounding box中的一个(和人工标注狂IOU大的)去负责预测拟合这个标注框。在预测阶段,这个YOLO就是一个黑箱子,输入的是448×448×3的图像,7×7×30维的张量tensor。这些tensor中就包含了所有预测框的坐标、置信度和类别结果,最后只需要解析7×7×30维的张量就可以获得目标检测的结果。

缺点
mAP较低,定位性能较差,即精确调整预测框位置的能力较差,同时recall也较低,因为YOLO V1把整个图分成了7*7个grid cell,每一个grid cell预测2个bounding box所以最多只能预测98个bounding box,所以很难把所有的目标全部检测出来。因此它检测小目标和密集目标能力较差。
二、YOLO V2
1.如何更准确?

1.1 Batch Normalization
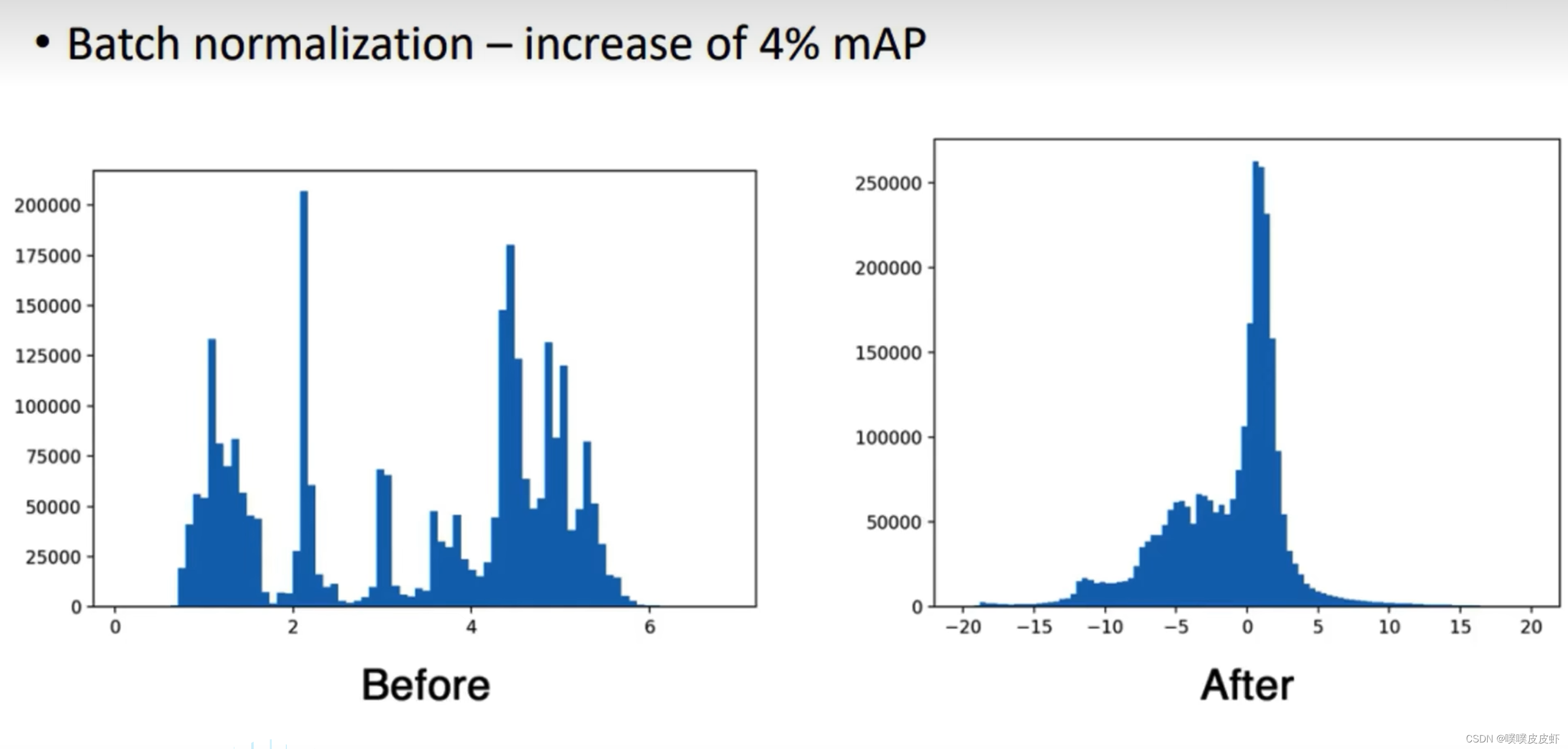

参考:参考太阳花的小绿豆:Batch Normalization详解以及pytorch实验
BN层一般在线性层后面,激活函数前面,(1)可以加快神经网络的收敛(2)改善梯度远离饱和区(3)可以使用较大的学习率来训练网络(4)并且对于初始化也不那么敏感了(5)正则化的作用
1.2 High Resolution Classifier
1.2.1Anchor
