







 本文介绍了利用Python和Keras对IDMB数据集进行情感分析的过程,包括数据预处理(如清洗、编码)、模型构建(使用词嵌入和多层感知机)、训练和评估。模型在训练后能够预测影评的情感极性,展示了NLP在情感分析中的应用。
本文介绍了利用Python和Keras对IDMB数据集进行情感分析的过程,包括数据预处理(如清洗、编码)、模型构建(使用词嵌入和多层感知机)、训练和评估。模型在训练后能够预测影评的情感极性,展示了NLP在情感分析中的应用。
目录
简介
IDMB数据集
IDMB数据集包含了50000条数据,每条数据包括影评文字及其对应的标签
数据集下载地址如下:【kaggle IDMB dataset】
接下来我们希望能建立一个模型,在对该模型进行大量训练之后,该模型可以用于预测某一段影评文字是正面或负面评价
数据预处理
数据加载
import pandas as pd
file_path='data/imdb_from_kaggle.csv'
init_data=pd.read_csv(file_path)
init_data.head()
结果

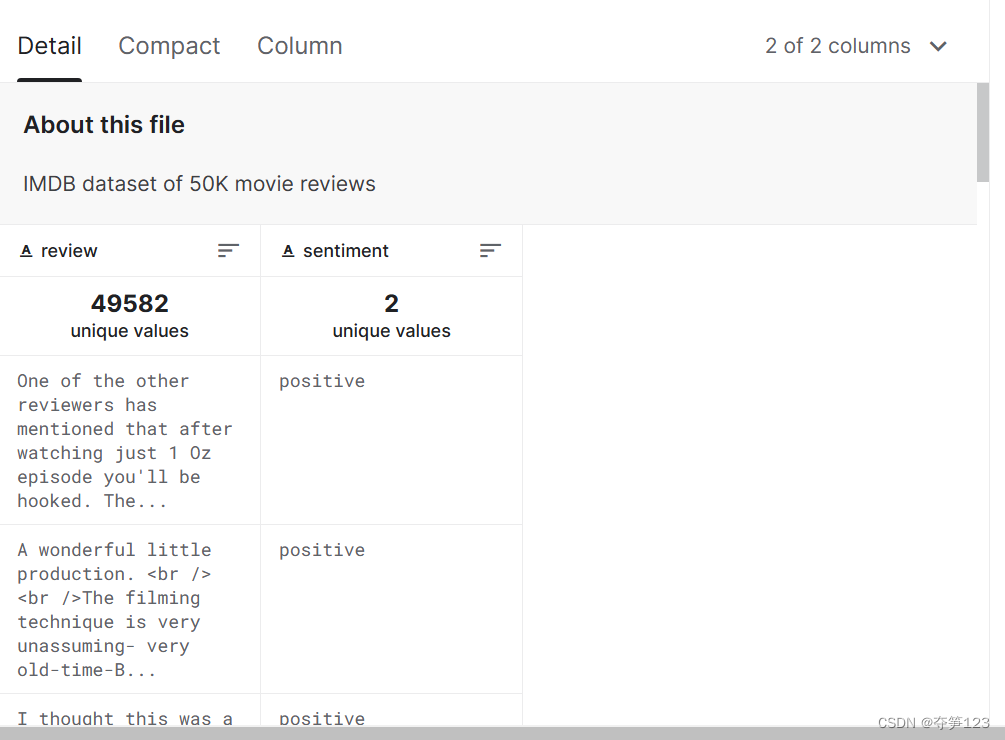
import matplotlib.pyplot as plt
init_data['sentiment'].value_counts().plot(kind='bar')
plt.show()
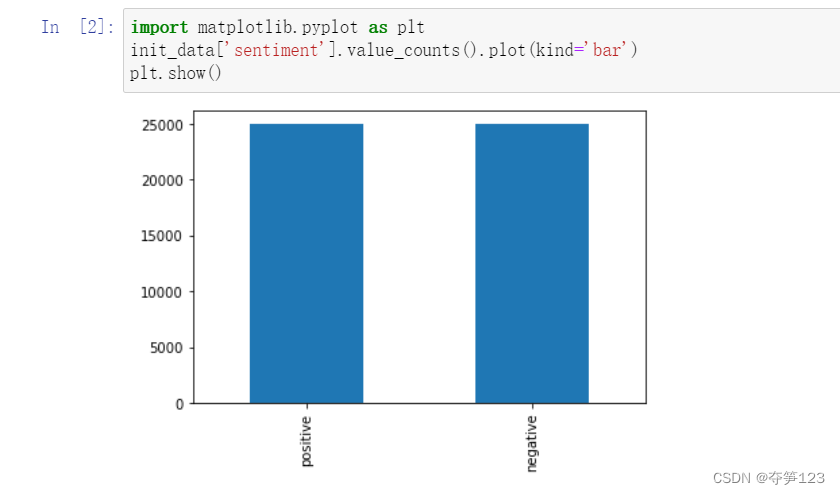
from wordcloud import WordCloud
cloud_positive = WordCloud().generate(init_data['review'][2])
cloud_negative = WordCloud().generate(init_data['review'][3])
plt.figure(figsize = (20,15))
plt.subplot(1,2,1)
plt.imshow(cloud_positive)
plt.title('Positive review')
plt.subplot(1,2,2)
plt.imshow(cloud_negative)
plt.title('Negative review')
plt.show()
我们已知数据集中的第3项和第4项分别为正向和负向评价,我们通过词云的方式查看每个影评中都说了什么
