






最近做的CUDA C++的高性能并行作业
本人小菜鸡一个,padding,stride...,全局/共享内存啥的都没做
如果你的输入矩阵不是方针,可自行修改输入大小的宽高,本文默认方针宽高皆为arr_size
1. 二维卷积如下,便不多做解释(图片来自网络,侵权请联系删除)
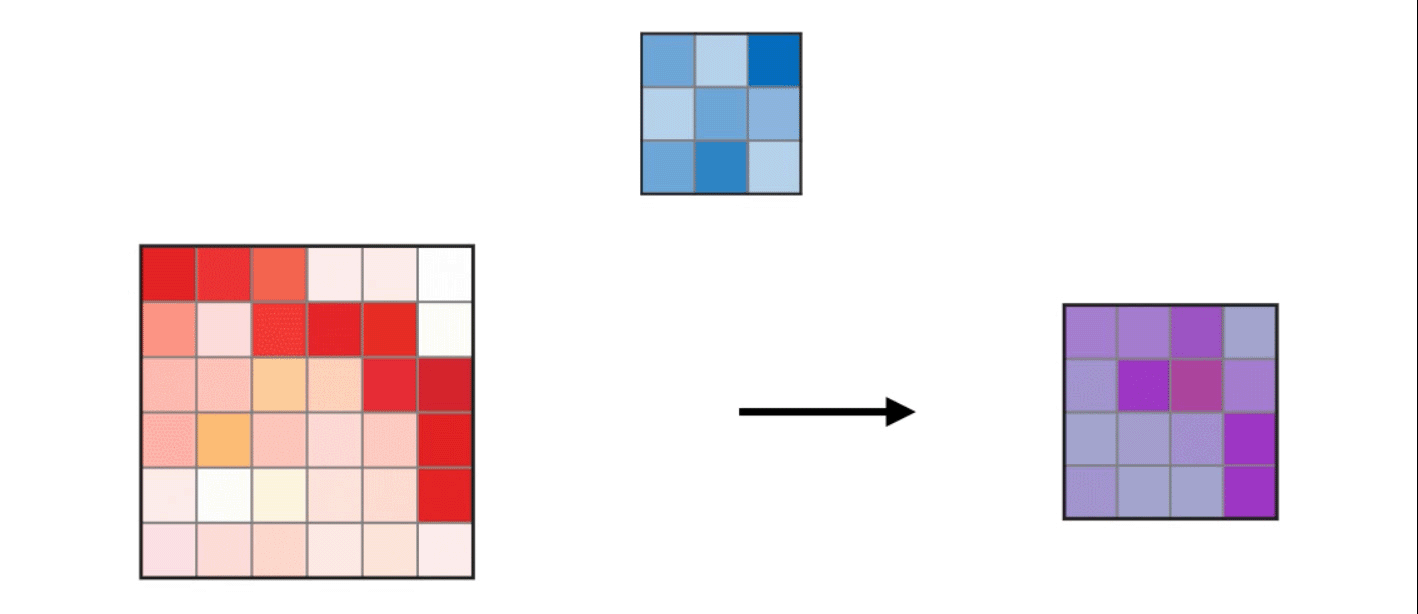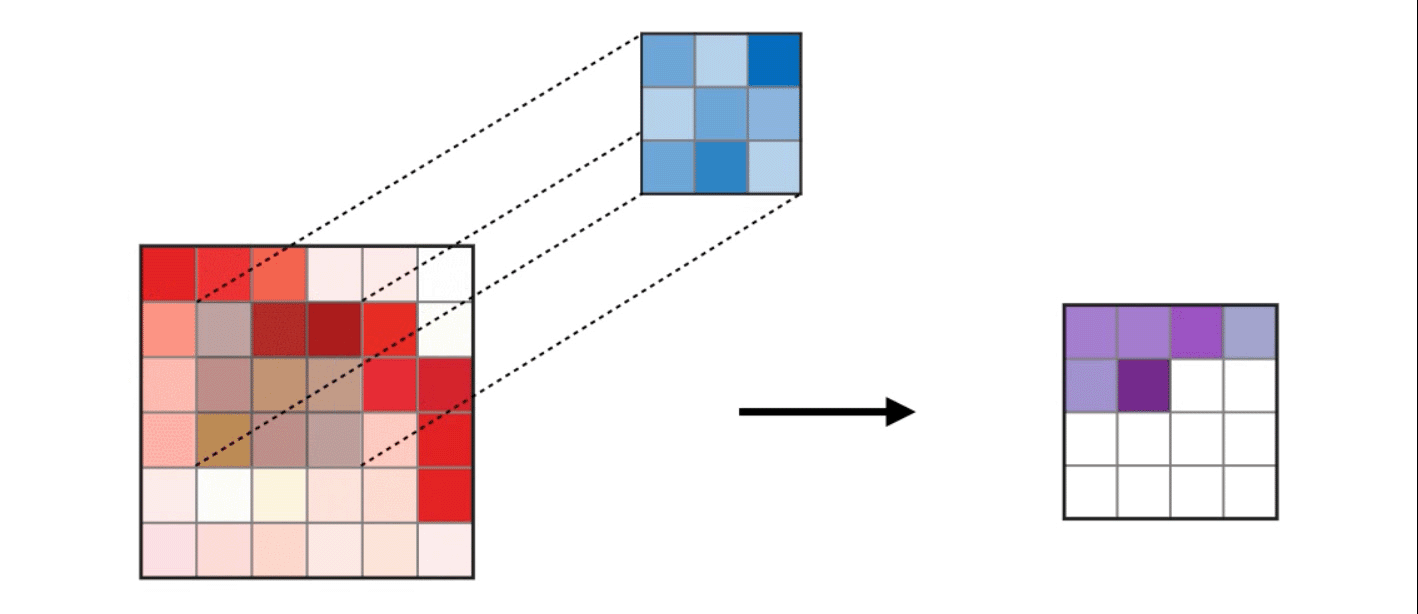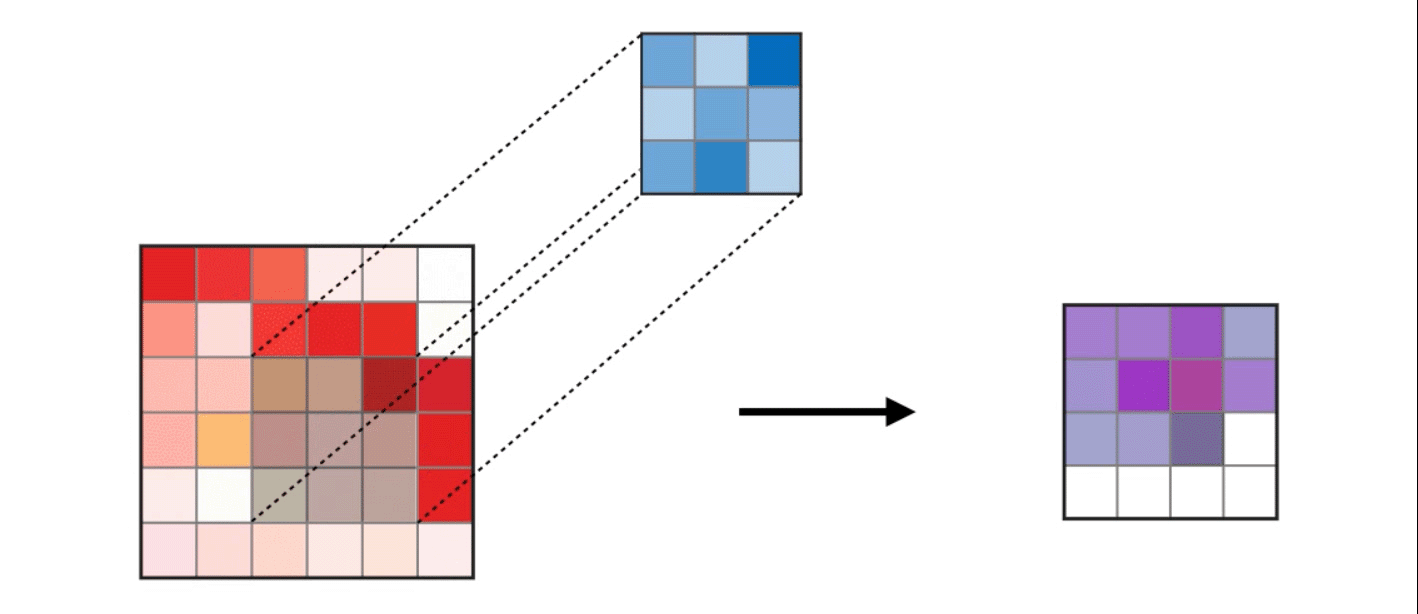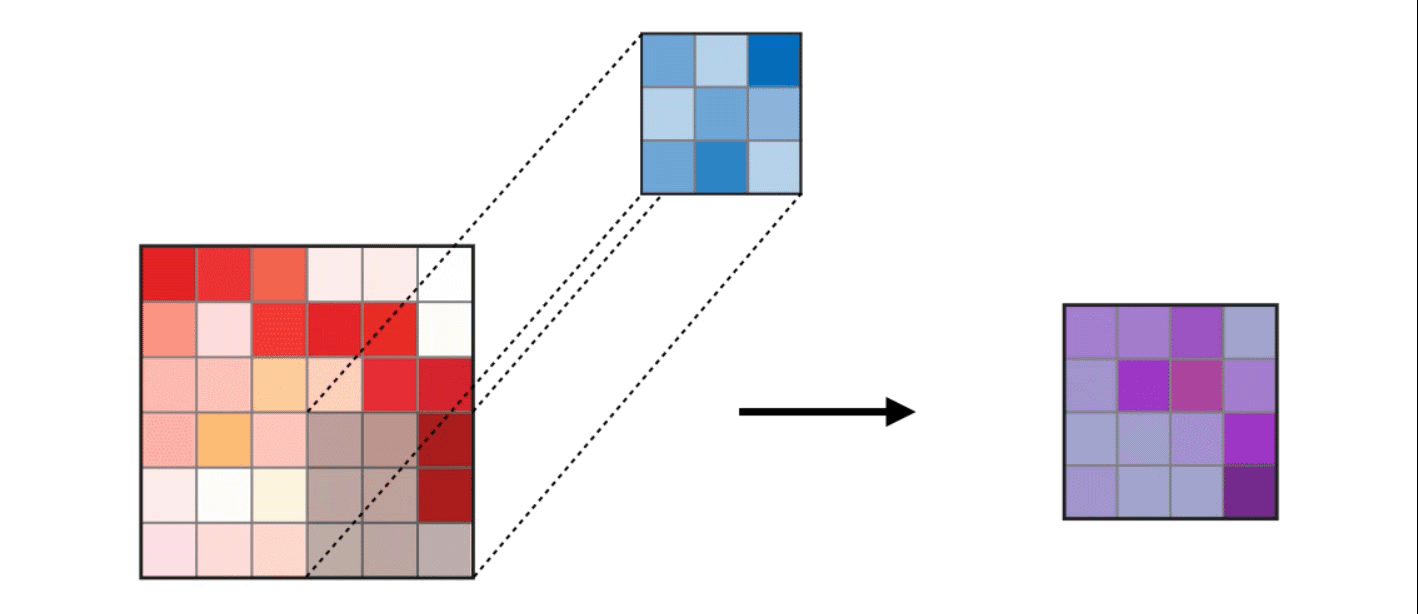
2. CPU串行实现代码
void Conv2(float** filter, float** arr, float** result, int filter_size, int arr_size) {
float temp;
for (int i = 0; i < arr_size - filter_size + 1; i++) {
for (int j = 0; j < arr_size - filter_size + 1; j++) {
temp = 0;
for (int m = 0; m < filter_size; m++) {
for (int n = 0; n < filter_size; n++) {
temp += filter[m][n] * arr[i + m][j + n];
}
}
result[i][j] = temp;
}
}
}3.GPU并行代码
此出采用了一维数组表示二维数组的方法
__global__
void convolution_2D_basic(float* filter, float* arr, float* result, int filter_size, int arr_size)
{
int Col = blockIdx.x*blockDim.x + threadIdx.x;
int Row = blockIdx.y*blockDim.y + threadIdx.y;
if (Row < arr_size - filter_size + 1 && Col < arr_size - filter_size + 1)
{
float pixVal = 0;
//start
int startCol = Col;
int startRow = Row;
//caculate the res
for (int i = 0; i < filter_size; i++)
{
for (int j = 0; j < filter_size; j++)
{
int curRow = startRow + i;
int curCol = startCol + j;
if (curRow > -1 && curRow<arr_size&&curCol>-1 && curCol < arr_size)
{
pixVal += filter[i*filter_size + j] * arr[curRow*arr_size + curCol];
}
}
}
result[Row*arr_size + Col] = pixVal;
}
}4. 文件结构和使用
创建一个CUDA runtime 项目(我的项目名:cuda_code)
