






目录
一.数据介绍与读取
数据介绍:选取数据为2018年1月1日~12 月 31日北京市的空气质量数据。空气质量指数(Air Quality Index ,AQI)用来描述空气质量状况,指数的数值越大说明空气污染状况越严重。参与空气质量评价的主要污染物有细颗粒物(PM 2.5)、可吸入颗粒物(PM10)、二氧化硫(SO2)、一氧化碳(CO)、二氧化氮(NO2)、臭氧浓度(03)等6项,根据空气质量指数将空气质量分为6级:优(0-50)良(51-100),轻度污染(101150),中度污染(151-200),重度污染(201-300),严重污染(300 以上):分别用绿色、黄色、橙色、红色、紫色、褐红色表示。
data4_1<-read.csv("./mydata/chap04/data4_1.csv")
head(data4_1)日期 AQI 质量等级 PM2.5 PM10 二氧化硫 一氧化碳 二氧化氮 臭氧浓度
1 2018/1/1 60 良 33 61 10 1.1 48 41
2 2018/1/2 49 优 27 49 7 0.9 35 50
3 2018/1/3 29 优 11 28 5 0.4 23 55
4 2018/1/4 44 优 15 29 5 0.5 35 42
5 2018/1/5 69 良 32 53 9 1.0 55 39
6 2018/1/6 52 良 16 29 6 0.6 41 53
str(data4_1) #显示数据内部结构'data.frame': 365 obs. of 9 variables:
$ 日期 : chr "2018/1/1" "2018/1/2" "2018/1/3" "2018/1/4" ...
$ AQI : int 60 49 29 44 69 52 59 55 35 35 ...
$ 质量等级: chr "良" "优" "优" "优" ...
$ PM2.5 : int 33 27 11 15 32 16 38 12 7 6 ...
$ PM10 : int 61 49 28 29 53 29 57 60 34 20 ...
$ 二氧化硫: int 10 7 5 5 9 6 11 4 3 3 ...
$ 一氧化碳: num 1.1 0.9 0.4 0.5 1 0.6 0.9 0.3 0.3 0.3 ...
$ 二氧化氮: int 48 35 23 35 55 41 47 12 14 10 ...
$ 臭氧浓度: int 41 50 55 42 39 53 55 66 69 69 ...
二.直方图与核密度图
1.直方图
直方图(histogram)是观察数据分布特征的常用图形,它们可以直观地展示数据分布的形状是否对称,偏斜的方向和程度等。
将数据分组后,在X轴上用矩形的宽度表示每个组的组距,在Y轴上用矩形的高度表示每个组的频数或密度,多个矩形并列在一起就是直方图
R中有很多函数可以绘制直方图,比如,graphics中的 hist 函数、 lattice 包中的 histogram 函数、sjPlot 包中的 plot frq 函数、epade 包中的 histogram.ade函数
(1)普通直方图
#图1 AQI的直方图
attach(data4_1) #绑定数据集
par(mfrow=c(2,2),mai=c(0.4,0.5,0.4,0.1),cex=0.7,mgp=c(2,1,0),cex.main=0.8)
hist(AQI,labels=TRUE,xlab="AQI",ylab="频数",ylim=c(0,80),main="(a) 添加频数标签") # 添加频数标签
hist(AQI,breaks=20,col="deepskyblue",xlab="AQI",ylab="频数",main="(b) 将数据分成20组") # 将数据分成20组
hist(AQI,freq=FALSE,breaks=20,col="lightgreen",xlab="AQI",ylab="密度",main="(c) 添加地毯图、核密度线和统计量")
rug(AQI) # 添加地毯图
lines(density(AQI)) # 添加核密度曲线
points(quantile(AQI),c(0,0,0,0,0),pch=19,col="red",lwd=3)
# 添加最大值、最小值、中位数和四分位数
hist(AQI,prob=TRUE,breaks=20,col="pink",xlab="AQI",ylab="密度",main="(d) 添加扰动点和正态分布曲线")
rug(jitter(AQI)) # 添加扰动点
curve(dnorm(x,mean(AQI),sd(AQI)),col="blue",add=TRUE) # 添加理论正态分布线 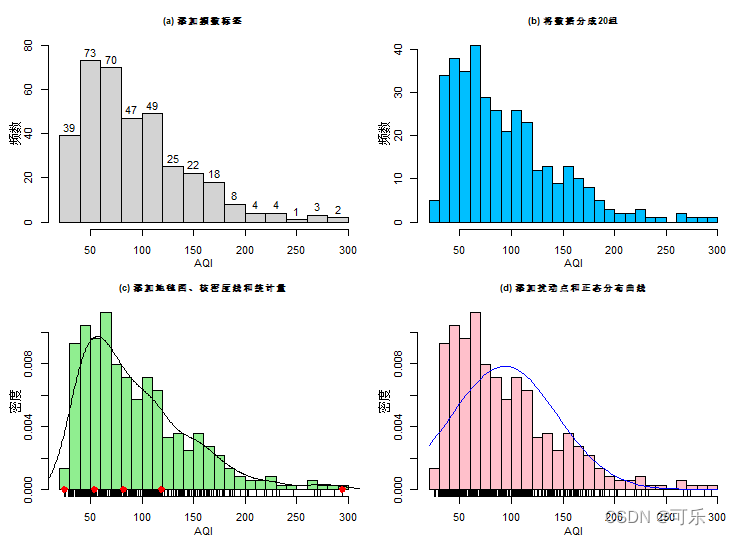
# 图2 带有均值和标准差信息的AQI的直方图
library(sjPlot)
set_theme(title.size=0.8, # 设置图形标题字体大小
axis.title.size=0.8, # 设置坐标轴标题字体大小
axis.textsize=0.8, # 设置坐标轴字体大小
geom.label.size=2.5, # 设置图形标签字体大小
geom.alpha=0.8) # 设置颜色透明度
plot_frq(data4_1$AQI,type="histogram", # 绘制直方图
show.mean=TRUE,show.sd=TRUE, # 画出数据的均值和标准差
geom.colors="green4", # 设置直方图的颜色
title="AQI的直方图") # 添加标题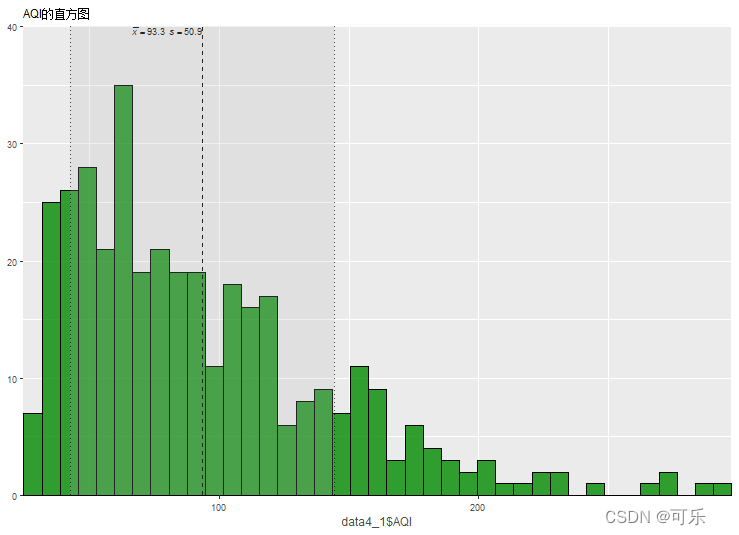
(2)叠加直方图和堆叠直方图
# 图3 AQI和PM2.5的叠加直方图
par(mfrow=c(1,1),mai=c(0.6,0.6,0.1,0.1),cex=0.7)
hist(data4_1$PM2.5,prob=TRUE,breaks=20,xlab="指标值",ylab="密度",col="deepskyblue",main="")
hist(data4_1$AQI,prob=TRUE,breaks=20,xlab="",ylab="",col="red2",density=60,main="",add=TRUE)
legend("topright",legend=c("PM2.5","AQI"),ncol=1,inset=0.04,
col=c("deepskyblue","red2"),density=c(200,60),
fill=c("deepskyblue","red2"),box.col="grey80",cex=0.8) # 添加图例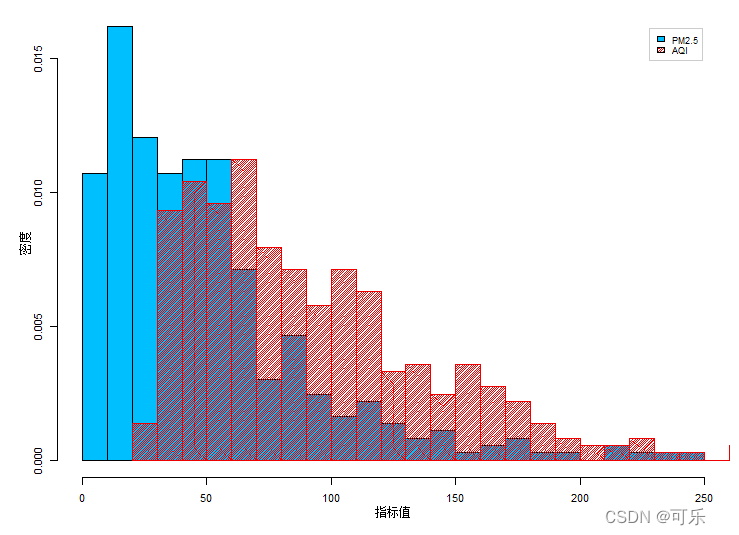