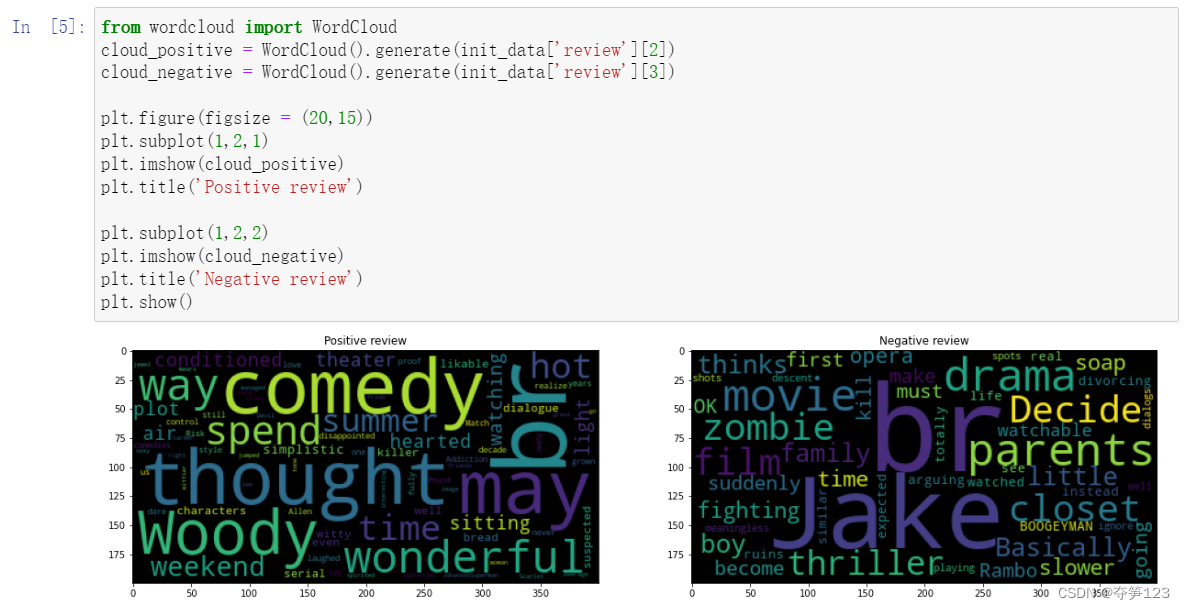 上面图片中竟然有<br/>标签,这说明每个影评中都可能存在有与影评内容无关的(或是我们无法解析的,比如emoji表情)元素,我们需要对其进行清除
上面图片中竟然有<br/>标签,这说明每个影评中都可能存在有与影评内容无关的(或是我们无法解析的,比如emoji表情)元素,我们需要对其进行清除
数据清洗
import re
# 清除影评中所有的链接
def remove_url(text):
url_tag = re.compile(r'https://\S+|www\.\S+')
text = url_tag.sub(r'', text)
return text
# 清除影评中所有的HTML标签
def remove_html(text):
html_tag = re.compile(r'<.*?>')
text = html_tag.sub(r'', text)
return text
# 清除影评中所有的标点符号
def remove_punctuation(text):
punct_tag = re.compile(r'[^\w\s]')
text = punct_tag.sub(r'', text)
return text
# 清除影评中所有的特殊符号
def remove_special_character(text):
special_tag = re.compile(r'[^a-zA-Z0-9\s]')
text = special_tag.sub(r'', text)
return text
# 清除影评中所有的emoji
def remove_emojis(text):
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # 表情符号
u"\U0001F300-\U0001F5FF" # 符号和象形文字
u"\U0001F680-\U0001F6FF" # 交通和地图符号
u"\U0001F1E0-\U0001F1FF" # 标志(iOS)
"]+", flags=re.UNICODE)
text = emoji_pattern.sub(r'', text)
return text
# 执行所有函数,返回数据清洗后的结果
def clean_text(text):
text = remove_url(text)
text = remove_html(text)