项目下文件结构如下:
5.完整代码
源.cpp完整代码:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <iostream>
#include"device_launch_parameters.h"
#include"cuda_runtime.h"
#define FILTER_WIDTH 3
int filter_size = FILTER_WIDTH;
int arr_size = 1024;
int result_size = arr_size + FILTER_WIDTH - 1;
extern "C" void Conv2Kernel(float** arr, float** pFilter, int filter_size, int arr_size, int result_size);
void Conv2(float** filter, float** arr, float** result, int filter_size, int arr_size) {
float temp;
for (int i = 0; i < arr_size - filter_size + 1; i++) {
for (int j = 0; j < arr_size - filter_size + 1; j++) {
temp = 0;
for (int m = 0; m < filter_size; m++) {
for (int n = 0; n < filter_size; n++) {
temp += filter[m][n] * arr[i + m][j + n];
}
}
result[i][j] = temp;
}
}
}
int main()
{
int dev = 0;
cudaDeviceProp devProp;
cudaGetDeviceProperties(&devProp, dev);
std::cout << "使用GPU device " << dev << ": " << devProp.name << std::endl;
std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl;
std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl;
std::cout << "每个Grid的Block数:" << devProp.maxGridSize[0] << " x " << devProp.maxGridSize[1] << " x " << devProp.maxGridSize[2] << std::endl;
std::cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << std::endl;
std::cout << "每个EM的最大线程数:" << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << "每个EM的最大线程束数:" << devProp.maxThreadsPerMultiProcessor / 32 << std::endl;
clock_t CPU_start, CPU_stop;