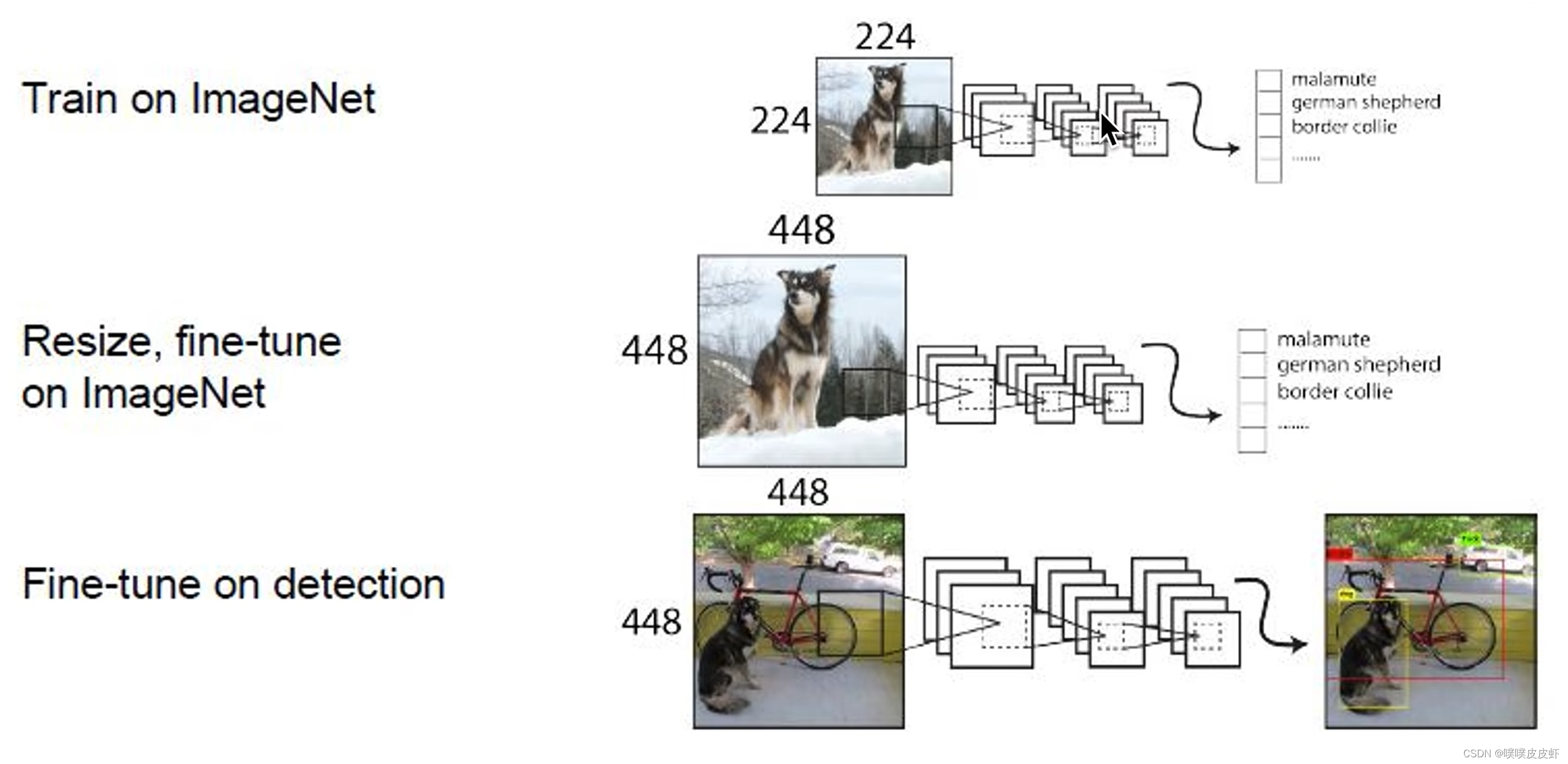
一般的图像分类网络都是以很小的分辨率在ImageNet图像分类数据上训练(224x224),而YOLO V1最后的目标检测模型输入图像尺度是448448,所以如果是用一个很小的图片训练的网络,再在448448上的目标检测去训练,网络就要切换,得学习切换这两种分辨率,这就带来了性能降低。YOLO V2就直接在448x448的图像分类数据集上进行训练。
1.3 Anchor , Dimension Cluster , Direct Iocation prediction
