






目录
一.轮廓图和雷达图
1.轮廓图
轮廓图(outline plot)也称平行坐标图或多线图
用X轴表示各样本,用Y轴表示每个样本的多个变量的数值(X轴和Y轴可以互换),将同一样本在不同变量上的观测值用折线连接起来
观察轮廓图中各折线的形状及其排列方式,可以比较各样本在多个变量上取值的相似性及差异
# 图1 31个地区8项消费支出(元)的轮廓图
library(DescTools)
data6_1<-read.csv("./mydata/chap06/data6_1.csv")
head(data6_1)地区 区域划分 三大地带 食品烟酒 衣着 居住 生活用品及服务 交通通信
1 北京 华北 东部地带 7548.9 2238.3 12295.0 2492.4 5034.0
2 天津 华北 东部地带 8647.0 1944.8 5922.4 1655.5 3744.5
3 河北 华北 东部地带 3912.8 1173.5 3679.4 1066.2 2290.3
4 山西 华北 中部地带 3324.8 1206.0 2933.5 761.0 1884.0
5 内蒙古 华北 西部地带 5205.3 1866.2 3324.0 1199.9 2914.9
6 辽宁 东北 东部地带 5605.4 1671.6 3732.5 1191.7 3088.4
教育文化娱乐 医疗保健 其他用品及服务
1 3916.7 2899.7 1000.4
2 2691.5 2390.0 845.6
3 1578.3 1396.3 340.1
4 1879.3 1359.7 316.1
5 2227.8 1653.8 553.8
6 2534.5 1999.9 639.3
mat<-as.matrix(data6_1[,4:11]);rownames(mat)=data6_1[,1] # 将数据框转换成矩阵
par(mai=c(0.7,0.7,0.1,0.1),cex=0.9)
PlotLinesA(t(mat),xlab="消费项目",ylab="支出金额",args.legend=NA,
col=rainbow(31),pch=21,pch.col=1,pch.bg="white",pch.cex=1)
legend(x="topright",legend=data6_1[,1],lty=1,
col=rainbow(31),box.col="grey80",inset=0.01,ncol=4,cex=0.8)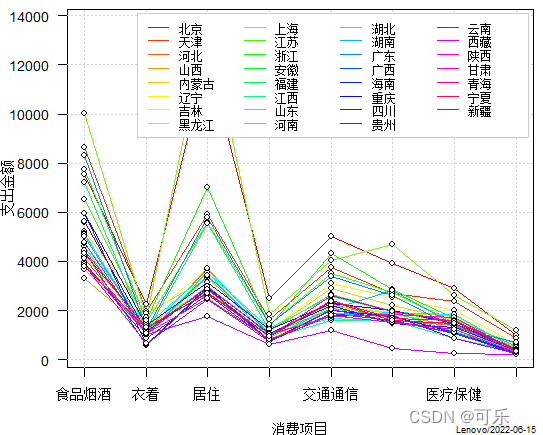
# 图2 按区域分组的31个地区8项消费支出的轮廓图
library("ggiraphExtra")
require(ggplot2)
ggPair(data6_1,aes(color=区域划分))+ # 按区域划分因子分组
theme(axis.text=element_text(size=9), # 设置坐标轴字体大小
# legend.position=c(0.6,0.87), # 设置图例位置
legend.direction="horizontal", # 图例水平排列
legend.text=element_text(size="7"), # 设置图例字体大小
axis.text.y=element_text(color = 'white')) 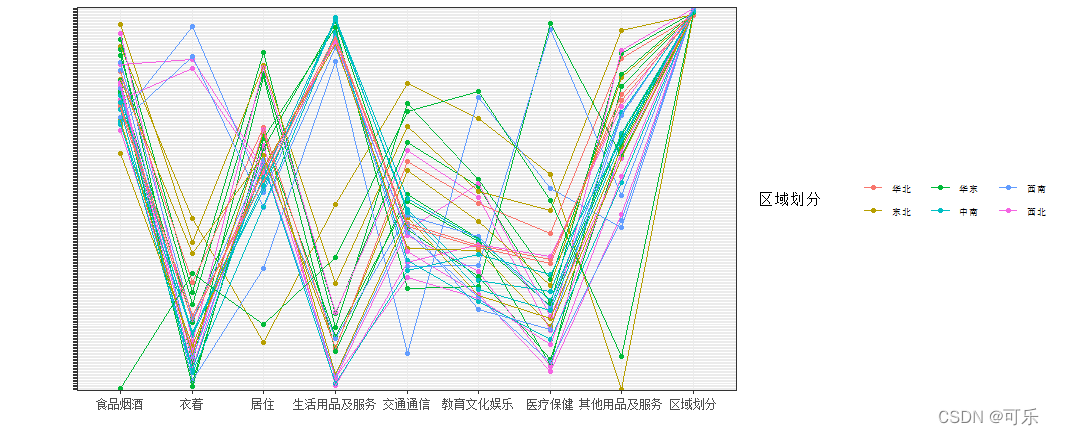