// Array, filter, result
float** pFilter = new float*[filter_size];
for (int i = 0; i < filter_size; i++)
{
pFilter[i] = new float[filter_size];
}
float** arr = new float*[arr_size];
for (int i = 0; i < arr_size; i++)
{
arr[i] = new float[arr_size];
}
float** res = new float*[result_size];
for (int i = 0; i < result_size; i++)
{
res[i] = new float[result_size];
}
//initialization
for (int i = 0; i < filter_size; i++) {
for (int j = 0; j < filter_size; j++)
pFilter[i][j] = rand() % 11;
}
for (int i = 0; i < arr_size; i++) {
for (int j = 0; j < arr_size; j++)
arr[i][j] = rand() % 11;
}
CPU_start = clock();
Conv2(pFilter, arr, res, filter_size, arr_size);
CPU_stop = clock();
float CPU_time = (float)(CPU_stop - CPU_start) / CLOCKS_PER_SEC;
printf("-------------------CPU version Done!------------------\n");
printf("CPU time:%f \n", CPU_time);
Conv2Kernel(arr, pFilter, filter_size, arr_size, result_size);
}kernel.cu完整代码:
#include"device_launch_parameters.h"
#include"cuda_runtime.h"
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
//kernel function
__global__
void convolution_2D_basic(float* filter, float* arr, float* result, int filter_size, int arr_size)
{
int Col = blockIdx.x*blockDim.x + threadIdx.x;
int Row = blockIdx.y*blockDim.y + threadIdx.y;
if (Row < arr_size - filter_size + 1 && Col < arr_size - filter_size + 1)
{
float pixVal = 0;
//start
int startCol = Col;
int startRow = Row;
//caculate the res
for (int i = 0; i < filter_size; i++)