# 图4 按质量等级分类的PM2.5的叠加直方图
library(epade)
par(cex=0.9)
histogram.ade(PM2.5,group=质量等级,wall=4,breaks=30,bar=TRUE,alpha=0.4,main="按质量等级分类的PM2.5的直方图")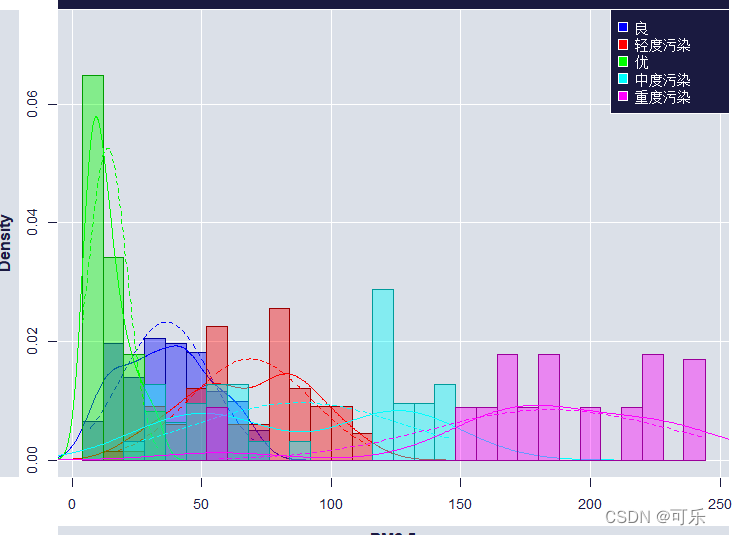
# 图5 按质量等级分类的PM10和臭氧浓度的堆叠直方图
par(mfrow=c(1,2),mai=c(0.8,0.5,0.1,0.1),cex=0.9)
library(plotrix)
cols=c("yellow2","orange","green","red","purple")
histStack(PM10~质量等级,data=data4_1,xlab="PM10",ylab="频数",ylim=c(0,80),col=cols,legend.pos="topright")
histStack(臭氧浓度~质量等级,data=data4_1,xlab="臭氧浓度",ylab="频数",xlim=c(0,300),ylim=c(0,70),col=cols,legend.pos="topright")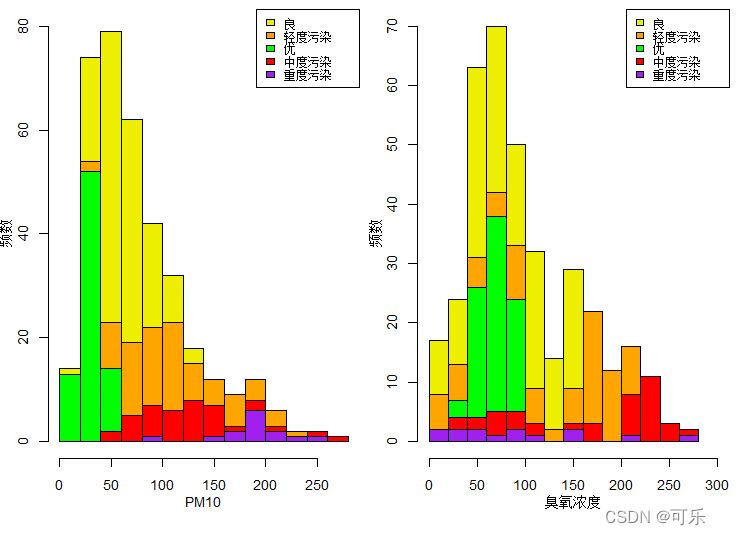
# 图6 6项空气污染指标的直方图
library(e1071)
par(mfrow=c(2,3),mai=c(0.5,0.5,0.2,0.1),mgp=c(2.5,1,0),cex=0.6,cex.main=1.2)
col<-"lightskyblue"
hist(PM2.5,prob=TRUE,breaks=10,col=col,xlab="PM2.5",main=paste("skewness =",round(skewness(PM2.5),digits=4)))
hist(PM10,prob=TRUE,col=col,xlab="PM10",main=paste("skewness =",round(skewness(PM10),digits=4)))
hist(二氧化硫,prob=TRUE,col=col,xlab="二氧化硫",main=paste("skewness =",round(skewness(二氧化硫),digits=4)))
hist(一氧化碳,prob=TRUE,col=col,xlab="一氧化碳",main=paste("skewness =",round(skewness(一氧化碳),digits=4)))
hist(二氧化氮,prob=TRUE,col=col,xlab="二氧化氮",main=paste("skewness =",round(skewness(二氧化氮),digits=4)))
hist(臭氧浓度,prob=TRUE,col=col,xlab="臭氧浓度",main=paste("skewness =",round(skewness(臭氧浓度),digits=4)))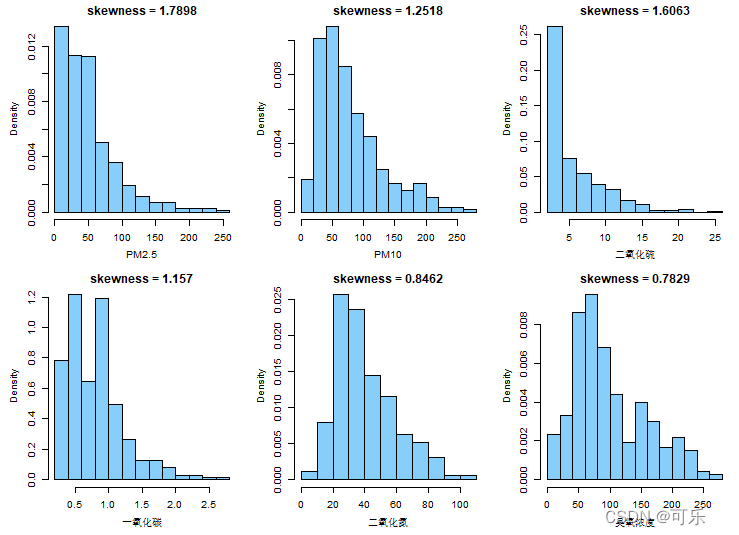
2.核密度图
核密度图(kernel density plot)是对核密度估计的一种图形描述
使用一定的核函数和带宽为数据的分布提供了一种平滑曲线,从中可以看出数据分布的大致形状与直方图相比,核密度估计则给出较为精确的估计
可以替代直方图来观察数据的分布
(1)核密度图与核密度比较图
# 图7 不同带宽的AQI的核密度曲线图
par(mfrow=c(1,3),mai=c(0.6,0.6,0.2,0.1),cex=0.9,cex.main=1)
d1<-density(data4_1$AQI) # 计算AQI的密度
d2<-density(data4_1$AQI,bw=3) # 计算AQI的密度,dw=3
d3<-density(data4_1$AQI,bw=10) # 计算AQI的密度,dw=3
plot(d1,xlab="AQI",ylab="Density",main="(a) 默认带宽")
plot(d2,col="red",xlab="AQI",ylab="Density",main="(b) bw=3")
polygon(d2,col="orange",border="black")
plot(d3,col="red",xlab="AQI",ylab="Density",main="(c) bw=10")
polygon(d3,col="orange",border="black")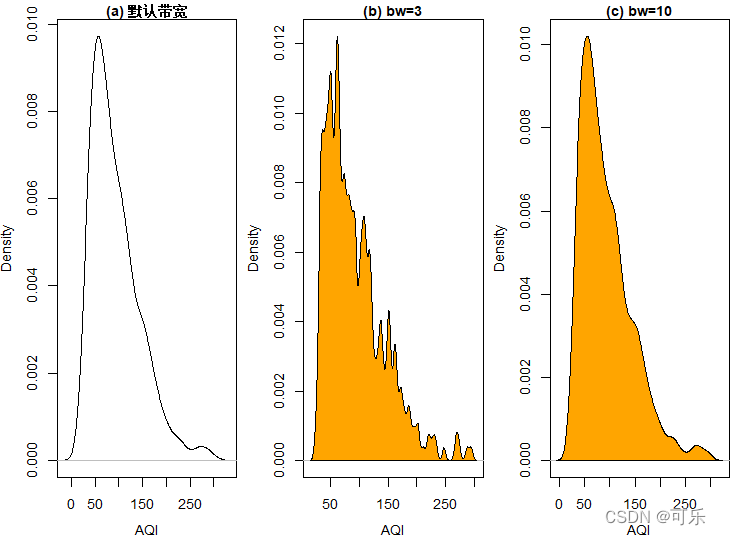
# 图8 带有直方图和理论正态分布曲线的AQI的核密度图
plot_frq(data4_1$AQI,type="density", # 绘制核密度曲线
normal.curve=TRUE,normal.curve.size=2, # 添加正态分布曲线
title="AQI的核密度图") 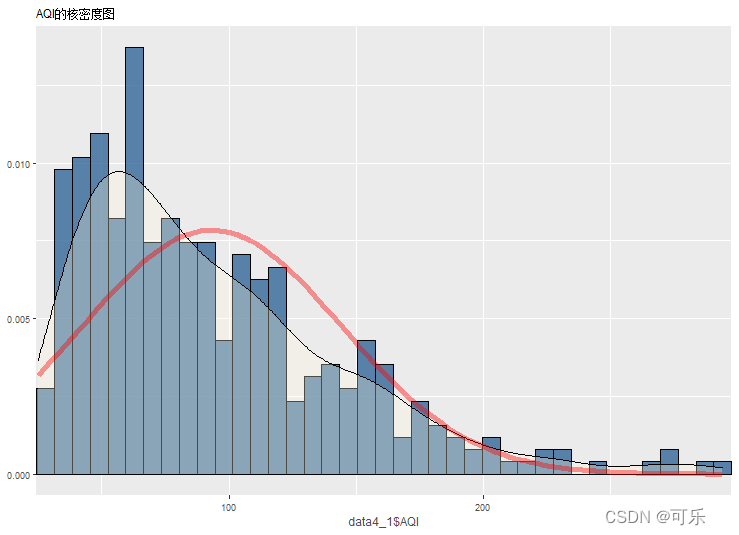
# 图9 AQI和4项空气污染指标的核密度比较图
library(reshape2)
library(gridExtra)
library(ggplot2)
d<-data4_1[,c(1,2,3,4,5,8,9)] # 选择绘制数据
head(d)日期 AQI 质量等级 PM2.5 PM10 二氧化氮 臭氧浓度
1 2018/1/1 60 良 33 61 48 41
2 2018/1/2 49 优 27 49 35 50
3 2018/1/3 29 优 11 28 23 55
4 2018/1/4 44 优 15 29 35 42
5 2018/1/5 69 良 32 53 55 39
6 2018/1/6 52 良 16 29 41 53
df<-melt(d,id.vars=c("日期","质量等级"),variable.name="指标",value.name="指标值") # 融合d与id变量
head(df)日期 质量等级 指标 指标值
1 2018/1/1 良 AQI 60
2 2018/1/2 优 AQI 49
3 2018/1/3 优 AQI 29
4 2018/1/4 优 AQI 44
5 2018/1/5 良 AQI 69
6 2018/1/6 良 AQI 52
# 设置图形主题
mytheme<-theme(plot.title=element_text(size="9"), # 设置主标题字体大小
axis.title=element_text(size=9), # 设置坐标轴标签字体大小
axis.text=element_text(size=8), # 设置坐标轴刻度字体大小
