






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
我的环境:
- 语言环境:Python3.11.2
- 编译器:PyCharm Community Edition 2022.3
- 深度学习环境:torch==2.0,torchvision==0.15.1
本次目标:
- 了解C3模块
YOLOv5-C3模块是YOLOv5网络中的一个重要组成部分,其主要作用是增加网络的深度和感受野,提高特征提取的能力。
具体来说,YOLOv5-C3模块由三个Conv模块(Conv1、Conv2、Conv3)和一个Bottleneck模块组成的,因此,其结构可以大致分为四部分:
- Conv1:作为第一个Conv模块,它对输入的特征图进行一次卷积操作。这个卷积操作可以使用任意的卷积核,但根据设计,采用1*1的卷积核可以起到降维或升维的作用,对于提取特征有重要意义。
- Bottleneck:这是第二个Conv模块,它包含两个部分。第一个部分是一个(1,1)的卷积,将输入特征图的通道数减半;第二部分是一个(3,3)的卷积,将通道数翻倍。这种设计有利于增加网络的感受野,同时减少计算量。感受野的增加可以让网络更加关注物体的全局信息,从而提高特征提取的效果。
- Conv2和Conv3:这两个Conv模块的作用与Conv1类似,都是对特征图进行卷积操作。其中,Conv2的步幅为1,而Conv3的步幅为2。这样的设计也是为了增加网络的感受野。
在每个Conv模块之间,还加入了BN层和LeakyReLU激活函数,以提高模型的稳定性和泛化性能。
总结起来,YOLOv5-C3模块通过多尺度特征融合技术和跨通道信息传递机制来提高特征图的表达能力,进而提升YOLOv5模型的性能和准确性。
一、前期准备
将数据集导入。
import torch
import torch.nn as nn
from torchvision import transforms,datasets
from torchvision.models import vgg16
import PIL,pathlib
from torchinfo import summary
import matplotlib.pyplot as plt
data_path='F:\\weather\\weather_photos'
data_path=pathlib.Path(data_path)
data_paths = list(data_path.glob('*'))
classNames = [str(path).split('\\')[2] for path in data_paths]
print(classNames)处理数据并划分数据集。
train_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225]
)
])
total_data =datasets.ImageFolder(data_path, transform=train_transforms)
print(total_data)
print(total_data.class_to_idx)
train_size = int(0.8*len(total_data))
test_size = len(total_data)-train_size
train_dataset,test_dataset=torch.utils.data.random_split(total_data,[train_size,test_size])
print(train_dataset,test_dataset)
print(train_size,test_size)
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size)二、构建C3模块
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class model_K(nn.Module):
def __init__(self):
super(model_K, self).__init__()
self.Conv = Conv(3, 32, 3, 2)
self.C3_1 = C3(32, 64, 3, 2)
self.classifier = nn.Sequential(
nn.Linear(in_features=802816, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=4)
)
def forward(self, x):
x = self.Conv(x)
x = self.C3_1(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
model = model_K().to("cpu")
summary(model)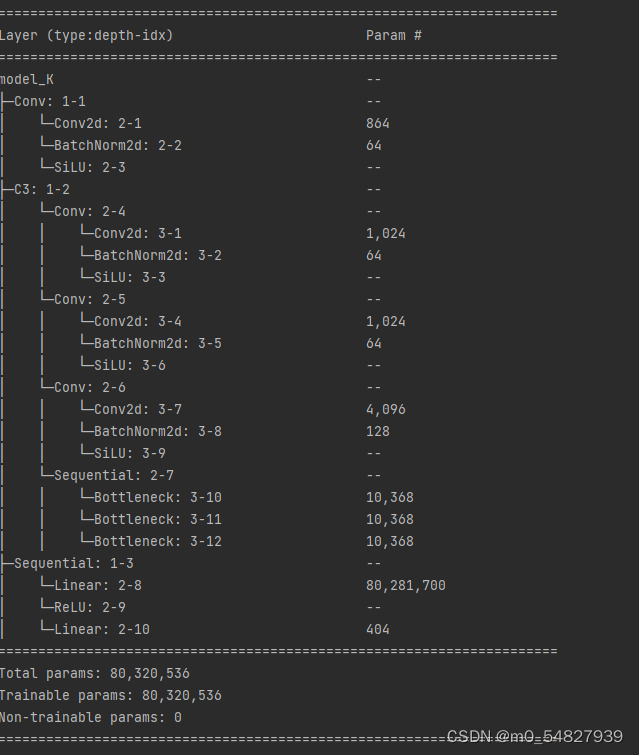
构建C3组成的模块,并将其整合。
三、训练模型
设置超参数。
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-3
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)编写训练函数和测试函数。
