







这篇论文是23年10月提交到arxiv上的,也是用大模型蒸馏小模型的思路。
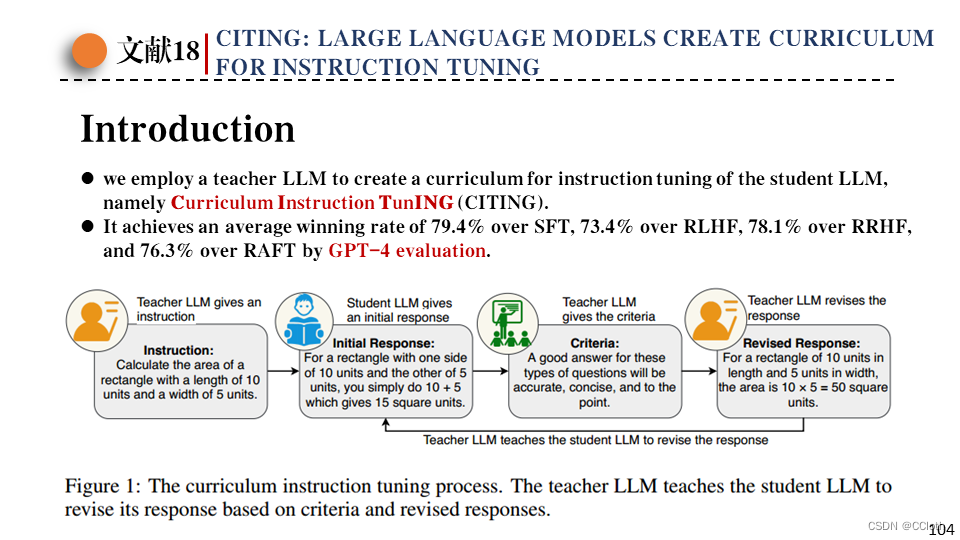
作者在这篇论文中提出了课程指令微调,大体流程如下图所示,教师模型给出一个问题,让学生模型回答一下,这时候学生回答大概率不够准确,这时候把学生的回答以及评价该问题的标准输入给教师模型,让教师模型给出一个修改后的回答,然后让学生根据修改过的回答进行微调,持续这个过程若干轮就能得到一个不错的学生模型。
作者的灵感来自于导师帮学生修改论文这个场景,学生把写好的论文发给导师,导师把修改版返回去,然后学生可以比较原版和修改版之间的差异,以此来提升自己的写作水平。
最终得到的小模型经过GPT-4评估,对比大部分模型都有70%以上的胜率。这些模型都是在LLaMA-7B的基础上训练得到的。

整个系统分为两部分,第一部分是根据教师LLM确定不同指令的评价标准,第二部分是对学生模型使用之前提到的课程指令微调。

对于第一部分确定不同指令评价标准时又分两步,首先是不同的指令众多,如果每个指令对应一个单独的标准是不现实的,作者将指令进行了分类,对于同一类指令使用相同的评价标准,分类这件事也是交给LLM处理的,使用的prompt如下图所示,顺便还让LLM把该类别标准一起生成了。
然后就是对于测试集中没见过的指令如果确定它的类别呢,这里使用sentence-BERT模型来对训练集中每条指令编码为embedding,然后新来的指令也同时编码为embedding,对于每个指令类都和其中每个指令计算内积,然后这条指令和每个类别的相似度就是内积的均值,最后这条指令类别就是相似度最高的那个类别。类别确定了那这条指令对应的标准也就确定了。
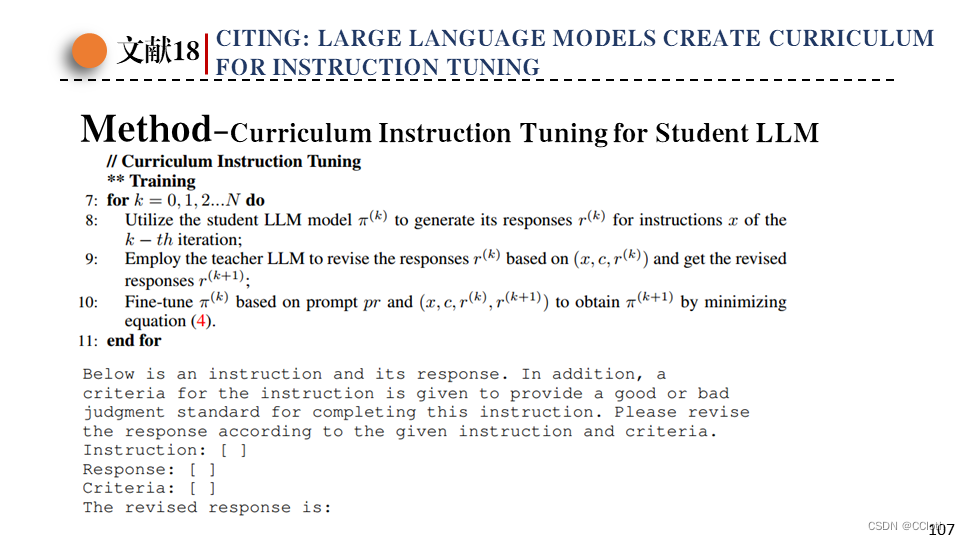
课程指令微调这部分直接看伪代码会好理解一些,上面那张图就是论文中的伪代码。一共有若干轮,每轮先直接让学生模型输出回答,然后把问题、标准还有学生回答拿给教师模型,让教师模型生成一个修改版的回答,再把问题、标准、学生回答还有教师回答拿给学生模型微调,教师生成回答和微调学生的prompt如下图所示。

这里展示了这篇论文的一些细节,这部分内容还是挺重要的。首先模型使用的是LLaMA-7B作为基座模型,然后使用了Alpaca数据集来训练,将划分训练集、验证集和测试集为8:1:1,然后在训练集和验证集上用LoRA框架微调学生模型得到SFT,之后就是抽取了1000条问题,以GPT-3.5为教师模型,逐步改进学生的回答。

最后是结果展示,作者在四个数据集上比较了CITING和SFT、RLHF、RRHF(Rank responses to align language models with human feedback without tears)和RAFT(Reward ranked finetuning for generative foundation model alignment)的胜率,由GPT-4给出从回答清晰度、回答深度和综合性三方面的得分。可以看到无论哪项比较CITING都保持着优势。

接下来是对于迭代轮数的消融实验,可以看到第四轮开始模型性能就开始退化了。作者解释到这是因为重复指令微调(毕竟一直是那1000个指令,如果每次重新抽样会不会好点?)导致了灾难性遗忘,微调后的模型忘记了最早的SFT的知识,导致模型性能下降。















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