text = remove_punctuation(text)
text = remove_special_character(text)
text = remove_emojis(text)
text = text.lower()# 影评文字转小写
return text
上面代码片段参考kaggle原作者:Thi Khuyen LE
保存经过清洗后的数据
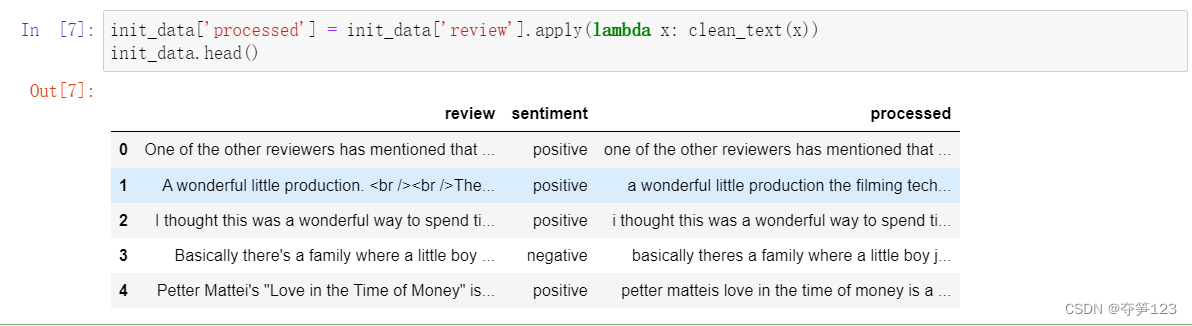
# 生成一个新的数据列用来存放清洗后的影评
init_data['processed'] = init_data['review'].apply(lambda x: clean_text(x))
init_data.head()
# 生成一个新的数据列用于将'positve'或'negative'转化为数字
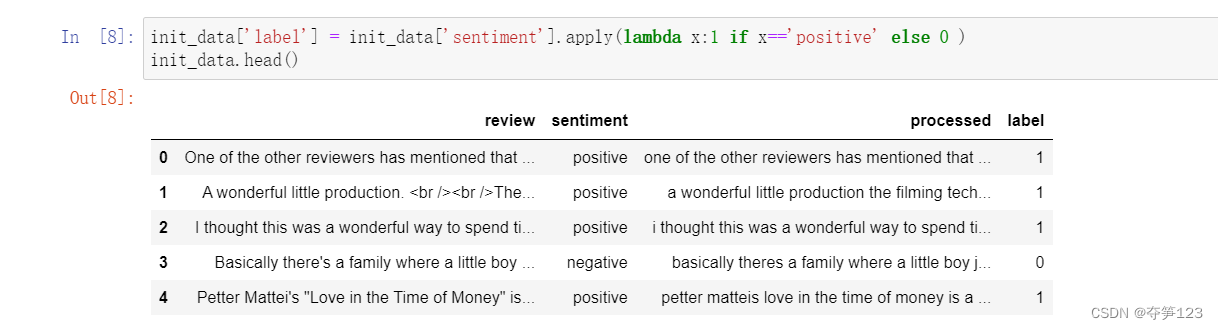
init_data['label'] = init_data['sentiment'].apply(lambda x:1 if x=='positive' else 0 )
init_data.head()
训练测试数据集分割
# 使用sklearn的train_test_split()函数对数据集进行分割,训练集:测试集=4:1
from sklearn.model_selection import train_test_split
x=init_data['processed']
y=init_data['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2)
文字编码
我们都知道机器学习模型几乎是不能够直接使用自然语言作为输入的,这就需要我们将自然语言进行编码(转化为数字),这一过程有点像两个语言之间的翻译过程:使用一个字典做映射,该字典的key对应着一种语言,而value对应着另一种语言,使用这个字典,就可以将一种语言的一段话转化为另一种语言的版本,比如
# 有这样一段话:我是汤姆
# dict :['我':'I','是':'am','汤姆':'Tom']
# 中文版本:我是汤姆
# English vision:I am Tom
看完上面的例子我们就要考虑了,将一段自然语言转化为一串数字,中间的这个桥梁:字典,该怎么构建?我们先看下面这个来自Keras的API