legend.position="right", # 设置图例的位置
legend.text=element_text(size="7")) # 设置图例字大小
# 绘制p1和p2
p1<-ggplot(df)+aes(x=指标值)+
geom_density(aes(group=指标,color=指标,fill=指标),alpha=0)+
mytheme+
ggtitle("(a) 核密度比较曲线(alpha=0)") # 添加标题
p2<-ggplot(df)+aes(x=指标值)+
geom_density(aes(group=指标,color=指标,fill=指标),alpha=0.3)+
mytheme+
ggtitle("(b) 核密度比较曲线(alpha=0.3)")
grid.arrange(p1,p2,ncol=2) # 组合图形p1和p2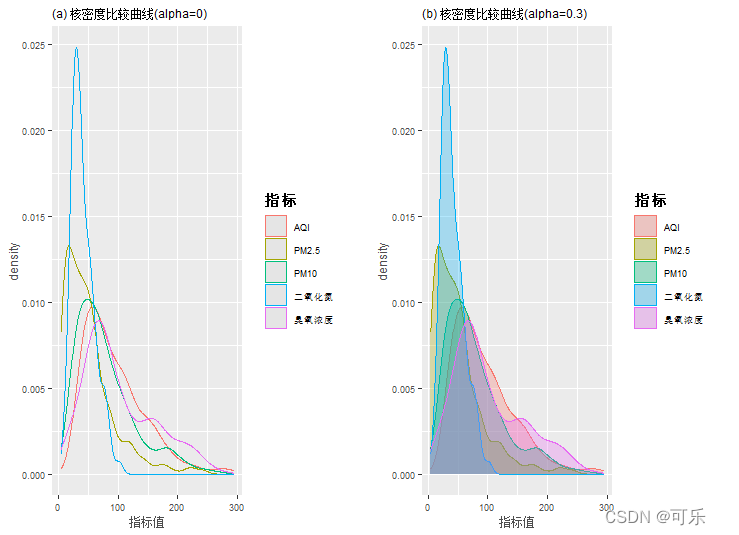
(2)分类核密度图
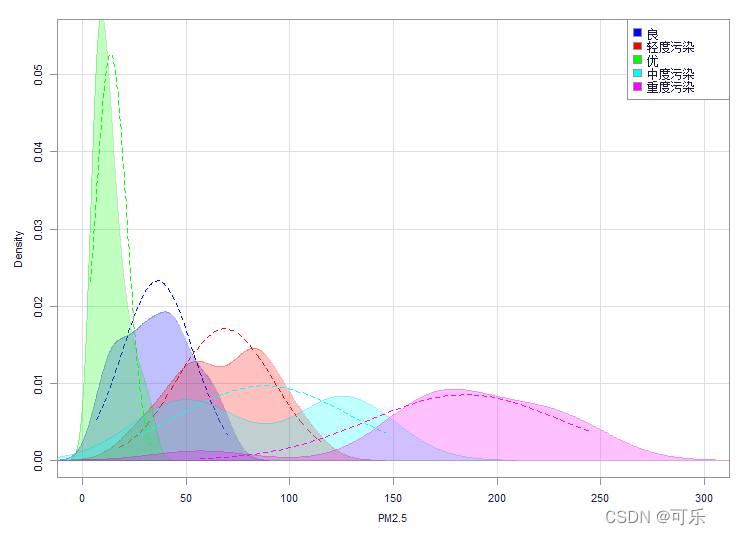
# 图10 按质量等级分类的PM2.5的核密度图
library(epade)
par(mfrow=c(1,1),cex=0.7)
histogram.ade(PM2.5,group=质量等级,wall=2,bar=FALSE,ylim=c(0,0.055),xlim=c(0,300))
# 图11 按质量等级分组,按指标分面的核密度图
library(ggplot2)
library(reshape2)
d<-data4_1[,c(1,2,3,4,5,8)] # 选择绘制数据
df<-melt(d,id.vars=c("日期","质量等级"),variable.name="指标",value.name="指标值") # 融合d与id变量
head(df)日期 质量等级 指标 指标值
1 2018/1/1 良 AQI 60
2 2018/1/2 优 AQI 49
3 2018/1/3 优 AQI 29
4 2018/1/4 优 AQI 44
5 2018/1/5 良 AQI 69
6 2018/1/6 良 AQI 52
ggplot(df)+aes(x=指标值)+
geom_density(aes(group=质量等级,color=质量等级,fill=质量等级),alpha=0.5)+
# 按质量等级分组
facet_grid(指标~.) # 按指标单列分面 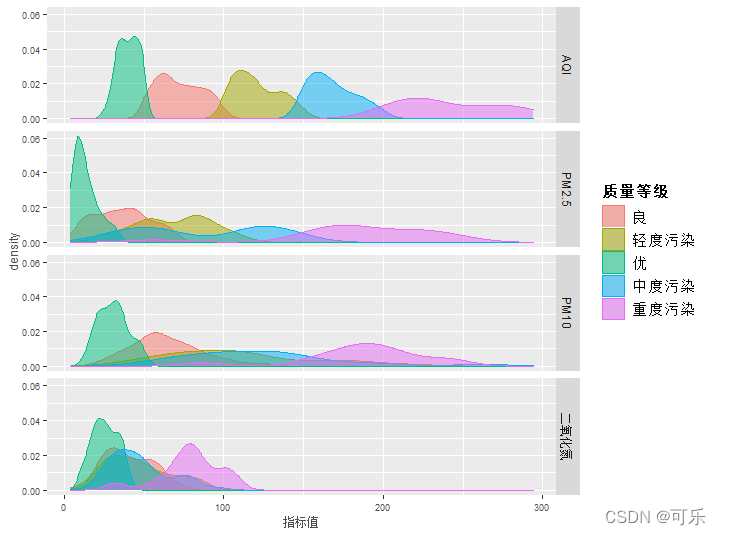
ggplot(df)+aes(x=指标值)+
geom_density(aes(group=指标,color=指标,fill=指标),alpha=0.5)+
# 按质量等级分组
facet_grid(质量等级~.) # 按指标单列分面
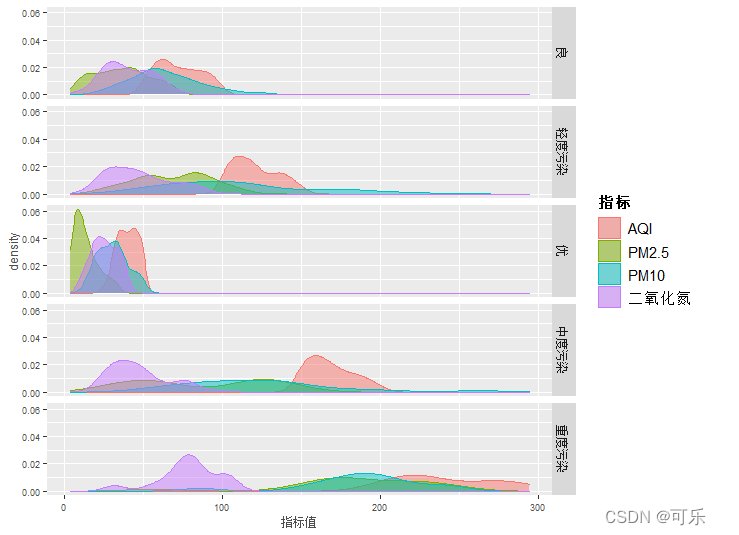
ggplot(df)+aes(x=指标值)+
geom_density(aes(group=质量等级,color=质量等级,fill=质量等级),alpha=0.5)+
# 按质量等级分组
facet_grid(指标~质量等级) # 按指标和质量等级两个因子分面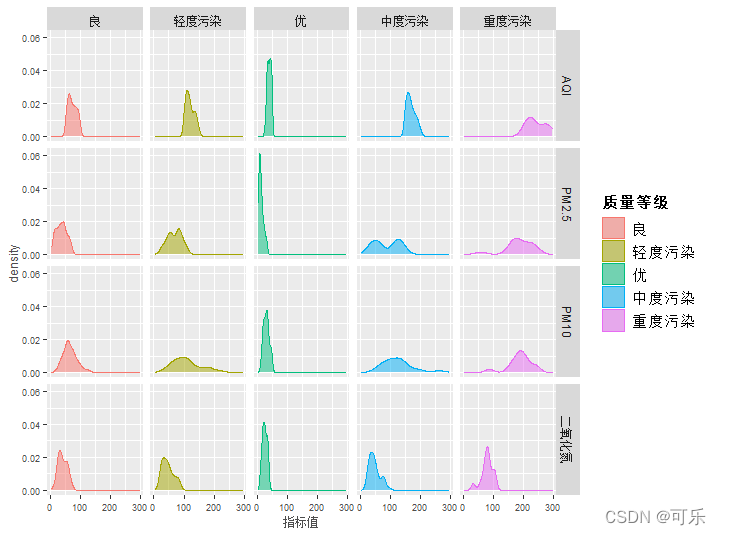
(3)核密度山峦图
山峦图(ridgeline diagram)也称山脊线图,它是核密度估计图的一种表现形式
可用于多数据系列或按因子分类的核密度估计的可视化
山峦图绘制的数据通常是相同的X轴(如同一个变量)和不同的Y轴(如不同的分类)
它将多个分类下的同一个数据系列的核密度估计图以交错堆叠的方式绘制在一幅图中,看起来像山峦起伏,从而有利于比较不同数据系列的分布特征
# 图12 按质量等级分类的AQI的山峦图
# 2018年北京市AQI的山峦图
library(ggridges)
library(ggplot2)
ggplot(data4_1,aes(x=AQI,y=质量等级,fill=质量等级,height=..density..))+
# 设置X轴、Y轴混和填充变量,高度为密度
geom_density_ridges(scale=4,stat="density")+ # 绘制核密度山峦图
scale_fill_brewer(palette=4)+ # 设置配色方案
theme_ridges(font_size=10)+ # 设置图中文本字体大小
theme(legend.position="bottom")+ # 设置图例位置
labs(title="AQI的山峦图") # 设置主标题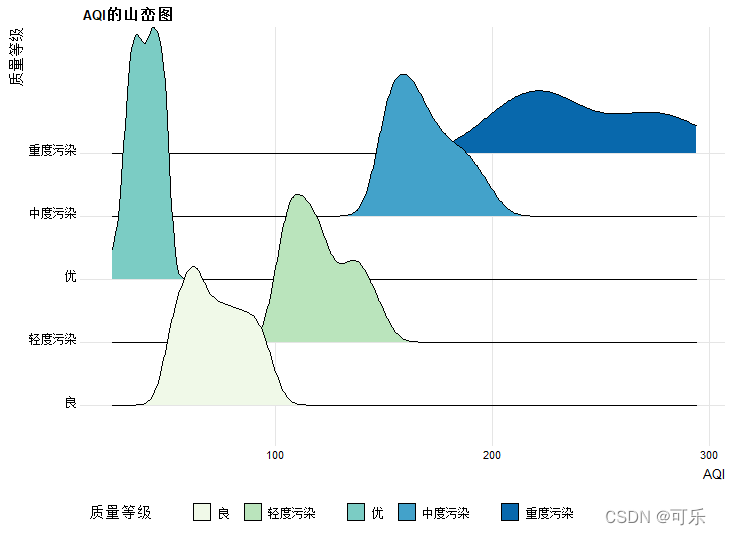
# 图13 按质量等级分类的PM10的山峦图
ggplot(data4_1,aes(x=PM10,y=质量等级,fill=..density..))+ # 填充为密度
geom_density_ridges_gradient(scale=3,rel_min_height=0.01)+
scale_x_continuous(expand=c(0.01,0))+ # 设置X轴(连续)扩展范围
scale_y_discrete(expand=c(0.01,0))+ # 设置Y轴(离散)扩展范围
scale_fill_viridis_c(name="density",option="C")+
# 设置要使用颜色映射的字符串和配色选项
labs(title="PM10的山峦图")+ # 设置主标题
theme_ridges(font_size=10,grid=TRUE)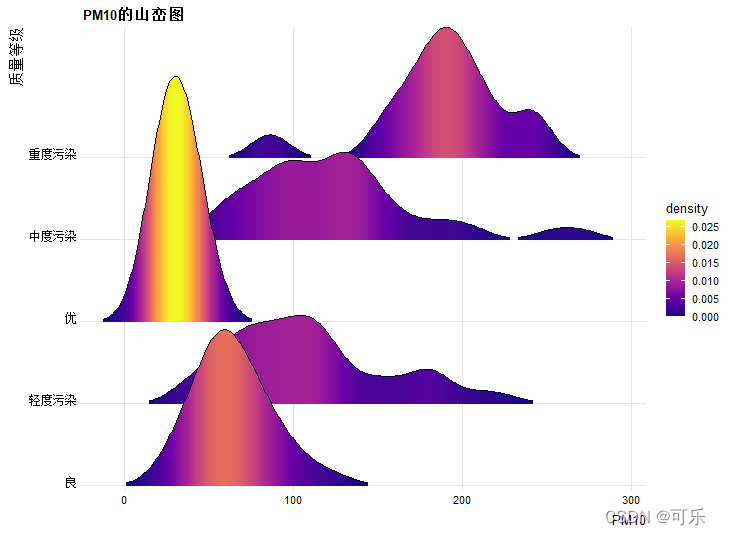
# 图14 各月份臭氧浓度的山峦图
library(RColorBrewer)
a<-c(rep("1月",31),rep("2月",28),rep("3月",31),rep("4月",30),
rep("5月",31),rep("6月",30),rep("7月",31),rep("8月",31),
rep("9月",30),rep("10月",31),rep("11月",30),rep("12月",31))
a[1] "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月"
[15] "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月" "1月"
[29] "1月" "1月" "1月" "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月"
[43] "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月" "2月"