# 图3 按三大地带分组的31个地区8项消费支出的轮廓图
ggPair(data6_1,aes(color=三大地带))+ # 按三大地带分组
theme(axis.text=element_text(size=7), # 设置坐标轴字体大小
# legend.position=c(0.8,0.8), # 设置图例位置
legend.direction="vertical", # 图例垂直排列
legend.text=element_text(size="7"), # 设置图例字体大小
axis.text.y=element_text(color = 'white')) 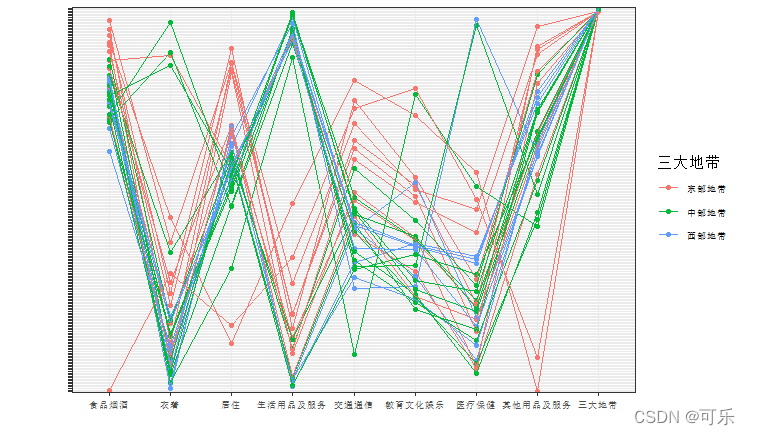
2.雷达图
雷达图(radar chart)也称为蜘蛛图(spider chart),它是从一个点出发,每个变量用一条射线表示,P个变量形成P条射线(P个坐标轴),每个样本在P个变量上的取值连接成线,即围成一个区域,多个样本围成多个区域,就是雷达图
P个变量的计量单位可能不同,数值的量级往往差异很大,每条坐标轴的刻度需要根据每个变量单独确定,因此,不同坐标轴的刻度是不可比的
利用雷达图也可以研究多个样本之间的相似程度
data6_1<-read.csv("./mydata/chap06/data6_1.csv")
head(data6_1)地区 区域划分 三大地带 食品烟酒 衣着 居住 生活用品及服务 交通通信
1 北京 华北 东部地带 7548.9 2238.3 12295.0 2492.4 5034.0
2 天津 华北 东部地带 8647.0 1944.8 5922.4 1655.5 3744.5
3 河北 华北 东部地带 3912.8 1173.5 3679.4 1066.2 2290.3
4 山西 华北 中部地带 3324.8 1206.0 2933.5 761.0 1884.0
5 内蒙古 华北 西部地带 5205.3 1866.2 3324.0 1199.9 2914.9
6 辽宁 东北 东部地带 5605.4 1671.6 3732.5 1191.7 3088.4
教育文化娱乐 医疗保健 其他用品及服务
1 3916.7 2899.7 1000.4
2 2691.5 2390.0 845.6
3 1578.3 1396.3 340.1
4 1879.3 1359.7 316.1
5 2227.8 1653.8 553.8
6 2534.5 1999.9 639.3
library(fmsb)
par(mai=c(0.2,0.2,0.2,0.2),cex=0.7)
d<-data6_1[c(1,2,9),] # 选出北京、天津和上海三个地区
head(d)地区 区域划分 三大地带 食品烟酒 衣着 居住
1 北京 华北 东部地带 7548.9 2238.3 12295.0
2 天津 华北 东部地带 8647.0 1944.8 5922.4
9 上海 华东 东部地带 10005.9 1733.4 13708.7
生活用品及服务 交通通信 教育文化娱乐 医疗保健 其他用品及服务
1 2492.4 5034.0 3916.7 2899.7 1000.4
2 1655.5 3744.5 2691.5 2390.0 845.6
9 1824.9 4057.7 4685.9 2602.1 1173.3
# 图4 北京、天津和上海8项消费支出的雷达图
labels=c("食品烟酒","衣着","居住","生活用品及服务","交通通信","教育文化娱乐","医疗保健","其他用品及服务")
