







目 录
一 课程设计的目的 3
二 课程设计的内容和要求 3
三 详细设计 3
- 算法介绍 3
- 实验及分析 3
2.1数据集介绍 3
2.2数据预处理 4
2.3 模型介绍 6
2.4 模型评估 8 - 结论 8
四 课程设计总结 9
一 课程设计的目的
在大数据时代,网络上的文本数据日益增长。采用文本分类技术对海量数据进行科学地组织和管理显得尤为重要。文本作为分布最广、数据量最大的信息载体,如何对这些数据进行有效地组织和管理是亟待解决的难题。文本分类是自然语言处理任务中的一项基础性工作,其目的是对文本资源进行整理和归类,同时其也是解决文本信息过载问题的关键环节。文本分类按照任务类型的不同可划分为问题分类、主题分类以及情感分类,常用于数字化图书馆、舆情分析、新闻推荐、邮件过滤等领域,为文本资源的查询、检索提供了有力支撑,是当前的主要研究热点之一。
二 课程设计的内容和要求
本次课程设计我们主要研究新闻文本分类,新闻文本分类技术是从预定义的新闻类目集合中,通过有监督分类模型,从源文本中提取出代表该文本的相关特征,最终自动将其划分到该主题标签下,达到新闻有序归类的目的。
三 详细设计
先收集数据集对其进行jieba分词并去除停用词以达到数据预处理的目的,再将其数据进行划分成训练集和测试集,使用词袋模型和TF-IDF两种模型对文本提取特征,并使用分类器进行分类,并计算最后的准确率。在分类器的选择上,我们选择了朴素贝叶斯算法,基于贝叶斯定理与特征条件独立性假设的分类方法,使用多项式模型来进行训练。
1 算法介绍
贝叶斯分类算法是一类分类算法的总和,均以贝叶斯定理为基础,故称之为贝叶斯分类。朴素贝叶斯分类算法就是其中最简单的分类算法,朴素贝叶斯分类算法很简单,就一个公式如下所示:
P(B|A) =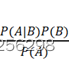
朴素贝叶斯的做法是将一个由[w1,w2,w3…wn]这样一个特征向量转换为分离的特征。
朴素贝叶斯常用的三个模型有:
高斯模型:处理特征是连续型变量的情况;
多项式模型:最常见,要求特征是离散数据;
伯努利模型:要求特征是离散的且为布尔类型,即true和false,或者1和0;
用朴素贝叶斯原理,处理一个分类问题,一般要经过以下几个步骤:
1、准备阶段:
获取数据集。分析数据,确定特征属性,并得到训练样本。
2、训练阶段:
计算每个类别概率P(B)。对每个特征属性,计算每个分类的条件概率P(A|B)。
B 代表所有的类别。
A 代表所有的特征。
3、预测阶段:
给定一个数据,计算该数据所属每个分类的概率P(A|B) * P(B)。最终哪个分类的概率大,数据就属于哪个分类。
2 实验及分析
2.1 数据集介绍
该数据集一共有5000条新闻数据,数据表示为四列,分别为:‘label’‘theme’‘URL’‘content’其中content包含有‘汽车’‘财经’‘科技’‘健康’‘体育’‘教育’‘文化’‘军事’‘娱乐’‘时尚’10类。
2.2 数据预处理
数据预处理是个很重要的过程,我们使用的是中文数据集,中文语料的特点是词与词之间是紧密相连的,这一点不同于英文,因此在分词的时候不能像英文使用空格分词,需要使用特殊的分词方法。
1、数据读取
import numpy as np
import pandas as pd
import jieba
newdata = pd.read_table("data.txt",names=['label','theme','URL','content'],encoding='utf-8')
# 查看数据维度
print(newdata.shape)
# 提取我们要用到的数据
content = newdata['content'].values.tolist()
print(content)
图 1 数据读取<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4370
4370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