[57] "2月" "2月" "2月" "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月"
[71] "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月" "3月"
[85] "3月" "3月" "3月" "3月" "3月" "3月" "4月" "4月" "4月" "4月" "4月" "4月" "4月" "4月"
[99] "4月" "4月" "4月" "4月" "4月" "4月" "4月" "4月" "4月" "4月" "4月" "4月" "4月" "4月"
[113] "4月" "4月" "4月" "4月" "4月" "4月" "4月" "4月" "5月" "5月" "5月" "5月" "5月" "5月"
[127] "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月"
[141] "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月" "5月" "6月" "6月" "6月"
[155] "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月"
[169] "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "6月" "7月"
[183] "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月"
[197] "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月" "7月"
[211] "7月" "7月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月"
[225] "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月" "8月"
[239] "8月" "8月" "8月" "8月" "8月" "9月" "9月" "9月" "9月" "9月" "9月" "9月" "9月" "9月"
[253] "9月" "9月" "9月" "9月" "9月" "9月" "9月" "9月" "9月" "9月" "9月" "9月" "9月" "9月"
[267] "9月" "9月" "9月" "9月" "9月" "9月" "9月" "10月" "10月" "10月" "10月" "10月" "10月" "10月"
[281] "10月" "10月" "10月" "10月" "10月" "10月" "10月" "10月" "10月" "10月" "10月" "10月" "10月" "10月"
[295] "10月" "10月" "10月" "10月" "10月" "10月" "10月" "10月" "10月" "10月" "11月" "11月" "11月" "11月"
[309] "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月"
[323] "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "11月" "12月" "12月"
[337] "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月"
[351] "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月" "12月"
[365] "12月"
# 生成每天数据对应的月份因子
b<-c("1月","2月","3月","4月","5月","6月","7月","8月","9月","10月","11月","12月") # 生成月份因子
f<-factor(a,ordered=TRUE,levels=b) # 将月份变为有序因子
f[1] 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月
[21] 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 1月 2月 2月 2月 2月 2月 2月 2月 2月 2月
[41] 2月 2月 2月 2月 2月 2月 2月 2月 2月 2月 2月 2月 2月 2月 2月 2月 2月 2月 2月 3月
[61] 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月
[81] 3月 3月 3月 3月 3月 3月 3月 3月 3月 3月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月
[101] 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月 4月
[121] 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月
[141] 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 5月 6月 6月 6月 6月 6月 6月 6月 6月 6月
[161] 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月 6月
[181] 6月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月
[201] 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 7月 8月 8月 8月 8月 8月 8月 8月 8月
[221] 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月 8月
[241] 8月 8月 8月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月
[261] 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 9月 10月 10月 10月 10月 10月 10月 10月
[281] 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月 10月
[301] 10月 10月 10月 10月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月
