






 该论文介绍了BLIP2的指令感知Q-former和均衡采样策略,以解决数据集规模不均衡导致的过拟合和欠拟合问题,实验证明了这两个贡献对模型性能的关键性。BLIP2在zero-shot任务中表现出SOTA性能,且指令微调效果优于多任务学习。
该论文介绍了BLIP2的指令感知Q-former和均衡采样策略,以解决数据集规模不均衡导致的过拟合和欠拟合问题,实验证明了这两个贡献对模型性能的关键性。BLIP2在zero-shot任务中表现出SOTA性能,且指令微调效果优于多任务学习。

instructBLIP这篇论文也是ALBEF,BLIP,BLIP2团队的工作,之前几篇的一作变成通讯和共一了,于23年9月发表。
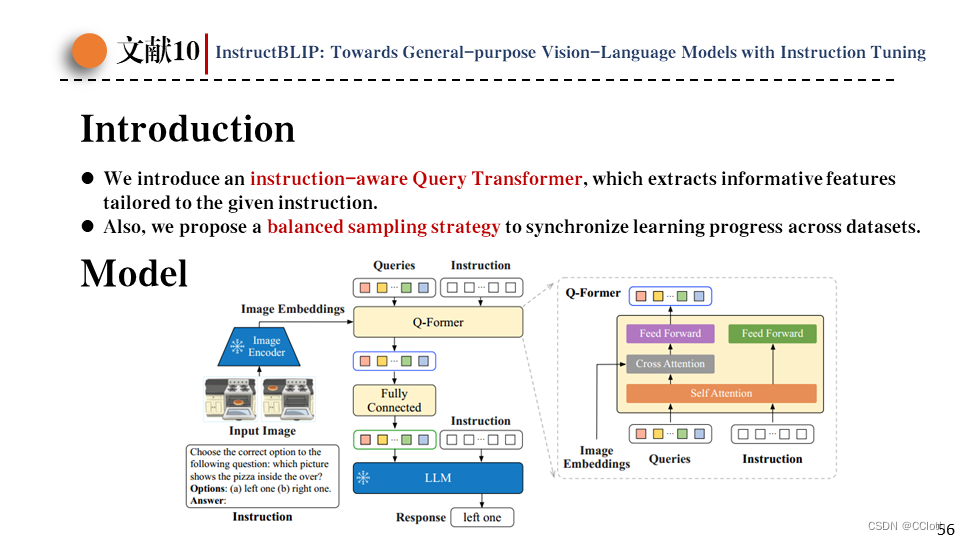
这篇论文内容比较简单,基本就是BLIP2的指令微调版本。作者主要提出了两点贡献。
第一点就是提出了指令感知的Q-former,可以提取与指令相关的图像特征。
第二点就是提出了均衡采样策略,对于不同数据集有不同的采样概率。
下面这张图就是模型结构,除了在做微调时将指令也一起输入给Q-former以外,还有LLM用vicuna版本替换opt版本。其余基本都与Blip2一致。
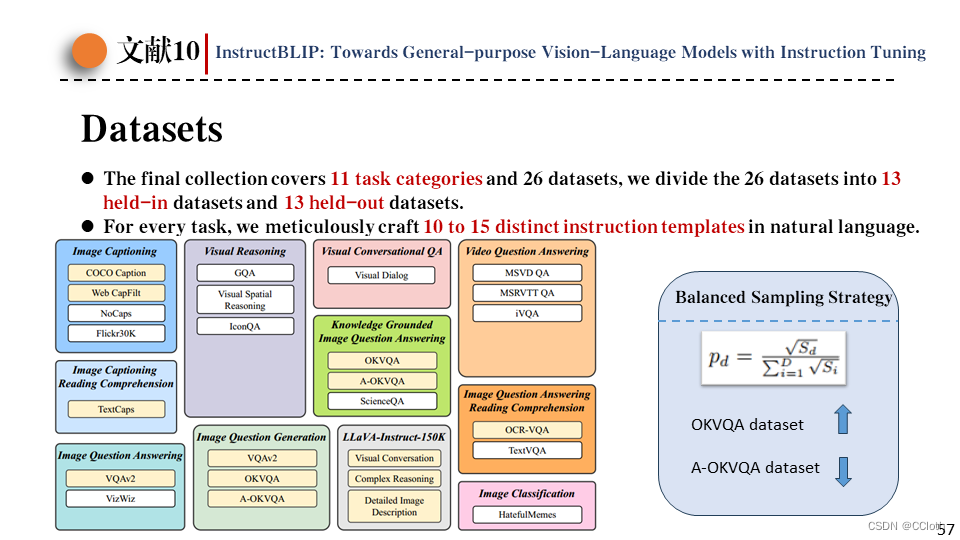
一共使用了26个公开数据集,涉及11项任务,其中标黄色的为微调数据集,其余为测试数据集。
