







1.组合技巧Compose
1.2 实例应用及其解释
# 用于组合多个数据处理方法
class Compose(object):
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, seq):
for t in self.transforms:
seq = t(seq)
return seq这段Python代码定义了一个名为`Compose`的类。此类的主要目的是组合多个变换函数并按顺序应用它们。这在数据预处理中很常见,尤其是在图像和序列数据处理中。让我们逐行解释代码:
1. **`class Compose(object):`**
定义了一个名为`Compose`的新类,该类继承自Python的基类`object`。
2. **`def __init__(self, transforms):`**
这是类的初始化方法。当创建`Compose`对象时,它会被调用。
- `transforms`是传递给此方法的参数,它预期是一个列表,其中包含要按顺序应用的一系列变换函数。
3. **`self.transforms = transforms`**
将传递的变换函数列表存储在类实例的`transforms`属性中。
4. **`def __call__(self, seq):`**
这是类的特殊方法`__call__`。当你像函数一样调用一个对象时,这个方法会被执行。因此,它使得对象的实例具有可调用的性质。
- `seq`是传递给此方法的参数,它是将要应用一系列变换的数据(例如,可以是一个图像、音频片段或文本序列)。
5. **`for t in self.transforms:`**
这是一个循环,用于遍历`transforms`列表中的每个变换函数。
6. **`seq = t(seq)`**
在循环内部,当前的变换函数`t`被应用于`seq`,并且结果重新赋值给`seq`。这意味着每个变换都是按顺序依次应用的,每次都更新`seq`的内容。
7. **`return seq`**
经过所有变换后,返回处理后的`seq`。
总体来说,`Compose`类的作用是,它接收一个变换函数列表,然后当你调用一个`Compose`对象并传递给它一个数据序列时,它会按照列表中的顺序依次应用这些变换,并返回处理后的数据。这种方式在深度学习库(如PyTorch的`torchvision.transforms`)中非常常见,用于定义数据增强和预处理的流程。
1.2应用逻辑
上述代码定义了一个`Compose`类,这个类的主要逻辑是:接受一个变换函数列表,并按顺序依次应用这些函数到某个输入数据上。
**实现逻辑**:
1. 初始化时,接受一个变换函数列表`transforms`并存储它。
2. 当类的实例被像函数一样调用时(使用`__call__`方法),它将按列表中的顺序依次应用这些变换函数到输入数据`seq`上。
**使用场景**:
这种设计模式在数据预处理中非常常见,特别是在机器学习和深度学习的领域:
1. **图像处理**:例如,在图像增强中,你可能希望先进行裁剪,然后旋转,接着调整亮度。通过将这些单独的变换组合成一个`Compose`对象,可以简化处理流程。
2. **文本处理**:对于文本数据,你可能希望进行分词、移除停用词、然后进行词干提取。这些变换可以通过一个`Compose`对象依次应用。
3. **数据增强**:在深度学习训练中,为了增强模型的泛化能力,经常使用数据增强技术,如图像旋转、翻转等。`Compose`可以按照指定的顺序应用这些增强。
4. **数据正则化与标准化**:在预处理流水线中,可能需要将数据进行缩放、中心化或标准化。通过`Compose`,可以将这些步骤组合成一个连续的流程。
例如,PyTorch的`torchvision`库中就有一个与上述代码类似的`transforms.Compose`类,用于构建图像预处理和数据增强的流程。
总之,`Compose`类提供了一种简洁、模块化的方法,用于组合和顺序应用多个处理步骤,使得数据预处理和增强流程更为有序和高效。
1.3 简单地上手示例
示例:
想象一下,你经常需要对数字列表进行一系列操作:先求平方,然后增加一个固定值,接着求每个数字的倒数。以下是如何使用一个Compose类似的方法来简化这个过程:
1.3.1 定义每个操作:
