






Weakly Supervised Instance Segmentation for Videos with Temporal Mask Consistency 阅读笔记
论文地址: Weakly Supervised Instance Segmentation for Videos with Temporal Mask Consistency
摘要
弱监督实例分割的优点:减少训练模型所需的标注成本。
现有的仅依赖于图像级类标签的方法主要存在由对象的部分分割、缺少对象预测导致的错误。提出使用弱标记视频来解决这些问题,具体地:
针对部分分割,提出使用flowIRN在训练过程中有效地融合运动信息。
针对缺少实例,提出MaskConsist,利用时间一致性,并在训练期间将稳定的掩码预测传输到相邻帧。

引言
虽然标注弱标签要便宜得多,但它们通常有两个错误来源:(a)部分实例分割和(b)缺少对象实例。
- (a)部分实例分割的原因:
弱监督方法通常只识别有助于预测类标签的最具辨别力的对象区域。如IRNet、CAM。 - (b)缺少对象实例的原因:
①当图像中存在多个实例时,容易错过某些对象实例。
②因为实例被遮挡或姿态改变,一个实例可以在一个图像中分割但不能在另外一个图像中分割。
这些问题在视频实例分割中并不严重,因为视频中的对象运动提供了额外的信号(属于同一(刚性)对象的像素一起移动,具有相似的流向量)。本文将此类视频信号用于训练弱监督的实例分割模型。
本文工作:
-
修改IRN,将相似的标签分配给具有相似运动的像素。(有助于解决部分分割的问题)“IRN”=>“flowIRN”。
-
引入MaskConsist模块,通过利用连续帧中对象之间的时间一致性来解决缺少实例的问题。
MaskConsist模块:它在相邻帧之间匹配预测,并传输稳定的预测,以获得flowIRN在训练期间丢失的额外伪标签。
本文方法
首先引入了像素间关系网络(inter-pixel relation network, IRN)的初步概念[1],并将其扩展到视频信息中,形成了flowIRN。接下来,引入了MaskConsist,它在连续帧的预测中强制时间一致性。该框架有两个阶段的训练过程:(1)训练flowIRN,(2)使用flowIRN在训练帧上生成的掩码作为监督来训练mask包括模型,如图2所示。

IRNet简单介绍:
- IRNet(IRN)具有两个分支的网络,分别预测:
- 指向包含像素的实例中心的每像素位移向量 (类不可知实例映射)
- 指示像素是否位于对象边界上的每像素边界可能性(一对像素之间的语义亲和力)
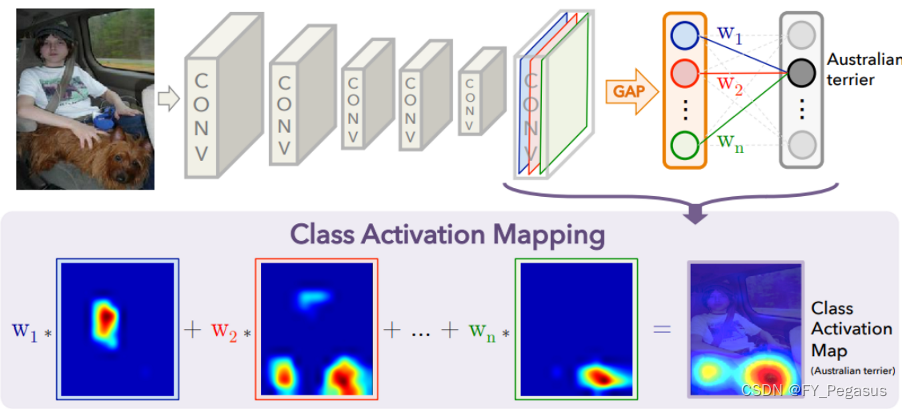
- IRNet:从类激活图(CAM)中提取像素间关系,并使用它来推断实例位置和类边界。
- CAM: 对于给定一个图片,为每个类提供像素级分数,然后将这些分数转换为类标签。
(如果该分数高于前景阈值,则为每个像素分配对应于该像素处最高类别激活分数的标签。否则,将为其指定背景标签)
- CAM: 对于给定一个图片,为每个类提供像素级分数,然后将这些分数转换为类标签。
- 使用弱监督的缺点:
- IRN在弱监督模型中不能使用位移和边界标签。
- 相反: IRN会带来基于从CAM推断的前景/背景标签对位移和边界预测施加约束产生的误差
- 推理中,获得实例分割掩码的步骤:
- 将位移向量指向同一质心的所有像素分组在一起,以获得每像素实例标签。
- 使用成对亲和力α对预测进行细化。
公式: B(k):IRN预测像素k的边界似然。 ∏_i,j:位于连接i和j的线上的像素集。