{
for (int j = 0; j < filter_size; j++)
{
int curRow = startRow + i;
int curCol = startCol + j;
if (curRow > -1 && curRow<arr_size&&curCol>-1 && curCol < arr_size)
{
pixVal += filter[i*filter_size + j] * arr[curRow*arr_size + curCol];
}
}
}
result[Row*arr_size + Col] = pixVal;
}
}
extern "C" void Conv2Kernel(float** arr, float** pFilter, int filter_size, int arr_size, int result_size)
{
int arr_size_1D = arr_size * arr_size;
int filter_size_1D = filter_size * filter_size;
int result_size_1D = result_size * result_size;
float *arr_1D = (float*)malloc(arr_size_1D * sizeof(float));
float *result_1D = (float*)malloc(result_size_1D * sizeof(float));
float *filter_1D = (float*)malloc(filter_size_1D * sizeof(float));
for (int i = 0; i < arr_size; i++) {
for (int j = 0; j < arr_size; j++) {
arr_1D[i*arr_size + j] = arr[i][j] * 1.0;
}
}
for (int i = 0; i < filter_size; i++) {
for (int j = 0; j < filter_size; j++) {
filter_1D[i*filter_size + j] = pFilter[i][j] * 1.0;
}
}
float *device_input_arr, *device_output_arr, *device_filter_arr;
cudaMalloc((void**)&device_input_arr, sizeof(float) * arr_size_1D);
cudaMalloc((void**)&device_output_arr, sizeof(float) * result_size_1D);
cudaMalloc((void**)&device_filter_arr, sizeof(float) * filter_size_1D);
cudaEvent_t start, stop;
cudaEventCreate(&start); //创建Event
cudaEventCreate(&stop);
cudaMemcpy(device_input_arr, arr_1D, sizeof(float) * arr_size_1D, cudaMemcpyHostToDevice);