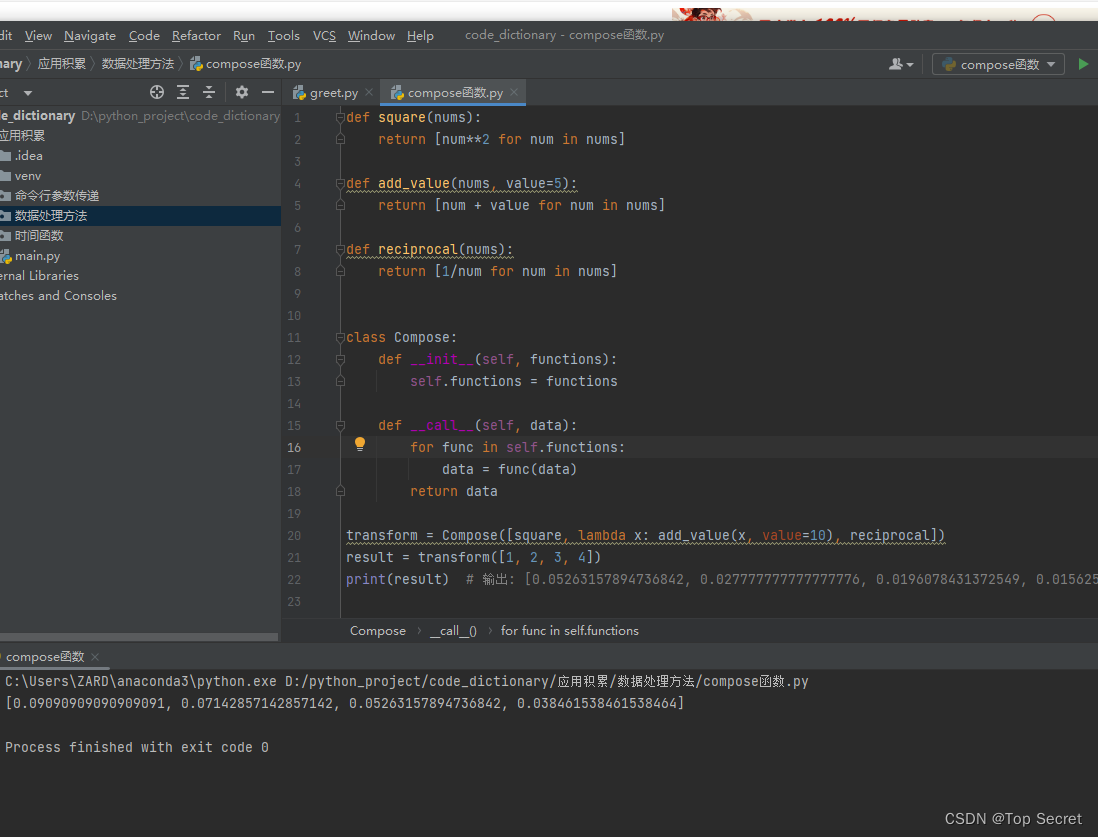
def square(nums):
return [num**2 for num in nums]
def add_value(nums, value=5):
return [num + value for num in nums]
def reciprocal(nums):
return [1/num for num in nums]
1.3.2 创建Compose工具:
class Compose:
def __init__(self, functions):
self.functions = functions
def __call__(self, data):
for func in self.functions:
data = func(data)
return data
1.3.3 使用Compose工具:
transform = Compose([square, lambda x: add_value(x, value=10), reciprocal])
result = transform([1, 2, 3, 4])
print(result) # 输出: [0.05263157894736842, 0.027777777777777776, 0.0196078431372549, 0.015625]
2.对序列进行转置操作Reshape
# 用于对序列进行转置操作
class Reshape(object):
def __call__(self, seq):
return seq.transpose()这个`Reshape`类是一个简单的工具,设计用来对输入数据(在这里是`seq`)进行转置操作。
让我们详细解释这个类:
1. **`class Reshape(object):`**
定义了一个新类名为`Reshape`,继承自Python的基类`object`。
2. **`def __call__(self, seq):`**
这是类的特殊方法`__call__`。这个方法允许我们像函数那样调用类的实例。在这种情况下,当我们创建一个`Reshape`对象,并像函数一样使用它时,这个方法将被执行。
- `seq`是传递给此方法的参数,它可能是一个矩阵或数组,我们希望对它进行转置操作。
3. **`return seq.transpose()`**
这里,我们使用了`transpose`方法对`seq`进行转置。该方法通常用于NumPy数组或其他支持这种操作的数据结构来转置矩阵。
**使用场景**:
1. **矩阵处理**:在机器学习和数据处理中,经常需要重新整形和转置数据。这个`Reshape`类提供了一种简单的方法来转置数据。
2. **图像处理**:图像通常被表示为三维数组,其中三个维度分别是高度、宽度和颜色通道。有时,基于计算需求,你可能需要调换这些维度的顺序。使用转置操作可以实现这一点。
3. **神经网络和深度学习**:在构建和训练神经网络模型时,经常需要对输入数据进行转置,以确保它们与模型的权重矩阵正确对齐。
2.1 举例实现
示例:
假设你经常需要对一系列数字进行以下操作:
- 对每个数字加5
- 将结果列表反转
传统的做法可能是:
numbers = [1, 2, 3, 4]
numbers = [num + 5 for num in numbers]
numbers.reverse()
print(numbers) # 输出:[9, 8, 7, 6]
现在,为了模块化和简化这些操作,你可以创建两个独立的类:
class AddFive:
def __call__(self, nums):
return [num + 5 for num in nums]
class Reverse:
def __call__(self, nums):
return nums[::-1]
然后,你可以使用先前介绍的Compose类将这两个操作组合起来:
class Compose:
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, data):
for t in self.transforms:
data = t(data)
return data
transform = Compose([AddFive(), Reverse()]) # 可见此步是需要按照数据处理的顺序进行的