keras.preprocessing.text.Tokenizer(nb_words=None, filters=base_filter(),
lower=True, split=" ")
keras为我们提供了一个Tokenizer模块,它用于向量化文本,或将文本转换为序列(即单词在字典中的下标构成的列表,从1算起)的类。
from tensorflow.keras.preprocessing.text import Tokenizer
# 使用Tokenizer建立一个有5000个单词的字典
token=Tokenizer(num_words=5000)
# 读取所有的训练数据影评,按照每个英文单词在影评中出现的次数进行排序,
# 排序前5000名的单词将会被列入字典
token.fit_on_texts(x_train)
token.word_index
结果

ok,现在我们得到了期望的字典,下面就需要将每一条影评都转化为一串数字,Tokenizer类提供了一个方法
x_train_seq=token.texts_to_sequences(x_train)
x_test_seq=token.texts_to_sequences(x_test)
效果
 到现在似乎数据预处理就要接近尾声了,但是还存在着一个问题。我们再来梳理一遍我们接下来要做什么:构建多层感知机模型>>>将数据传给模型进行训练>>评价模型。
到现在似乎数据预处理就要接近尾声了,但是还存在着一个问题。我们再来梳理一遍我们接下来要做什么:构建多层感知机模型>>>将数据传给模型进行训练>>评价模型。
我们来思考一下,在以往对机器学习模型进行训练时,每一条训练数据是不是拥有相同的数据维度?但是现在我们得到的x_train_seq也即将作为训练数据,其中包含了40000条数据,每条数据的维度相同吗
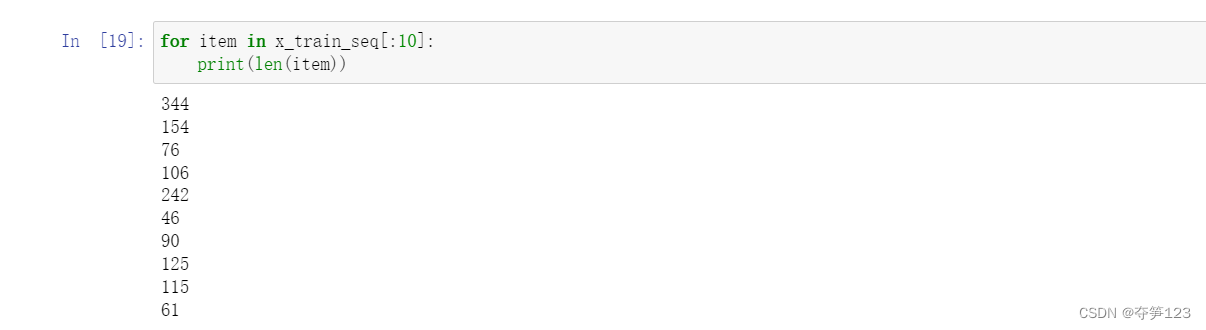
我们使用keras中的sequence.pad_sequences()函数解决该问题,该函数将会在元素长度小于maxlen时,在数据后部填充0以达到该长度。长于maxlen的序列将会被截断,以使其匹配目标长度。
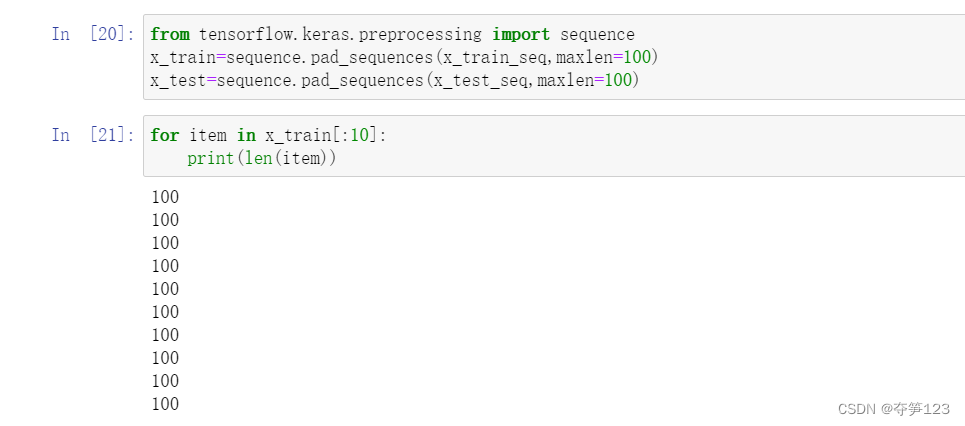 于是,到现在为止训练集和测试集的维度分别为(40000,100),(10000,100)
于是,到现在为止训练集和测试集的维度分别为(40000,100),(10000,100)
词嵌入