在YOLO V1中人工的标注框中心点落在了哪个grid cell,就由该grid cell去负责预测出的两个bounding box中的一个(和人工标注狂IOU大的)去负责预测拟合这个标注框。但是这两个bounding box是“野蛮生长”的。
在YOLO V2中,给这bounding box先验的参考框,只需要这先验的参考框进行微调就行了。所以下图中“矮胖”的框就适合来预测车,“高瘦”的就时候来预测人。每一个预测框只需预测出相较于Anchor的偏移量就可以了。
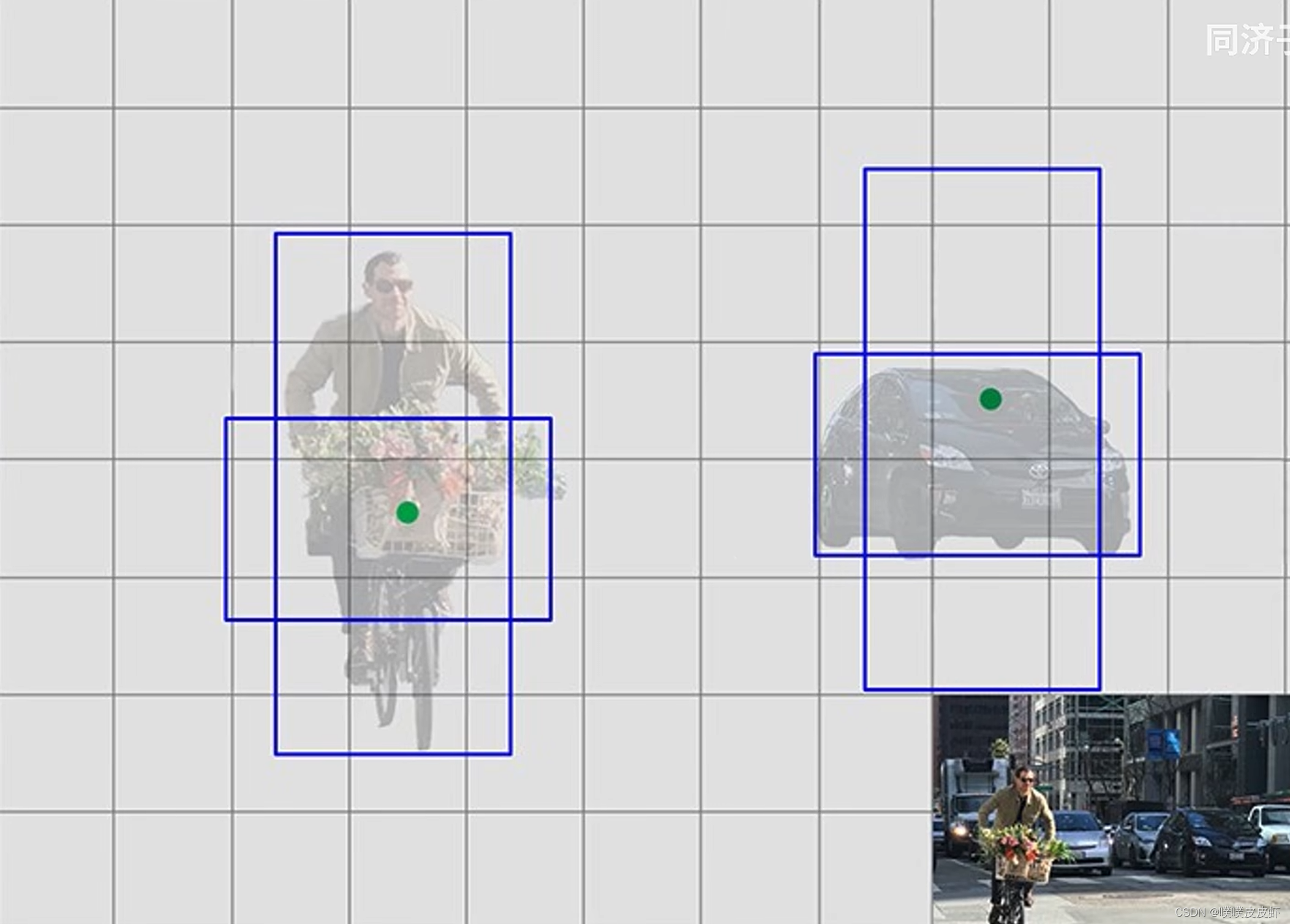
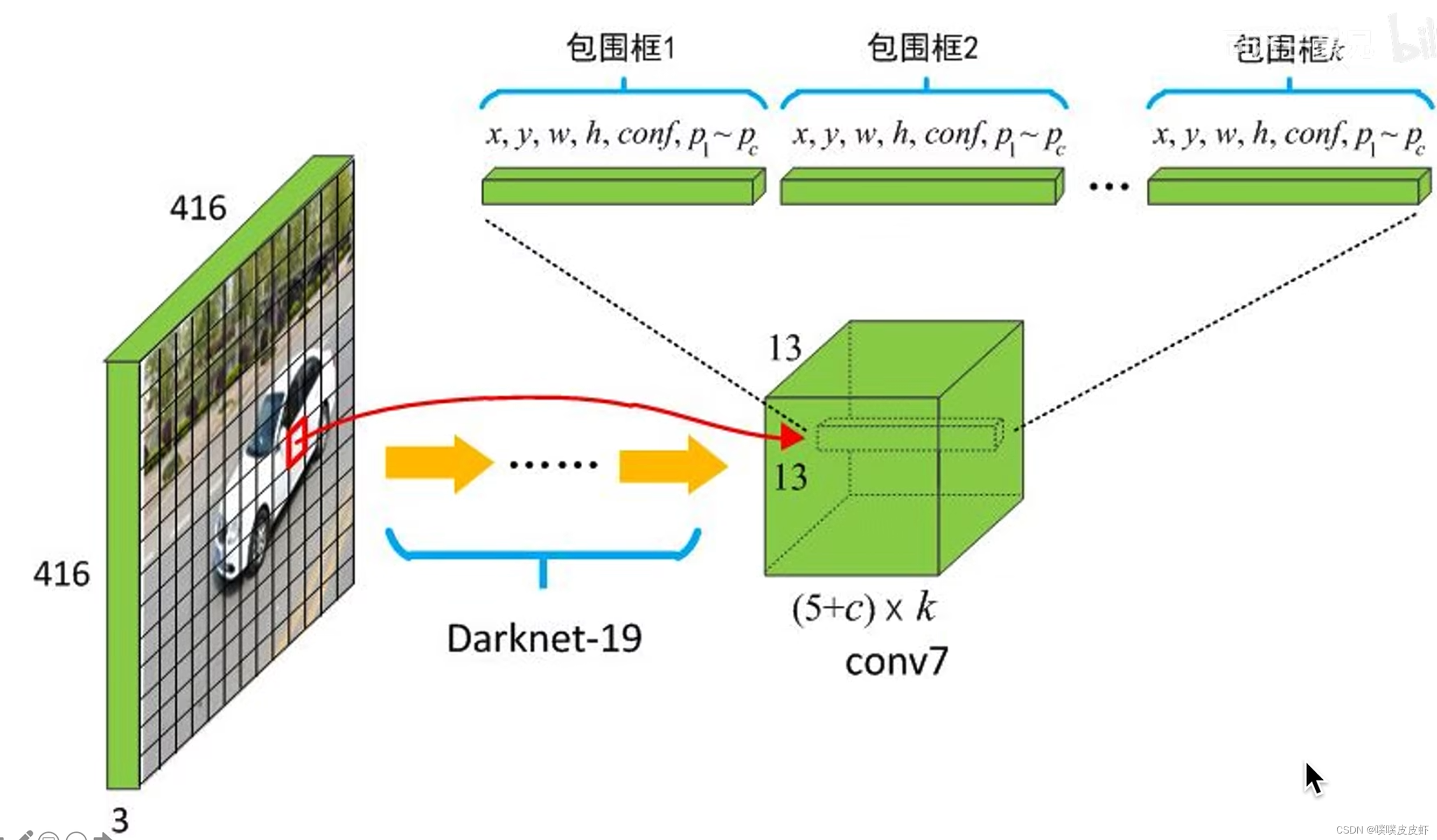