numbers = [1, 2, 3, 4]
print(transform(numbers)) # 输出:[9, 8, 7, 6]
3.给序列添加高斯噪声
# 用于给序列添加服从高斯分布的噪声
class AddGaussian(object):
def __init__(self, sigma=0.01):
self.sigma = sigma
def __call__(self, seq):
return seq + np.random.normal(loc=0, scale=self.sigma, size=seq.shape)3.1 以一定概率给序列添加高斯噪声
# 用于以一定概率给序列添加高斯噪声
class RandomAddGaussian(object):
def __init__(self, sigma=0.01):
self.sigma = sigma
def __call__(self, seq):
if np.random.randint(2):
return seq
else:
return seq + np.random.normal(loc=0, scale=self.sigma, size=seq.shape)4.对序列进行缩放操作
# 用于对序列进行缩放操作
class Scale(object):
def __init__(self, sigma=0.01): # 定义缩放因子的标准差。默认值为0.01
self.sigma = sigma
"""
类的特殊方法__call__,它允许我们像函数那样调用类的实例。这意味着你可以创建一个Scale对象,并直接对序列进行缩放,而不需要调用特定的方法。
seq:这是传入此方法的序列,我们打算对它进行缩放。
"""
def __call__(self, seq):
scale_factor = np.random.normal(loc=1, scale=self.sigma, size=(seq.shape[0], 1))
scale_matrix = np.matmul(scale_factor, np.ones((1, seq.shape[1])))
return seq*scale_matrix-
scale_factor = np.random.normal(loc=1, scale=self.sigma, size=(seq.shape[0], 1))
这行代码生成一个随机缩放因子。缩放因子来自正态分布,其均值为1(即loc=1),标准差为sigma。这些缩放因子的形状与输入序列的行数相同。 -
scale_matrix = np.matmul(scale_factor, np.ones((1, seq.shape[1])))
这行代码创建一个缩放矩阵。为此,它将缩放因子与一个全为1的矩阵进行矩阵乘法。这确保了每行的所有元素都乘以相同的缩放因子。 -
return seq*scale_matrix
这是最后一步,它返回缩放后的序列。这是通过将原始序列与缩放矩阵进行元素级乘法来实现的。
这个
Scale类提供了一种随机缩放输入序列的方法。缩放的程度由参数sigma决定,它控制随机生成的缩放因子的变异程度。这种随机缩放通常在数据增强中使用,特别是在机器学习和深度学习领域,用于增加模型的泛化能力。
4.1 以一定概率对序列进行缩放操作
# 以一定概率对序列进行缩放操作
class RandomScale(object):
def __init__(self, sigma=0.01):
self.sigma = sigma
def __call__(self, seq):
if np.random.randint(2):
return seq
else:
scale_factor = np.random.normal(loc=1, scale=self.sigma, size=(seq.shape[0], 1))
scale_matrix = np.matmul(scale_factor, np.ones((1, seq.shape[1])))
return seq*scale_matrix`RandomScale`类与之前的`Scale`类主要有一个显著的区别:在`RandomScale`中,有一个随机决策过程决定是否对序列`seq`进行缩放。