cudaMemcpy(device_output_arr, result_1D, sizeof(float) * result_size_1D, cudaMemcpyHostToDevice);
cudaMemcpy(device_filter_arr, filter_1D, sizeof(float) * filter_size_1D, cudaMemcpyHostToDevice);
dim3 ThreadNum = (64, 64);
dim3 BlockNum = ((arr_size - 0.5) / ThreadNum.x + 1, (arr_size - 0.5) / ThreadNum.x + 1, 1);
cudaEventRecord(start, 0);
convolution_2D_basic << <BlockNum, ThreadNum >> > (device_input_arr, device_output_arr, device_filter_arr, filter_size, arr_size);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaMemcpy(result_1D, device_output_arr, sizeof(float)*arr_size_1D, cudaMemcpyDeviceToHost);
float GPU_time;
cudaEventElapsedTime(&GPU_time, start, stop);
printf("-------------------GPU version Done!------------------\n");
printf("GPU_Time: %f \n", GPU_time);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaFree(device_input_arr);
cudaFree(device_output_arr);
cudaFree(device_filter_arr);
}6.如果想读入图片数据,操作如下
- 为项目配置opencv(网上随便一搜,便能找到)
- 添加头文件,替换初始化arr部分的代码
#include <opencv2/core/core.hpp> #include <opencv2/highgui/highgui.hpp> using namespace cv; //读取图像img。0表示转换为灰度图像(单通道)读入 Mat img = imread("image.jpg", 0); int row = img.rows; int col = img.cols; float** arr = new float*[row]; for (int i = 0; i < row; i++) { arr[i] = new float[col]; } for (int i = 0; i < row; i++) { for (int j = 0; j < col; j++) { arr[i][j] = img.at<uchar>(i, j); } }
















 113
113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











