







笔者最近在复习spark,发现对cogroup算子掌握不牢固。因此写下这篇博客,方便以后学习。
join算子
join算子相当于将两个rdd进行内连接,在join的结果中,返回值是key和元组
cogroup算子
cogroup算子相当于将两个rdd中 相同键的每个元素的value进行合并中。
在 cogroup 的结果中,返回值是key和迭代器。对于每个key,元组的第一个元素是一个迭代器,包含了所有具有该键的第一个RDD的元素,第二个元素是另一个迭代器,包含了所有具有该键的第二个RDD的元素。如果某个RDD中没有与该键匹配的元素,对应的迭代器将为空。
代码如下
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("test230827")
sc = SparkContext(conf=conf)
data1 = [("a", 1), ("b", 2), ("c", 3), ("b", 5)]
data2 = [("a", "x"), ("b", "y"), ("d", "z")]
# join ===========================================================
rdd1 = sc.parallelize(data1)
rdd2 = sc.parallelize(data2)
joined = rdd1.join(rdd2)
result = joined.collect()
print(result)
# cogroup ===========================================================
rdd1 = sc.parallelize(data1)
rdd2 = sc.parallelize(data2)
cogrouped = rdd1.cogroup(rdd2)
result = cogrouped.mapValues(lambda x: (list(x[0]), list(x[1]))).collect() # 因为返回值是迭代器 所以要使用list进行处理
print(result)
sc.stop()
运行结果
[('b', (2, 'y')), ('b', (5, 'y')), ('a', (1, 'x'))]
[('b', ([2, 5], ['y'])), ('d', ([], ['z'])), ('a', ([1], ['x'])), ('c', ([3], []))]
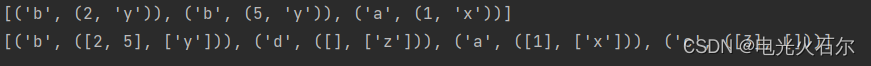
















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