[321] 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 11月 12月 12月 12月 12月 12月 12月
[341] 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月 12月
[361] 12月 12月 12月 12月 12月
Levels: 1月 < 2月 < 3月 < 4月 < 5月 < 6月 < 7月 < 8月 < 9月 < 10月 < 11月 < 12月
df<-data.frame(月份=f,data4_1) # 构建新的数据框
head(df)月份 日期 AQI 质量等级 PM2.5 PM10 二氧化硫 一氧化碳 二氧化氮 臭氧浓度
1 1月 2018/1/1 60 良 33 61 10 1.1 48 41
2 1月 2018/1/2 49 优 27 49 7 0.9 35 50
3 1月 2018/1/3 29 优 11 28 5 0.4 23 55
4 1月 2018/1/4 44 优 15 29 5 0.5 35 42
5 1月 2018/1/5 69 良 32 53 9 1.0 55 39
6 1月 2018/1/6 52 良 16 29 6 0.6 41 53
palette<-rev(brewer.pal(11,"Spectral")) # 设置调色板
ggplot(df,aes(x=臭氧浓度,y=月份,fill=..density..))+
geom_density_ridges_gradient(scale=3,rel_min_height=0.01)+
scale_x_continuous(expand=c(0.01,0))+
scale_y_discrete(expand=c(0.01,0))+
scale_fill_gradientn(colors=palette)+ # 使用梯度调色板
theme_ridges(font_size=10,grid=TRUE)+
labs(title="臭氧浓度的山峦图")+
theme(axis.title.y=element_blank()) # 去掉Y轴标题 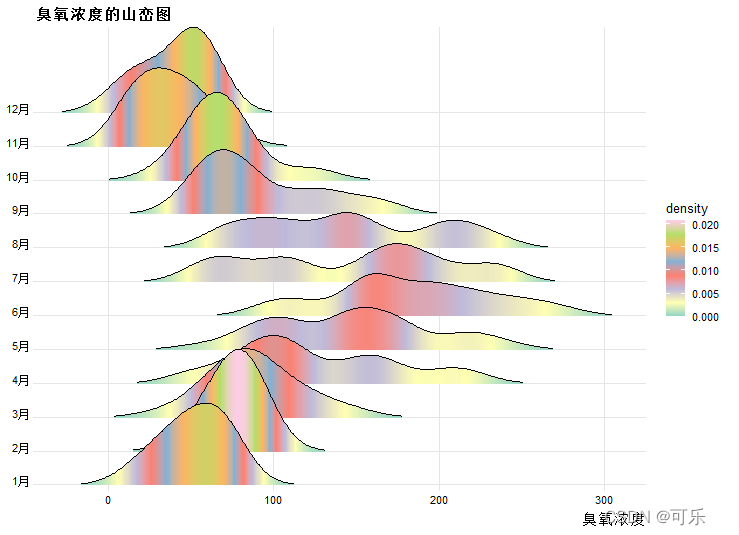
# 图15 AQI和6项空气污染指标标准化后的山峦图
library(RColorBrewer)
library(ggridges)
library(ggplot2)
d<-data4_1[,c(1:2,4:9)] # 选择data4_1中的第1:2列和第4:9列
head(d)日期 AQI PM2.5 PM10 二氧化硫 一氧化碳 二氧化氮 臭氧浓度
1 2018/1/1 60 33 61 10 1.1 48 41
2 2018/1/2 49 27 49 7 0.9 35 50
3 2018/1/3 29 11 28 5 0.4 23 55
4 2018/1/4 44 15 29 5 0.5 35 42
5 2018/1/5 69 32 53 9 1.0 55 39
6 2018/1/6 52 16 29 6 0.6 41 53
dz<-scale(d[,2:8]) # 标准化数据框
class(dz)[1] "matrix" "array"
df<-data.frame(日期=d[,1],dz) # 构建新的数据框
head(df)日期 AQI PM2.5 PM10 二氧化硫 一氧化碳 二氧化氮 臭氧浓度
1 2018/1/1 -0.6546731 -0.4041212 -0.3525141 1.0120586 0.5961085 0.378631934 -1.0024765
2 2018/1/2 -0.8709226 -0.5454539 -0.5936153 0.2820163 0.1341561 -0.306573454 -0.8501787
3 2018/1/3 -1.2641035 -0.9223412 -1.0155424 -0.2046785 -1.0207251 -0.939070736 -0.7655688
4 2018/1/4 -0.9692178 -0.8281194 -0.9954506 -0.2046785 -0.7897488 -0.306573454 -0.9855546
5 2018/1/5 -0.4777417 -0.4276767 -0.5132483 0.7687111 0.3651323 0.747588682 -1.0363205
6 2018/1/6 -0.8119454 -0.8045639 -0.9954506 0.0386689 -0.5587726 0.009675187 -0.7994128
library(reshape2)
# 将新数据框转化成长格式
df.long<-melt(df,id.vars="日期",variable.name="指标",value.name="标准化值")
head(df.long)日期 指标 标准化值
1 2018/1/1 AQI -0.6546731
2 2018/1/2 AQI -0.8709226
3 2018/1/3 AQI -1.2641035
4 2018/1/4 AQI -0.9692178
5 2018/1/5 AQI -0.4777417
6 2018/1/6 AQI -0.8119454
palette<-rev(brewer.pal(11,"Spectral")) # 设置调色板
ggplot(df.long,aes(x=标准化值,y=指标,fill=..density..))+
geom_density_ridges_gradient(scale=3,rel_min_height=0.01)+
scale_x_continuous(expand=c(0.01,0))+
scale_y_discrete(expand=c(0.01,0))+
scale_fill_gradientn(colors=palette)+ # 使用梯度调色板
theme_ridges(font_size=10,grid=TRUE)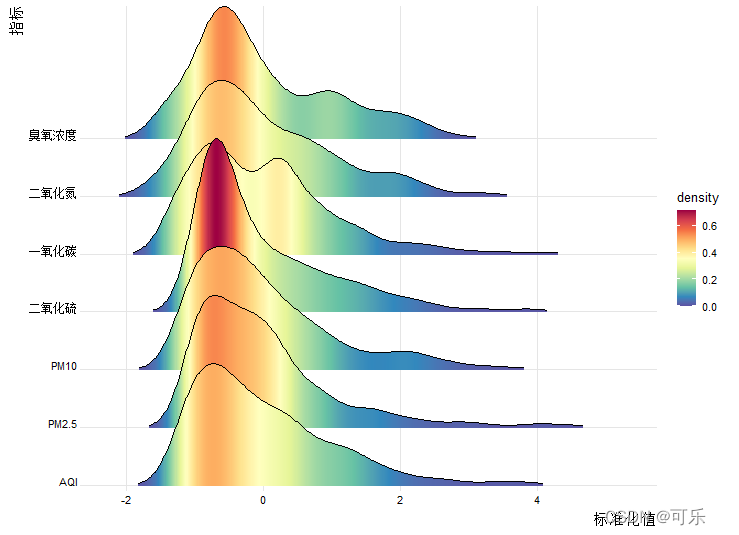
三.箱线图和小提琴图
1.箱线图
箱线图是展示数据分布的另一种图形
它不仅可用于反映一组数据分布的特征,比如,分布是否对称、是否存在离群点等,还可以用于 对多组数据的分布特征进行比较,这也是箱线图的主要用途
# 图18
data4_1<-read.csv("./mydata/chap04/data4_1.csv")
par(mai=c(0.7,0.7,0.1,0.1),cex=0.7)
palette<-RColorBrewer::brewer.pal(6,"Set2") # 设置离散型调色板