在YOLO V2中把图片分成了13*13个grid cell,每一个grid cell预测5个Anchor(同样是与中心位置标注框IOU最大的Anchor去预测)只需预测出相较于Anchor的偏移量就可以了。
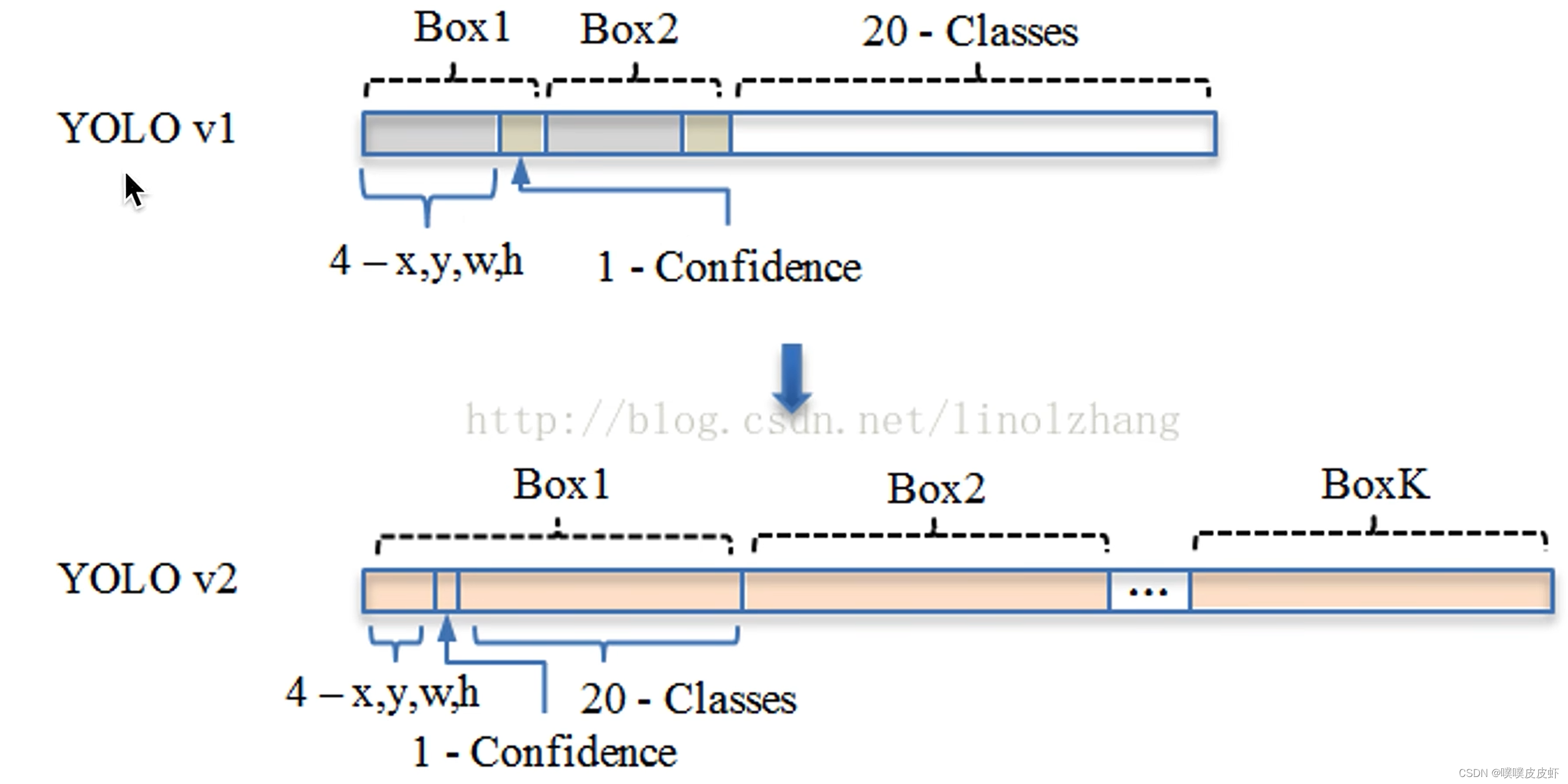
所以模型输出的结构也变了,在YOLO V2中把图片分成了13*13个grid cell,每一个grid cell预测5个Anchor,每一个Anchor除了四个定位参数一个置信度之外,还有20个类别条件类别概率。所以grid cell一个就是125个数。
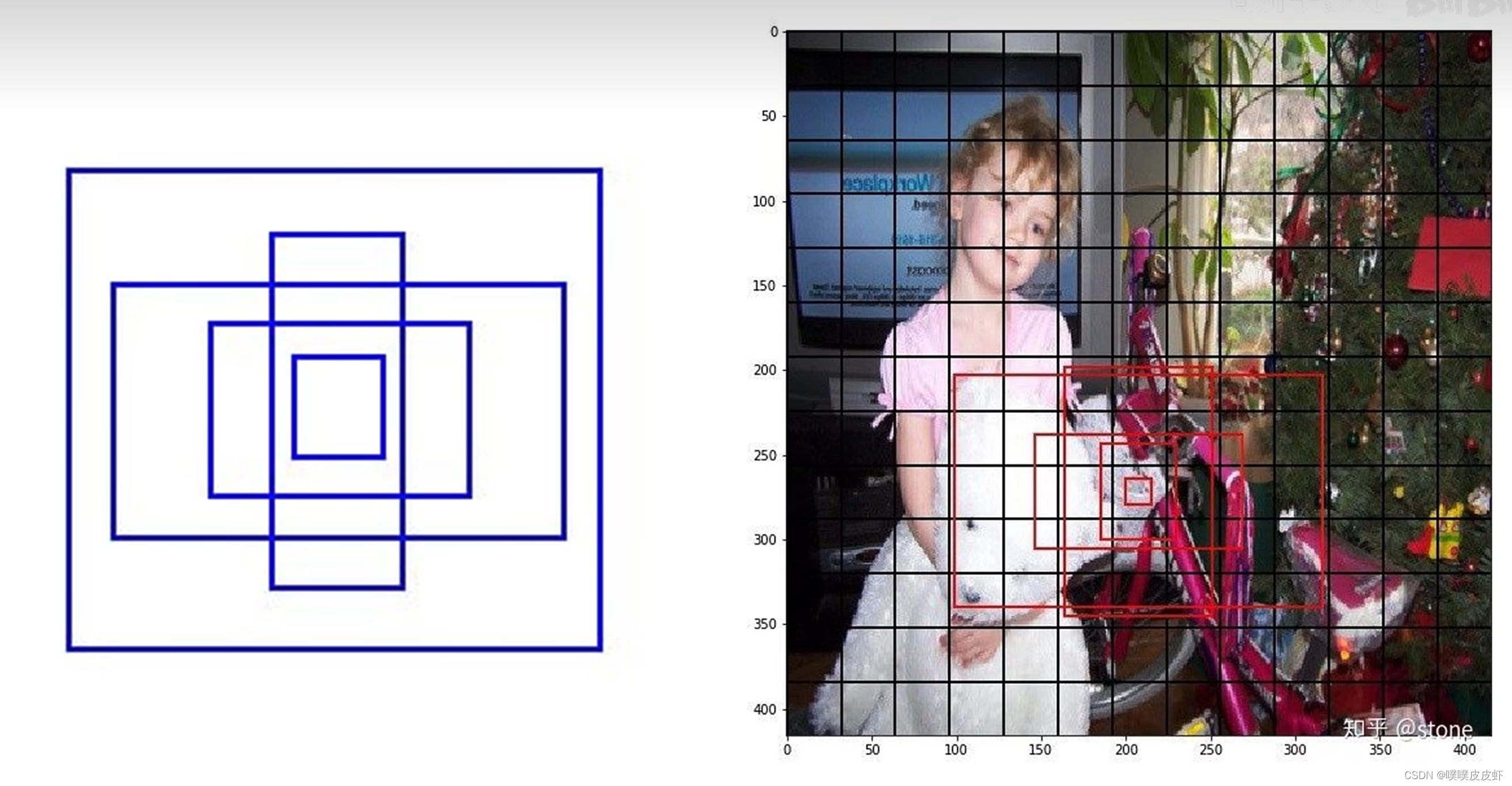