cols<-c("green2","red2","blue2")
pfcol<-c("lightgreen","red","lightblue")
radarchart(d[,4:11],vlabels=labels,maxmin=FALSE,seg=4,
axistype=2,plty=c(1,2,6),plwd=1,pcol=cols,
pdensity=c(30,60,90),pangle=c(90,90,160),
palcex=1.1,pfcol=pfcol)
legend(x="topleft",legend=d[,1],lty=c(1,2,6),col=pfcol,fill=pfcol,text.width=0.2,inset=0.02,cex=0.9,box.col="grey80") #添加图例
box(col="grey80") #添加边框 
# 图5 尺度缩放后的31个地区8项消费支出的雷达图
library(ggiraphExtra)
ggRadar(data=data6_1,rescale=TRUE,aes(group=地区),alpha=0,size=1)+# 按地区分组
theme(axis.text=element_text(size=9), # 设置坐标轴字体大小
legend.position="right", # 设置图例位置
legend.text=element_text(size="8")) # 设置图例字体大小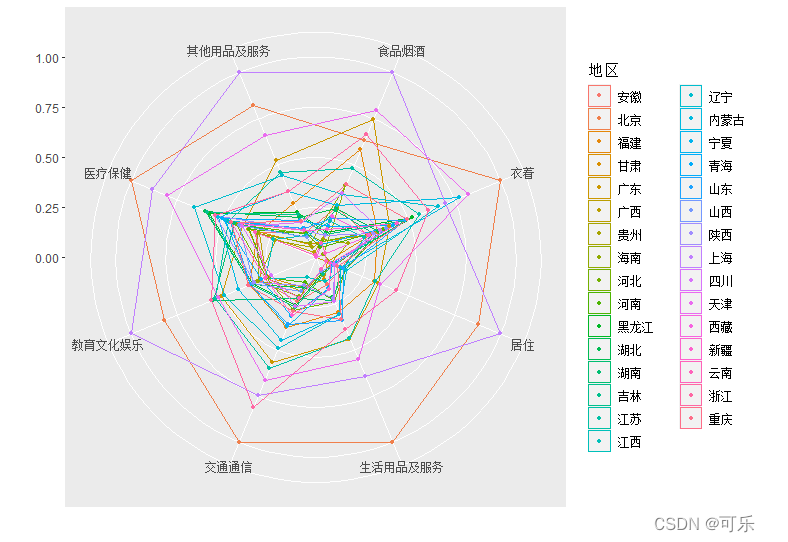
# 图6 按三大地带分组的8项消费支出的雷达图
ggRadar(data=data6_1,rescale=FALSE,aes(group=三大地带),alpha=0.2,size=2)+
# 按三大地带分组,不对时间做标准化
theme(axis.text=element_text(size=9), # 设置坐标轴字体大小
legend.position="right", # 设置图例位置
legend.text=element_text(size="9")) # 设置图例字体大小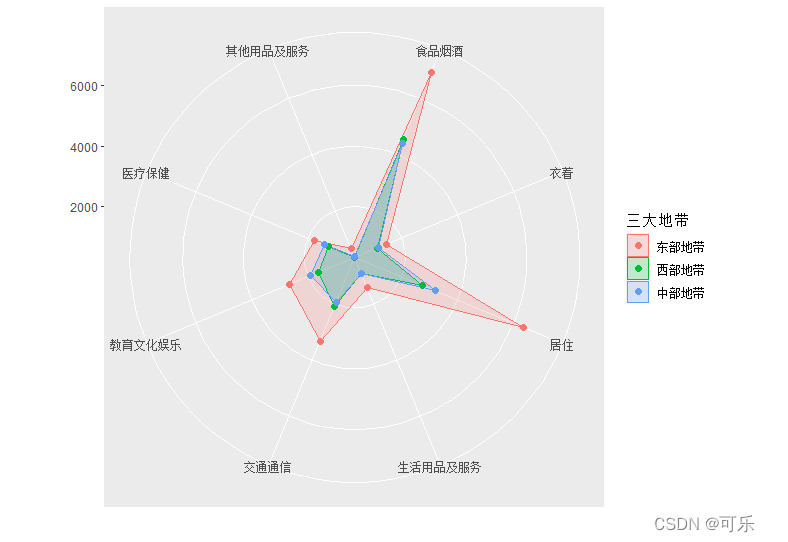
# 图7 按区域划分分面的8项消费支出的雷达图
ggRadar(data=data6_1,aes(group=区域划分,facet=区域划分),alpha=0.3,size=2,rescale=FALSE)+ # 按区域划分分面
theme(axis.text=element_text(size=7), # 设置坐标轴字体大小
legend.text=element_text(size="8")) # 设置图例字体大小
二.星图和脸谱图
1.星图
星图(star plot)也被称为雷达图,它用P个变量将圆P等分,并将P个半径与圆心连接,再将一个样本的P个变量的取值连接成一个P边形,n个样本形成n个独立的P边形,即为星图
利用星图可根据n个P边形比较n个样本的相似性。
绘制星图时,因各样本的计量单位可能不同,或不同变量的数值差异可能很大,因此需要先对变量做标准化处理,之后再绘制星图
data6_1<-read.csv("./mydata/chap06/data6_1.csv")
head(6_1)地区 区域划分 三大地带 食品烟酒 衣着 居住 生活用品及服务 交通通信