boxplot(data4_1[,4:9],xlab="指标",col=palette,ylab="指标值")
points((apply(data4_1[,4:9],2,mean)),col="black",cex=1,pch=3) # 画出均值点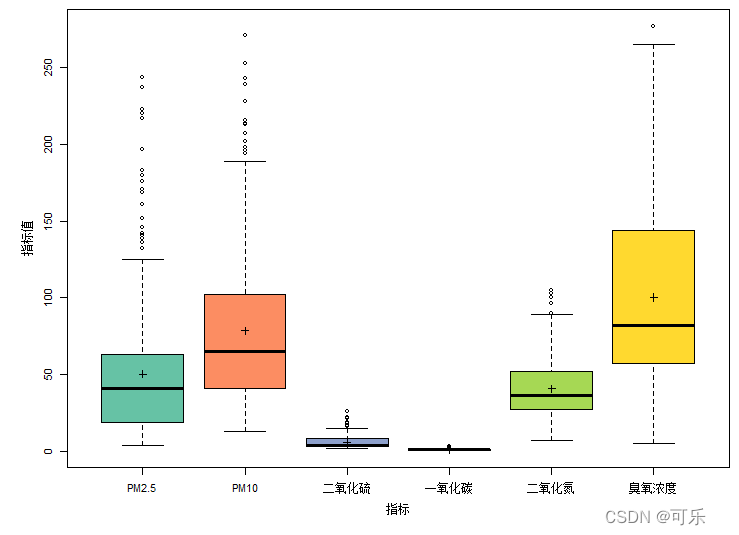
#图19 对数变换和标准化变换效果的箱线图比较
par(mfrow=c(1,3),mai=c(0.6,0.3,0.6,0.1),cex=0.7,mgp=c(1.5,1,0))
set.seed(123)
x<-rnorm(100,100,30)
y<-x/10 # y是x的十分之一,但离散程度相同
df<-data.frame(x,y)
boxplot(df,col=c("red","green"),main="(a) 变换前")
boxplot(df,log="y",col=c("red","green"),main="(b) 对数变换后")
dt<-data.frame(scale(df)) # 标准化变换后组织成数据框
boxplot(dt,col=c("red","green"),main="(c) 标准化变换后")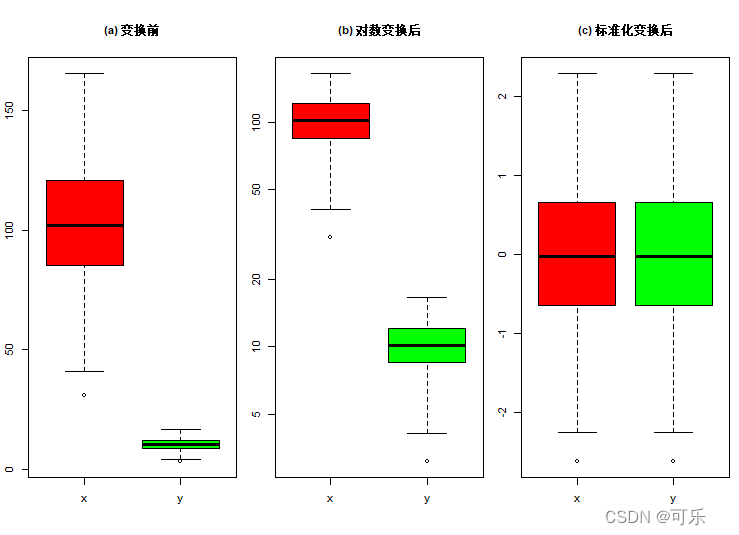
# 图20 对数变换和标准化变换后的6项空气污染指标的箱线图
data4_1<-read.csv("./mydata/chap04/data4_1.csv")
par(mfcol=c(2,1),mai=c(0.6,0.6,0.2,0.1),cex=0.7,cex.main=1)
d<-data4_1[,4:9]
palette<-RColorBrewer::brewer.pal(6,"Set2") # 设置调色板
boxplot(d,xlab="指标",log="y",col=palette,ylab="对数变换后的值",main="(a) 对数变换后的箱线图")
dt<-data.frame(scale(d))
boxplot(dt,col=palette,xlab="指标",ylab="标准化值",main="(b) 标准化变换后的箱线图")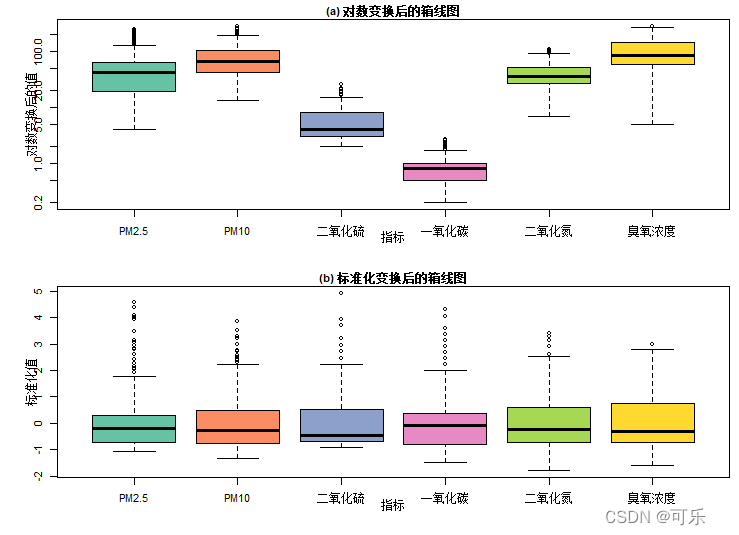
# 图21 按质量等级分类的臭氧浓度的箱线图
library(gplots)
f<-factor(data4_1$质量等级,ordered=TRUE,levels=c("优","良","轻度污染","中度污染","重度污染")) # 将质量等级变为有序因子
df<-data.frame(质量等级=f,data4_1[,-3]) # 构建新的数据框
head(df)质量等级 日期 AQI PM2.5 PM10 二氧化硫 一氧化碳 二氧化氮 臭氧浓度
1 良 2018/1/1 60 33 61 10 1.1 48 41
2 优 2018/1/2 49 27 49 7 0.9 35 50
3 优 2018/1/3 29 11 28 5 0.4 23 55
4 优 2018/1/4 44 15 29 5 0.5 35 42
5 良 2018/1/5 69 32 53 9 1.0 55 39
6 良 2018/1/6 52 16 29 6 0.6 41 53
par(mfcol=c(1,1),mai=c(0.6,0.6,0.2,0.2),cex=0.7)
cols=c("green","yellow","orange","red","purple") # 设置颜色向量
boxplot2(data=df,臭氧浓度~质量等级,top=TRUE, # 将样本量信息放在图的上方
shrink=1.2,textcolor=cols, # 设置样本量文本字体的大小和颜色
col=cols,varwidth=TRUE, # 设置箱线图的颜色和箱宽
xlab="质量等级",ylab="臭氧浓度") 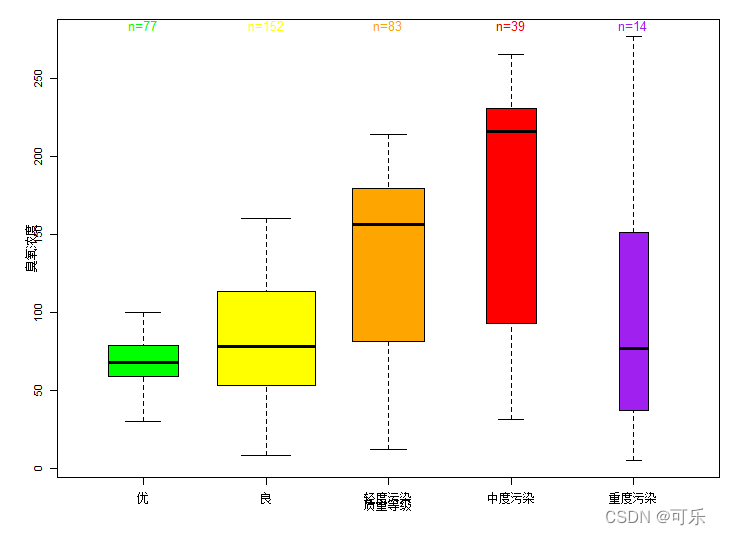
# 图22 按质量等级分类的AQI、PM2.5和二氧化硫的箱线图
library("ggiraphExtra")
require(ggplot2)
ggBoxplot(data4_1,aes(x=c(AQI,PM2.5,二氧化硫),fill=质量等级),rescale=TRUE)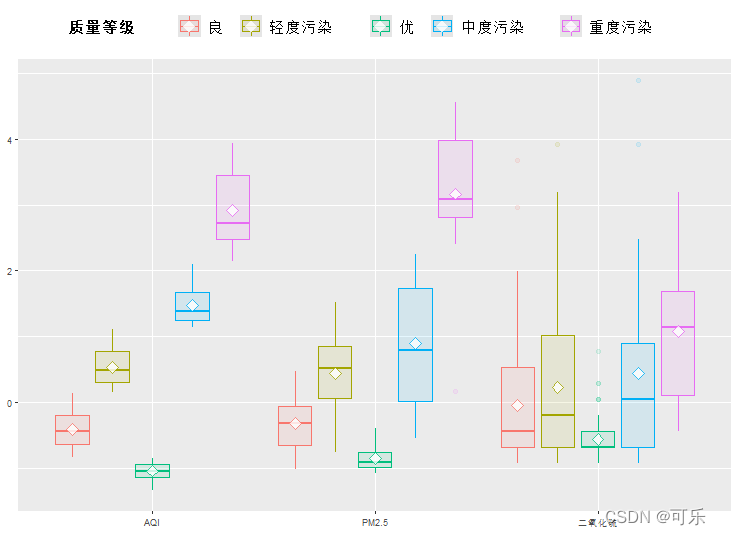
2.小提琴图
小提琴图作为箱线图的一个变种,将分布的核密度估计图与箱线图结合在一起
它在箱线图上以镜像方式叠加上核密度估计图,以显示数据分布的大致形状
小提琴图可作为箱线图的最佳替代图形
# 图23 6项空气污染指标的小提琴图
library(vioplot)
df<-data4_1[,4:9]
par(mai=c(0.6,0.6,0.1,0.1),cex=0.7)
palette<-RColorBrewer::brewer.pal(6,"Set2") # 设置调色板
names=c("PM2.5","PM10","二氧化硫","一氧化碳","二氧化氮","臭氧浓度")
# 设置名称向量
vioplot(df,col=palette,names=names,xlab="指标",ylab="指标值")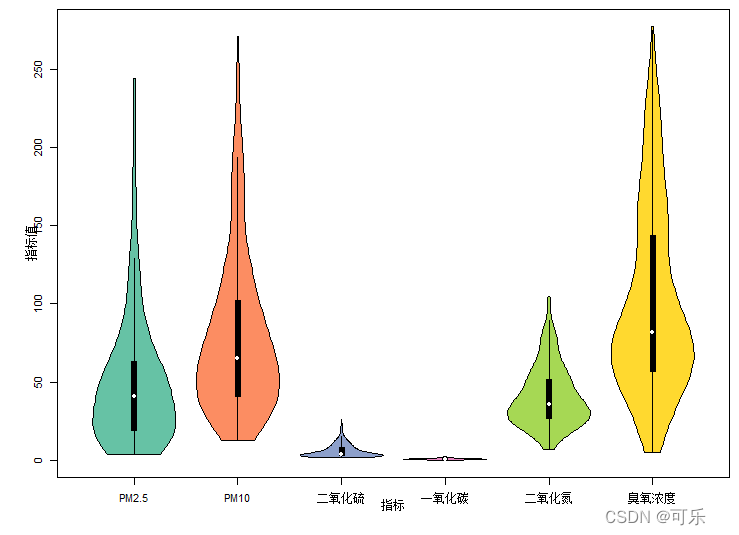
# 图24 对数变换和标准化变换后的6项指标的小提琴图
palette<-RColorBrewer::brewer.pal(6,"Set2") # 设置调色板
# 对数变换
dt<-log10(data4_1[,4:9]) # 做以10为底的对数变换
library(vioplot)
par(mfcol=c(2,1),mai=c(0.4,0.4,0.2,0.1),cex=0.7,cex.main=1)
names=c("PM2.5","PM10","二氧化硫","一氧化碳","二氧化氮","臭氧浓度")
vioplot(dt,col=palette,names=names)
title("(a) 对数变换后的小提琴图")
# 标准化变换
sdt<-data.frame(scale(data4_1[,4:9])) # 做标准化变换并转化成数据框
vioplot(sdt,col=palette,names=names)
title("(b) 标准化变换后的小提琴图")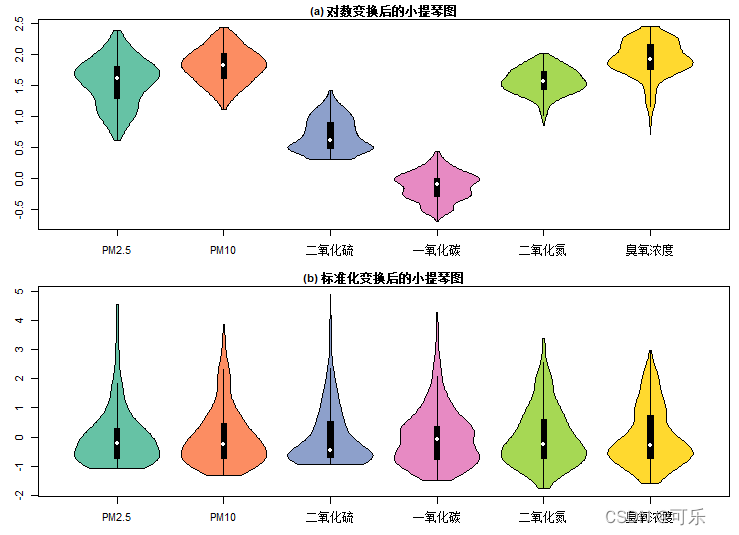
# 图25 7项指标原始数据和标准化变换后数据的小提琴图
library("ggiraphExtra")
require(ggplot2)
library(gridExtra)
# 绘制7个指标的小提琴图p1和p2
mytheme<-theme(plot.title=element_text(size="10"),