Dimension Clusters—维度聚类K-means聚类确定Anchor初始值)
Anchor Boxes的尺寸是手工指定了长宽比和尺寸,相当于一个超参数,这违背了YOLO对于目标检测模型的初衷,因为如果指定了Anchor的大小就没办法适应各种各样的物体了。
在训练集的边界框上运行K-means聚类训练bounding boxes,可以自动找到更好的boxes宽高维度。由上面分析已知,设置先验Anchor Boxes的主要目的是为了使得预测框与真值的IOU更好,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标
Direct location prediction—直接的位置预测
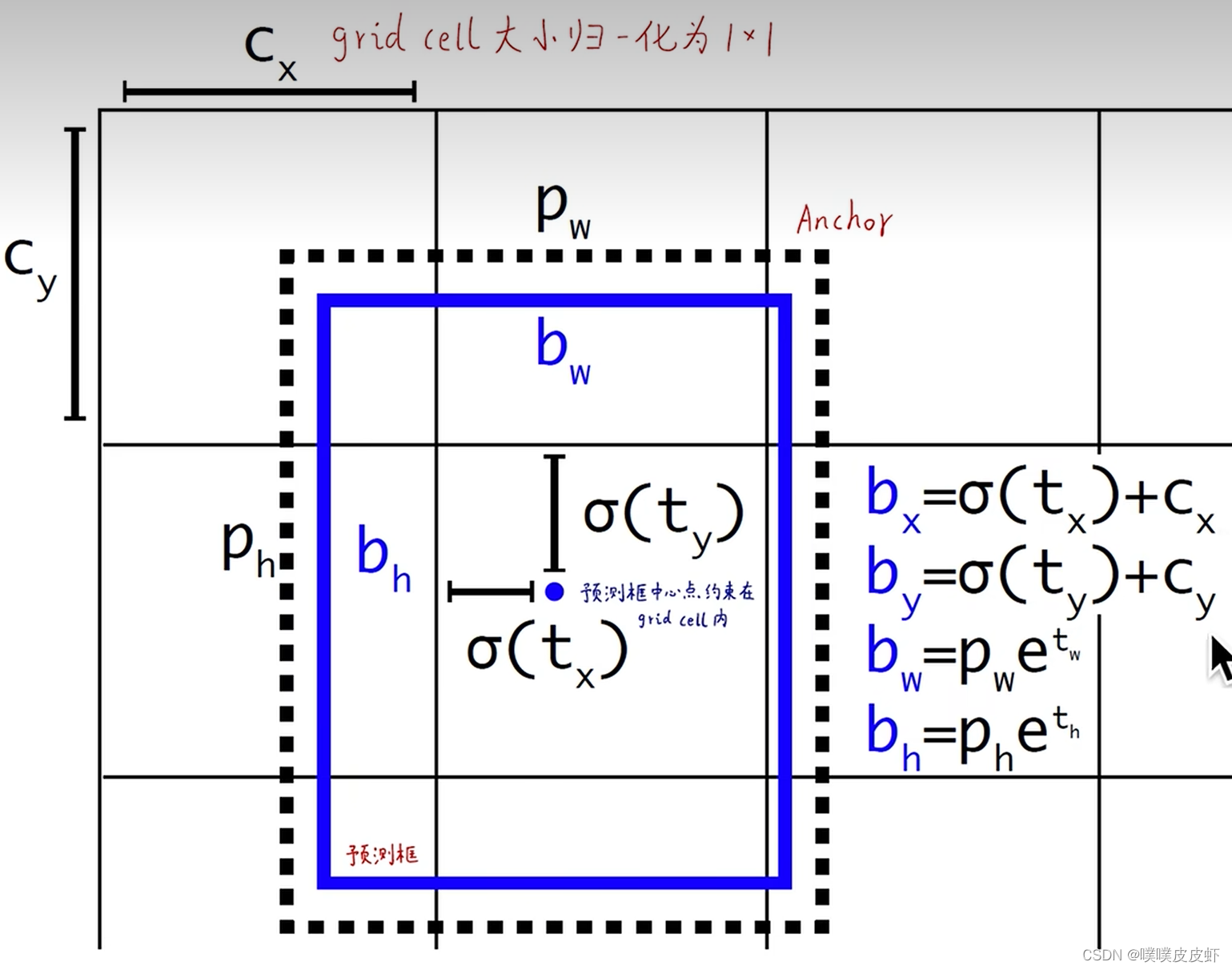

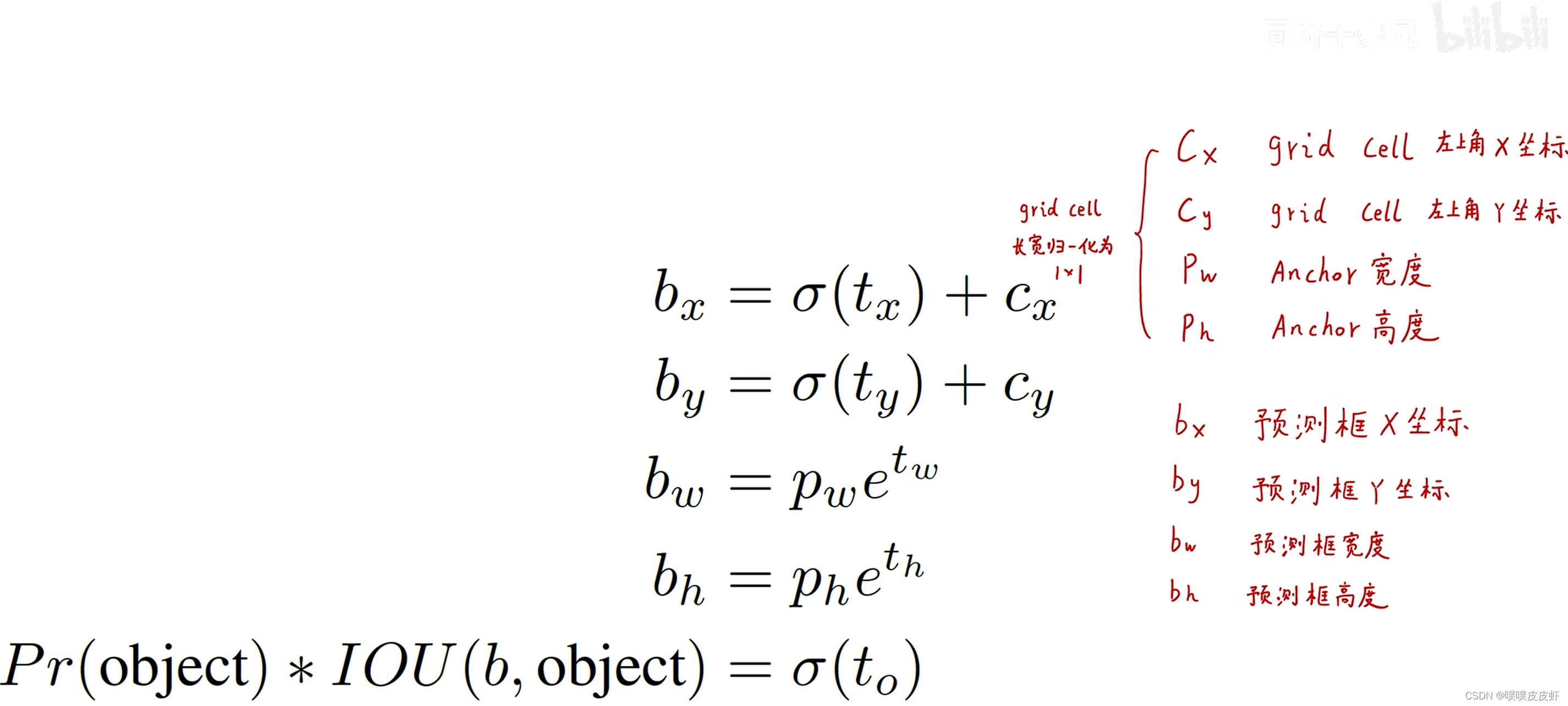
解读慢慢更新…
1.4 Loss
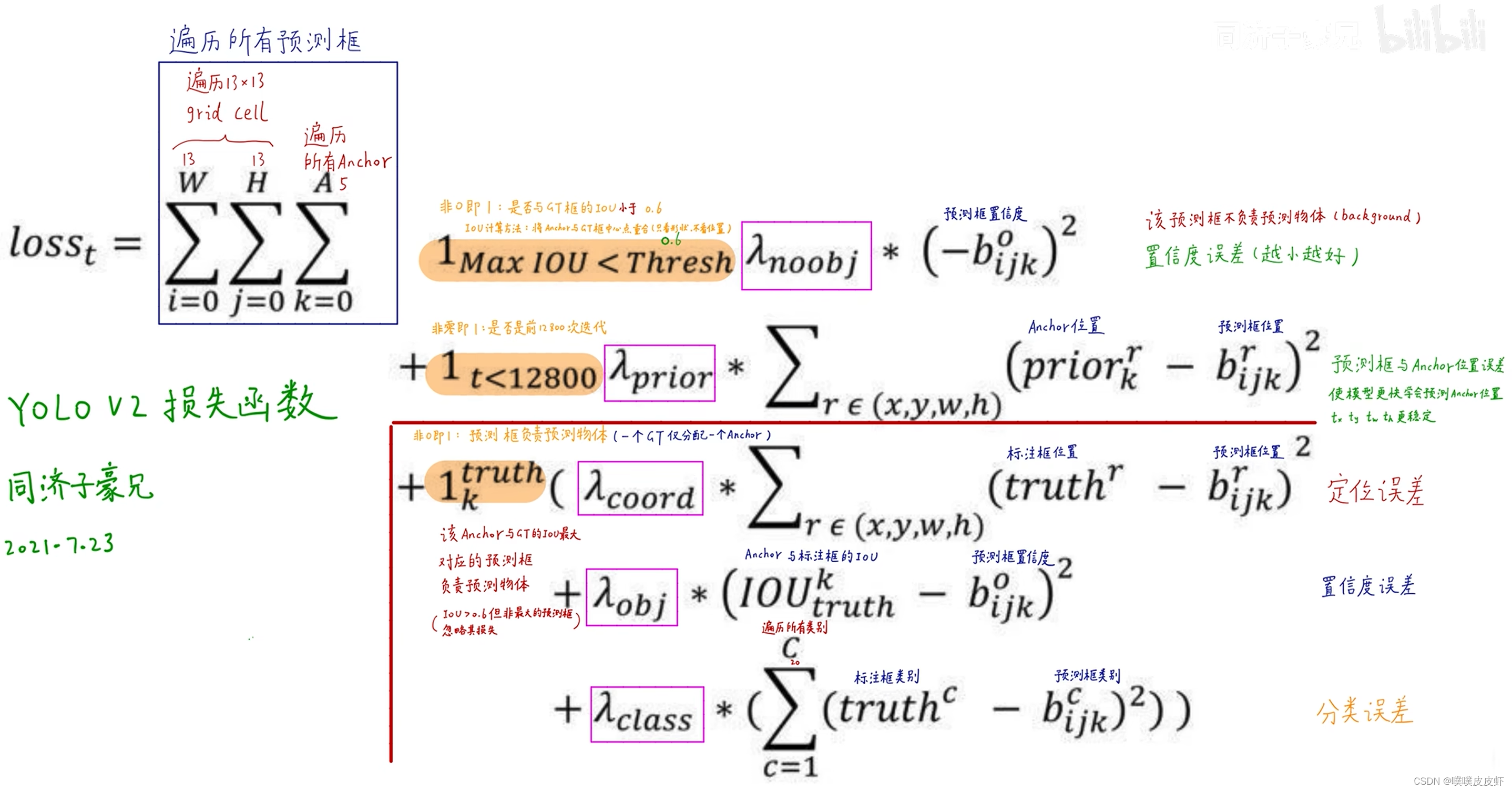
解读慢慢更新…(最近在摆烂)
1.5 Fine-Grained Features—细粒度的特征
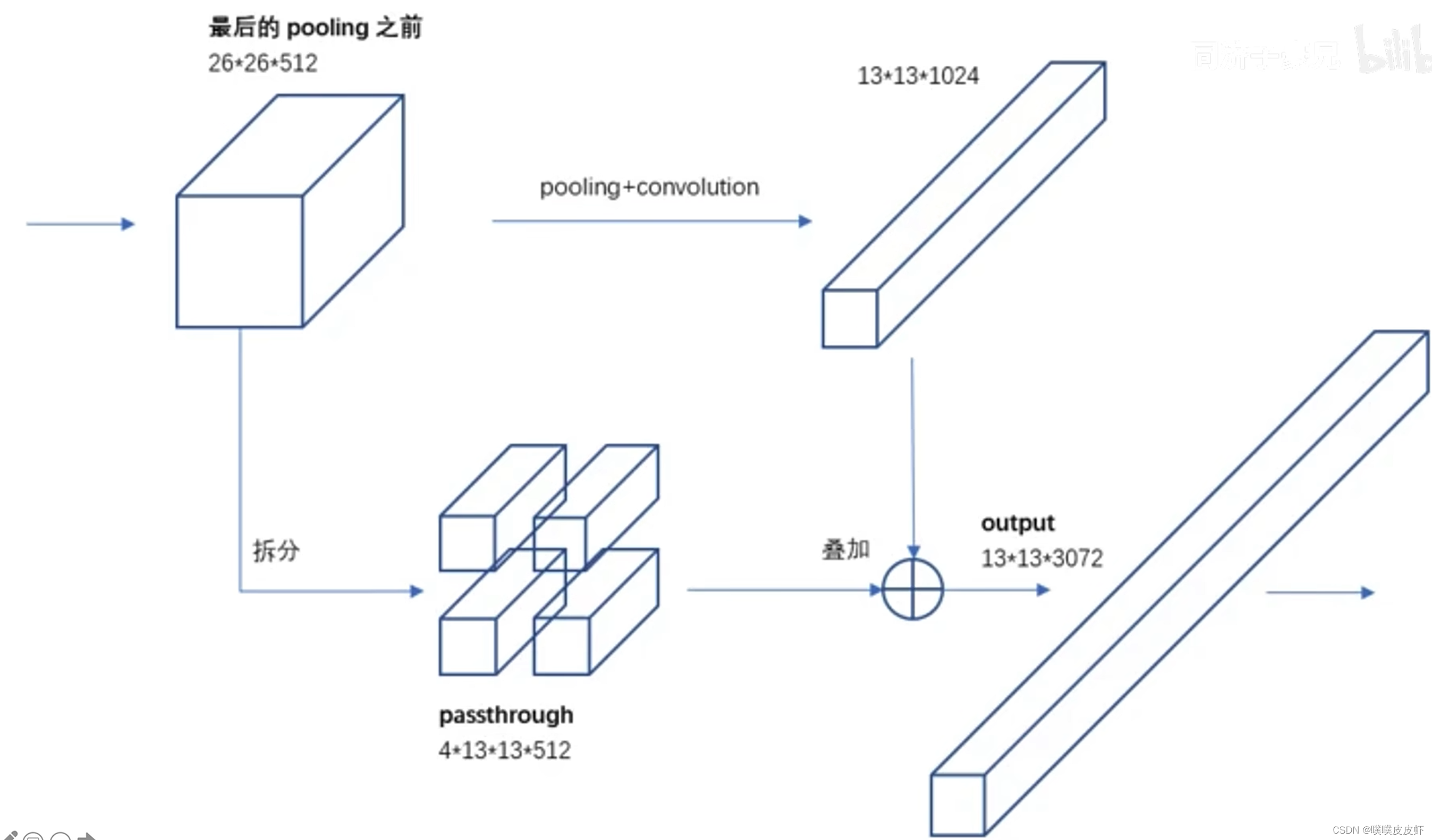
细粒度的特征:一个feature map,也就是在最后的池化之前,分成两路:一路是做拆分,分成四块,四块拼成一个长条,另一个是做正常的池化卷积操作,最后两个长条叠加输出。