以下是该类的特定部分的解释:
1. **`if np.random.randint(2):`**
这里使用`np.random.randint(2)`随机生成0或1。如果生成的数字是1(有50%的概率),则直接返回原始序列而不进行缩放。
2. **`else:`**
如果生成的数字是0,该方法将继续并对序列进行与`Scale`类相同的缩放操作。
这种随机决策意味着不是每次都对输入序列进行缩放。大约有一半的机会序列会保持不变,而另一半的机会会进行随机缩放。
此设计有以下可能的原因或应用场景:
1. **提供更多的多样性**:有时不对数据进行任何变化也是有益的,这增加了数据集的多样性,可以更好地模拟真实世界的不确定性。
2. **减少计算成本**:在某些情况下,每次都进行缩放可能会增加不必要的计算成本。通过随机地只对一部分数据进行缩放,可以在保持模型性能的同时减少这些额外的计算。
3. **数据增强的平衡**:在某些情况下,过多的数据增强可能会导致模型学到错误的模式。通过只随机应用缩放,可以为模型提供更平衡的、增强与未增强的数据组合。
总的来说,`RandomScale`类提供了一个在随机情况下对输入序列进行缩放的方法,而`Scale`类则始终对输入序列进行缩放。根据应用场景和需求,你可以选择最适合的方法。
4.2 在什么情况下需要做此缩放
在机器学习和深度学习中,对数据进行缩放或其他类型的增强是为了满足多种目的。使用`Scale`类进行随机缩放可能是基于以下几个原因:
1. **数据增强**:特别是在深度学习领域,数据增强是一种常用的技术,用于通过对原始数据进行微小的变化来人为地增加训练数据。这可以帮助模型更好地泛化到未见过的数据,防止过拟合。
2. **模拟真实情境**:在某些情况下,原始数据可能会受到各种因素的影响而发生微小的变化。随机缩放可以模拟这种真实的数据变化,帮助模型在实际应用中表现得更好。
3. **特征工程**:缩放可以作为特征工程的一部分,以创建新的或修改现有的特征,从而提高模型的性能。
4. **破坏不相关的模式**:在某些情况下,数据中可能存在不希望模型学习的模式。随机缩放可以破坏这些模式,使模型更加专注于真正重要的特征。
5. **增加模型的鲁棒性**:通过训练模型处理缩放后的数据,可以增加其对输入变化的鲁棒性。
6. **处理不稳定数据**:在某些应用中,例如金融或医学图像处理,数据可能会有大的变化或不稳定性。随机缩放可以帮助模型适应这些变化,提高预测的稳定性。
总的来说,随机缩放和其他数据增强技术在处理有限的数据、增加模型泛化能力或模拟特定的实际情境时都非常有用。
5.以一定概率对序列进行随机拉伸操作
随机地“拉伸”或“压缩”一个输入的序列:
# 以一定概率对序列进行随机拉伸操作
class RandomStretch(object):
def __init__(self, sigma=0.3):
self.sigma = sigma
def __call__(self, seq):
if np.random.randint(2):
return seq # 返回原始的、未修改的序列。
else: # 如果进入这部分代码,序列将会被拉伸或压缩。
# 创建一个形状与原始序列相同的零数组,用于存储修改后的序列。
seq_aug = np.zeros(seq.shape)
len = seq.shape[1]
"""
计算拉伸或压缩后的序列长度,其中,(random.random()-0.5)*self.sigma会生成一个在-self.sigma/2到self.sigma/2范围内的随机值,这决定了拉 伸或压缩的幅度。
"""
length = int(len * (1 + (random.random()-0.5)*self.sigma))
# 这个循环会对序列的每一行(假设序列是二维的)进行拉伸或压缩。
for i in range(seq.shape[0]):
# 使用resample方法对当前行的数据进行重采样,使其达到前面计算的length长度。
y = resample(seq[i, :], length)
"""
接下来的if-else语句块
这部分考虑了新的序列长度与原始长度的关系,并相应地填充或截断数据以适应seq_aug的形状。
如果新长度小于原始长度,程序会选择将重采样后的数据放在seq_aug的开头或结尾。