1 北京 华北 东部地带 7548.9 2238.3 12295.0 2492.4 5034.0
2 天津 华北 东部地带 8647.0 1944.8 5922.4 1655.5 3744.5
3 河北 华北 东部地带 3912.8 1173.5 3679.4 1066.2 2290.3
4 山西 华北 中部地带 3324.8 1206.0 2933.5 761.0 1884.0
5 内蒙古 华北 西部地带 5205.3 1866.2 3324.0 1199.9 2914.9
6 辽宁 东北 东部地带 5605.4 1671.6 3732.5 1191.7 3088.4
教育文化娱乐 医疗保健 其他用品及服务
1 3916.7 2899.7 1000.4
2 2691.5 2390.0 845.6
3 1578.3 1396.3 340.1
4 1879.3 1359.7 316.1
5 2227.8 1653.8 553.8
6 2534.5 1999.9 639.3
# 图8 31个地区8项消费支出的星图
d<-data6_1[-c(2,3)]
matrix6_1<-as.matrix(d[,2:9]);rownames(matrix6_1)=d[,1] # 将data6_1转化成矩阵
stars(matrix6_1,
full=TRUE, # 绘制出满圆
scale=TRUE, # 将数据缩放到[0,1]的范围。
len=1, # 设置半径或线段长度的比例
draw.segments=TRUE,key.loc=c(10.5,1.8,5), # 绘制线段图,并设置位置
mar=c(0.5,0.1,0.1,0.1), # 设置图形边界
cex=0.7) # 设置标签字体大小 
# 图9 31个地区8项消费支出的半圆太阳图
stars(matrix6_1,
full=FALSE, # 绘制出满圆
scale=TRUE, # 将数据缩放到[0,1]的范围。
len=1, # 设置半径或线段长度的比例
draw.segments=TRUE,key.loc=c(10.5,1.8,5), # 绘制线段图,并设置位置
mar=c(0.5,0.1,0.1,0.1), # 设置图形边界
cex=0.7) # 设置标签字体大小
# 图10 31个地区8项消费支出的太阳图
stars(mat,
full = T,
scale = T,
nrow = 5,
len = 1,
draw.segments = F,key.loc=c(13.2,2,5),
col.stars = rainbow(31),
frame.plot = T,
mar = c(0.5,0.1,0.1,0.1),
cex=0.6)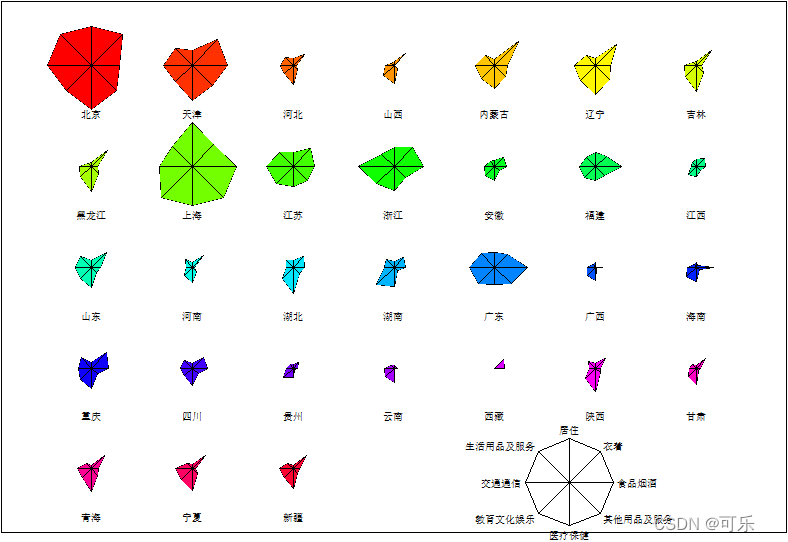
2.脸谱图
脸谱图(faces plot)由美国统计学家Chernoff(1973)首先提出,也称为Chernoff脸谱(Chernoff faces)
脸谱图将P个变量(P个维度的数据)用人脸部位的形状或大小来表征
通过对脸谱的分析,可根据P个变量对样本进行归类或比较研究
按照Chernoff提出的画法 ,由15个变量决定脸部的特征 ,若实际变量更多,多出的将被忽略;若实际变量较少,变量将被重复使用
# 图11 31个地区8项消费支出的脸谱图
library(aplpack)
data6_1<-read.csv("C:/mydata/chap06/data6_1.csv")