由于不同数据集规模不同,等概率地对每个数据集采样可能导致模型在小数据集(一般是简单任务)上过拟合,在大数据集(一般是复杂任务)上欠拟合。为此作者又提出了第二点贡献,也就是均衡采样策略。具体而言就是根据模型规模确定采样概率,大数据集采样概率高,小数据集采样概率低。另外作者又考虑任务难度,对于这两个数据集手动调整采样概率。具体而言,像OKVQA这种开放式文本生成的数据集,提升采样概率,对于A-OKVQA这种以选择题为主的数据集降低采样概率。主要是考虑前者任务难,后者任务简单。
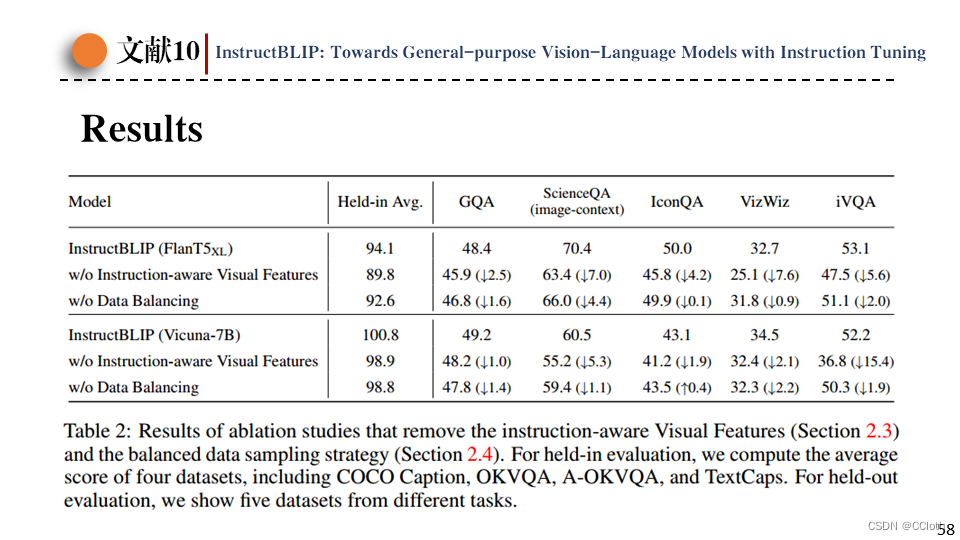
这张表对论文提出的两点主要贡献做的消融实验,可以看到去掉这两个哪一个对于模型性能都会造成明显的下降。
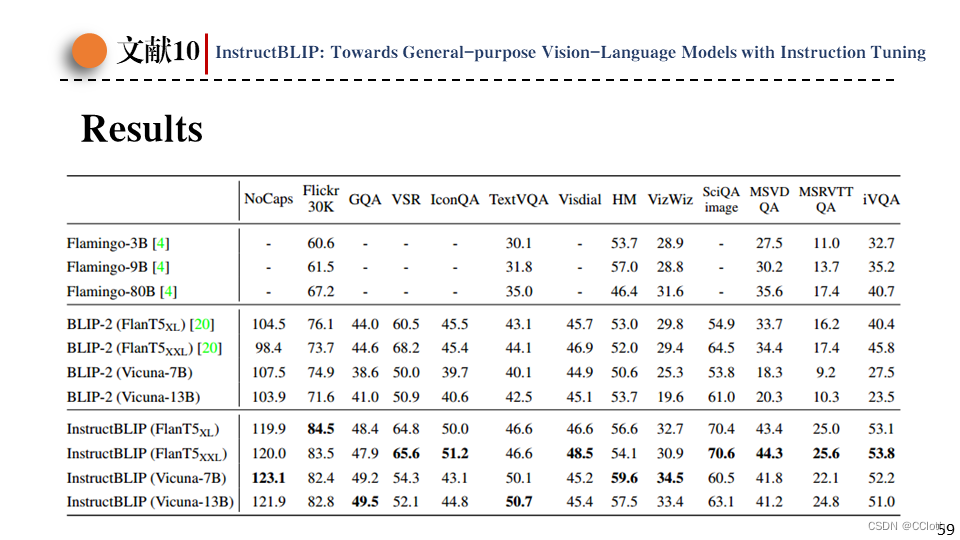
这是在未参与微调的13个数据集上的zero-shot表现,在这些数据集上均达到了sota,另外instructBLIP在模型大小上也占据着明显优势。
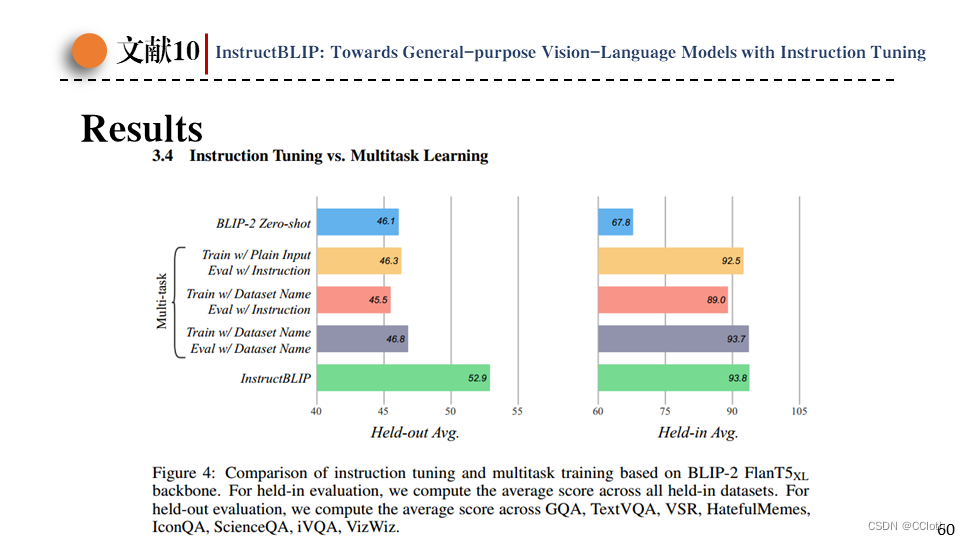
这里的实验类似谷歌FLAN中的实验,以BLIP2为基础,测试了BLIP2+多任务学习和BLIP2+指令微调的结果,显然指令微调的zero-shot效果要更好。

















 4274
4274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