legend.position="none") # 设置图形主题
p1<-ggViolin(data4_1,alpha=0.3,rescale=FALSE)+ # 使用原始数据
mytheme+ggtitle("(a) 原始数据小提琴图") # 使用主题和添加标题
p2<-ggViolin(data4_1,alpha=0.3,rescale=TRUE)+ # 使用标准化变换后的数据
mytheme+ggtitle("(b) 变换后数据小提琴图")
grid.arrange(p1,p2,ncol=1) # 按1列组合图形p1和p2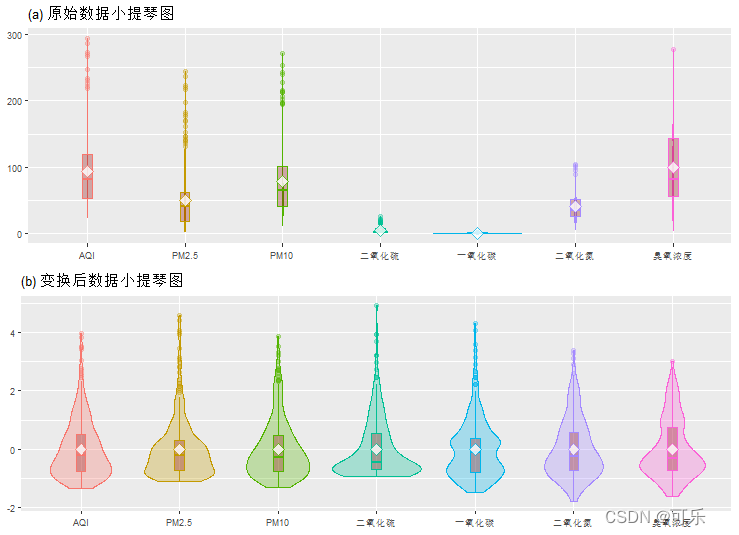
# 图26 按质量等级分组的AQI、PM2.5和二氧化硫浓度的小提琴图
ggiraphExtra::ggViolin(data4_1,aes(x=c(AQI,PM2.5,二氧化硫),fill=质量等级),alpha=0.3,rescale=TRUE)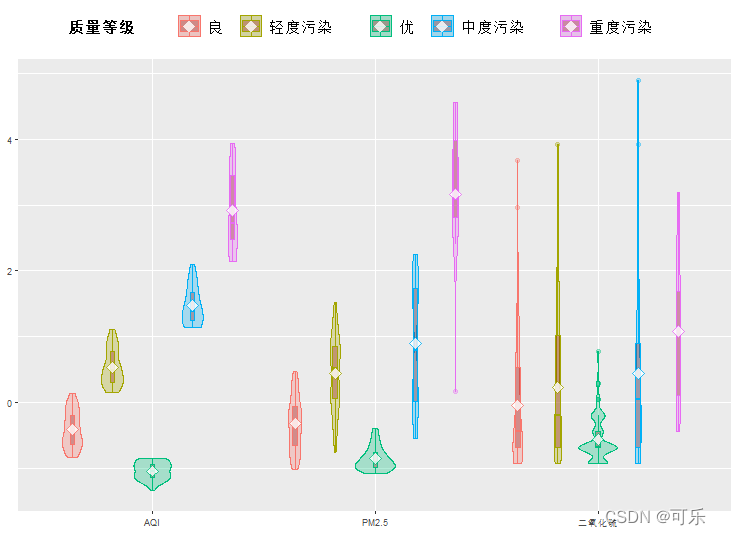
四.点图、带状图和太阳花图
1.点图
点图 (dot plot)是将各数据用点绘制在图中
点图有多种形式,其中最常见的是克利夫兰(Cleveland)点图
点图是检测数据离群点的有效工具,当数据量较少时,也可以替代直方图和箱线图来观察数据的分布
# 图27 按质量等级分组的PM2.5的克利夫兰点图
par(mfcol=c(1,1))
data4_1<-read.csv("./mydata/chap04/data4_1.csv")
par(mai=c(0.6,0.6,0.2,0.2),cex=0.7,font=2)
cols=c("yellow2","orange","green","red","purple")
dotchart(data4_1$PM2.5,groups=as.factor(data4_1$质量等级),gcolor=cols,
lcolor="grey95",pch="o",col=cols[as.factor(data4_1$质量等级)],pt.cex=0.5,xlab="PM2.5")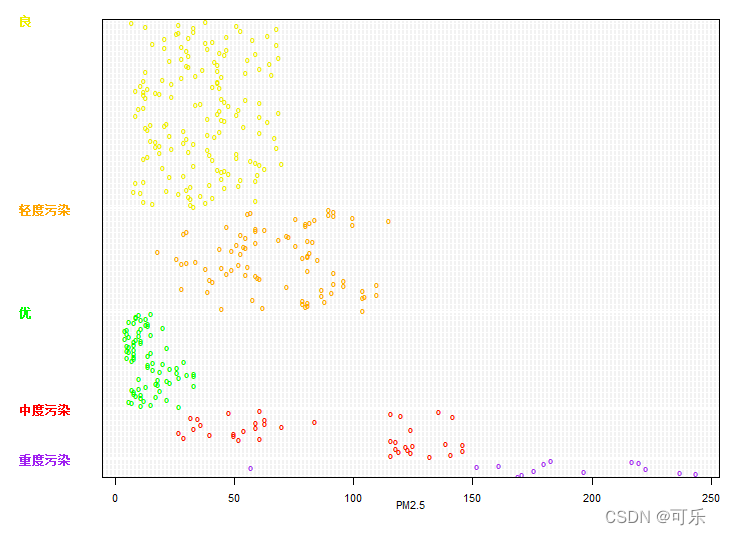
# 图28 以x轴为日期的AQI的克利夫兰点图
library(ggpubr)
d<-data4_1[274:304,] # 选择10月份的数据
ggdotchart(d,x="日期",y="AQI",
color="质量等级", # 定义因子的颜色变量
palette=c("green4","orange","blue3","red3","purple"),# 设置调色板
sorting="ascending", # 设置升序的排列方式
dot.size=2, # 设置点的大小
legend="top", # 设置图例位置
ggtheme=theme_bw()) # 设置图形主题
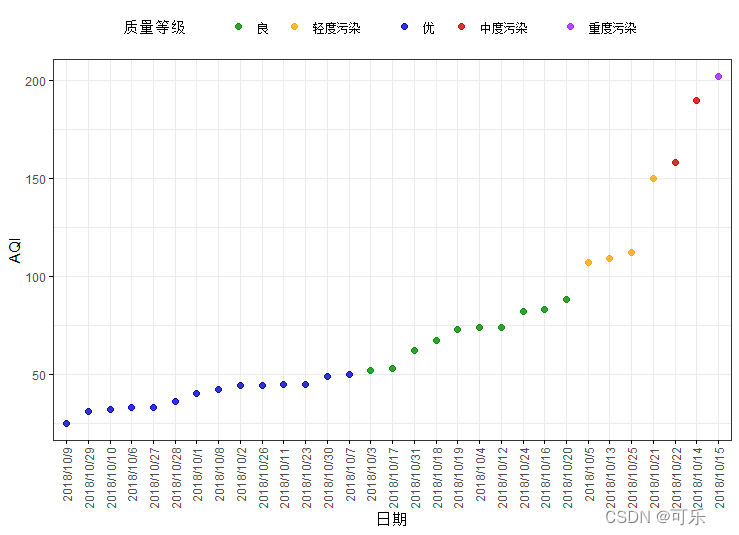
# 图29 按质量等级分类的AQI的克利夫兰点图
d<-data4_1[274:304,]
ggdotchart(d,x="日期",y="AQI",
group="质量等级",color ="质量等级",
palette=c("green4","orange","blue3","red3","purple"),
rotate=TRUE, # 将图形整体旋转
sorting="descending",
dot.size=2.5,
add="segments", # 添加线段
add.params=list(color="lightgray",size=1), # 设置线的颜色和宽度
legend="right",
ggtheme=theme_pubclean())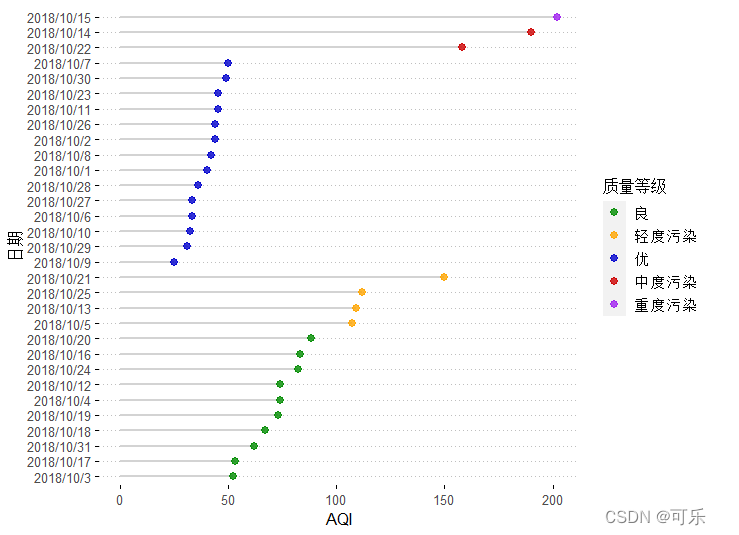
2.带状图
带状图(stripchart)又称平行散点图(parallel scatterplot)
它与点图类似,用于产生一维(one dimensional)散点图
当样本数据较少时,可作为直方图和箱线图的替代图形
# 图30
par(mai=c(0.6,0.2,0.1,0.1),cex=0.7)
stripchart(data4_1$AQI,method="overplot",at=1.35,
pch="A",cex=0.6,col="blue3")
stripchart(data4_1$PM2.5,method="jitter",at=1.16,
pch="P",cex=0.6,col="orange",add=TRUE,)
stripchart(data4_1$PM10,method="jitter",at=0.89,
pch="+",cex=0.9,col="green3",add=TRUE)
stripchart(data4_1$臭氧浓度,method="stack",at=0.6,
pch="o",cex=1,col="red2",add=TRUE)
legend(x=235,y=0.77,legend=c("A=AQI(overplot)","P=PM2.5(jitter)",
"+=PM10(jitter)","O=臭氧浓度(stack)"),col=c("blue3","orange",
"green3","red2"),fill=c("blue3","orange","green3","red2"),
cex=0.8,box.col="grey80")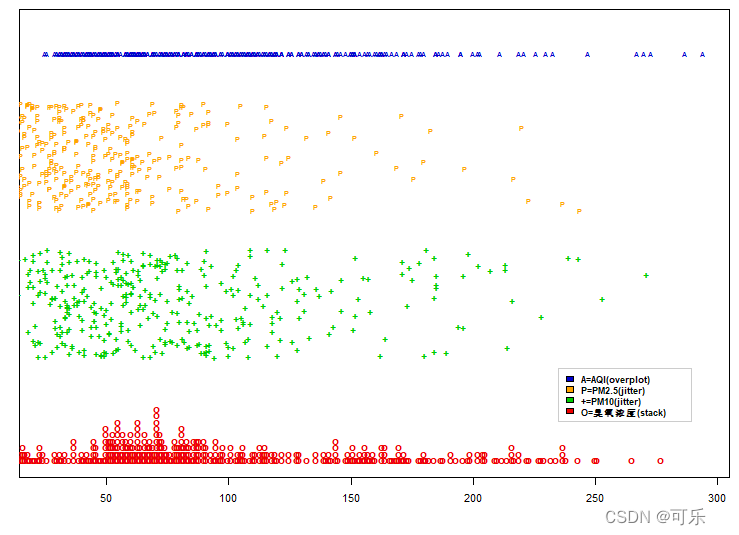
3.太阳花图
数据集中有相同的数据时,绘制点图或带状图时相同数据的点就会重叠
太阳花图(sun flower plot)与点图类似,它将数据点绘制成向日葵形状,相同的数据点用向日葵 中的花瓣(叶子)表示,花瓣的多少表示数据的密集程度
# 图4-31的绘制代码
data4_1<-read.csv("./mydata/chap04/data4_1.csv")
par(mai=c(0.6,0.6,0.2,0.2),cex=0.7)
attach(data4_1)
sunflowerplot(一氧化碳,as.factor(质量等级),cex=1,cex.fact=0.8,
size=0.1,col="blue",xlab="一氧化碳",ylab="质量等级")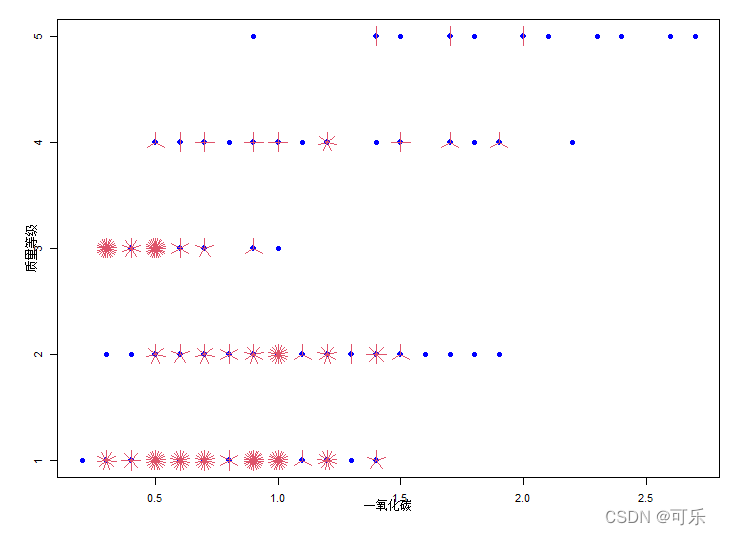
五.海盗图
海盗图(pirate plot)是展示数据多种特征的一种图形,它提供了原始数据、描述统计和推断统计等多方面的信息,通常用于展示1到3个分类独立变量和一个连续因数值变量之间的关系
海盗图集多种信息于一体,图中含有4个主要元素
一是用于表示原始数据的水平扰动点(points)
