







 本文深入探讨了混合动作空间在深度强化学习中的挑战,重点介绍了HyAR算法,一种利用条件变分自编码器和嵌入表来构建紧凑隐式动作表征的方法。通过环境动力学预测增强动作表征学习,HyAR在高维混合动作空间中展现出优越性能和收敛速度。实验部分展示了与基线算法的对比,并分析了算法的关键组件如Latent Space Constraint和Representation Shift Correction的作用。
本文深入探讨了混合动作空间在深度强化学习中的挑战,重点介绍了HyAR算法,一种利用条件变分自编码器和嵌入表来构建紧凑隐式动作表征的方法。通过环境动力学预测增强动作表征学习,HyAR在高维混合动作空间中展现出优越性能和收敛速度。实验部分展示了与基线算法的对比,并分析了算法的关键组件如Latent Space Constraint和Representation Shift Correction的作用。
在前几期博客里,我们介绍了混合动作空间的定义和相关的一些经典算法(如 P-DQN,H-PPO 等):
混合动作空间 | 创造人工智能的黑魔法(1)_面向连续-离散混合决策的游戏ai智能体强化学习方法_OpenDILab开源决策智能平台的博客-CSDN博客
混合动作空间|揭秘创造人工智能的黑魔法(2)_OpenDILab开源决策智能平台的博客-CSDN博客
混合动作空间|揭秘创造人工智能的黑魔法(3)_OpenDILab开源决策智能平台的博客-CSDN博客
混合动作空间|揭秘创造人工智能的黑魔法(4)_OpenDILab开源决策智能平台的博客-CSDN博客
而在近些年来,深度强化学习的研究者们将目光投向了更通用的混合动作空间建模方法,开始尝试设计额外的表征学习模块来获得更紧凑(compact)、更高效的动作表征,从而拓展强化学习在复杂动作空间上的应用。在本博客中,我们将会介绍相关工作之一:HyAR [1]。
论文概述
🌟研究背景
针对决策问题输出成混合动作空间的问题(这里特指参数化动作空间,即离散动作类型和对应的连续参数),最直接的方法是通过简单离散化或连续化将原始空间转换为统一的同质动作空间 ,但显然这种做法忽略了混合动作空间的底层内在结构,存在严重的扩展性和训练稳定性问题,具体参考下例:
例如,原始混合动作空间为维离散动作和
维连续动作,如果对这
维连续动作的每一维离散为
个 bin,则变换后的总的离散动作空间为
维。当
较大时该值会很大,如果用类似 DQN 算法来求解会导致 Q 函数学习负担比较大,不能很好地拟合每一个动作的 Q 值,从而不能扩展到高维空间上。
为了更好地建模混合动作空间的内在结构并扩展到高维情形,HyAR 便应运而生,具体概览如下:
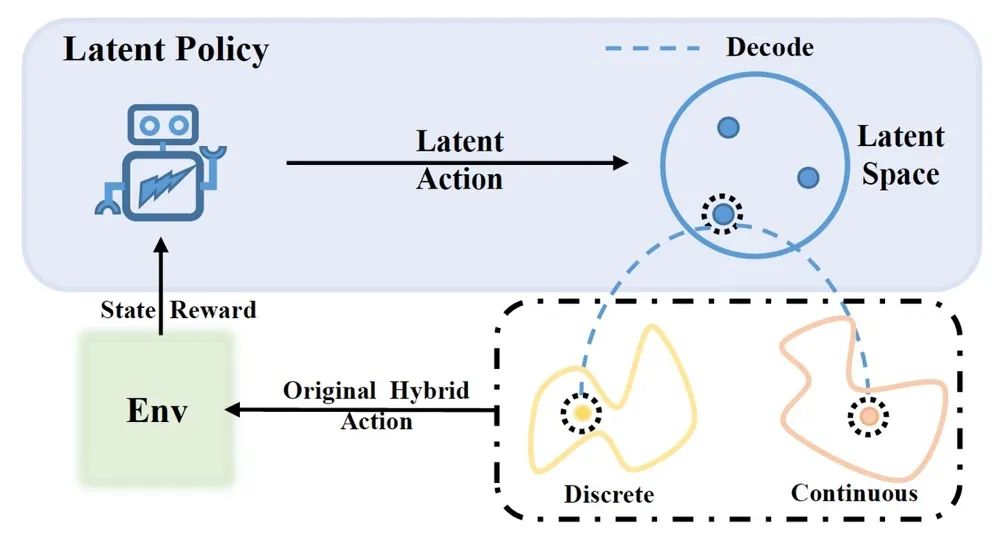
图1:HyAR 算法概览图
上图将原始混合动作映射到一个隐式表征空间 (latent space) ,RL 智能体在隐空间上训练学习一个 latent policy。而在与环境交互时,智能体选择的 latent action 会通过 decoder 解码回原始混合动作,然后执行收集数据与评估的后续流程。
🌟核心思路
-
提出了一种混合动作表征(Hybrid Action Representation,HyAR)方法,将原始混合动作空间转换为一个紧凑的、可编解码的隐式表征空间。
-
通过条件变分自编码器(conditional VAE)和可学习的嵌入表(embedding table),对原始动作的离散部分和连续部分之间的依赖性进行建模,构造出一个优质的隐式动作空间。
-
为了进一步提高模型的有效性,作者利用无监督的环境动力学预测(unsupervised environmental dynamics prediction)方法,使得训练得到的动作表征更适用于 RL 训练。
-
最后,应用常规强化学习算法在这个学习得到的动作表征空间上优化策略,通过动作表征的 decoder 将动作表征解码回原始动作空间执行与环境交互收集数据与评估的后续流程。
🌟实验评估
在 gym-hybrid 等混合动作空间 Benchmark 环境上对比了 HyAR 与其他基线混合动作空间算法,展现出更好的最终性能和收敛速度。另外,进一步的实验表明,在高维动作空间上,HyAR 的优势会更加明显。
核心算法
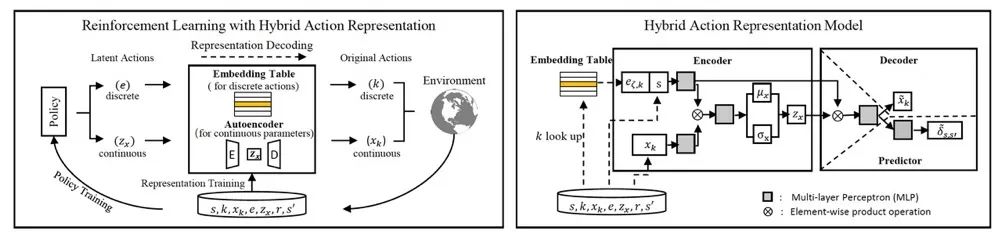
图2: (左) 混合动作空间表征与强化学习结合的流程图。(右) 混合动作表征模型的结构:包括条件变分自编码器 (conditional VAE) 和可学习的嵌入表 (embedding table)

具体的算法设计需要解决两方面的问题:
-
建模混合动作中各部分之间的关系。
-
latent policy 输出的 latent
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8484
8484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









