






 文章介绍了如何使用pandas库在Python中读取CSV、TSV和TXT文件,并演示了数据透视表的创建过程,包括Excel中的透视表制作和pandas中的pivot_table函数。作者还提到了利用groupby函数进行数据汇总。最后,文章鼓励系统化学习和交流IT技能。
文章介绍了如何使用pandas库在Python中读取CSV、TSV和TXT文件,并演示了数据透视表的创建过程,包括Excel中的透视表制作和pandas中的pivot_table函数。作者还提到了利用groupby函数进行数据汇总。最后,文章鼓励系统化学习和交流IT技能。
import pandas as pd
导入csv文件
test1 = pd.read_csv(‘./excel/test12.csv’,index_col=“ID”)
df1 = pd.DataFrame(test1)
print(df1)
💦2.2 读取tsv文件
tab键用 \t 来表示
import pandas as pd
导入tsv文件
test3 = pd.read_csv(“./excel/test11.tsv”,sep=‘\t’)
df3 = pd.DataFrame(test3)
print(df3)
💦2.3 读取txt文件
import pandas as pd
导入txt文件
test2 = pd.read_csv(“./excel/test13.txt”,sep=‘|’)
df2 = pd.DataFrame(test2)
print(df2)
结果:

=============================================================================
在excel中存在多种数据,且分为很多类型,这时使用数据透视表就会很方便也很直观的为我们分析出各种我们想要的数据了。
实例:将下列数据绘制成一个透视表,并绘制出按总类分每年的销售额!

需要按照年份来分,则我们需要将date列拆分,把年份拆分出来。随后在数据栏下选择数据透视表,选择区域即可。

随后将各部分数据拖动到各区域即可。

结果:
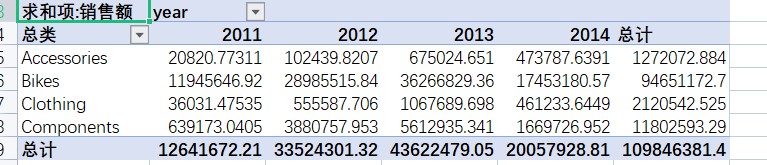
这样就在excel中完成了数据透视表的制作。
那么在pandas中要怎么实现这一效果呢?
绘制透视表的函数为:df.pivot_lable(index,columns,values),最后将数据求和即可。
import pandas as pd
import numpy as np
pd.options.display.max_columns =999
test = pd.read_excel(‘./excel/test14.xlsx’)
df = pd.DataFrame(test)
将年份取出并新建一个列名为年份的列
df[‘year’] = pd.DatetimeIndex(df[‘Date’]).year
绘制透视表
table = df.pivot_table(index=‘总类’,columns=‘year’,values=‘销售额’,aggfunc=np.sum)
df1 = pd.DataFrame(table)
df1[‘总计’] = df1[[2011,2012,2013,2014]].sum(axis=1)
print(df1)
结果:

除此之外还可以利用groupby函数来绘制数据表。这里将总类和年份分组求销售总额和销售数量。
import pandas as pd
import numpy as np
pd.options.display.max_columns =999
test = pd.read_excel(‘./excel/test14.xlsx’)
df = pd.DataFrame(test)
将年份取出并新建一个列名为年份的列
df[‘year’] = pd.DatetimeIndex(df[‘Date’]).year
groupby方法
group = df.groupby([‘总类’,‘year’])
s= group[‘销售额’].sum()
c = group[‘ID’].count()
table = pd.DataFrame({‘sum’😒,‘total’:c})
print(table)

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 9085
9085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