d<-data6_1[-c(2,3)]
matrix6_1<-as.matrix(d[,2:9]);rownames(matrix6_1)=d[,1] # 将data6_1转化成矩阵
faces(matrix6_1,face.type=1,ncol.plot=6,scale=TRUE,cex=1)
effect of variables:
modified item Var
"height of face " "食品烟酒"
"width of face " "衣着"
"structure of face" "居住"
"height of mouth " "生活用品及服务"
"width of mouth " "交通通信"
"smiling " "教育文化娱乐"
"height of eyes " "医疗保健"
"width of eyes " "其他用品及服务"
"height of hair " "食品烟酒"
"width of hair " "衣着"
"style of hair " "居住"
"height of nose " "生活用品及服务"
"width of nose " "交通通信"
"width of ear " "教育文化娱乐"
"height of ear " "医疗保健"
三.聚类图和热图
1.聚类图
根据分层聚类(hierarchical cluster)和K-均值聚类(K-means cluster)的结果绘制的图形(也称聚类树状图或谱系图)
层次聚类 ——事先不确定要分多少类, 而是先把每一个样本作为一类, 然后按照某种方法度量样本之间的距离 ,并将距离最近的两个样本合并为一个类别,从而形成k-1个类别再计算出新产生的类别与其他各类别之间的距离 ,并将距离最近的两个类别合并为一类。这时,如果类别的个数仍然大于1,则重复这一步上述步骤,直到所有的类别都合并成一类为止
K-均值聚类——不是把所有可能的聚类结果都列出来,使用者需要先指定要划分的类别个数,然后确定各聚类中心,再计算出各样本到聚类中心的距离 ,最后按距离的远近进行分类
K-均值聚类中的“K”就是 指事先指定要分的类别个数, 而“均值 ”则是指聚类的中心。
data6_1<-read.csv("C:/mydata/chap06/data6_1.csv")
head(data6_1)地区 区域划分 三大地带 食品烟酒 衣着 居住 生活用品及服务
1 北京 华北 东部地带 7548.9 2238.3 12295.0 2492.4
2 天津 华北 东部地带 8647.0 1944.8 5922.4 1655.5
3 河北 华北 东部地带 3912.8 1173.5 3679.4 1066.2
4 山西 华北 中部地带 3324.8 1206.0 2933.5 761.0
5 内蒙古 华北 西部地带 5205.3 1866.2 3324.0 1199.9
6 辽宁 东北 东部地带 5605.4 1671.6 3732.5 1191.7
交通通信 教育文化娱乐 医疗保健 其他用品及服务
1 5034.0 3916.7 2899.7 1000.4
2 3744.5 2691.5 2390.0 845.6
3 2290.3 1578.3 1396.3 340.1
4 1884.0 1879.3 1359.7 316.1
5 2914.9 2227.8 1653.8 553.8
6 3088.4 2534.5 1999.9 639.3