如果新长度大于原始长度,程序会选择从重采样后的数据的开头或结尾截取适量的数据以适应seq_aug 的长度。
"""
if length < len:
if random.random() < 0.5:
seq_aug[i, :length] = y
else:
seq_aug[i, len-length:] = y
else:
if random.random() < 0.5:
seq_aug[i, :] = y[:len]
else:
seq_aug[i, :] = y[length-len:]
return seq_aug # 最后,返回拉伸或压缩后的序列。总结:
RandomStretch类是用于对输入序列进行随机拉伸或压缩的。这种拉伸或压缩的数据增强方法可能在处理时序数据,如音频、股票价格或其他连续数据时特别有用,因为它可以模拟序列的时间变化,从而增加模型的泛化能力。
6.以一定概率对序列进行随机裁剪操作
RandomCrop类的目的是以一定的概率对输入的序列进行随机裁剪操作。裁剪并不是像图像裁剪那样移除某个部分,而是将选定的序列部分设置为0。
# 以一定概率对序列进行随机裁剪操作
class RandomCrop(object):
def __init__(self, crop_len=20): #参数crop_len,代表需要被设置为0的序列的长度。默认长度为20。
self.crop_len = crop_len
def __call__(self, seq):
if np.random.randint(2): # 有50%的机会直接返回原始的、未修改的序列。
return seq
else: # 否则序列的某一部分将会被设置为0。
"""
计算可以裁剪的最大起始索引。例如,如果序列长度为100,crop_len为20,那么最大的起始索引为80, 以确保裁剪的部分不会超出序列长度。
"""
max_index = seq.shape[1] - self.crop_len
# 随机选择一个起始索引,范围从0到max_index。
random_index = np.random.randint(max_index)
"""
将选定的部分设置为0。这里,:表示操作应用于所有行(如果seq是二维的),而 random_index:random_index+self.crop_len选择从random_index开始的self.crop_len长度的序列。
"""
seq[:, random_index:random_index+self.crop_len] = 0
return seq # 返回裁剪后的序列总体来说,
RandomCrop类将随机选择输入序列的一个部分,并将其设置为0。这种数据增强方法可以模拟序列中的数据丢失或干扰,从而增强模型的鲁棒性和泛化能力。
7.对序列进行归一化操作
这个Normalize类用于对输入的序列进行规范化或标准化处理。这是处理数据集时常见的一个预处理步骤,以确保所有数据在同一尺度上,从而有助于模型的训练和收敛。
# 对序列进行归一化操作
class Normalize(object):
# 默认为"0-1"范围规范化。
def __init__(self, type = "0-1"): # "0-1","-1-1","mean-std"
self.type = type
def __call__(self, seq):
if self.type == "0-1":
seq = (seq-seq.min())/(seq.max()-seq.min())
# 如果选择的规范化类型为"-1-1",则使用这种方法。这会将序列中的最小值映射到-1,最大值映射到1,所有其他值将在-1到1之间。
elif self.type == "-1-1":
seq = 2*(seq-seq.min())/(seq.max()-seq.min()) + -1
elif self.type == "mean-std" :
seq = (seq-seq.mean())/seq.std()
else:
raise NameError('This normalization is not included!')
return seq

















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