数据预处理已经基本完成,但是我们得到的每一条训练数据都是一串串数字,在语义上没有任何关联,为了让每一个文字都有关联性,我们在接下来构建模型时将使用keras中的Embedding嵌入层将数字列表转换为向量列表
模型构建
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense,Dropout,Flatten
from tensorflow.keras.utils import plot_model # 绘制模型的结构图
model1=Sequential()
model1.add(Embedding(output_dim=32,input_dim=5000,input_length=100))
model1.add(Dropout(0.2))
model1.add(Flatten())
model1.add(Dense(units=256,activation='relu'))
model1.add(Dropout(0.35))
model1.add(Dense(units=1,activation='sigmoid'))
模型训练
model1.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
plot_model(model1, show_shapes = True)
train_history=model1.fit(x_train,y_train,batch_size=100,
epochs=10,verbose=2,
validation_split=0.2)
结果
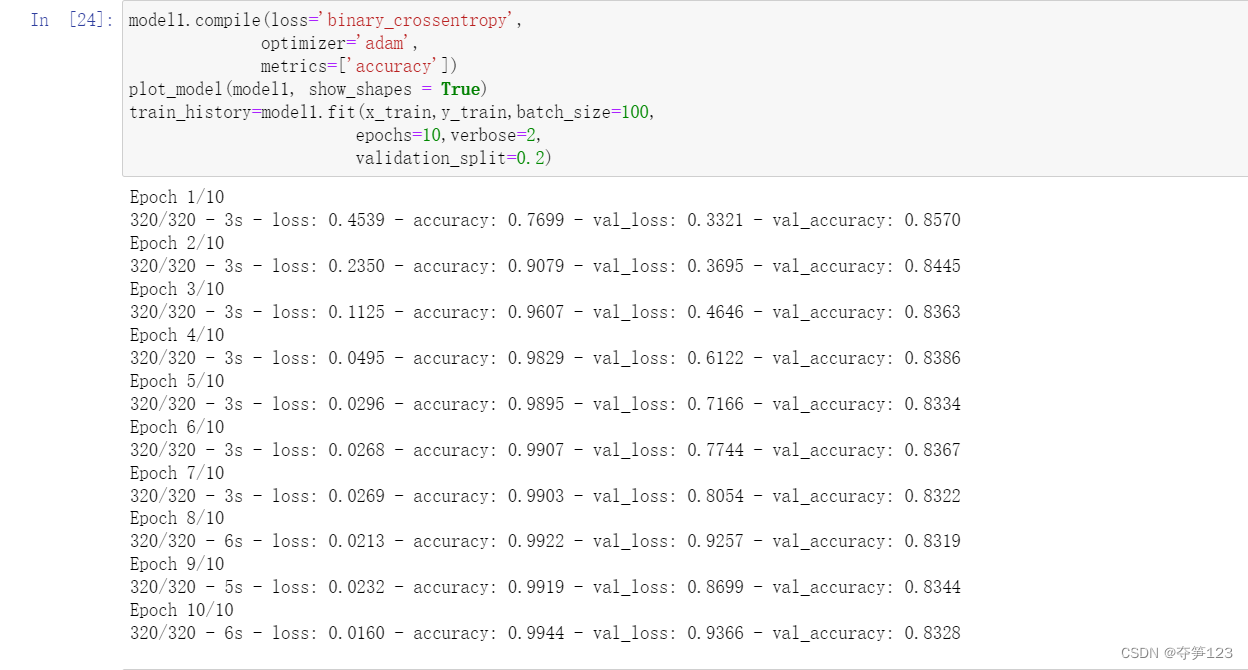
训练效果
模型评分

模型预测及混淆矩阵

# 混淆矩阵可视化
from sklearn.metrics import confusion_matrix,ConfusionMatrixDisplay
cm = ConfusionMatrixDisplay(confusion_matrix(y_test,prediction1.reshape(10000,)), display_labels = ['Negative', 'Positive'])
plt.figure(figsize = (5,5))
cm.plot()
plt.title('Confusion matrix')
plt.show()