# 图12 31个地区层次聚类树状图
library(factoextra)
df<-data6_1[,-c(2,3)] # 去掉数据框的2、3列
mat<-as.matrix(df[,2:9]);rownames(mat)=df[,1] # 将data6_1转化成矩阵
d<-dist(scale(mat),method="euclidean") # 采用euclidean距离计算样本的点间距离
hc<-hclust(d,method="ward.D2")
# 采用ward.D法计算类间距离并用层次聚类法进行聚类
fviz_dend(hc,k=4, # 分成4类
cex=0.6, # 设置数据标签的字体大小
horiz=FALSE, # 垂直摆放图形
k_colors=c("red","green3","blue3","6"),
# 设置聚类集群的线条颜色
color_labels_by_k=TRUE, # 自动设置数据标签颜色
lwd=0.8, # 设置分支和矩形的线宽
type="rectangle", # 设置绘图类型为矩形
rect=TRUE, # 使用不同的颜色矩形标记类别
rect_lty=1,rect_fill=TRUE, # 设置标记框的线型和填充颜色
main="") # 不显示标题 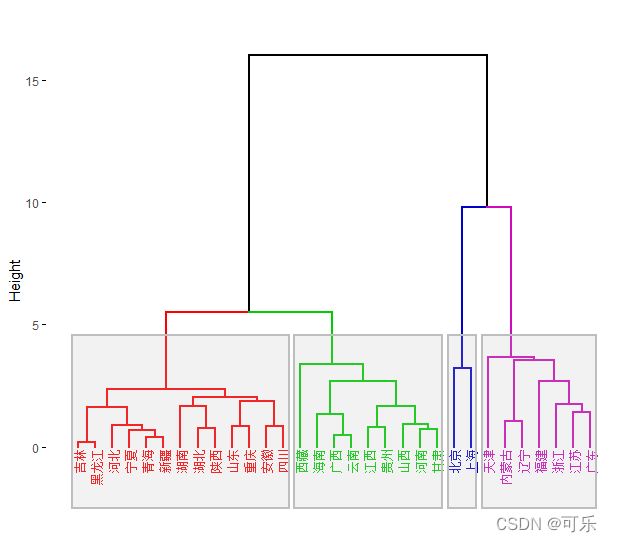
# 图13 31个地区层次聚类的圆形树状图
fviz_dend(hc,k=4, # 分成4类
cex=0.6, # 设置数据标签的总体大小
horiz=FALSE, # 垂直摆放图形
k_colors=c("#1B9E77","#D95F02","#7570B3","#E7298A"),
# 设置聚类集群的线条颜色
color_labels_by_k=TRUE, # 自动设置数据标签颜色
lwd=0.8, # 设置分支和矩形的线宽
type="circular", # 设置绘图类型为矩形
rect=TRUE, # 使用不同的颜色矩形标记类别
rect_lty=1,rect_fill=TRUE) # 设置标记框的线型和填充颜色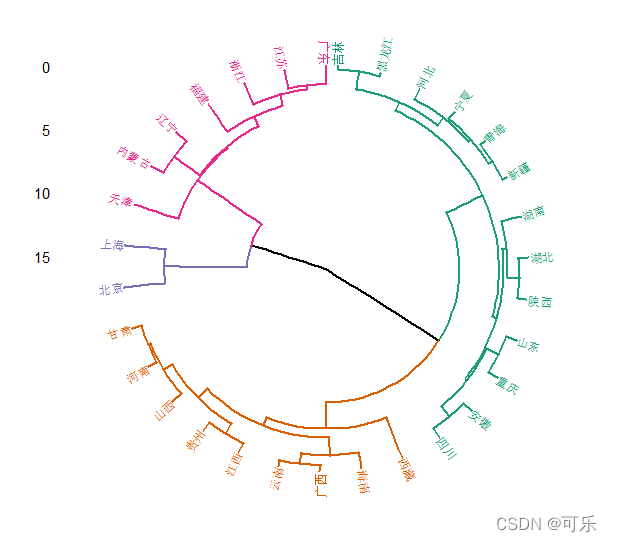
# 图14 31个地区层次聚类的植物形树状图
fviz_dend(hc,k=4, # 分成4类
cex=0.8, # 设置数据标签的大小
horiz=FALSE, # 垂直摆放图形
k_colors=c("#1B9E77","#D95F02","#7570B3","#E7298A"),
# 设置聚类集群的线条颜色
color_labels_by_k=TRUE , # 自动设置数据标签颜色
lwd=0.8, # 设置分支和矩形的线宽
type="phylogenic", # 设置绘图类型为矩形
rect=TRUE, # 使用不同的颜色矩形标记类别
repel=TRUE, # 避免图中的文本标签重叠
rect_lty=1,rect_fill=TRUE) # 设置标记框的线型和填充颜色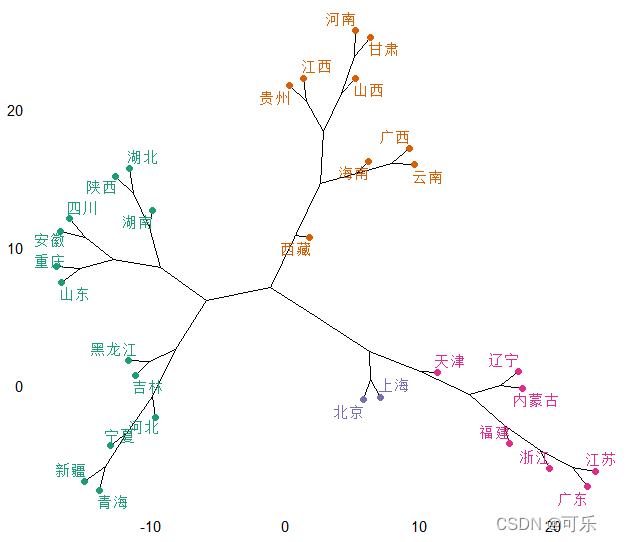
# 图15 31个地区分成4类的k-means聚类图
df<-data6_1[,-c(2,3)] # 去掉数据框的2、3列
mat<-as.matrix(df[,2:9]);rownames(mat)=df[,1] # 将data6_1转化成矩阵
km<-kmeans(mat,centers=4) # 分成4类