亲和力:随机游走算法的转移概率。- 亲和力低:如果两个像素由对象边界分隔,则连接它们的线上至少有一个像素应属于该边界。
- 亲和力高:位于同一实例的一部分的像素。
FlowIRN Module
IRN的改进:通过将光流信息纳入两个组件(流量放大CAMs和流量边界损耗)来改进IRN。
-
流量放大CAMs:
- 原来的CAMs:
仅识别物体的辨别区域(如动物的脸),而错过与该物体对应的其他区域。
由于视频中感兴趣的对象通常是移动的前景对象,所以在观察到大运动的区域通过放大摄像机来解决这个问题。 - 具体改进步骤:
-
当前帧的估计光流:

-
将IRN中用到的CAMs替换,公式中A是放大系数 T是流量大小阈值。
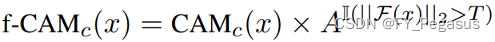
(此操作将平等地应用于所有类的CAMs,保持类分数的相对顺序。从CAMs获取的类别标签不会翻转;只影响前景和背景指定。)
- 原来的CAMs:
-
流量边界损耗:
在图片中,边界预测来自CAMs的伪分割标签(不区分同一类别的实例,尤其是重叠实例)监督。
在视频中,光流可以消除这种情况的歧义。因为同一刚性对象的像素一起移动并且具有一致的运动,来自同一对象的点可以来自相对于摄影机的不同深度,并且可能不具有相同的光流。
因此,使用光流的空间梯度来识别两个像素是否来自同一对象实例,可以观察到:梯度对这种深度变化更为稳健。 -
新的流动边界损失
式中F’(i)是表示像素i处的光流相对于其各自的空间坐标(xi,yi)的梯度的二维向量。Ni是IRN中定义的i周围的小像素邻域,λ是正则化参数。
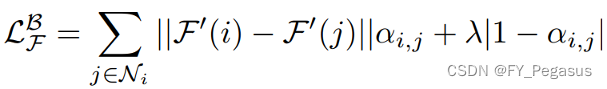
- 式中第一项:具有相似流动梯度的像素可以具有高亲和力(属于同一实例),
而具有不同流梯度的像素应该具有低亲和力(属于不同实例)。 - 式中第二项:用于正则化损失并防止α的平凡解始终为0。
- 式中第一项:具有相似流动梯度的像素可以具有高亲和力(属于同一实例),
本文利用上述损失和IRN中的原始损失来训练flowIRN。
MaskConsist
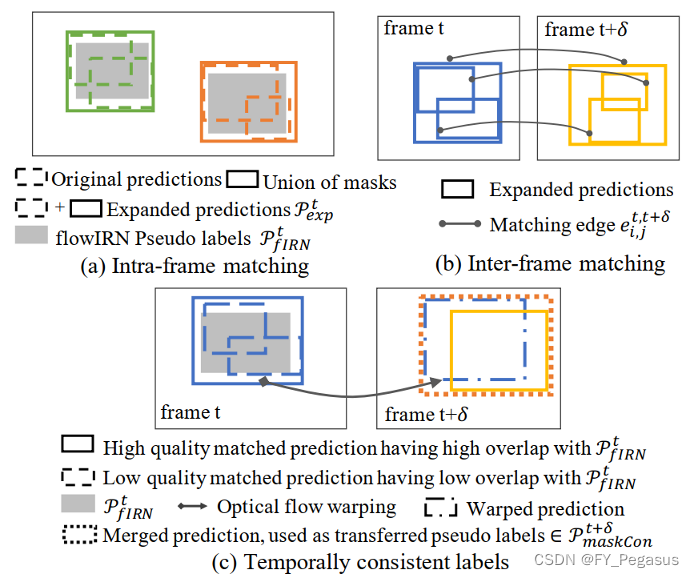
a. 帧内匹配通过合并高度重叠的预测来扩展当前Mask R-CNN的原始预测。
b. 帧间匹配识别跨帧预测之间的一对一匹配。
c. 使用光流扭曲后,时间一致性标签将匹配的预测从一帧传输到另一帧。
- 问题描述: flowIRN生成的实例级掩码现在可以用作伪标签来训练完全监督的实例分割模型(如Mask R-CNN),这在验证集上产生了比原始flowIRN模型更好的性能。但是flowIRN生成的伪标签可能会丢失某些帧上的对象实例。
- 解决方法:
MaskConsist通过在训练Mask R-CNN的同时将“高质量”掩码预测作为新的伪标签从相邻帧传输到当前帧来解决此问题。- 具体步骤:
- 在每次训练迭代中,使用视频中的一对相邻帧t和t+δ来训练网络,除了来自flowIRN的伪标签外,当前Mask R-CNN对t+δ的预测子集被用作t的附加伪标签,反之亦然。
- 仅当(a)预测在时间上稳定且(b)与现有的伪标签重叠时,预测才会转移。这避免了MaskConsist的错误否定。
- 具体步骤:
- MaskConsist包含:
-
帧内匹配:

-
帧间匹配:

-
时间一致的标签分配:

-

















 2160
2160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