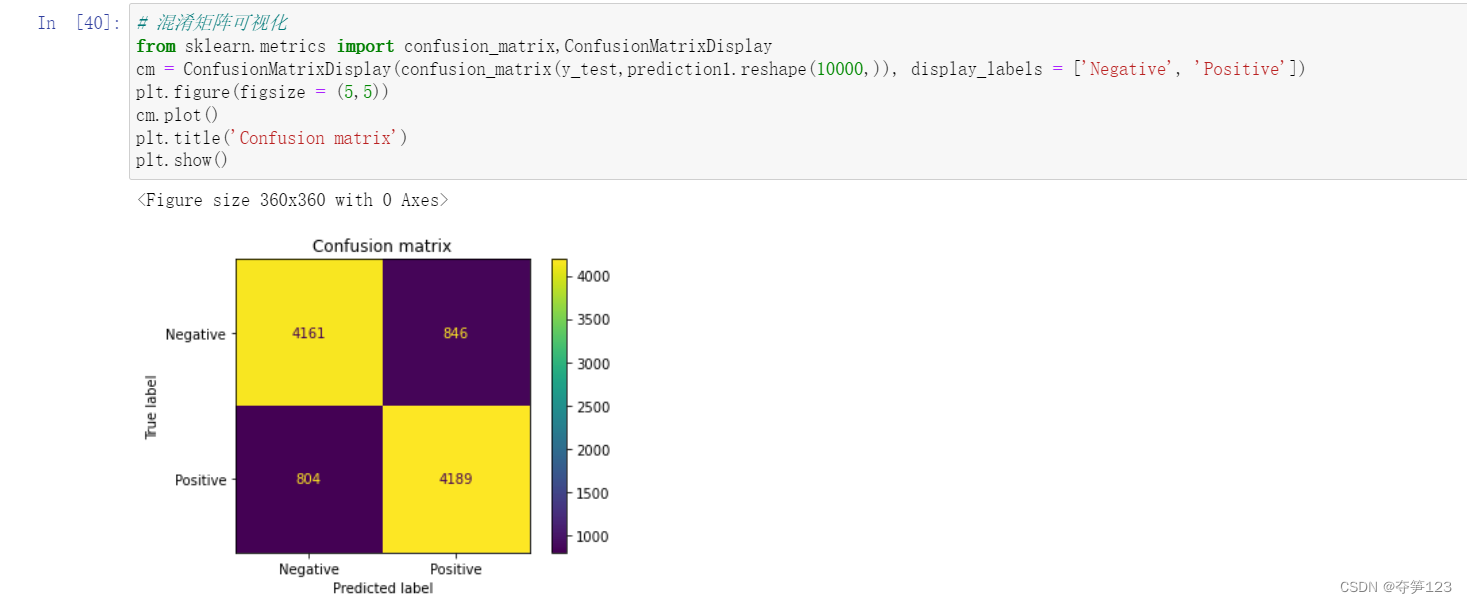
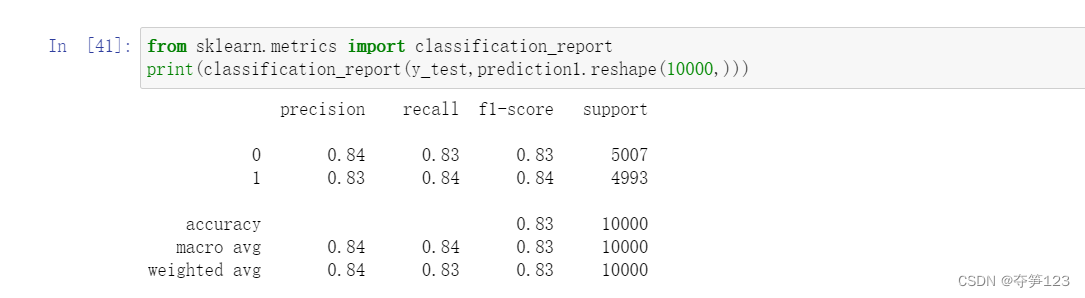
查看F1 Score、召回率等信息
from sklearn.metrics import classification_report
print(classification_report(y_test,prediction1.reshape(10000,)))
预测新的影评
接下来我们去豆瓣上复制两条关于电影《黑豹2》的评价并交给模型去预测
def text_prediction(text):
text_seq=token.texts_to_sequences([text])
seq_after_pad=sequence.pad_sequences(text_seq,maxlen=100)
return seq_after_pad
text_list=["""The worst movie of Marvel Stage 4, not even as good looking as Thor 4, using top notch ingredients to make a bad dish,worse than Black Panther 1, which I didn't expect, just as bad looking as Black Widow. The first half of the film was made into documentaries,\
In Memory of T 'Chara and The Quest for Water, which made you fall asleep, If you can believe that the most advanced country in the world sends two small fighter jets to fight the Namor, \
and uses a ship to fight the people under the sea without even building a plane, the final factor of the war is very funny. I suggest you keep your eyes on it. When you get to the rear, \
just like you did when you watched the Surprise team, you expect to see an Easter egg. It's really disappointing. I was expecting Black Panther 2 to be a success. I think this is even dragging down the stage 4 average""",
"""It's good to watch, and there are plenty of female characters. The story is very patient in shaping Su Rui's growth, but I really like her stubbornness. The conflict in the movies is more realistic than the super-English storyline, \
which threatens to destroy the universe at every turn. People fight and turn against each other, and it's not even because they have any real conflict of interest"""]
for text in text_list:
new_text=text_prediction(text)
predict_new_text=model1.predict_classes(new_text)
print(predict_new_text)
结果

很明显,我们输入的影评是一条坏评一条好评,而模型得到了相同的结果!大功告成!
总结
本篇博客我们使用多层感知机实现了简单的自然处理过程,数据集采用了经典的IDMB数据集,通过数据清洗等一系列操作将影评等自然语言处理为一个个向量数据并作为训练数据喂给了机器学习模型,后者通过训练能完成简单的影评情感分析功能,从最终的模型得分来看,达到了较好的效果,但是仍然存在需要改进的地方:比如数据预处理部分的Tokenizer字典建立、机器学习模型结构及训练轮次等等,今天的学习过程暂且告一段落


















 6095
6095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