fviz_cluster(km,mat[,-1],
repel=TRUE, # 避免图中的文本标签重叠
ellipse.type="norm", # 画出正态置信椭圆
labelsize=8, # 设置文本字体的大小
pointsize=1.5, # 设置点的大小
main = "K-means聚类(分成4类)")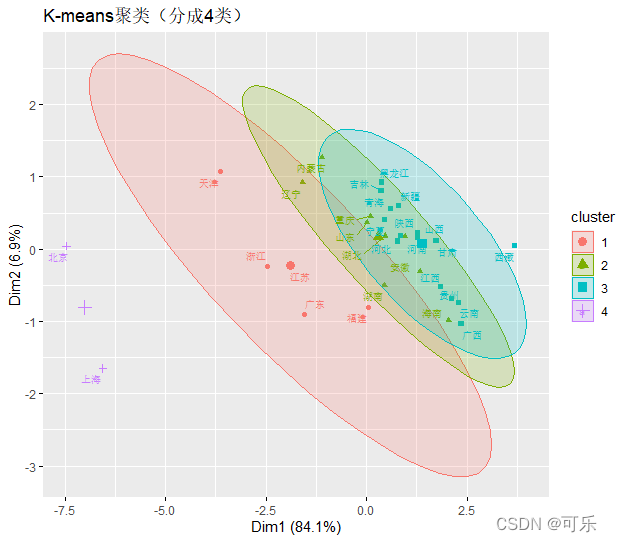
# 图16 31个地区分成3类的k-means聚类图
km<-kmeans(mat,centers=3) # 分成3类
fviz_cluster(km,mat[,-1],repel=TRUE,ellipse.type="convex",labelsize=8,main="K-means聚类(分成3类)")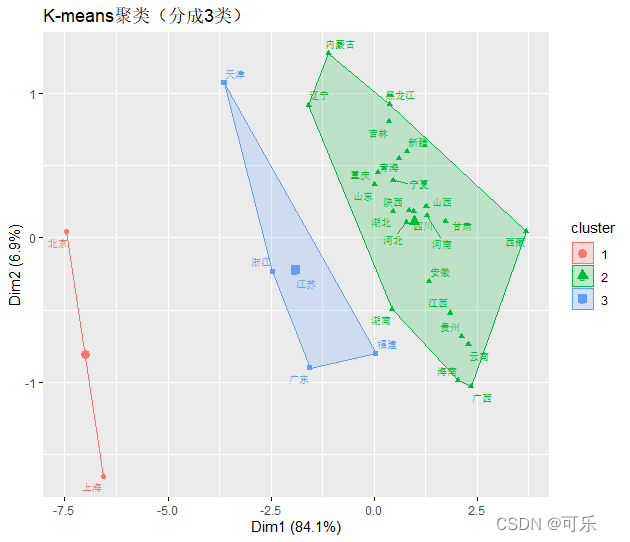
2.热图
热图(heat map)是将矩阵中的每个数值转化成一个颜色矩形,用颜色 表示数值的近似大小或强度热图在很多领域都有应用,比如基因组数据的可视化
热图可以在聚类的基础上同时用颜色表示出数据的大小绘制热图时要求数据必须是矩阵。由于各变量间的数值差异,一般需要做中心化或标准化处理。当数据量很大时,通常会将数据归类后再绘制热图
data6_1<-read.csv("./mydata/chap06/data6_1.csv")
head(data6_1)地区 区域划分 三大地带 食品烟酒 衣着 居住 生活用品及服务
1 北京 华北 东部地带 7548.9 2238.3 12295.0 2492.4
2 天津 华北 东部地带 8647.0 1944.8 5922.4 1655.5
3 河北 华北 东部地带 3912.8 1173.5 3679.4 1066.2
4 山西 华北 中部地带 3324.8 1206.0 2933.5 761.0
5 内蒙古 华北 西部地带 5205.3 1866.2 3324.0 1199.9
6 辽宁 东北 东部地带 5605.4 1671.6 3732.5 1191.7
交通通信 教育文化娱乐 医疗保健 其他用品及服务
1 5034.0 3916.7 2899.7 1000.4
2 3744.5 2691.5 2390.0 845.6
3 2290.3 1578.3 1396.3 340.1
4 1884.0 1879.3 1359.7 316.1
5 2914.9 2227.8 1653.8 553.8
6 3088.4 2534.5 1999.9 639.3
# 图17 heatmap函数绘制的31个地区8项消费支出的热图
mat<-as.matrix(data6_1[,4:11]);rownames(mat)=data6_1[,1] # 将data6_1中的数值变量转换为矩阵
heatmap(mat,scale="column",margins=c(4,3),cexRow=0.8,cexCol=0.8) # 对矩阵按列做标准化后绘制热图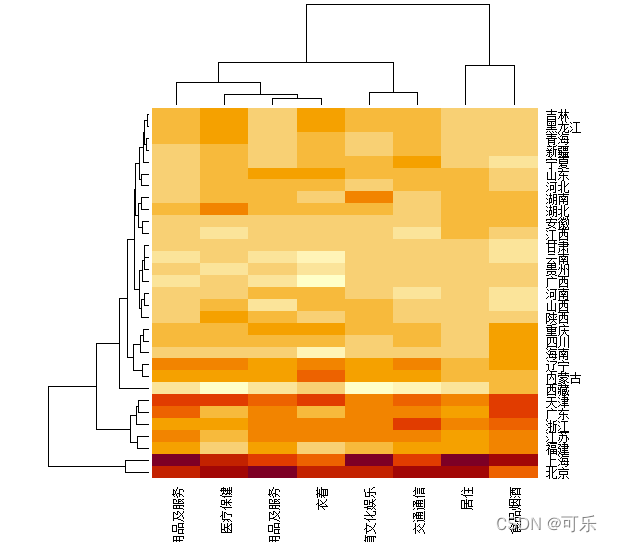
# 图18 col=rainbow(256)绘制的31个地区8项消费支出的热图
rc<-rainbow(nrow(mat),start=0,end=0.6) # 设置注释矩阵中行变量的垂直侧条的颜色向量
cc<-rainbow(ncol(mat),start=0,end=0.6) # 设置注释矩阵中列变量的水平条的颜色向量