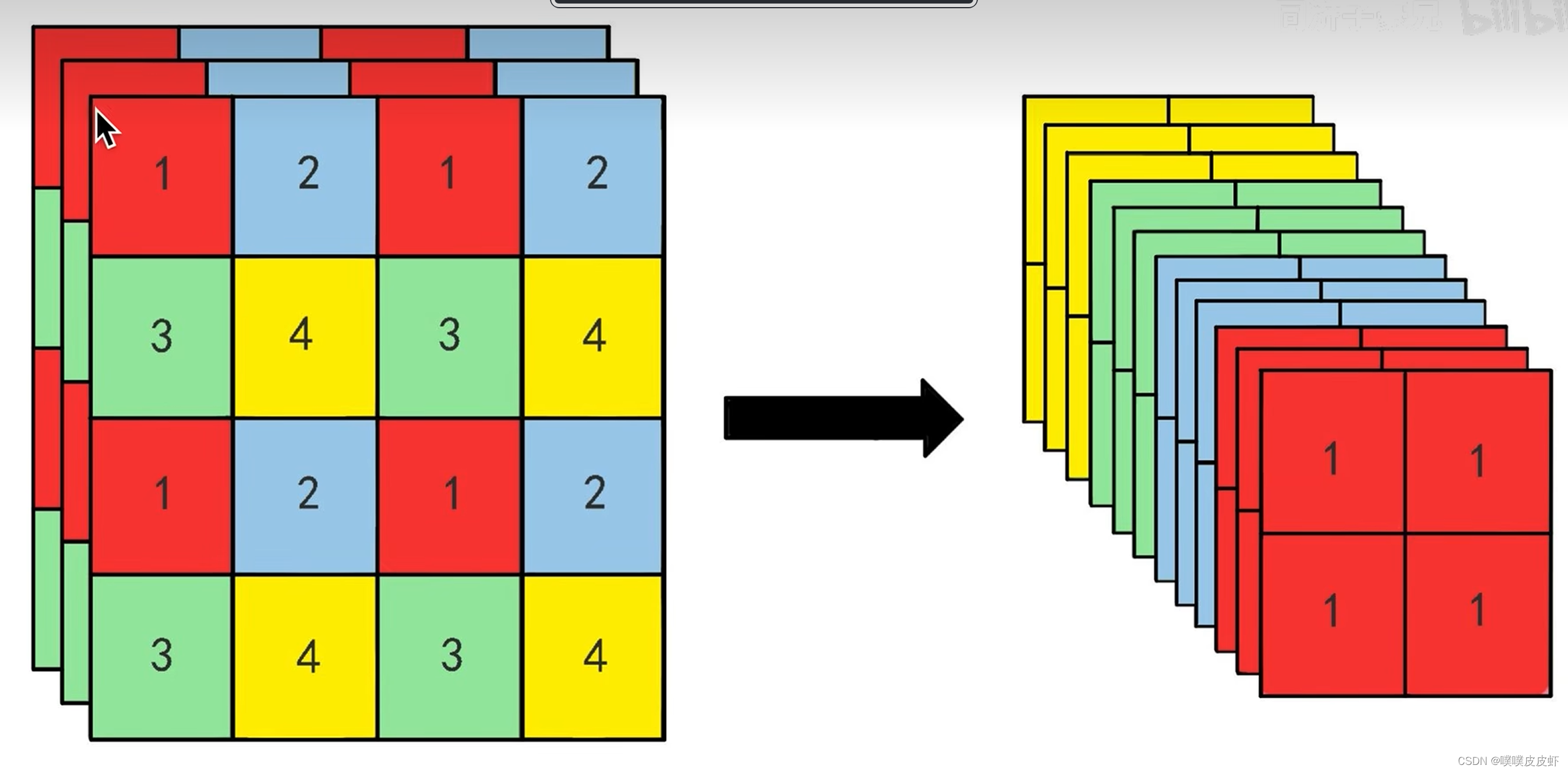
1.6 Multi-Scale Training—多尺度的训练
后续更新(不想写了,日常发疯,反正我自用QAQ)
三、Faster—更快
后面再写。。。
四、Stronger—种类更多(YOLO9000部分)
后面再写。。。
总结
学习的是b站同济子豪兄:链接在此















 1712
1712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