二是用于表示中心趋势的垂直条(bar)
三是表示平滑密度的豆(bean)
四是表示推断(inf)信息(比如,置信区间)的矩形(rectangle)
# 图32 AQI和4项空气污染指标的海盗图
library(yarrr)
library(reshape2)
d<-data4_1[,-c(3,6,7)] # 选择画图数据
df<-melt(d,id.vars="日期",variable.name="指标",value.name="指标值")
# 将数据转化成长格式
par(mfrow=c(1,2),mai=c(0.8,0.8,0.4,0.1),cex.lab=0.8,cex.axis=0.8,cex.main=1)
pirateplot(formula=指标值~指标,data=df,xlab="指标",
gl.col="grey90", # 设置背景网格线的颜色
theme=1,main="(a) theme=1") # 设置图形主题theme=1
pirateplot(formula=指标值~指标,data=df,xlab="指标",
gl.col="grey90",
theme=3,main="(b) theme=3") # 设置图形主题theme=3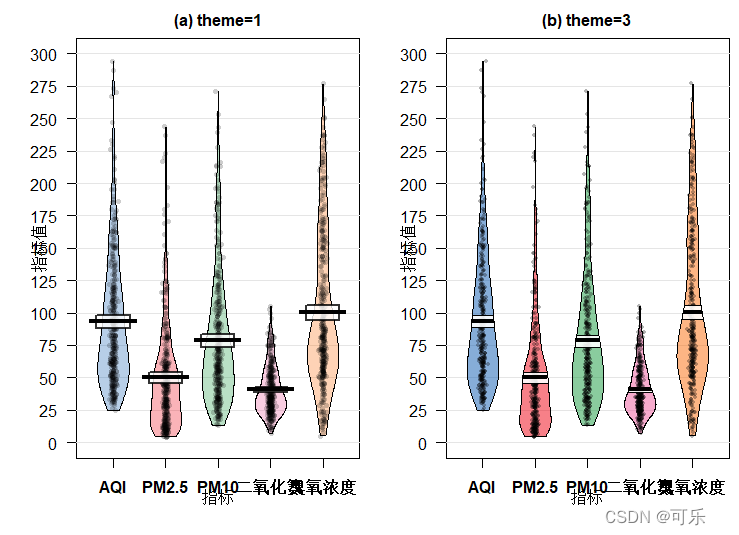
# 图33
par(mfrow=c(1,1),mai=c(0.9,0.9,0.4,0.1),cex.lab=0.7,cex.axis=0.7,cex.main=1)
pirateplot(formula=指标值~指标,data=df,main="",xlab="指标",
gl.col="white", # 背景网格颜色
theme=2, # 初始主题theme=2
inf.lwd=0.9,inf.f.o=0.5, # 置信矩形的线宽和填充的透明度
inf.b.col="black", # 置信矩形边框的颜色
avg.line.lwd=3,avg.line.o=0.8, # 平均线线宽和填充的透明度
point.o=0.2,bar.f.o=0.6, # 点和条形填充的透明度
bean.b.o=0.3,bean.f.o=0.5, # 豆的透明度和填充的透明度
point.pch=21,point.col="black", # 点型和颜色
point.cex=0.7,point.bg="white") # 点的大小和背景色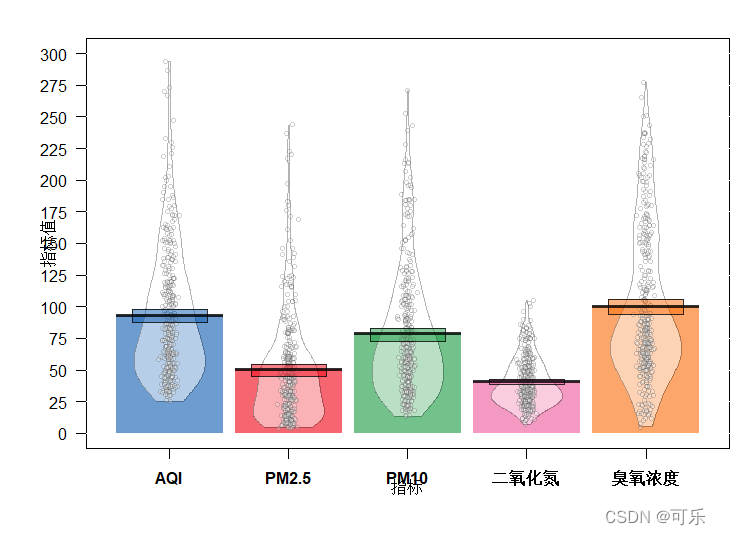
六.分布概要图
用一幅图对数据的分布特征有一个概括性的描述
只分析一个变量时,可以使用 DescTools 包中 PlotFdist 函数绘制该变量的概要图示。该函数将直方图、核密度曲线、箱线图和经验累积分布函数(ecdf) 组合在一个图中,而且还可以将地毯图以及理论分布曲线(例如正态曲线)等叠加在图形中
如果有多个变量,想要绘制出每个变量的图形概要,可以使用aplpack 包中的 plotsummary 函数,该函数可以对数据集中的每个变量绘制一个图集来展示变量的主要特征。图集中包括条纹图(条形图)、经验累积分布函数、核密度图和箱线图
# 图34 6项空气污染指标的分布概要图
library(aplpack)
data4_1<-read.csv("./mydata/chap04/data4_1.csv")
plotsummary(data4_1[,4:9],types=c("stripes","ecdf","density", "boxplot"),
y.sizes=4:1,design="chessboard",mycols="RB",main="6项空气污染指标的分布概要图")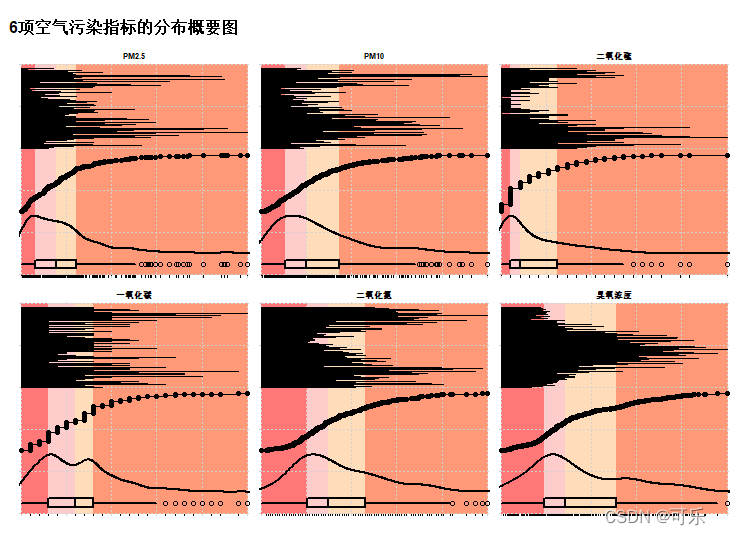
七.正态概念图
# 图36 北京市2018年AQI的正态Q-Q图
data4_1<-read.csv("./mydata/chap04/data4_1.csv")
par(mfrow=c(1,1),mai=c(0.6,0.6,0.1,0.1),cex=0.7)
qqnorm(data4_1$AQI,xlab="理论分位数",ylab="样本分位数",main="") # 绘制Q-Q点
qqline(data4_1$AQI,col="red",lwd=2) # 添加Q-Q线
par(fig=c(0.08,0.55,0.55,0.96),new=TRUE) # 设置图形位置
hist(data4_1$AQI,xlab="PM2.5",ylab="",ylim=c(0,0.012),breaks=20,freq=FALSE,col="lightblue", cex.axis=0.7,cex.lab=0.7,main="") # 绘制直方图
lines(density(data4_1$AQI),col="red") # 添加核密度曲线
box(col="grey80") # 添加盒子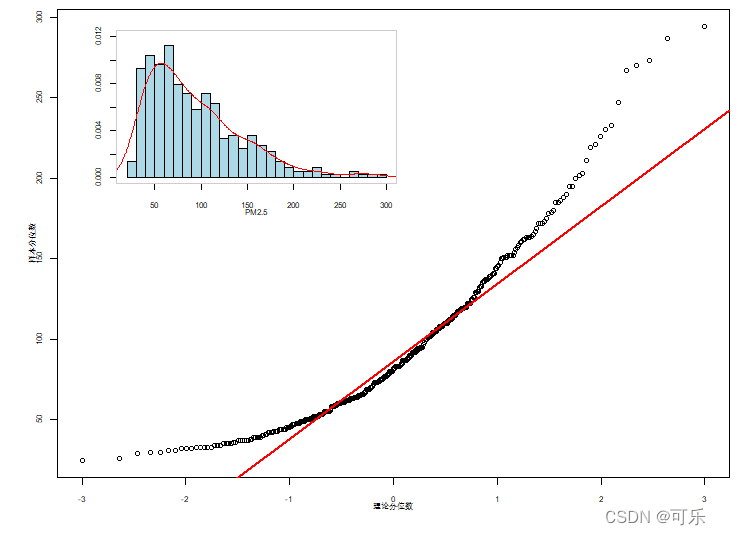
# 图37 北京市2018年PM2.5、PM10和臭氧浓度的正态Q-Q图
library(DescTools)
data4_1<-read.csv("./mydata/chap04/data4_1.csv")
par(mfrow=c(1,1),cex=0.7,mai=c(0.6,0.6,0.3,0.1),cex.main=1)
PlotQQ(data4_1$PM2.5,qdist=qnorm, # 绘制正态Q-Q图
col="red2",args.qqline=list(col="red2"), # 设置点和线的颜色
xlab="理论分位数",ylab="样本分位数",main="正态Q-Q图")
PlotQQ(data4_1$PM10,qdist=qnorm,
col="green3",args.qqline=list(col="green3"),add=TRUE)
PlotQQ(data4_1$臭氧浓度,qdist=qnorm,
col="orange1",args.qqline=list(col="orange1"),add=TRUE)
legend("topleft",legend=c("PM2.5","PM10","臭氧浓度"),
ncol=1,col=c("red2","green3","orange"),
fill=c("red2","orange","green3"),box.col="grey80",cex=0.8) # 添加图例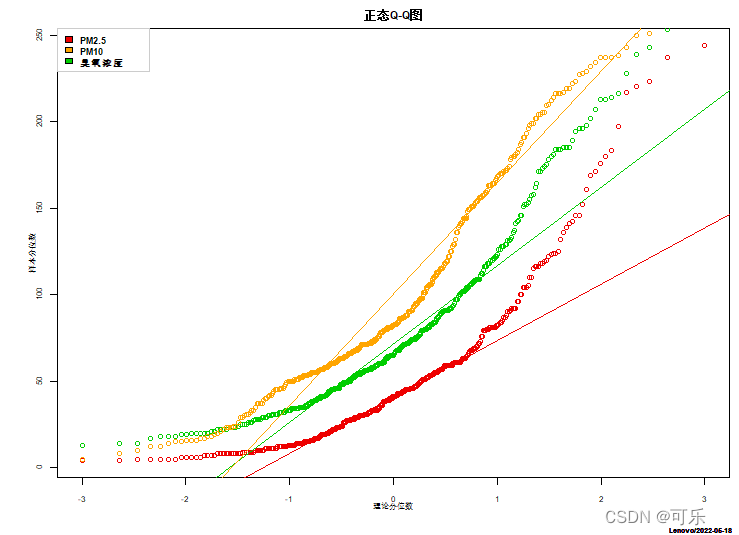
















 581
581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