heatmap(mat,scale="column",RowSideColors=rc,ColSideColors=cc,margins=c(4,3),col=rainbow(256),cexRow=0.8,cexCol=0.9) 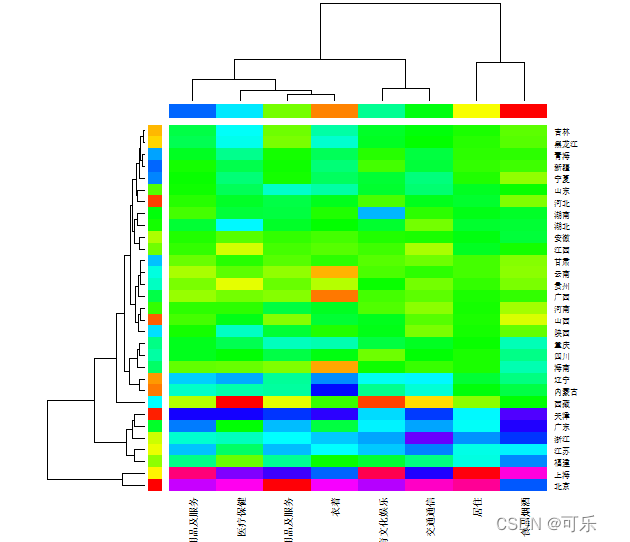
# 图19 去掉聚类图的31个地区8项消费支出的热图
heatmap(mat,Rowv=NA,Colv=NA, # 去掉聚类图
scale="column",margins=c(5,3),
cm.colors(256,start=02,end=0.5),cexRow=0.8,cexCol=0.9) 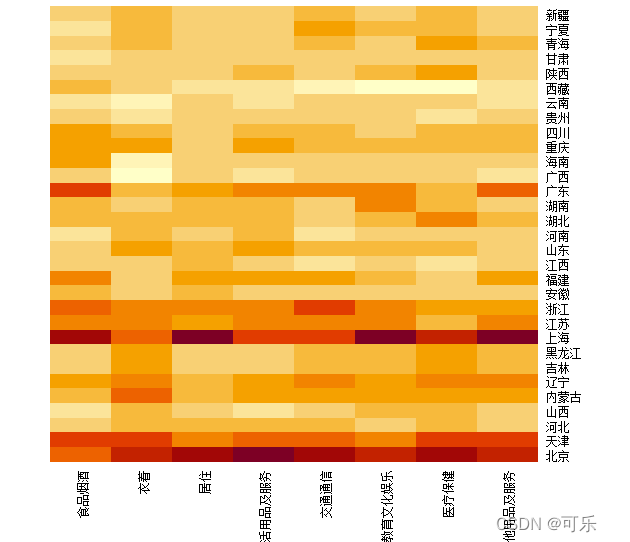
# 图20 heatmap.2绘制的31个地区8项消费支出的热图
library(gplots)
M<-as.matrix(data6_1[,4:11]);rownames(M)=data6_1[,1]
heatmap.2(M,
scale="none",col=rainbow(256),tracecol="grey50",
dendrogram="both",cexRow=0.8,cexCol=0.8,
margins=c(5.3,3),keysize=2, key.title="色键与直方图") 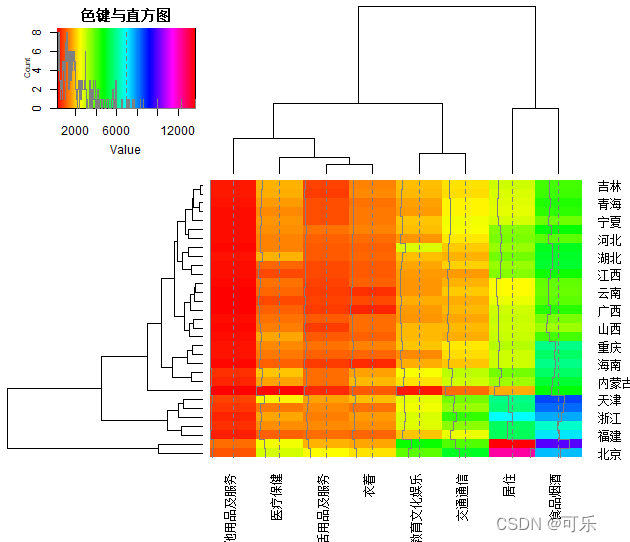
# 图6-21 heatmap.2函数绘制的31个地区8项消费支出标准化后的热图
M<-as.matrix(data6_1[,4:11]);rownames(M)=data6_1[,1]
gplots::heatmap.2(M,
col=bluered,tracecol="gray50",scale="column",
dendrogram="both",cexRow=0.6,cexCol=0.7,
margins=c(5.3,3),keysize=2,key.title="色键与直方图")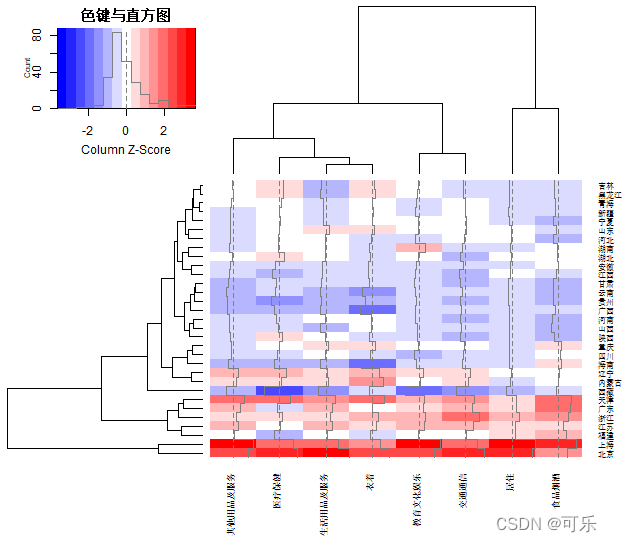
# 图22 pheatmap函数绘制的31个地区8项消费支出的热图
library(pheatmap)
mat<-as.matrix(data6_1[,4:11]);rownames(mat)=data6_1[,1] # 将数据框转化成矩阵
mat<-scale(mat) # 对矩阵做标准化
pheatmap(mat,
color=colorRampPalette(c("navy","white","firebrick3"))(10),
# 热图中使用的颜色向量
display_numbers=FALSE, # 默认FALSE,不显示矩阵单元的数据
cellheight_row=6, # 设置单元格行高度
fontsize=8, # 设置文本字体大小
treeheight_row=50,treeheight_col=35, # 设置行和列聚类树的高度
cutree_col=2, # 设置聚类列数
cutree_row=4) # 设置聚类行数 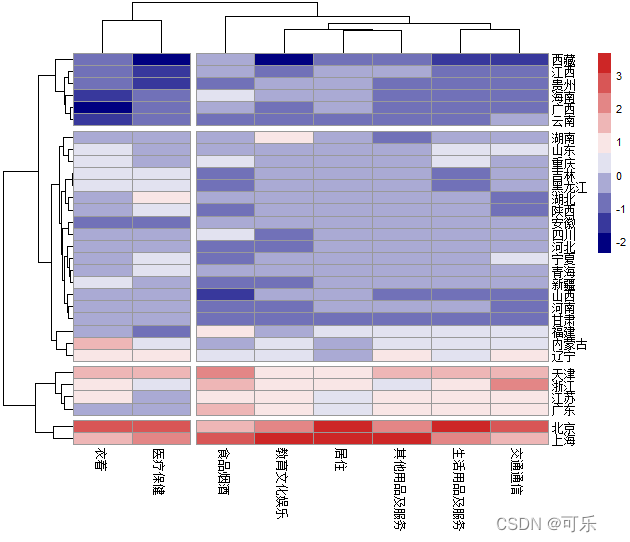


















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