def train(dataloader,model,loss_fn,optimizer):
size = len(dataloader.dataset)
num_batchs = len(dataloader)
train_loss, train_acc = 0, 0
for X,y in dataloader:
pred=model(X)
loss=loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc+=(pred.argmax(1)==y).type(torch.float).sum().item()
train_loss+=loss.item()
train_acc /= size
train_loss /= num_batchs
return train_acc,train_loss
def test(dataloader,model,loss_fn):
size=len(dataloader.dataset)
num_batchs=len(dataloader)
test_loss,test_acc=0,0
with torch.no_grad():
for imgs,target in dataloader:
target_pred = model(imgs)
loss=loss_fn(target_pred,target)
test_loss+=loss.item()
test_acc+=(target_pred.argmax(1)==target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batchs
return test_acc,test_loss
正式训练。
epochs=20
train_loss=[]
train_acc=[]
test_loss=[]
test_acc=[]
for epoch in range(epochs):
model.train()
epoch_train_acc,epoch_train_loss= train(train_dl,model,loss_fn,opt)
model.eval()
epoch_test_acc,epoch_test_loss=test(test_dl,model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d},Train_acc:{:.1f}%,Train_loss:{:.3f},Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1,epoch_train_acc,epoch_train_loss,epoch_test_acc,epoch_test_loss))
print('Done')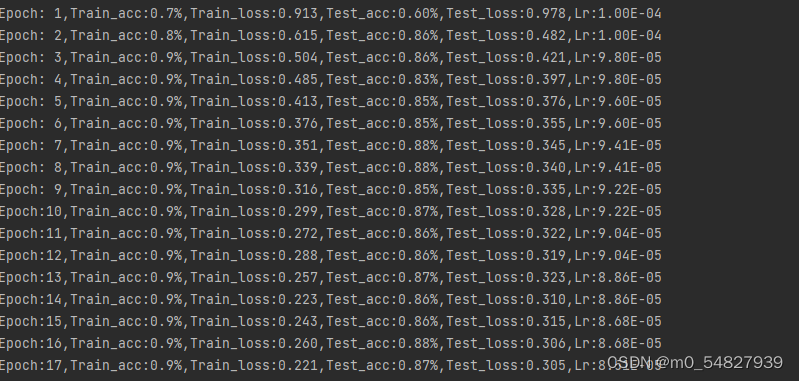
四、结果可视化
epochs_range = range(epochs)
plt.figure(figsize=(12,3))
plt.subplot(1,2,1)
plt.plot(epochs_range,train_acc,label='Training Accuracy')
plt.plot(epochs_range,test_acc,label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1,2,2)
plt.plot(epochs_range,train_loss,label='Training Loss')
plt.plot(epochs_range,test_loss,label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()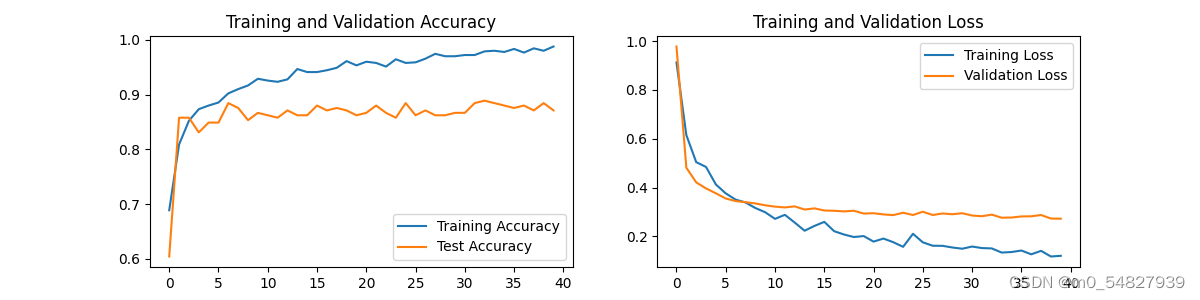
五、指定图片进行预测
classes = list(total_data.class_to_idx)
def predict_one_img(image_path, model, transform, classes):
test_img = PIL.Image.open(image_path).convert('RGB')
test_img=transform(test_img)
img = test_img.to('cpu').unsqueeze(0)
model.eval()
output = model(img)
x,pred = torch.max(output,1)
pred_class=classes[pred]
print(f'预测结果是{pred_class}')
predict_one_img(image_path='F:\\weather_photos\\cloudy\\cloudy1.jpg',model=model,transform=train_transforms,classes=classes)保存模型参数
PATH = './model.pth'
torch.save(model.state_dict(),PATH)
model.load_state_dict(torch.load(PATH))














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









